資訊專欄INFORMATION COLUMN

摘要:判別器勝利的條件則是很好地將真實(shí)圖像自編碼,以及很差地辨識生成的圖像。
先看一張圖:
下圖左右兩端的兩欄是真實(shí)的圖像,其余的是計算機(jī)生成的。

過渡自然,效果驚人。
這是谷歌本周在 arXiv 發(fā)表的論文《BEGAN:邊界均衡生成對抗網(wǎng)絡(luò)》得到的結(jié)果。這項(xiàng)工作針對 GAN 訓(xùn)練難、控制生成樣本多樣性難、平衡鑒別器和生成器收斂難等問題,提出了改善。
尤其值得注意的,是作者使用了很簡單的結(jié)構(gòu),經(jīng)過常規(guī)訓(xùn)練,取得了優(yōu)異的視覺效果。
作者在論文中寫道,他們的主要貢獻(xiàn)是:
一個簡單且具有魯棒性的 GAN 架構(gòu),使用標(biāo)準(zhǔn)的訓(xùn)練步驟實(shí)現(xiàn)了快速、穩(wěn)定的收斂
一種均衡的概念,用于平衡判別器和生成器(判別器往往在訓(xùn)練早期就以壓倒性優(yōu)勢勝過生成器)
一種控制在圖像多樣性與視覺質(zhì)量之間權(quán)衡的新方法
用于近似衡量收斂的方法,據(jù)我們所知,目前發(fā)表過的這類方法另外只有一種,那就是 Wasserstein GAN(WGAN)
GAN 的結(jié)構(gòu)特點(diǎn)和理論優(yōu)勢
在介紹 BEGAN 之前,有必要回顧一下 GAN 和 EBGAN(Engry-Based GAN,基于能量的 GAN)。它們是 BEGAN 的基礎(chǔ)。
中國科學(xué)院計算技術(shù)研究所智能信息處理重點(diǎn)實(shí)驗(yàn)室助理教授楊雙在她發(fā)表在“深度學(xué)習(xí)大講壇”的文章《解讀 GAN 及其 2016 年度進(jìn)展》當(dāng)中,做了很好的介紹。我們在取得授權(quán)后引用了介紹 GAN 和 EBGAN 的相關(guān)部分。
首先是基本的 GAN 模型。
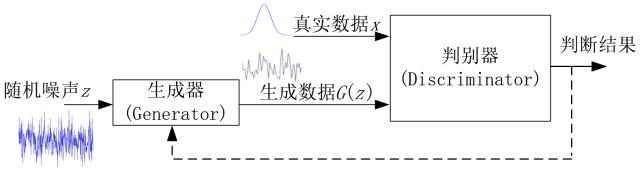
“原始 GAN 模型的基本框架如上圖所示,其主要目的是要由判別器 D 輔助生成器 G 產(chǎn)生出與真實(shí)數(shù)據(jù)分布一致的偽數(shù)據(jù)。模型的輸入為隨機(jī)噪聲信號 z;該噪聲信號經(jīng)由生成器 G 映射到某個新的數(shù)據(jù)空間,得到生成的數(shù)據(jù) G(z);接下來,由判別器 D 根據(jù)真實(shí)數(shù)據(jù) x 與生成數(shù)據(jù) G(z) 的輸入來分別輸出一個概率值或者說一個標(biāo)量值,表示 D 對于輸入是真實(shí)數(shù)據(jù)還是生成數(shù)據(jù)的置信度,以此判斷 G 的產(chǎn)生數(shù)據(jù)的性能好壞;當(dāng)最終 D 不能區(qū)分真實(shí)數(shù)據(jù) x 和生成數(shù)據(jù) G(z) 時,就認(rèn)為生成器 G 達(dá)到了最優(yōu)。
“D 為了能夠區(qū)分開兩者,其目標(biāo)是使 D(x) 與 D(G(z)) 盡量往相反的方向跑,增加兩者的差異,比如使 D(x) 盡量大而同時使 D(G(z)) 盡量小;而 G 的目標(biāo)是使自己產(chǎn)生的數(shù)據(jù)在 D 上的表現(xiàn) D(G(z)) 盡量與真實(shí)數(shù)據(jù)的表現(xiàn) D(x) 一致,讓 D 不能區(qū)分生成數(shù)據(jù)與真實(shí)數(shù)據(jù)。因此,這兩個模塊的優(yōu)化過程是一個相互競爭相互對抗的過程,兩者的性能在迭代過程中不斷提高,直到最終 D(G(z)) 與真實(shí)數(shù)據(jù)的表現(xiàn) D(x) 一致,此時 G 和 D 都不能再進(jìn)一步優(yōu)化。”
楊雙介紹說,GAN 除了提供了一種對抗訓(xùn)練的框架,另一個重要貢獻(xiàn)是其收斂性的理論證明。
“作者通過將 GAN 的優(yōu)化過程進(jìn)行分解,從數(shù)學(xué)推導(dǎo)上嚴(yán)格證明了:在假設(shè) G 和 D 都有足夠的 capacity 的條件下,如果在迭代過程中的每一步,D 都可以達(dá)到當(dāng)下在給定 G 時的最優(yōu)值,并在這之后再更新 G ,那么最終 Pg 就一定會收斂于Pdata。也正是基于上述的理論,原始文章中是每次迭代中優(yōu)先保證 D 在給定當(dāng)前 G 下達(dá)到最優(yōu),然后再去更新 G 到最優(yōu),如此循環(huán)迭代完成訓(xùn)練。這一證明為 GAN 的后續(xù)發(fā)展奠定了堅實(shí)基礎(chǔ),使其沒有像許多其它深度模型一樣只是被應(yīng)用而沒有廣而深的改進(jìn)。”
判別器:借鑒基于能量的GAN
楊雙在《解讀 GAN 及其 2016 年度進(jìn)展》當(dāng)中介紹,對 GAN 模型的理論框架層面的改進(jìn)工作主要可以歸納為兩類:一類是從第三方的角度(不是從GAN 模型本身)看待 GAN 并進(jìn)行改進(jìn)和擴(kuò)展的方法;第二類是從 GAN 模型框架的穩(wěn)定性、實(shí)用性等角度出發(fā)對模型本身進(jìn)行改進(jìn)的工作。
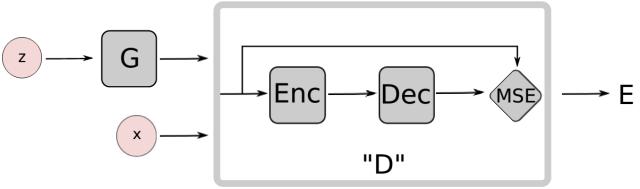
其中,“EBGAN 是 Yann LeCun 課題組提交到 ICLR2017的一個工作,從能量模型的角度對 GAN 進(jìn)行了擴(kuò)展。EBGAN 將判別器看做是一個能量函數(shù),這個能量函數(shù)在真實(shí)數(shù)據(jù)域附近的區(qū)域中能量值會比較小,而在其他區(qū)域(即非真實(shí)數(shù)據(jù)域區(qū)域)都擁有較高能量值。因此,EBGAN 中給予 GAN 一種能量模型的解釋,即生成器是以產(chǎn)生能量最小的樣本為目的,而判別器則以對這些產(chǎn)生的樣本賦予較高的能量為目的。
“從能量模型的角度來看待判別器和 GAN 的好處是,我們可以用更多更寬泛的結(jié)構(gòu)和損失函數(shù)來訓(xùn)練 GAN 結(jié)構(gòu),比如文中就用自編碼器(AE)的結(jié)構(gòu)來作為判別器實(shí)現(xiàn)整體的GAN 框架,如下圖所示:
在訓(xùn)練過程中,EBGAN 比 GAN 展示出了更穩(wěn)定的性能,也產(chǎn)生出了更加清晰的圖像,如下圖所示。

