資訊專欄INFORMATION COLUMN

摘要:本文將詳細解析深度神經網絡識別圖形圖像的基本原理。卷積神經網絡與圖像理解卷積神經網絡通常被用來張量形式的輸入,例如一張彩色圖象對應三個二維矩陣,分別表示在三個顏色通道的像素強度。
本文將詳細解析深度神經網絡識別圖形圖像的基本原理。針對卷積神經網絡,本文將詳細探討網絡 中每一層在圖像識別中的原理和作用,例如卷積層(convolutional layer),采樣層(pooling layer),全連接層(hidden layer),輸出層(softmax output layer)。針對遞歸神經網絡,本文將解釋它在在序列數據上表現出的強大能力。針對通用的深度神經網絡模型,本文也將詳細探討網絡的前饋和學習過程。卷 積神經網絡和遞歸神經網絡的結合形成的深度學習模型甚至可以自動生成針對圖片的文字描述。作為近年來重新興起的技術,深度學習已經在諸多人工智能領域取得 了令人矚目的進展,但是神經網絡模型的可解釋性仍然是一個難題,本文從原理的角度探討了用深度學習實現圖像識別的基本原理,詳細解析了從圖像到知識的轉換 過程。
1、引言
傳統的機器學習技術往往使用原始形式來處理自然數據,模型的學習能力受到很大的局限,構成一個模式識別或機器學習系統往往需要相當的專業知識來從原始數據 中(如圖像的像素值)提取特征,并轉換成一個適當的內部表示。而深度學習則具有自動提取特征的能力,它是一種針對表示的學習。
深度學習允許多個處理層組成復雜計算模型,從而自動獲取數據的表示與多個抽象級別。這些方法大大推動了語音識別,視覺識別物體,物體檢測,藥物發現和基因組學等領域的發展。通過使用BP算法,深度學習有能力發現在大的數據集的隱含的復雜結構。
?“表示學習”能夠從原始輸入數據中自動發現需要檢測的特征。深度學習方法包含多個層次,每一個層次完成一次變換(通常是非線性的變換),把某個較低級別的 特征表示表示成更加抽象的特征。只要有足夠多的轉換層次,即使非常復雜的模式也可以被自動學習。對于圖像分類的任務,神經網絡將會自動剔除不相關的特征, 例如背景顏色,物體的位置等,但是會自動放大有用的特征,例如形狀。圖像往往以像素矩陣的形式作為原始輸入,那么神經網絡中第一層的學習功能通常是檢測特 定方向和形狀的邊緣的存在與否,以及這些邊緣在圖像中的位置。第二層往往會檢測多種邊緣的特定布局,同時忽略邊緣位置的微小變化。第三層可以把特定的邊緣 布局組合成為實際物體的某個部分。后續的層次將會把這些部分組合起來,實現物體的識別,這往往通過全連接層來完成。對于深度學習而言,這些特征和層次并不 需要通過人工設計:它們都可以通過通用的學習過程得到。
2、神經網絡的訓練過程
如圖1所示,深度學習模型的架構一般是由一些相對簡單的模塊多層堆疊起來,并且每個模塊將會計算從輸入到輸出的非線性映射。每個模塊都擁有對于輸入的選擇 性和不變性。一個具有多個非線性層的神經網絡通常具有5~20的深度,它將可以選擇性地針對某些微小的細節非常敏感,同時針對某些細節并不敏感,例如為背 景。
在模式識別的初期,研究者們就希望利用可訓練的多層網絡來代替手工提取特征的功能,但是神經網絡的訓練過程一直沒有被廣泛理解。直到20世紀80年代中 期,研究者才發現并證明了,多層架構可以通過簡單的隨機梯度下降來進行訓練。只要每個模塊都對應一個比較平滑的函數,就可以使用反向傳播過程計算誤差函數 對于參數梯度。
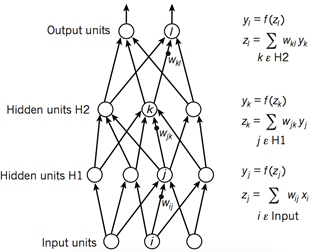
圖1 神經網絡的前饋過程
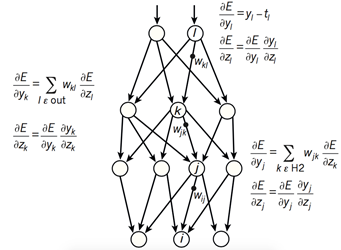
圖2 神經網絡的反向誤差傳播過程
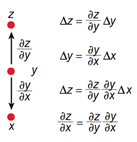
圖3 鏈式法則
?如圖2所示,復雜神經網絡基于反向傳播過程來計算目標函數相對于每個模塊中的參數的梯度。反向傳播過程的數學原理即為鏈式法則,如圖3所示。目標函數相對 于每個模塊的梯度具有一定的獨立性,這是鏈式法則的關鍵,目標函數相對于一個模塊的輸入的梯度可以在計算出目標函數相對于這個模塊輸出的梯度之后被計算, 反向傳播規則可以反復施加通過所有模塊傳播梯度,從而實現梯度(亦即誤差)的不斷反向傳播,從最后一層一直傳播到原始的輸入。
