資訊專欄INFORMATION COLUMN

摘要:深度神經網絡已經成為解決計算機視覺語音識別和自然語言處理等機器學習任務的較先進的技術。圖深度壓縮的實驗結果訓練深度神經網絡可以被大量剪枝和壓縮的事實意味著我們當前的訓練方法具有一些局限性。
深度神經網絡已經成為解決計算機視覺、語音識別和自然語言處理等機器學習任務的較先進的技術。盡管如此,深度學習算法是計算密集型和存儲密集型的,這使得它難以被部署到只有有限硬件資源的嵌入式系統上。
為了解決這個限制,可以使用深度壓縮來顯著地減少神經網絡所需要的計算和存儲需求。例如對于具有全連接層的卷積神經網絡(如Alexnet和VGGnet),深度壓縮可以將模型大小減少35到49倍。即使對于全卷積神經網絡(如GoogleNet和SqueezeNet),深度壓縮也可以將模型大小減少10倍。而且上述兩種壓縮情況都不會降低模型預測的精度。
當前的訓練方法有不足之處
壓縮模型而不丟失其較精確度意味著在訓練好的模型中有嚴重的冗余,這說明當前的訓練方法有不足之處。為了解決這個問題,我和來自NVIDIA的JeffPool、百度的Sharan Narang和Facebook的Peter Vajda合作開發了“密集-稀疏-密集”(DSD)的訓練方法。這是一種新的方法,它首先通過稀疏約束的優化方法將模型正則化,然后通過恢復和重新訓練被剪枝的連接的權重來提高預測精度。在測試時,由DSD訓練得到的最終模型仍然跟原始密集型模型具有相同的架構和維度,并且DSD訓練不會增加任何推理開銷。我們對主流的神經網絡(如CNN / RNN / LSTM)架構用DSD訓練方法進行了圖像分類、圖像描述和語音識別的實驗,發現模型有顯著的性能改進。
在本文中,我們會首先介紹深度壓縮,然后介紹“密集-稀疏-密集”(DSD)訓練方法。
深度壓縮
深度壓縮的第一步是“突觸剪枝”。 人類大腦是有這一剪枝過程的。從嬰兒時期到成年,人腦會有5成的突觸會被修剪掉。
類似的規則是否適用于人工神經網絡呢?答案是肯定的。在早期的工作中,網絡剪枝已經被證明是一種減少網絡復雜度和過度擬合的有效方法。這種方法也適用于現代神經網絡。首先我們通過常規神經網絡訓練來學習網絡連接權重。然后我們會剪枝權重值較小的連接:即刪除網絡中權重值低于某一閾值的所有連接。最后,我們重新訓練網絡,得到剩余稀疏連接的權重值。剪枝方法使AlexNet和VGG-16模型的參數數量分別減少了9倍和13倍。

圖1. 剪枝一個神經網絡。所有圖片由Song Han 友情提供
深度壓縮的下一步是權重共享。我們發現神經網絡對低精度權重值具有非常高的容忍度:極度粗略的權重值并不會降低預測精度。如圖2所示,藍色權重值最初為2.09、2.12、1.92和1.87,然后讓它們共享相同的權重值2,網絡的預測較精確度仍然不受影響。因此我們可以只存儲非常少量的權重值,稱之為“編碼本”。并讓許多其他權重共享這些相同的權重值,且只在碼本中存儲其索引即可。
索引可以用非常少的比特數來表示。例如在下圖中存在四種顏色,因此僅需要兩位來表示一個權重而不用原來的32位。另一方面,編碼本占用的存儲空間幾乎可以忽略不計。我們的實驗發現,就權衡壓縮比和精度而言,這種權重共享技術是優于線性量化的方法的。
