資訊專欄INFORMATION COLUMN

摘要:可以想象,監督式學習和增強式學習的不同可能會防止對抗性攻擊在黑盒測試環境下發生作用,因為攻擊無法進入目標策略網絡。我們的實驗證明,即使在黑盒測試中,使用特定對抗樣本仍然可以較輕易地愚弄神經網絡策略。

機器學習分類器在故意引發誤分類的輸入面前具有脆弱性。在計算機視覺應用的環境中,對這種對抗樣本已經有了充分研究。論文中,我們證明了對于強化學習中的神經網絡策略,對抗性攻擊依然有效。我們特別論證了,現有的制作樣本的技術可以顯著降低訓練策略在測試時的性能。我們的威脅模型認為對抗攻擊會為神經網絡策略的原始輸入引入小的干擾。針對對抗樣本攻擊,我們通過白盒測試和黑盒測試, 描述了任務和訓練算法中體現的脆弱程度。 無論是學習任務還是訓練算法,我們都觀測到了性能的顯著下降,即使對抗干擾微小到無法被人類察覺的程度。
深度學習和深度強化學習最近的進展使得涵蓋了從原始輸入到動作輸出的end-to-end學習策略變為可能。深度強化學習算法的訓練策略已經在Atari 游戲和圍棋中取得了驕人的成績,展現出復雜的機器操縱技巧,學習執行了運動任務,并在顯示世界中進行了無人駕駛。
這些策略由神經網絡賦予了參數,并在監督式學習中表現出對于對抗性攻擊的脆弱性。例如,對訓練用于分類圖像的卷積神經網絡,添加進入輸入圖像的干擾可能會引起網絡對圖像的誤分,而人類卻看不出加入干擾前后的圖像有何不同。論文中,我們會研究經過深度強化學習訓練的神經網絡策略,是否會受到這樣的對抗樣本的影響。
不同于在學習過程中處理修正后的訓練數據集的監督式學習,在增強式學習中,這些訓練數據是在整個訓練過程中逐漸被收集起來的。換句話說,用于訓練策略的算法,甚至是策略網絡加權的隨機初始態,都會影響到訓練中的狀態和動作。不難想象,根據初始化和訓練方式的不同,被訓練做相同任務的策略,可能大相徑庭(比如從原始數據中提取高級特征)。因此,某些特定的學習算法可能導致出現較為不受對抗樣本影響的策略。可以想象,監督式學習和增強式學習的不同可能會防止對抗性攻擊在黑盒測試環境下發生作用,因為攻擊無法進入目標策略網絡。
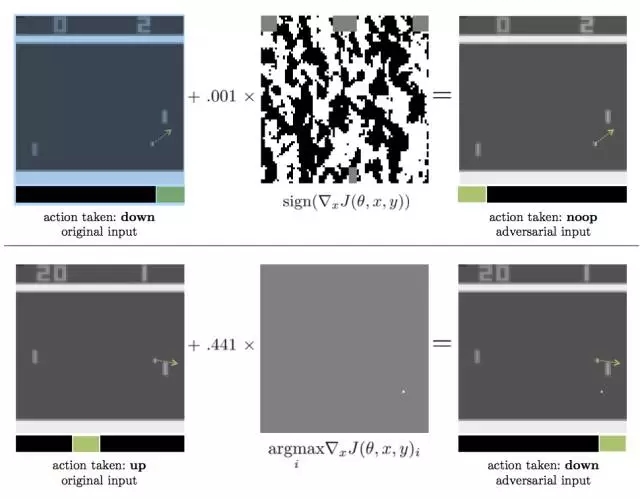
圖表1:產生對抗樣本的兩種方法,適用于借助DQN算法玩PONG游戲來進行策略訓練。點形箭頭從小球開始,表明了其運動方向,綠色的箭頭則強調了對于特定輸入來說較大化Q值的action。兩種情況下,對于原始輸入,策略都采取了好的action,但對抗性干擾都造成了小球和點的遺失。
上圖:對抗性樣本使用FGSM構造,對抗干擾帶有l∞-norm constraint;轉化為8-bit的圖像編碼率后,對抗性輸入和原始輸入相等,但仍然影響了性能。
下圖:對抗性樣本使用FGSM構造,對抗干擾帶有l∞-norm constraint;最優干擾是在真實的小球下方創造一個“假的”小球。
我們的主要貢獻是描寫了兩個因素對于對抗樣本的作用效果:用于學習策略的深度強化學習算法,以及對抗性攻擊自己是否能進入策略網絡(白盒測試vs.黑盒測試)。我們首先分析了對4種Atari games的3類白盒攻擊,其中游戲是經過3種深度強化學習算法訓練過的(DQN、TRPO和A3C)。我們論證了,整體上來說,這些經訓練的策略對于對抗樣本是脆弱的。然而,經過TRPO和A3C訓練的策略似乎對于對抗樣本的抵抗性更好。圖表1顯示了在測試時的特定一刻,兩個對經過DQN訓練的Pong策略的對抗性攻擊樣本。
接著,我們考察了對于相同策略的黑盒攻擊,前提是我們假設對抗性攻擊進入到了訓練環境(例如模擬器),但不是目標策略的隨機初始態,而且不知道學習策略是什么。在計算機視覺方面,Szegedy等人觀測到了可傳遞特性:一個設計用于被一種模型誤分的對抗樣本經常會被其他經過訓練來解決相同問題的模型誤分。我們觀測到在強化學習應用中,整個數據集里也存在這樣的可傳遞特性,即一個設計用于干擾某種策略運行的對抗樣本也會干擾另一種策略的運行,只要這些策略是訓練用于解決同樣的問題。特別的,我們觀測到對抗樣本會在使用不同trajectory rollouts算法進行訓練的模型之間傳遞,會在使用不同訓練算法進行訓練的模型之間傳遞。
下面介紹一下關于實驗的基本情況。
我們在 Arcade Learning Environment 模擬器中評估了針對4種Atari 2600游戲的對抗性攻擊,四種游戲是:Chopper Command, Pong, Seaquest, and Space Invaders.
我們用3種深度強化學習算法對每個游戲進行了訓練:A3C、TRPO和DQN。
對于DQN,我們使用了與附錄1相同的前處理和神經網絡結構。我們也把這一結構用于經A3C和TRPO訓練的隨機策略。需要指出,對神經網絡策略的輸入是最后4副圖像的連續體,從RGB轉換為Luminance(Y),大小修改為to 84 × 84。Luminance value被定義為從0到1。策略的輸出所有可能的action的分布。
