資訊專欄INFORMATION COLUMN

摘要:得到的結果如下上圖是門卷積神經網絡模型與和模型在數(shù)據(jù)集基準上進行測試的結果。雖然在這一研究中卷積神經網絡在性能上表現(xiàn)出了對遞歸神經網絡,尤其是的全面超越,但是,現(xiàn)在談取代還為時尚早。
語言模型對于語音識別系統(tǒng)來說,是一個關鍵的組成部分,在機器翻譯中也是如此。近年來,神經網絡模型被認為在性能上要優(yōu)于經典的 n-gram 語言模型。經典的語言模型會面臨數(shù)據(jù)稀疏的難題,使得模型很難表征大型的文本,以及長距離的依存性。神經網絡語言模型通過在連續(xù)的空間中嵌入詞語的方法,來解決這一難題。目前,語言建模的較好表現(xiàn)是基于長短記憶網絡(LSTM,1997年由Hochreiter和Schmidhuber提出)的,它能對潛在的任意長期依存進行建模。
算法模型的突破意義在哪
Facebook AI 實驗室的這一研究在發(fā)表后吸引了大量的注意力。LSTM目前在語言、語音和翻譯等方面有著廣泛的應用,是學術和產業(yè)都十分關注的技術,現(xiàn)在忽然出現(xiàn)了一種比它更好的模型,AI 圈內人士怎么看?
美國卡內基梅隆計算機系博士鄧侃對新智元說:“這是 LSTM 的改進版,性能有所提高,但是方法論仍然沿用了 LSTM 的既有框架,并沒有本質突破。”
國內語音技術專家賈磊也與新智元分享了他的觀點。他說:“CNN有一個優(yōu)點,就是通過共享權重由局部到整體,實現(xiàn)對輸入‘whole picture’ 的建模;而LSTM是通過逐幀遞推的方式來建模整體,而遞推過程中引入“門機制”進行信息選擇。”
他解釋說:“通俗一點說,CNN更像視覺,天然具有二維整體性;而LSTM更像聽覺和語音,總是通過串行的方式來理解整體。Facebook的這篇論文恰恰是通過在CNN技術中引入LSTM的“門機制”來解決語言順序依存問題,是對傳統(tǒng)cnn技術很大的豐富和完善,文章具有很高的理論價值和實踐意義。但是到目前為止,CNN是否會取代LSTM,即全局共享權重連接是不是真的能夠完全取代帶有遞推機制和門機制的LSTM,形式還并不明朗。特別在一些高時效性的語音識別和語音交互問題上,由于嚴格的時效要求,LSTM這種隨著時間的延展,逐步遞推,逐漸遍及信號全貌的技術,還是有一定速度優(yōu)勢的。”
模型詳情
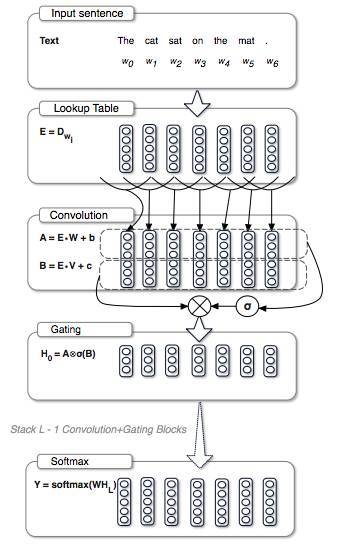
圖 : 用于語言建模的門卷積網絡架構
統(tǒng)計學意義的語言模型評估的是詞語序列的概率分布。這導致了傾向于根據(jù)正在處理的詞語對下一個詞語出現(xiàn)的概率進行建模的方法。目前,語言建模的主要方法都是基于遞歸神經網絡的。Facebook AI 研究院 提出了一個卷積的方法,來為語言建模。他們引入了一個新的門機制(gating mechanism),能夠釋放梯度傳播,同時比Oord 等人在2016年提出的 LSTM 風格的 gating 性能上要好很多,并且還更加簡單。
門(gating)機制控制著神經網絡中的信息流動,在1997年時就被 Schmidhuber等人證明在遞歸神經網絡中非常有用。LSTM通過一個由輸入控制的多帶帶單元(cell)和forget gates來激活長期記憶,這能讓信息在多個時間點可以無阻礙地流動。如果沒有這些門的存在,信息在每一個時間點上的變化可能會導致消失的情況。相反地,卷積神經網絡并不會存在梯度消失的問題,在實驗中,我們發(fā)現(xiàn),他們并不要求有forget gates。