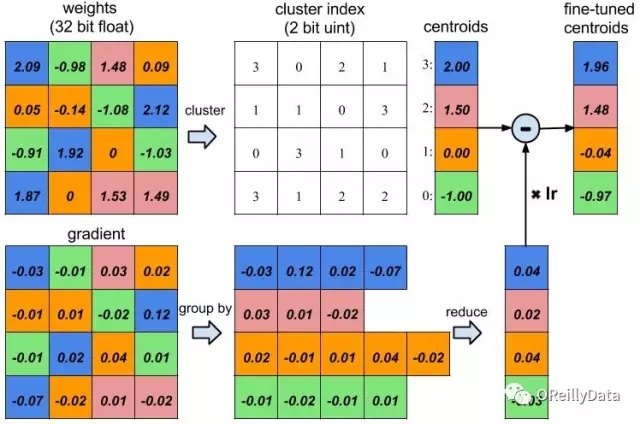
圖2. 訓練權重共享的神經網絡
圖3顯示了使用深度壓縮的總體結果。Lenet-300-100和Lenet-5是在MNIST數據集上評估的,而AlexNet、VGGNet、GoogleNet和SqueezeNet是在ImageNet數據集上評估的。壓縮比從10倍到49倍不等。即使對于那些全卷積神經網絡(如GoogleNet和SqueezeNet),深度壓縮仍然可以將它們壓縮一個數量級。我們重點看一下SqueezeNet,它比有相同預測精度的AlexNet少50倍的參數,但仍然還可以再壓縮10倍使其模型大小只有470KB,這使它可以很容易地在片上SRAM里使用。而訪問SRAM比DRAM更快更節能。
我們還嘗試了其他壓縮方法,例如基于低秩近似的方法,但是壓縮比沒有那么高。你可以在Deep Compression的論文中找到完整的討論。
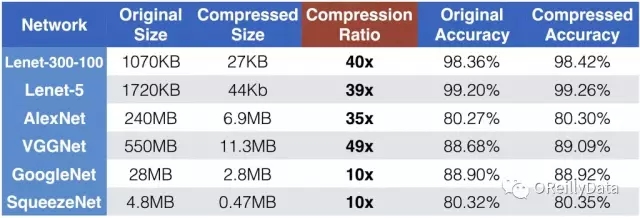
圖3 深度壓縮的實驗結果
DSD訓練
深度神經網絡可以被大量剪枝和壓縮的事實意味著我們當前的訓練方法具有一些局限性。它不能充分利用密集模型的全部容量來找到較佳局部最小值,而一個剪枝過的有著更少神經突觸的稀疏模型也可以達到相同的精度。這帶來了一個問題:我們是否可以通過恢復并重新學習這些權重來達到更好的精度嗎?
讓我們拿奧運會田徑比賽的訓練做個比喻。教練首先會讓跑步運動員在高海拔的山地上訓練,那里會有很多的限制:低氧、寒冷等。結果當跑步運動員再次返回平原地區時,他的速度就會有提高。對于神經網絡來說也是相同的道理:給定嚴格約束的稀疏訓練方法得到的網絡模型有跟密集網絡模型一樣的性能。一旦你解除了這些約束,模型可以工作得更好。
理論上,以下是DSD訓練能行之有效的因素:
1.避開鞍點:
優化深度網絡較大的困難之一是鞍點的擴散。 DSD訓練方法通過剪枝和重新密集化的框架來避開鞍點。對收斂的模型做剪枝干擾了模型學習的模式并使得網絡模型能夠避開鞍點,這使模型有機會可以收斂到一個更好的局部或全局最小值。這個想法也跟“模擬退火”算法類似。雖然模擬退火算法在搜索圖上隨著概率降低而隨機跳躍,但是DSD訓練方法會確定性的偏離收斂值。這一收斂值是通過在第一次密集模型訓練階段中去除小權重值和增強稀疏支持得到的。
2.正規化和稀疏訓練:
稀疏訓練步驟中的稀疏正規化將模型優化降維到較低維空間,在這個空間中的損失函數表面更平滑并且對噪聲更魯棒。很多數值實驗證實了稀疏訓練和最終DSD方法可以降低方差和減少誤差。
3. 強大的重新初始化:
權重初始化在深度學習中起著重要的作用。傳統的訓練方法只有一次初始化的機會,而DSD方法在訓練過程中給模型優化第二次(或更多)的機會。它基于更魯棒的稀疏訓練結果來重新初始化。我們基于稀疏模型結果來重新構建密集網絡,這可以理解為剪枝權重的零初始化。其它的初始化方法也值得嘗試。
4. 打破對稱性:
隱藏單元的置換對稱性會使權重對稱,因此在訓練中容易相互影響。在DSD方法中,權重剪枝打破了與權重相關的隱藏單元的對稱性,而且在最終的密集模型中是不對稱的。
