資訊專欄INFORMATION COLUMN

摘要:但是,有一些研究人員在同一個(gè)深度神經(jīng)網(wǎng)絡(luò)中巧妙地實(shí)現(xiàn)了二者能力的結(jié)合。一次讀取并解釋輸入文本中的一個(gè)字或字符圖像,因此深度神經(jīng)網(wǎng)絡(luò)必須等待直到當(dāng)前字的處理完成,才能去處理下一個(gè)字。
從有一些有趣的用例看,我們似乎完全可以將 CNN 和 RNN/LSTM 結(jié)合使用。許多研究者目前正致力于此項(xiàng)研究。但是,CNN 的研究進(jìn)展趨勢(shì)可能會(huì)令這一想法不合時(shí)宜。

一些事情正如水與油一樣,看上去無(wú)法結(jié)合在一起。雖然兩者各具價(jià)值,但它們無(wú)法結(jié)合起來(lái)。
這就是我首次想到組合使用 CNN(卷積神經(jīng)網(wǎng)絡(luò))和 RNN(遞歸神經(jīng)網(wǎng)絡(luò))時(shí)的反應(yīng)。畢竟,二者分別針對(duì)完全不同類型的問(wèn)題做了優(yōu)化。 ?
CNN 適用于分層或空間數(shù)據(jù),從中提取未做標(biāo)記的特征。適用的數(shù)據(jù)可以是圖像,或是手寫體字符。CNN 接受固定規(guī)模的輸入,并生成固定規(guī)模的輸出。
RNN 適用于時(shí)態(tài)數(shù)據(jù)及其它類型的序列數(shù)據(jù)。數(shù)據(jù)可以是文本正文、股票市場(chǎng)數(shù)據(jù),或是語(yǔ)音識(shí)別中的字母和單詞。RNN 的輸入和輸出可以是任意長(zhǎng)度的數(shù)據(jù)。LSTM 是 RNN 的一種變體,它記憶可控?cái)?shù)量的前期訓(xùn)練數(shù)據(jù),或是以更適當(dāng)?shù)姆绞竭z忘。
對(duì)于一些特定的問(wèn)題類型,我們知道如何選取適當(dāng)?shù)墓ぞ摺?/p>
是否存在同時(shí)需要 CNN 和 RNN 能力的問(wèn)題?
事實(shí)證明,的確如此。其中大部分針對(duì)的是按時(shí)間序列出現(xiàn)的圖像數(shù)據(jù),換句話說(shuō),就是視頻數(shù)據(jù)。但還存在著其它一些有意思的應(yīng)用,它們與視頻并沒(méi)有任何直接關(guān)系,正是這些應(yīng)用激發(fā)了研究者的想象力。下面我們將介紹其中部分應(yīng)用。
還有一些近期提出的模型,它們探索了如何組合使用 CNN 和 RNN 工具。在很多情況下,CNN 和 RNN 可使用多帶帶的層進(jìn)行組合,并以 CNN 的輸出作為 RNN 的輸入。但是,有一些研究人員在同一個(gè)深度神經(jīng)網(wǎng)絡(luò)中巧妙地實(shí)現(xiàn)了二者能力的結(jié)合。
視頻場(chǎng)景標(biāo)記