在論文摘要中,他們寫道:“在WikiText-103上,我們創(chuàng)造了新的記錄。同時,在谷歌 Billion Word 基準上,我們也獲得了單個 GPU 的較佳表現(xiàn)。在設置中,延遲非常重要,比起遞歸機制的基線,我們的模型獲得了一個維度的加速,因為計算能夠多次并行運行。據(jù)我們所知,這是此類的任務中,一個非遞歸性的方法首次在性能上超越了向來強大的遞歸模型。”
測試結果
研究者基于兩個大型數(shù)據(jù)集——WikiText-103和谷歌 Billion Word(GBW)進行測試,并與幾個強大的 LSTM 和RNN 模型性能進行橫向對比。得到的結果如下:
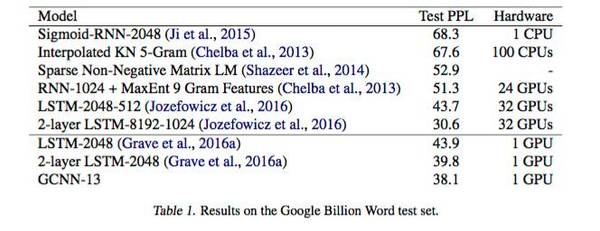
上圖是門卷積神經網絡(GCNN)模型與LSTM和RNN 模型在 Billion Word(GBW)數(shù)據(jù)集基準上進行測試的結果。在單個GPU的情況下,GCNN的性能做到了較好。并且,據(jù)Facebook 研究者在論文中介紹,他們使用的 GCNN-13 模型擁有13層神經網絡、每層包含1268個單元,LSTM每層擁有1024個單元。在與多GPU 進行對比時,只有超大型LSTM模型在性能上比GCNN好。但是,超大型LSTM -2048 (代表層數(shù))使用了32個GPU,訓練時間為3周,GCNN只使用1個GPU,訓練時間1周。
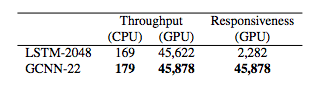
?另一個橫向對比是在WikiText-103 上進行的,這個語言建模數(shù)據(jù)庫包含了超過1億個從Wikepedia 上被標注為Good 或者Featured的文章中提取的字符(tokens),另外,數(shù)據(jù)庫中還包含了20萬個單詞的詞匯表。
在這個數(shù)據(jù)集進行測試時,輸入的序列是一篇完整的Wikipedia 文章,而不僅僅是一句話。上圖的結果表明。GCNN 模型在這個問題上的性能也比LSTM要好得多。
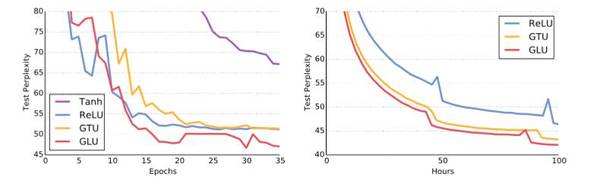
上圖是WikiText-103(左)和 Google Billion Word (右) 的在不同激活機制模型下的學習曲線。可以看到,門線性單元(GLU,圖中紅線)在實現(xiàn)向更低的復雜性轉換的過程是最快的。
被超越的 LSTM
LSTM 和遞歸神經網絡能捕捉長期的依存性,在被提出后便以席卷之勢迅速成為自然語言處理的奠基石。LSTM可以記憶不定時間長度的數(shù)值,區(qū)塊中有一個Gate能夠決定input是否重要到能被記住及能不能被輸出output。
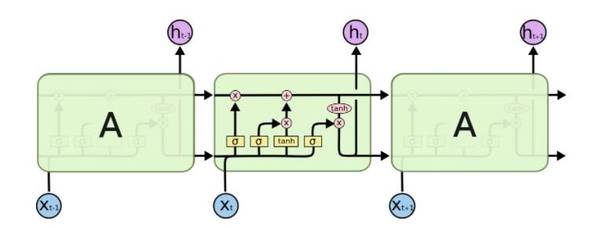
LSTM 模型的基本架構,其中中間四個相互交互的層,是整個模型的核心
此外,由于LSTM 適用于處理和預測時間序列中間隔和延遲非常長的重要事件。因而在自然語言理解(NLU)上有著重要作用。
LSTM 目前在行業(yè)內有著廣泛的應用,范圍包括但不限于:不分段連續(xù)手寫識別上、自主語音識別、機器翻譯等等。作為非線性模型,LSTM可作為復雜的非線性單元用于構造更大型深度神經網絡。
2009年,用LSTM構建的人工神經網絡模型贏得過ICDAR手寫識別比賽冠軍。LSTM還普遍用于自主語音識別,2013年運用 TIMIT 自然演講數(shù)據(jù)庫達成17.7%錯誤率的紀錄。?
