資訊專欄INFORMATION COLUMN

摘要:的這項研究,總共生成了篇深度學習論文的和代碼,還創建了一個網站,供同行們眾包編輯這些代碼。來自印度研究院。目前是印度研究院的實習生。
深度學習的論文越來越多了~
多到什么程度?Google scholar的數據顯示,2016年以來,人工智能領域新增的論文已經超過3.5萬篇。arXiv上,AI相關的論文每天都不下百篇。
剛剛結束不久的計算機視覺會議ICCV上,發表了621篇論文;2018年的ICLR,有1004篇論文正在匿名開放評審;NIPS 2017共收到3240篇論文投稿。
研究成果極大豐富了,但離應用到產品中,還差一大步:把論文轉化成代碼。畢竟,作者順便提供源碼的是少數。
怎么辦?
IBM印度研究院最近公布了一項新研究:DLPaper2Code,顧名思義,這個程序能夠用深度學習技術,將論文轉化成代碼。

論文轉代碼的過程
這么神奇?!該不是看到一篇假研究?
坦白講,相關論文DLPaper2Code: Auto-generation of Code from Deep Learning Research Papers已經被AAAI 2018接收為會議論文。
AAAI是人工智能頂會之一,明年就是第32屆了,2月2-7日在美國路易斯安那州的新奧爾良召開。百度、京東是大會的黃金贊助商。

深度學習論文自動轉代碼
這篇論文中指出,由于大部分深度學習論文都會用流程圖來表示神經網絡模型的設計模式,因此,在論文轉換成代碼的過程中,DLPaper2Code首先提取、理解論文中描述的深度學習設計流程圖和表格,將它們轉化成抽象的計算圖。
然后,它會把抽取的計算圖轉換成Keras和Caffe框架下的可執行源代碼。
IBM的這項研究,總共生成了5000篇arXiv深度學習論文的Caffe和Keras代碼,還創建了一個網站,供同行們眾包編輯這些代碼。不過,這個網站的地址還沒有公布,目前只能看到截圖:
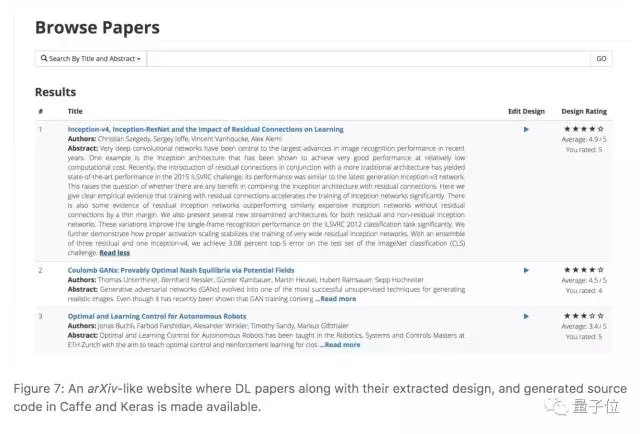
在提取流程圖的過程中,IBM的研究員們遇到了一些障礙:他們需要讓程序提取論文中所有圖表之后,再進行一次分類,找出包含深度學習模型設計的那些,去掉那些和模型相關性不大的描述性圖片和展示結果的表格。
但是,論文中介紹深度學習模型設計的圖千奇百怪,表格的結構也各不相同。
怎樣讓程序自動找出有用的圖表呢?IBM研究員們人肉處理了論文中的3萬張圖,將深度學習模型設計圖分成了5大類:
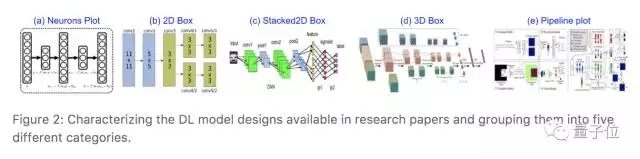
5大類深度學習模型設計圖
1. 神經元分布圖;
2. 2D Box:將每個隱藏層表示為一個2D方塊;
3. Stacked2D Box:將神經網絡每一層表示為堆疊的2D方塊,表示層的深度;
4. 3D Box:將每個隱藏層表示為一個3D立方體結構;
5. 表示整個流程的Pipeline plot。
而表格,主要包括橫排表示模型設計流程和縱列表示模型設計流程兩類。
在此基礎上,他們構建了一個細粒度的分類器,來把圖表分到上面提到的5類圖2類表之中,然后就可以使用OCR等工具將圖表中的內容提取出來。
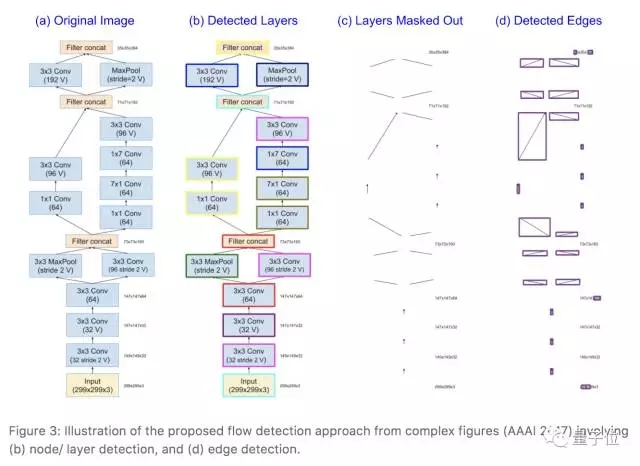
從圖中提取內容的過程
圖表內容提取出來之后,就可以根據這些信息構建計算圖并生成源代碼了。
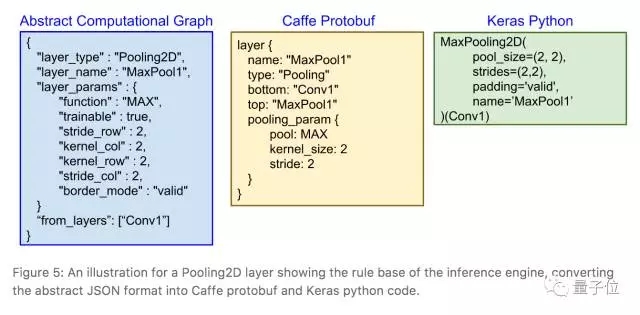
池化2D層對應的計算圖、Caffe(Protobuf)和Keras(Python)代碼
自動生成的代碼究竟怎么樣呢?
為了對DLPaper2Code進行評估,IBM研究員們創建了一個包含21.6萬份設計可視化圖的模擬數據集,在這些數據集上的實驗顯示,上面講的模型,在流程圖內容提取上準確率可達93%。
AI自動化暢想曲
上面這個研究。來自IBM印度研究院。
共有五位署名作者:Akshay Sethi、Anush Sankaran、Naveen Panwar、Shreya Khare、Senthil Mani。其中第一作者Akshay Sethi,明年才會本科畢業。目前是IBM印度研究院的實習生。
嗯,實習生又開掛了。中外概莫能外~
但這么一篇清新脫俗的研究,真能在實踐中應用么?
在reddit上,不少人還是對這篇論文有點心生疑慮。比方有人覺得這個論文很有意思,但是細細讀下來,還是有些地方比較奇怪。但也有人覺得雖然標題有點唬人,但這項研究感覺還是不錯。當然也有人直言:浪費時間。
更多的結論還有待時間考驗,但歸根結底,這些都是AI自動化方向的一種探索。讓AI自己搞定AI,讓軟件自己編寫軟件,一直都是研究人員追逐的目標。
比方今年5月,Google發布了AutoML。對,就是跟今天正式推出的TensorFlow Lite同天發布的AutoML。
AutoML就是要讓神經網絡去設計神經網絡。谷歌希望能借AutoML來促進深度學習開發者規模的擴張,讓設計神經網絡的人,從供不應求的PhD,變成成千上萬的普通工程師。

