資訊專欄INFORMATION COLUMN

摘要:音頻超分辨率旨在重建一個以較低分辨率波形作為輸入的高分辨率音頻波形。由于受到深度學(xué)習(xí)成功應(yīng)用于圖像超分辨率的啟發(fā),我最近致力于使用深層神經(jīng)網(wǎng)絡(luò)來完成原始音頻波形的上采樣。上采樣塊使用子像素卷積,其沿著一個維度重新排列信息以擴展其他維度。
音頻超分辨率旨在重建一個以較低分辨率波形作為輸入的高分辨率音頻波形。在諸如流式音頻和音頻恢復(fù)之類的領(lǐng)域中,這種類型的上采樣存在著若干種潛在應(yīng)用。一個傳統(tǒng)的解決方案是使用音頻剪輯的數(shù)據(jù)庫,憑借相似性指標(biāo)來填充下采樣波形中的缺失頻率(見本文和本文)。由于受到深度學(xué)習(xí)成功應(yīng)用于圖像超分辨率的啟發(fā),我最近致力于使用深層神經(jīng)網(wǎng)絡(luò)來完成原始音頻波形的上采樣。在制定了幾種方法之后,我把注意力主要集中于實施和自定義最近將發(fā)表于2017年國際學(xué)習(xí)代表會議(ICLR)上的研究論文。

雖然音頻上采樣在大量的領(lǐng)域中都可能是有用的,但我只專注于潛在的IP語音應(yīng)用程序。我為這個項目選擇的數(shù)據(jù)集是一個TED演講的集合,大小大約為35 GB。每個講話都位于一個多帶帶的文件中,比特率為16千比特每秒(kbps),這被認(rèn)為是高質(zhì)量的語音音頻。這個數(shù)據(jù)集主要包含一些非常精彩的英語演講,而這是從大量演講者在面對不同觀眾的演講中挑選出來的。這些TED演講的質(zhì)量與人們在IP語音對話期間所期望的值近似。
?
預(yù)處理步驟如上圖所示。每個文件的第一個和最后30秒被修剪以便刪除TED演講的開始和結(jié)束部分。然后將文件拆分為2秒的剪輯,并以4 kbps的速率創(chuàng)建一個獨立的,4x下采樣的剪輯集合以及一組原始速率為16 kbps的集合。60%的數(shù)據(jù)集用于訓(xùn)練,20%用于驗證,20%用于測試。
?