研究者的自我評價
在論文的最后,研究者總結說,我們(Facebook)發(fā)布了一個卷積的神經網絡,使用一個新的門機制來為語言建模。與遞歸神經網絡相比,我們的方法建立了一個輸入詞語的層級表征,讓它可以更好地捕獲長距離的依存性(dependencies),這和語言學中語法形式體系中的樹結構分析的思路很像。由于特征通過的是固定數(shù)量的神經網絡層,并且是非線性的,這種相似的屬性夠產生學習。這和遞歸神經網不同,遞歸神經網絡中,處理步驟的數(shù)量根據(jù)詞在輸入中的位置會有所不同。
結果顯示,我們的門卷積神經網絡在WikiText-103 上打破了記錄,在更大型的谷歌Billion Word 基準中,單一GPU上的模型訓練表現(xiàn)也優(yōu)于其他幾個強大的 LSTM 模型。
不談取代,我們談談優(yōu)化
正如上文中專家的分析,在語言建模上,現(xiàn)在卷積神經網絡和遞歸神經網絡各自有不同優(yōu)勢。雖然在這一研究中卷積神經網絡在性能上表現(xiàn)出了對遞歸神經網絡,尤其是LSTM的全面超越,但是,現(xiàn)在談取代還為時尚早。
算法模型的演進是不斷優(yōu)化的漸進過程,F(xiàn)acebook帶來了一種新的思路,并且在研究中進行了驗證,究其意義,正如作者在論文中介紹的那樣:一個非遞歸性的方法首次在性能上超越了向來強大的遞歸模型。但是,算法模型到底只是工具,并不存在真正的“取代”之爭。對于實際應用來說,還是要看效果。該模型對于整個產業(yè)應用的意義,目前來看還有待驗證,畢竟LSTM現(xiàn)在已經得到了廣泛的應用,并且效果還不錯。
論文地址:https://arxiv.org/pdf/1612.08083v1.pdf
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4451.html
摘要:本文將詳細解析深度神經網絡識別圖形圖像的基本原理。卷積神經網絡與圖像理解卷積神經網絡通常被用來張量形式的輸入,例如一張彩色圖象對應三個二維矩陣,分別表示在三個顏色通道的像素強度。 本文將詳細解析深度神經網絡識別圖形圖像的基本原理。針對卷積神經網絡,本文將詳細探討網絡 中每一層在圖像識別中的原理和作用,例如卷積層(convolutional layer),采樣層(pooling layer),...
摘要:但是,有一些研究人員在同一個深度神經網絡中巧妙地實現(xiàn)了二者能力的結合。一次讀取并解釋輸入文本中的一個字或字符圖像,因此深度神經網絡必須等待直到當前字的處理完成,才能去處理下一個字。 從有一些有趣的用例看,我們似乎完全可以將 CNN 和 RNN/LSTM 結合使用。許多研究者目前正致力于此項研究。但是,CNN 的研究進展趨勢可能會令這一想法不合時宜。一些事情正如水與油一樣,看上去無法結合在一起...
摘要:通過兩年的發(fā)展,今天我們可以肯定地說放棄你的和有證據(jù)表明,谷歌,,等企業(yè)正在越來越多地使用基于注意力模型的網絡。 摘要: 隨著技術的發(fā)展,作者覺得是時候放棄LSTM和RNN了!到底為什么呢?來看看吧~ showImg(https://segmentfault.com/img/bV8ZS0?w=800&h=533); 遞歸神經網絡(RNN),長期短期記憶(LSTM)及其所有變體: 現(xiàn)在是...
摘要:接上文深度學習和的聯(lián)合綜述上卷積神經網絡卷積神經網絡被設計用來處理到多維數(shù)組數(shù)據(jù)的,比如一個有個包含了像素值圖像組合成的一個具有個顏色通道的彩色圖像。近年來,卷積神經網絡的一個重大成功應用是人臉識別。 三大牛Yann LeCun、Yoshua Bengio和Geoffrey Hinton在深度學習領域的地位無人不知。為紀念人工智能提出60周年,的《Nature》雜志專門開辟了一個人工智能 +...
摘要:表示學習和深度學習的興起是密切相關。自然語言處理中的深度學習在自然語言的表示學習中提及深度學習這是因為深度學習首要的用處就是進行自然語言的表示。圖是深度學習在自然語言理解中應用描述。 本文根據(jù)達觀數(shù)據(jù)特聘專家復旦大學黃萱菁教授在達觀數(shù)據(jù)舉辦的長三角人工智能應用創(chuàng)新張江峰會上的演講整理而成,達觀數(shù)據(jù)副總裁魏芳博士統(tǒng)稿 一、概念 1 什么是自然語言和自然語言理解? 自然語言是指漢語、英語、...

閱讀 2967·2021-11-25 09:43
閱讀 3586·2021-11-24 11:13
閱讀 3354·2021-10-14 09:42
閱讀 2555·2021-09-23 11:53
閱讀 3605·2021-09-22 15:57
閱讀 3221·2021-09-02 09:54
閱讀 3499·2019-08-30 13:47
閱讀 1638·2019-08-29 16:55