對于每個游戲和訓練算法,我們從不同的隨機初始態開始訓練了5個策略。我們主要關注了表現較好的訓練策略(我們的定義是那些在最后10次訓練迭代中拿到較大分數的80%的策略)。我們最終為每個游戲和訓練算法選取了3個策略。有一些特定組合(比如Seaquest和A3C)僅有一條策略達到要求。
我們在rllab框架內部進行了實驗,使用了TRPO的rllab 平行版本,并整合了DQN和A3C。我們使用OpenAI Gym enviroments作為Arcade Learning Environment的交互界面。
我們在 Amazon EC2 c4.8x large machines上用TRPO和A3C進行了策略訓練。運行TRPO時每100,000步有2000次迭代,用時1.5到2天。KL散度設在0.01;運行A3C時,我們使用了18 actor-learner threads,learning rate是0.0004。對于每個策略,每1,000,000步進行200次迭代,耗時1.5到2天;運行DQN時,我們在Amazon EC2 p2.xlarge machines上進行策略訓練。每代 100000步,訓練2天。
這一研究方向對于神經網絡策略在線上和現實世界的布局都有顯著意義。我們的實驗證明,即使在黑盒測試中,使用特定對抗樣本仍然可以較輕易地“愚弄”神經網絡策略。這些對抗性干擾在現實世界中也可能發生作用,比如在路面上特意添加的色塊可能會搞暈遵循車道策略的無人駕駛汽車。因此,未來工作的一個重要方向就是發展和對抗性攻擊相抵抗的防范措施,這可能包括在訓練時增加對抗性干擾的樣本,或者在測試時偵測對抗性輸入。
論文地址:https://arxiv.org/pdf/1702.02284.pdf
參考文獻
[1] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller. Playing atari with deep reinforcement learning. In NIPS Workshop on Deep Learning, 2013.
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4465.html
摘要:論文可遷移性對抗樣本空間摘要對抗樣本是在正常的輸入樣本中故意添加細微的干擾,旨在測試時誤導機器學習模型。這種現象使得研究人員能夠利用對抗樣本攻擊部署的機器學習系統。 現在,卷積神經網絡(CNN)識別圖像的能力已經到了出神入化的地步,你可能知道在 ImageNet 競賽中,神經網絡對圖像識別的準確率已經超過了人。但同時,另一種奇怪的情況也在發生。拿一張計算機已經識別得比較準確的圖像,稍作調整,...
摘要:據報道,生成對抗網絡的創造者,前谷歌大腦著名科學家剛剛正式宣布加盟蘋果。他將在蘋果公司領導一個機器學習特殊項目組。在加盟蘋果后會帶來哪些新的技術突破或許我們很快就會看到了。 據 CNBC 報道,生成對抗網絡(GAN)的創造者,前谷歌大腦著名科學家 Ian Goodfellow 剛剛正式宣布加盟蘋果。他將在蘋果公司領導一個「機器學習特殊項目組」。雖然蘋果此前已經縮小了自動駕駛汽車研究的規模,但...
摘要:作者在論文中將這種新的譜歸一化方法與其他歸一化技術,比如權重歸一化,權重削減等,和梯度懲罰等,做了比較,并通過實驗表明,在沒有批量歸一化權重衰減和判別器特征匹配的情況下,譜歸一化改善生成的圖像質量,效果比權重歸一化和梯度懲罰更好。 就在幾小時前,生成對抗網絡(GAN)的發明人Ian Goodfellow在Twitter上發文,激動地推薦了一篇論文:Goodfellow表示,雖然GAN十分擅長...
摘要:是世界上最重要的研究者之一,他在谷歌大腦的競爭對手,由和創立工作過不長的一段時間,今年月重返,建立了一個探索生成模型的新研究團隊。機器學習系統可以在這些假的而非真實的醫療記錄進行訓練。今年月在推特上表示是的,我在月底離開,并回到谷歌大腦。 理查德·費曼去世后,他教室的黑板上留下這樣一句話:我不能創造的東西,我就不理解。(What I cannot create, I do not under...
摘要:我仍然用了一些時間才從神經科學轉向機器學習。當我到了該讀博的時候,我很難在的神經科學和的機器學習之間做出選擇。 1.你學習機器學習的歷程是什么?在學習機器學習時你最喜歡的書是什么?你遇到過什么死胡同嗎?我學習機器學習的道路是漫長而曲折的。讀高中時,我興趣廣泛,大部分和數學或科學沒有太多關系。我用語音字母表編造了我自己的語言,我參加了很多創意寫作和文學課程。高中畢業后,我進了大學,盡管我不想去...

閱讀 2770·2021-11-17 09:33
閱讀 3092·2021-10-25 09:44
閱讀 1200·2021-10-11 10:59
閱讀 2396·2021-09-27 13:34
閱讀 2905·2021-09-07 10:19
閱讀 2133·2019-08-29 18:46
閱讀 1535·2019-08-29 12:55
閱讀 928·2019-08-23 17:11