經(jīng)典的場(chǎng)景標(biāo)記方法是訓(xùn)練 CNN 去識(shí)別視頻幀中的對(duì)象,并對(duì)這些對(duì)象分類。對(duì)象可能會(huì)進(jìn)一步分類為更高級(jí)別的邏輯組。例如,CNN 可以識(shí)別出爐子、冰箱和水槽等物品,進(jìn)而升級(jí)分類為廚房。
顯然,我們?nèi)鄙俚氖菍?duì)多個(gè)幀(在時(shí)間上)間動(dòng)作的理解。例如,幾幀臺(tái)球視頻就能正確表明擊球者已經(jīng)將八個(gè)球擊入了邊袋。另一個(gè)例子是如果有幾個(gè)幀分別是一些年輕人在練習(xí)騎行兩輪車,并且有一位騎手躺在地上,那么完全可以合理地得出結(jié)論:“那個(gè)男孩從兩輪車上摔了下來(lái)”。
有研究者實(shí)現(xiàn)了一種分層的 CNN-RNN 對(duì),以 CNN 的輸出作為 RNN 的輸入。為創(chuàng)建對(duì)每個(gè)視頻片段的“瞬間”描述,研究者從邏輯上以 LSTM 取代了 RNN。組合而成的 RCNN 模型如上圖所示,其中遞歸連接直接實(shí)現(xiàn)在內(nèi)核上。研究者最后對(duì)該 RCNN 模型做了一些實(shí)驗(yàn)驗(yàn)證。
細(xì)節(jié)內(nèi)容可參閱論文原文:http://proceedings.mlr.press/v32/pinheiro14.pdf
情緒檢測(cè)
如何通過(guò)視頻判斷個(gè)體或群體的情緒,這依然是一個(gè)挑戰(zhàn)性問(wèn)題。針對(duì)此問(wèn)題,ACM 國(guó)際多模式互動(dòng)會(huì)議(ICMI,International Conference on Multimodal Interaction)每年舉辦一屆競(jìng)賽,稱為“情緒大挑戰(zhàn)”(EGC,EmotiW Grand Challenge)。
每年 EGC 競(jìng)賽的目標(biāo)數(shù)據(jù)集會(huì)有一定變化。競(jìng)賽通常會(huì)給出一組不同的測(cè)試,對(duì)視頻中出現(xiàn)的人群或個(gè)體做分類。
2016 年:基于群體的幸福感分析。
2017 年: 基于群體的三類情緒(即正向、中立和負(fù)向)檢測(cè)。
2018 年的競(jìng)賽(計(jì)劃在 11 月開(kāi)展)將更為復(fù)雜。挑戰(zhàn)涉及就餐環(huán)境分類,其中包括三個(gè)子項(xiàng): ?
食物類型挑戰(zhàn):將每個(gè)表述(utterance)按七類食物做分類。
食物好感度挑戰(zhàn):識(shí)別對(duì)象對(duì)食物好感度的打分情況。
進(jìn)餐中交談挑戰(zhàn):識(shí)別進(jìn)餐中交談的難度等級(jí)。
挑戰(zhàn)的關(guān)鍵不僅在于如何組合使用 CNN 和 RNN,而且包括如何添加可多帶帶建模并集成的音軌數(shù)據(jù)。