也是在今年,MIT學者開發出一套系統,能夠自動給代碼打補丁。
聽起來,以后碼農越來越好干了呢。其實不是。
要知道,微軟和劍橋聯合開發了一個系統:DeepCoder。就能夠通過搜索一系列代碼建立一個完整的程序,可達到編程比賽的水平。而且,這個系統還能通過自我訓練能夠變得更聰明。未來程序員的飯碗也不是很鐵了。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4673.html
摘要:期間,我從爬蟲入手,一路摸爬滾打,實現了千萬級微博評論自動抓取,在即將成為爬蟲專家前,受師兄指點轉向算法。確定研究方向經過前面的理論學習,你應該發現深度學習領域有很多細分方向,例如語音自然語言處理視覺強化學習純深度學習理論。 最近很多剛入學的學弟學妹給我們留言,聽說算法崗現在競爭很激烈,...
摘要:不過,蘋果實驗室作為計算機學院的學習類組織,撰寫此貼的內容集中于本科期間學習路線的宏觀規劃建議。其中主要問題大概是初入大學的迷茫與美好大學愿景之間的矛盾自主學習能力的欠缺與遠大志向的矛盾。 ...
摘要:主流機器學習社區對神經網絡興趣寡然。對于深度學習的社區形成有著巨大的影響。然而,至少有兩個不同的方法對此都很有效應用于卷積神經網絡的簡單梯度下降適用于信號和圖像,以及近期的逐層非監督式學習之后的梯度下降。 我們終于來到簡史的最后一部分。這一部分,我們會來到故事的尾聲并一睹神經網絡如何在上世紀九十年代末擺脫頹勢并找回自己,也會看到自此以后它獲得的驚人先進成果。「試問機器學習領域的任何一人,是什...

閱讀 2694·2023-04-25 17:58
閱讀 2978·2021-11-15 11:38
閱讀 2378·2021-11-02 14:48
閱讀 1184·2021-08-25 09:40
閱讀 1823·2019-08-30 15:53
閱讀 1093·2019-08-30 15:52
閱讀 1031·2019-08-30 13:55
閱讀 2436·2019-08-29 15:21