我們在幾個主流的CNN/RNN/LSTM模型上進行了圖像分類、圖像描述和語音識別數據集的實驗,發現這種“密集-稀疏-密集”的訓練流程能夠顯著地提高模型精度。我們的DSD訓練方法采用了三個步驟:密集,稀疏,密集。圖4展示了每個步驟。
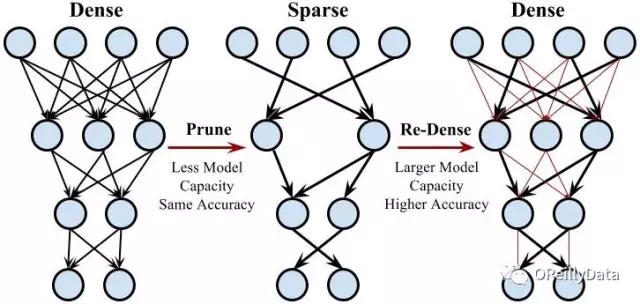
圖4 密集-稀疏-密集的訓練流程
1.初始的密集訓練:
第一個“密集”步驟通過在密集網絡上的常規網絡訓練來學習連接權重。然而跟傳統訓練不同的是,該“密集”步驟的目的不是學習連接權重的最終值,而是學習哪些連接是重要的。
2. 稀疏訓練:
“稀疏”步驟會剪枝掉權重值較低的連接并重新訓練稀疏網絡。我們對試驗中的所有層都使用相同的稀疏度,因此會有一個單一的超參數:稀疏度(sparsity)。我們對每一層的參數進行排序,從網絡中去掉最小的N* sparsity個稀疏參數,將密集網絡轉換為稀疏網絡。我們發現稀疏比率為50%-70%的效果非常好。然后我們重新訓練稀疏網絡,這可以在稀疏約束下完全復原模型的精度。
3. 最終的密集訓練:
最后的“密集”步驟會恢復已剪枝的連接,使網絡再次變的密集。這些之前剪枝的連接會初始化為零并重新訓練。恢復被剪枝的連接增加了網絡的維度,并且更多的參數更容易使網絡的鞍點向下滑動以獲得更好的局部最小值。
我們將DSD訓練方法應用于各種類型的神經網絡和不同領域的數據集。 我們發現DSD訓練方法提高了所有這些神經網絡的較精確度。 神經網絡選自CNN、RNN和LSTM;數據集是從圖像分類、語音識別和圖像描述領域中選擇的, 結果如圖5所示。DSD模型可以在DSD Model Zoo上下載。

圖 5. DSD訓練提高了預測精度
生成圖像描述
我們把在圖像描述任務中使用DSD訓練方法的效果做了可視化(見圖6)。我們把DSD訓練方法應用于NeuralTalk中,NeuralTalk是一個用于生成圖像自然語言描述的長短時記憶模型(LSTM)。基準模型不能很好的描述圖片1、4和5。例如圖片1,基準模型將女孩錯誤地描述為男孩,并且把女孩的頭發錯誤地描述為巖墻。稀疏模型可以在圖片中識別出有一個女孩,而DSD模型可以進一步識別出秋千。
在第二張圖片中,DSD訓練方法可以識別出運動員正在嘗試投籃,而基準模型只能描述成運動員正在打球。值得注意的是稀疏模型有時比DSD 模型表現得更好。在最后一張圖片中,稀疏模型能夠正確地識別出泥潭,而DSD模型只能從背景中識別出森林。DSD訓練方法的優良性能不僅限于這些例子,此論文的附錄中提供了更多的由DSD訓練方法生成的圖像描述結果。

圖6. DSD訓練方法提高圖像描述的性能的可視化展現
稀疏模型的優點
用于把深度神經網絡壓縮為較小模型的深度壓縮和用于神經網絡正則化的DSD訓練方法都是利用模型稀疏性來實現更小的模型或者更高的預測精度的技術。除了模型大小和預測精度,我們還研究了可以利用稀疏性的其他兩個方面:速度和能耗,這超出了本文的討論范圍。讀者可以查看EIE論文作為進一步的參考。

Song Han