2016 年競(jìng)賽的獲勝者創(chuàng)建了一個(gè)由 RNN 和 3D 卷積網(wǎng)絡(luò)(C3D)組成的混合網(wǎng)絡(luò)。和傳統(tǒng)方式一樣,數(shù)據(jù)融合和分類是在后期進(jìn)行的。RNN 以使用 CNN 從各個(gè)幀中提取的外觀特征作為輸入,并對(duì)隨后的運(yùn)動(dòng)做編碼。同時(shí),C3D 也對(duì)視頻中的外觀和運(yùn)動(dòng)進(jìn)行建模,隨后同樣與音頻模塊合并。
準(zhǔn)確性是 EGC 競(jìng)賽挑戰(zhàn)的難點(diǎn)所在,該指標(biāo)目前依然不是很高。2016 年的獲勝者在個(gè)體面部識(shí)別上的得分為 59.02%。2017 年則升至 60.34%,群組得分升至 80.89%。但應(yīng)注意的是,挑戰(zhàn)的性質(zhì)每年都會(huì)發(fā)生一些變化,因此不能按年度進(jìn)行比較。
EGC 年度競(jìng)賽挑戰(zhàn)的詳細(xì)信息可訪問(wèn) ICMI 官方主頁(yè):https://icmi.acm.org/2018/index.php?id=challenges
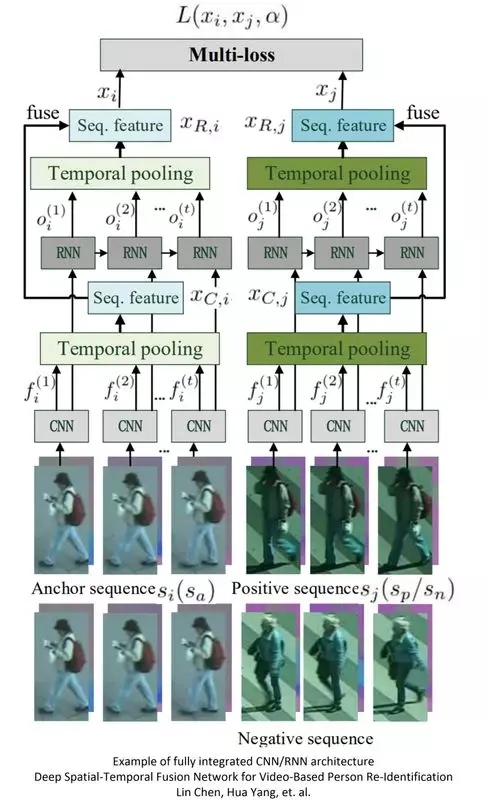
基于視頻的人員重識(shí)別 / 步態(tài)識(shí)別
該應(yīng)用的目標(biāo)是識(shí)別視頻中的某個(gè)人(根據(jù)已有的個(gè)人標(biāo)記數(shù)據(jù)庫(kù)),或者僅僅識(shí)別視頻是否曾經(jīng)出現(xiàn)過(guò)某人(即重識(shí)別,其中人員是未標(biāo)記的)。步態(tài)識(shí)別是該應(yīng)用的關(guān)鍵研究領(lǐng)域,進(jìn)而發(fā)展為全身運(yùn)動(dòng)識(shí)別(例如手臂擺動(dòng)方式、行走特征、體態(tài)等)。
該項(xiàng)應(yīng)用中存在一些明顯的非技術(shù)性挑戰(zhàn),其中最突出的問(wèn)題包括著裝和鞋子的變化、外套或全身衣物存在部分模糊等。CNN 中一些眾所周知的技術(shù)問(wèn)題包括多視角(實(shí)際上是一個(gè)人從左到右經(jīng)過(guò)所引發(fā)的多個(gè)視角,即第一視角是前面,然后是側(cè)面,最后是背面),以及照明情況、反照率和大小等經(jīng)典圖像問(wèn)題。
前期已有研究將一個(gè)完整的走步(即步態(tài))使用由 CNN 獲取的多個(gè)幀表示,進(jìn)而組合成一類稱為“步態(tài)能量圖像”(GEI,Gait Energy Image)的熱力圖。
為一并分析多個(gè)“走步”的情況,有研究在模型中加入了 LSTM。LSTM 的時(shí)序能力實(shí)現(xiàn)了幀間視圖變換模型,可用于調(diào)整透視的情況。
該研究原文及所用圖像數(shù)據(jù)提供于此:https://vision.unipv.it/CV/materiale2016-17/3rd%20Choice/0213.pdf。
視頻監(jiān)視、步態(tài)識(shí)別的研究論文具有很高的被引數(shù),毫不驚奇幾乎所有的研究都是在中國(guó)開(kāi)展的。