生成器:借鑒 Wasserstein GAN
谷歌的這篇新論文提出的 BEGAN(Boundary Equilibrium GAN),將 AE 作為判別器,在架構(gòu)上與 EBGAN 十分類似。
在生成器方面,BEGAN 則借鑒了 Wasserstein GAN 定義 loss 的思路。作者在論文中寫道,“我們的方法使用從 Wasserstein 距離衍生而來的 loss 去匹配自編碼 loss 分布。”
今年年初 WGAN 論文發(fā)布時,也在業(yè)界引發(fā)熱議,當(dāng)時新智元轉(zhuǎn)載了鄭華濱發(fā)表在知乎專欄的文章《令人拍案叫絕的 Wasserstein GAN,徹底解決 GAN 訓(xùn)練不穩(wěn)定問題》。
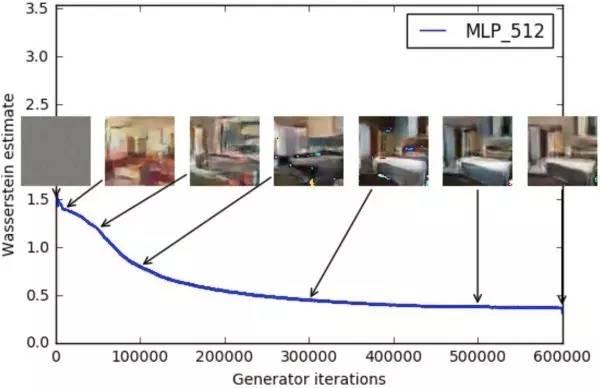
在 WGAN 中,判別器近似的 Wasserstein 距離與生成器的生成圖片質(zhì)量高度相關(guān),如下所示:
相比傳統(tǒng) GAN 直接匹配數(shù)據(jù)分布,EBGAN 使用一種新的方法,將 loss 基于判別器的重構(gòu)誤差。作者通過一個額外的均衡條件,讓生成器和判別器相互平衡。作者表示,他們的方法訓(xùn)練起來更方便,與傳統(tǒng) GAN 技巧相比架構(gòu)也更簡單。
EBGAN:簡單模型,效果驚艷
回到我們介紹的 BEGAN,BEGAN 的架構(gòu)十分簡單,幾乎所有都是 3×3 卷積,sub-sampling 或者 upsampling,沒有 dropout、批量歸一化或者隨機(jī)變分近似。
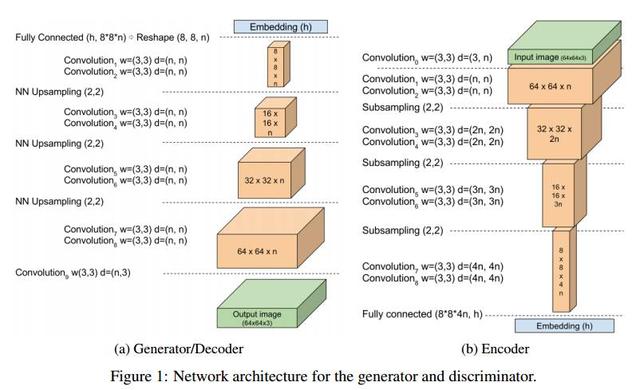
判別器是 loss 為 L1 的自編碼器,生成器每生成一幅圖,這幅圖判別器能夠在 loss 很小的情況下自編碼,生成器就算勝利。判別器勝利的條件則是①很好地將真實(shí)圖像自編碼,以及②很差地辨識生成的圖像。
這篇論文的另一個貢獻(xiàn)是提出了一個衡量生成樣本多樣性的超參數(shù) γ:生成樣本 loss 的預(yù)期與真實(shí)樣本 loss的預(yù)期之比。這個超參數(shù)能夠均衡 D 和 G,從而穩(wěn)定訓(xùn)練過程。如果生成器表現(xiàn)太好,就側(cè)重判別器。
不僅如此,這個超參數(shù) γ 還提供了一個可以衡量的指標(biāo),用于判斷收斂,最終也對應(yīng)圖像的質(zhì)量。