上圖中列出的訓(xùn)練工作流程使用數(shù)據(jù)預(yù)處理步驟中的下采樣片段,并將其批量饋入模型(深層神經(jīng)網(wǎng)絡(luò))以更新其權(quán)重。具有較低驗證分?jǐn)?shù)的模型(表示為“較佳模型”)被保存以供接下來使用。
?
在上圖中給出了使用“較佳模型”對音頻文件進行上采樣的過程。該工作流采用整個音頻文件,與預(yù)處理步驟類似地將其拼接到剪輯中,將它們依次饋送到經(jīng)過訓(xùn)練后的模型中,將高分辨率剪輯縫合在一起,并將高分辨率文件保存到磁盤中。
模型架構(gòu)
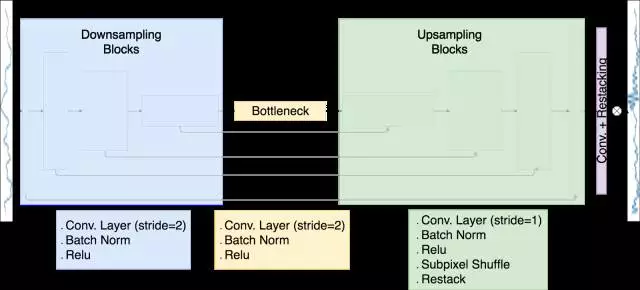
我所實現(xiàn)的模型架構(gòu)是U-Net,它使用的是子像素卷積的一維模擬而不是反卷積層。我使用Tensorflow的Python API構(gòu)建和訓(xùn)練模型,同時使用Tensorflow的C ++ API實現(xiàn)子像素卷積層。該模型的工作原理如下:
下采樣波形通過八個下采樣塊發(fā)送,每個采樣塊都由步幅為2的卷積層組成。在每個層上,濾波器組的數(shù)量加倍,使得沿著波形的維度減小了一半,濾波器組的尺寸增加了兩個。
該瓶頸層被構(gòu)造成與下采樣塊相同,這個下采樣塊與8個上采樣塊相連,而這些塊與下行采樣塊是有殘留連接的。這些殘留連接允許共享從低分辨率波形學(xué)習(xí)到的特征。
上采樣塊使用子像素卷積,其沿著一個維度重新排列信息以擴展其他維度。
在原始輸入中添加了具有重新排列和重新排序操作的最終卷積層,以便產(chǎn)生上采樣波形。
所使用的損耗函數(shù)是輸出波形與原始高分辨率波形之間的均方差。
性能
?
上圖顯示了在10個訓(xùn)練時期之后,測試樣本的兩項性能指標(biāo)。左列是頻率與時間的頻譜圖,右邊是波形振幅對時間的曲線。
第一行包含原始高分辨率音頻樣本的頻譜圖和波形圖。
中間行包含原始音頻樣本的4x下采樣版本的相似圖。請注意,下采樣頻率圖中缺少3/4的較高頻率。
最后一行包含訓(xùn)練模型輸出的語譜圖和波形圖。
插入值是兩個量化的性能度量指標(biāo):信噪比(SNR)和對數(shù)光譜距離(LSD)。較高的SNR值表示更清晰的聲音,而較低的LSD值表示匹配的頻率內(nèi)容。LSD值顯示神經(jīng)網(wǎng)絡(luò)正在嘗試在適當(dāng)?shù)牡胤交謴?fù)較高的頻率。然而,稍低的SNR值意味著音頻可能不是清晰的。
一篇受到這個架構(gòu)啟發(fā)的論文聲稱對數(shù)據(jù)進行了400次的訓(xùn)練,而由于時間限制,我只能訓(xùn)練10次。較長的訓(xùn)練周期可能導(dǎo)致重建波形的清晰度提高。你可以在下面聆聽測試集中的示例音頻剪輯。前5秒剪輯是原始音頻16 kbps,第二個是4kbps的下采樣音頻,最后一個是16kbps的重建音頻。
1.從測試集中以16 kbps的隨機剪輯。
2.下采樣版本的上述剪輯。請注意,所有高頻內(nèi)容都丟失。
3.重建剪輯。大部分高頻內(nèi)容已經(jīng)以犧牲清晰度的代價來恢復(fù)。
開源貢獻
下采樣音頻的重建可以有各種應(yīng)用,更令人興奮的是將這些技術(shù)應(yīng)用于其他非音頻信號的可能性。我鼓勵你采用和修改我的github repo提供的代碼,從而對這些代碼進行實驗。
除了提供這些實驗的代碼之外,我還希望為日益增長的應(yīng)用AI社區(qū)提供更多的開源資源。由于子像素卷積層是一種可能對深入學(xué)習(xí)研究人員和工程師都有用的通用操作,因此我一直在對TensorFlow作出貢獻,并與他們的團隊緊密合作,以便將其整合到代碼庫中。
作者:Jeffrey Hetherly
來源:insightdatascience
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4560.html
摘要:基于深度學(xué)習(xí)的,主要是基于單張低分辨率的重建方法,即。而基于深度學(xué)習(xí)的通過神經(jīng)網(wǎng)絡(luò)直接學(xué)習(xí)分辨率圖像到高分辨率圖像的端到端的映射函數(shù)。 超分辨率技術(shù)(Super-Resolution)是指從觀測到的低分辨率圖像重建出相應(yīng)的高分辨率圖像,在監(jiān)控設(shè)備、衛(wèi)星圖像和醫(yī)學(xué)影像等領(lǐng)域都有重要的應(yīng)用價值。SR可分為兩類:從多張低分辨率圖像重建出高分辨率圖像和從單張低分辨率圖像重建出高分辨率圖像。基于深度學(xué)...
摘要:深度學(xué)習(xí)已經(jīng)在圖像分類檢測分割高分辨率圖像生成等諸多領(lǐng)域取得了突破性的成績。另一個問題是深度學(xué)習(xí)的模型比如卷積神經(jīng)網(wǎng)絡(luò)有時候并不能很好地學(xué)到訓(xùn)練數(shù)據(jù)中的一些特征。本文通過最近的幾篇文章來介紹它在圖像分割和高分辨率圖像生成中的應(yīng)用。 深度學(xué)習(xí)已經(jīng)在圖像分類、檢測、分割、高分辨率圖像生成等諸多領(lǐng)域取得了突破性的成績。但是它也存在一些問題。首先,它與傳統(tǒng)的機器學(xué)習(xí)方法一樣,通常假設(shè)訓(xùn)練數(shù)據(jù)與測試數(shù)...
摘要:深度學(xué)習(xí)方法是否已經(jīng)強大到可以使科學(xué)分析任務(wù)產(chǎn)生最前沿的表現(xiàn)在這篇文章中我們介紹了從不同科學(xué)領(lǐng)域中選擇的一系列案例,來展示深度學(xué)習(xí)方法有能力促進科學(xué)發(fā)現(xiàn)。 深度學(xué)習(xí)在很多商業(yè)應(yīng)用中取得了前所未有的成功。大約十年以前,很少有從業(yè)者可以預(yù)測到深度學(xué)習(xí)驅(qū)動的系統(tǒng)可以在計算機視覺和語音識別領(lǐng)域超過人類水平。在勞倫斯伯克利國家實驗室(LBNL)里,我們面臨著科學(xué)領(lǐng)域中最具挑戰(zhàn)性的數(shù)據(jù)分析問題。雖然商業(yè)...

閱讀 1030·2021-09-22 15:26
閱讀 2606·2021-09-09 11:52
閱讀 1889·2021-09-02 09:52
閱讀 2241·2021-08-12 13:28
閱讀 1180·2019-08-30 15:53
閱讀 505·2019-08-29 13:47
閱讀 3379·2019-08-29 11:00
閱讀 3095·2019-08-29 10:58