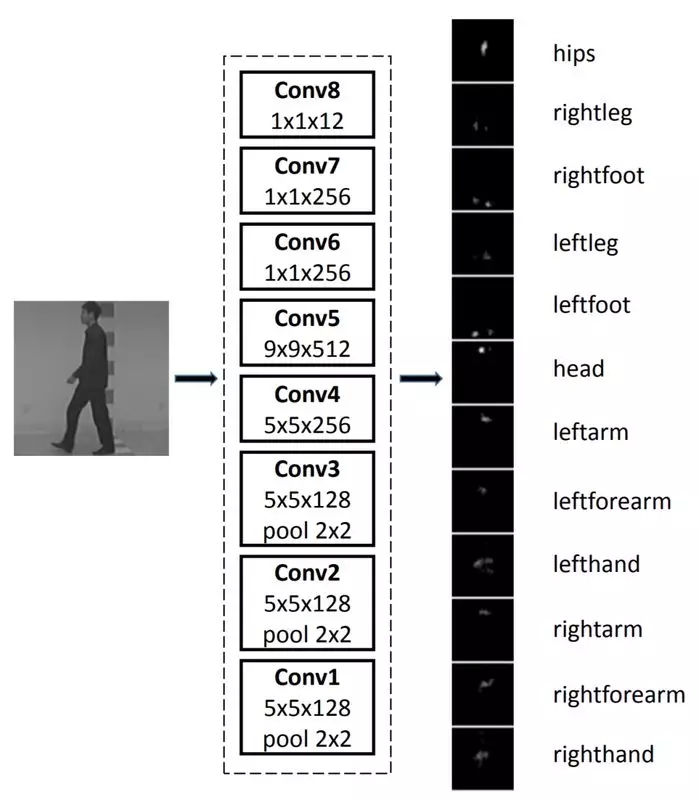
下一個(gè)研究前沿方向?qū)?huì)是完整的人體姿勢(shì)識(shí)別,無(wú)論是用于識(shí)別還是標(biāo)記(人體處于站立、跳躍、坐姿等),它將對(duì)人體的每個(gè)部位提出獨(dú)立的卷積模型。作為 UI 的一部分,手勢(shì)識(shí)別正成為一個(gè)研究熱點(diǎn),尤其是在增強(qiáng)現(xiàn)實(shí)領(lǐng)域。

天氣預(yù)報(bào)
該應(yīng)用的目標(biāo)是預(yù)測(cè)局部區(qū)域及相當(dāng)短的時(shí)間跨度內(nèi)的降雨強(qiáng)度。這一領(lǐng)域也被稱為“臨近預(yù)報(bào)”(nowcasting)。
?
DNA 序列功能量化
人類 DNA 中有 98% 尚未編碼,這些未編碼的片段稱為“內(nèi)含子”(Intron)。內(nèi)含子在最初被認(rèn)為是一些毫無(wú)價(jià)值的進(jìn)化殘余,但是遺傳學(xué)家現(xiàn)在認(rèn)識(shí)到其價(jià)值所在。例如,有 93%的疾病相關(guān)變種位于這些區(qū)域中。對(duì)這些區(qū)域的性質(zhì)和功能建模,這是一項(xiàng)正在開(kāi)展中的研究。近期,一種稱為“DanQ”的 CNN/LSTM 組合模型為解決這一挑戰(zhàn)給出了一定的貢獻(xiàn)。
據(jù) DanQ 的研究者介紹,“卷積層可捕獲了調(diào)控模體(regulatory motif),而遞歸層則捕獲了模體間的長(zhǎng)期依賴關(guān)系,用于學(xué)習(xí)調(diào)控“語(yǔ)法”以改進(jìn)預(yù)測(cè)。與其它模型做對(duì)比,DanQ 在多個(gè)指標(biāo)上得到了大大的改進(jìn)。與一些相關(guān)模型的 ROC 曲線下面積相比,DanQ 實(shí)現(xiàn)了某些調(diào)控標(biāo)記(regulatory marker)超過(guò) 50%的相對(duì)改善”。
研究論文原文提供于此:https://academic.oup.com/nar/article/44/11/e107/2468300
?為默音視頻創(chuàng)建逼真的音軌
一些 MIT 的研究者盡其所能創(chuàng)建了大量標(biāo)記的鼓槌聲音片段。他們使用了一種 CNN/LSTM 組合方法,其中 CNN 用于識(shí)別視覺(jué)場(chǎng)景(鼓槌在靜音視頻中的擊打情況)。但由于聲音片段是時(shí)序的,并且延伸了數(shù)個(gè)幀,因而他們使用 LSTM 層將聲音片段與適當(dāng)?shù)膸M(jìn)行匹配。
據(jù)研究者報(bào)告,人們?cè)诔^(guò) 50%的時(shí)間中會(huì)被預(yù)測(cè)的聲音匹配所欺騙。
可在此查看視頻:https://www.youtube.com/watch?t=0s&v=flOevlA9RyQ
?