Song Han是斯坦福大學Bill Dally教授的5年級博士生。他專注于機器學習和計算機體系架構的交叉領域的節能深度學習。Song提出的深度壓縮技術可以將較先進的卷積神經網絡模型的大小壓縮10倍到49倍,也可以把SqueezeNet壓縮到只有470KB,這使得模型完全可用于片上SRAM上。他提出的DSD訓練流程提高了很多神經網絡的預測精度。他設計的EIE(高效推理引擎)是在壓縮的稀疏神經網絡模型上直接推理的硬件架構體系,這種引擎比GPU的速度提高了13倍而能耗降低了3000倍。他的工作已經在TheNextPlatform、TechEmergence、Embedded Vision和O"Reilly上發表。并且他的論文獲得了ICLR’16的較佳論文獎。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4452.html
摘要:淺層結構化預測方法有損失的條件隨機域,有的較大邊緣馬爾可夫網絡和隱支持向量機,有感知損失的結構化感知深層結構化預測圖變換網絡圖變換網絡深度學習上的結構化預測該圖例展示了結構化感知損失實際上,使用了負對數似然函數損失于年配置在支票閱讀器上。 卷積網絡和深度學習的動機:端到端的學習一些老方法:步長內核,非共享的本地連接,度量學習,全卷積訓練深度學習缺少什么?基礎理論推理、結構化預測記憶有效的監督...
摘要:為了使的思想更具體化,現在我們來看一下在深度神經網絡中執行多任務學習的兩種最常用的方法。圖深度神經網絡多任務學習的參數共享共享參數大大降低了過擬合的風險。 目錄1.介紹2.動機3.兩種深度學習 MTL 方法Hard 參數共享Soft 參數共享4.為什么 MTL 有效隱式數據增加注意力機制竊聽表征偏置正則化5.非神經模型中的 MTL塊稀疏正則化學習任務的關系6.最近 MTL 的深度學習研究深度...
摘要:近來在深度學習中,卷積神經網絡和循環神經網絡等深度模型在各種復雜的任務中表現十分優秀。機器學習中最常用的正則化方法是對權重施加范數約束。 近來在深度學習中,卷積神經網絡和循環神經網絡等深度模型在各種復雜的任務中表現十分優秀。例如卷積神經網絡(CNN)這種由生物啟發而誕生的網絡,它基于數學的卷積運算而能檢測大量的圖像特征,因此可用于解決多種圖像視覺應用、目標分類和語音識別等問題。但是,深層網絡...
摘要:近日,谷歌大腦發布了一篇全面梳理的論文,該研究從損失函數對抗架構正則化歸一化和度量方法等幾大方向整理生成對抗網絡的特性與變體。他們首先定義了全景圖損失函數歸一化和正則化方案,以及最常用架構的集合。 近日,谷歌大腦發布了一篇全面梳理 GAN 的論文,該研究從損失函數、對抗架構、正則化、歸一化和度量方法等幾大方向整理生成對抗網絡的特性與變體。作者們復現了當前較佳的模型并公平地對比與探索 GAN ...

閱讀 3477·2021-09-06 15:13
閱讀 1527·2021-09-02 10:19
閱讀 2473·2019-08-30 15:52
閱讀 918·2019-08-29 15:25
閱讀 1565·2019-08-26 18:36
閱讀 495·2019-08-26 13:23
閱讀 1331·2019-08-26 10:46
閱讀 3498·2019-08-26 10:41