摘要
我們提出了一種新的用于促成訓(xùn)練時生成器和判別器實(shí)現(xiàn)均衡(Equilibrium)的方法,以及一個配套的 loss,這個 loss 由 Wasserstein distance 衍生而來,Wasserstein distance 則是訓(xùn)練基于自編碼器的生成對抗網(wǎng)絡(luò)(GAN)使用的。此外,這種新的方法還提供了一種新的近似收斂手段,實(shí)現(xiàn)了快速穩(wěn)定的訓(xùn)練和很高的視覺質(zhì)量。我們還推導(dǎo)出一種能夠控制權(quán)衡圖像多樣性和視覺質(zhì)量的方法。在論文里我們專注于圖像生成任務(wù),在更高的分辨率下建立了視覺質(zhì)量的新里程碑。所有這些都是使用相對簡單的模型架構(gòu)和標(biāo)準(zhǔn)的訓(xùn)練流程實(shí)現(xiàn)的。

測試結(jié)果:上面是基于能量的GAN(EBGAN)與邊界均衡 GAN(BEGAN)的對比,后者由顯著提升;下面展示展示了超參數(shù) γ 值不同情況的對比,可以看出 γ 值越大圖片質(zhì)量越高。
參考資料
楊雙,【青年學(xué)者專欄】解讀GAN及其 2016 年度進(jìn)展,深度學(xué)習(xí)大講堂
鄭華濱,令人拍案叫絕的Wasserstein GAN,知乎專欄
商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4503.html
摘要:一段時間以來,我一直在嘗試使用生成神經(jīng)網(wǎng)絡(luò)制作人物肖像。生成圖像的質(zhì)量與低分辨率輸出實(shí)現(xiàn)密切相關(guān)。在第一階段,根據(jù)給定描述生成相對原始的形狀和基本的色彩,得出低分辨圖像。使用生成的圖像比現(xiàn)有方法更加合理逼真。 一段時間以來,我一直在嘗試使用生成神經(jīng)網(wǎng)絡(luò)制作人物肖像。早期試驗(yàn)基于類似 Deep Dream 的方法,但最近我開始將精力集中在 GAN 上面。當(dāng)然,無論在什么時候,高精度和較精確的細(xì)...

閱讀 772·2021-10-09 09:58
閱讀 641·2021-08-27 16:24
閱讀 1723·2019-08-30 14:15
閱讀 2384·2019-08-30 11:04
閱讀 2067·2019-08-29 18:43
閱讀 2170·2019-08-29 15:20
閱讀 2716·2019-08-26 12:20
閱讀 1616·2019-08-26 11:44