未來(lái)的研究方向
我十分驚喜能看到大量的研究,其中研究者組合使用了 CNN 和 RNN,以獲得兩者的優(yōu)勢(shì)。一些研究甚至在混合網(wǎng)絡(luò)中使用了 GAN,這非常有意思。
盡管這種組合模型似乎提供了更好的能力,但目前還有另一個(gè)新研究方向更受關(guān)注。該研究方向認(rèn)為 CNN 自身就足以適用,RNN/LSTM 組合模型并非長(zhǎng)久之計(jì)。
一組研究人員提出了一種新穎的深度森林架構(gòu)。該架構(gòu)嵌入在節(jié)點(diǎn)結(jié)構(gòu)中,性能超出 CNN 和 RNN,并降低了計(jì)算資源和復(fù)雜度。
我們也關(guān)注著 Facebook 和 Google 這樣的更主流方向。兩家企業(yè)在近期停止在自己的語(yǔ)音互譯產(chǎn)品中使用的基于 RNN/LSTM 的工具,轉(zhuǎn)向使用 TCN(Temporal Convolutional Net)。
通常對(duì)于時(shí)序問(wèn)題,尤其是對(duì)于文本問(wèn)題,RNN 在設(shè)計(jì)上存在著固有的問(wèn)題。RNN 一次讀取并解釋輸入文本中的一個(gè)字(或字符、圖像),因此深度神經(jīng)網(wǎng)絡(luò)必須等待直到當(dāng)前字的處理完成,才能去處理下一個(gè)字。
這意味著 RNN 無(wú)法像 CNN 那樣利用大規(guī)模并行處理(MPP)。尤其是為了更好地理解上下文而需要同時(shí)運(yùn)行 RNN/LSTM 時(shí)。
這是一個(gè)無(wú)法消除的障礙,會(huì)限制 RNN/LSTM 架構(gòu)的效用。TCN 通過(guò)使用 CNN 架構(gòu)解決這個(gè)問(wèn)題。CNN 架構(gòu)可以輕松實(shí)現(xiàn)“關(guān)注”(attention)和“跳門”(gate hopping)等新概念的 MPP 加速。
詳細(xì)內(nèi)容可參閱我們的論文原文:https://www.datasciencecentral.com/profiles/blogs/temporal-convolutional-nets-tcns-take-over-from-rnns-for-nlp-pred
當(dāng)然,我無(wú)法做到概述整個(gè)研究領(lǐng)域。即便是針對(duì)最小延遲需求不像語(yǔ)音翻譯那么嚴(yán)格的情況,我也做不到一一列出所有研究。然而,對(duì)于我們上面介紹的所有這些應(yīng)用,似乎完全可以重新審視 TCN 這種新方法是否適用。
Bill Vorhies 的博客文章:
https://www.datasciencecentral.com/profiles/blog/list?user=0h5qapp2gbuf8
作者簡(jiǎn)介
Bill Vorhies 是 Data Science Central 的總編輯,自 2001 年以來(lái)一直從事數(shù)據(jù)科學(xué)研究。可通過(guò) Bill@Data-Magnum.com 或 Bill@DataScienceCentral.com 與他聯(lián)系。
查看英文原文:
https://www.datasciencecentral.com/profiles/blogs/combining-cnns-and-rnns-crazy-or-genius
聲明:文章收集于網(wǎng)絡(luò),如有侵權(quán),請(qǐng)聯(lián)系小編及時(shí)處理,謝謝!
歡迎加入本站公開(kāi)興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉(cāng)庫(kù),數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識(shí)
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請(qǐng)注明本文地址:http://specialneedsforspecialkids.com/yun/4825.html
摘要:本文將詳細(xì)解析深度神經(jīng)網(wǎng)絡(luò)識(shí)別圖形圖像的基本原理。卷積神經(jīng)網(wǎng)絡(luò)與圖像理解卷積神經(jīng)網(wǎng)絡(luò)通常被用來(lái)張量形式的輸入,例如一張彩色圖象對(duì)應(yīng)三個(gè)二維矩陣,分別表示在三個(gè)顏色通道的像素強(qiáng)度。 本文將詳細(xì)解析深度神經(jīng)網(wǎng)絡(luò)識(shí)別圖形圖像的基本原理。針對(duì)卷積神經(jīng)網(wǎng)絡(luò),本文將詳細(xì)探討網(wǎng)絡(luò) 中每一層在圖像識(shí)別中的原理和作用,例如卷積層(convolutional layer),采樣層(pooling layer),...
摘要:在普通的全連接網(wǎng)絡(luò)或中,每層神經(jīng)元的信號(hào)只能向上一層傳播,樣本的處理在各個(gè)時(shí)刻獨(dú)立,因此又被成為前向神經(jīng)網(wǎng)絡(luò)。不難想象隨著深度學(xué)習(xí)熱度的延續(xù),更靈活的組合方式更多的網(wǎng)絡(luò)結(jié)構(gòu)將被發(fā)展出來(lái)。 從廣義上來(lái)說(shuō),NN(或是更美的DNN)確實(shí)可以認(rèn)為包含了CNN、RNN這些具體的變種形式。在實(shí)際應(yīng)用中,所謂的深度神經(jīng)網(wǎng)絡(luò)DNN,往往融合了多種已知的結(jié)構(gòu),包括卷積層或是LSTM單元。這里的DNN特指全連接...
摘要:在兩個(gè)平臺(tái)三個(gè)平臺(tái)下,比較這五個(gè)深度學(xué)習(xí)庫(kù)在三類流行深度神經(jīng)網(wǎng)絡(luò)上的性能表現(xiàn)。深度學(xué)習(xí)的成功,歸因于許多層人工神經(jīng)元對(duì)輸入數(shù)據(jù)的高表征能力。在年月,官方報(bào)道了一個(gè)基準(zhǔn)性能測(cè)試結(jié)果,針對(duì)一個(gè)層全連接神經(jīng)網(wǎng)絡(luò),與和對(duì)比,速度要快上倍。 在2016年推出深度學(xué)習(xí)工具評(píng)測(cè)的褚曉文團(tuán)隊(duì),趕在猴年最后一天,在arXiv.org上發(fā)布了的評(píng)測(cè)版本。這份評(píng)測(cè)的初版,通過(guò)國(guó)內(nèi)AI自媒體的傳播,在國(guó)內(nèi)業(yè)界影響很...
摘要:摘要在年率先發(fā)布上線了機(jī)器翻譯系統(tǒng)后,神經(jīng)網(wǎng)絡(luò)表現(xiàn)出的優(yōu)異性能讓人工智能專家趨之若鶩。目前在阿里翻譯平臺(tái)組擔(dān)任,主持上線了阿里神經(jīng)網(wǎng)絡(luò)翻譯系統(tǒng),為阿里巴巴國(guó)際化戰(zhàn)略提供豐富的語(yǔ)言支持。 摘要: 在2016年Google率先發(fā)布上線了機(jī)器翻譯系統(tǒng)后,神經(jīng)網(wǎng)絡(luò)表現(xiàn)出的優(yōu)異性能讓人工智能專家趨之若鶩。本文將借助多個(gè)案例,來(lái)帶領(lǐng)大家一同探究RNN和以LSTM為首的各類變種算法背后的工作原理。 ...

閱讀 2486·2021-11-15 18:14
閱讀 1710·2021-10-14 09:42
閱讀 3744·2021-10-11 10:58
閱讀 3938·2021-10-09 09:44
閱讀 2409·2021-09-26 09:55
閱讀 2430·2021-09-24 10:38
閱讀 2024·2021-09-04 16:48
閱讀 3268·2021-09-02 15:21