在90年代后期,神經網絡和以及其它基于反向傳播的機器學習領域在很大程度上為人詬病,計算機視覺和語音識別社區也忽略了這樣的模型。人們普遍認為,學習 很少先驗知識是有用的,多階段的自動特征提取是不可行的。尤其是簡單的梯度下降將得到局部極小值,這個局部極小值和全局最小值可能相差甚遠。
但是在實踐中,局部最優很少會成為大型網絡的一個問題。實踐證明,不管初始條件,系統幾乎總是達到非常接近的結果。一些最近的理論和實證研究結果也傾向于 表明局部最優不是一個嚴重問題。相反,模型中會存在大量鞍點,在鞍點位置梯度為0,訓練過程會滯留在這些點上。但是分析表明,大部分鞍點都具有想接近的目 標函數值,因此,它訓練過程被卡在哪一個鞍點上往往并不重要。
前饋神經網絡有一種特殊的類型,即為卷積神經網絡(CNN)。人們普遍認為這種前饋網絡是更容易被訓練并且具有更好的泛化能力,尤其是圖像領域。卷積神經網絡已經在計算機視覺領域被廣泛采用。
3、卷積神經網絡與圖像理解
卷積神經網絡(CNN)通常被用來張量形式的輸入,例如一張彩色圖象對應三個二維矩陣,分別表示在三個顏色通道的像素強度。許多其它輸入數據也是張量的形 式:如信號序列、語言、音頻譜圖、3D視頻等等。卷積神經網絡具有如下特點:局部連接,共享權值,采樣和多層。
如圖4所示,一個典型CNN的結構可以被解釋為一系列階段的組合。最開始的幾個階段主要由兩種層組成:卷積層(convolutional layer)和采樣層(pooling layer)。卷積層的輸入和輸出都是多重矩陣。卷積層包含多個卷積核,每個卷積核都是一個矩陣,每一個卷積核相當于是一個濾波器,它可以輸出一張特定的 特征圖,每張特征圖也就是卷積層的一個輸出單元。然后通過一個非線性激活函數(如ReLU)進一步把特征圖傳遞到下一層。不同特征圖使用不同卷積核,但是 同一個特征圖中的不同位置和輸入圖之間的連接均為共享權值。這樣做的原因是雙重的。首先,在張量形式的數據中(例如圖像),相鄰位置往往是高度相關的,并 且可以形成的可以被檢測到的局部特征。其次,相同的模式可能出現在不同位置,亦即如果局部特征出現在某個位置,它也可能出現在其它任何位置。在數學上,根 據卷積核得到特征圖的操作對應于離散卷積,因此而得名。
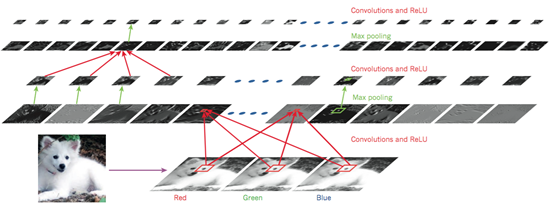
圖 4 卷積神經網絡與圖像理解
事實上有研究表明無論識別什么樣的圖像,前幾個卷積層中的卷積核都相差不大,原因在于它們的作用都是匹配一些簡單的邊緣。卷積核的作用在于提取局部微小特 征,如果在某個位置匹配到了特定的邊緣,那么所得到的特征圖中的這個位置就會有較大的強度值。如果多個卷積核在臨近的位置匹配到了多個特征,那么這些特征 就組合成為了一個可識別的物體。對于現實世界中的圖像而言,圖形常常都是由很多簡單的邊緣組成,因此可以通過檢測一系列簡單邊緣的存在與否實現物體的識 別。
卷積層的作用是從前一層的輸出中檢測的局部特征,不同的是,采樣層的作用是把含義相似的特征合并成相同特征,以及把位置上相鄰的特征合并到更接近的位置。 由于形成特定主題的每個特征的相對位置可能發生微小變化,因此可以通過采樣的方法輸入特征圖中強度較大的位置,減小了中間表示的維度(即特征圖的尺寸), 從而,即使局部特征發生了一定程度的位移或者扭曲,模型仍然可以檢測到這個特征。CNN的梯度計算和參數訓練過程和常規深度網絡相同,訓練的是卷積核中的 所有參數。
自上世紀90年代初以來,CNN已經被應用到諸多領域。,在90年代初,CNN就已經被應用在自然圖像,臉和手的檢測,面部識別和物體檢測中。人們還使用 卷積網絡實現語音識別和文檔閱讀系統,這被稱為時間延遲神經網絡。這個文檔閱讀系統同時訓練了卷積神經網絡和用于約束自然語言的概率模型。此外還有許多基 于CNN的光學字符識別和手寫識別系統。
4、遞歸神經網絡與自然語言理解
?當涉及到處理不定長序列數據(如語音,文本)時,使用遞歸神經網絡(RNN)更加自然。不同于前饋神經網絡,RNN具有內部狀態,在其隱藏單元中保留了 “狀態矢量”,隱式地包含了關于該序列的過去的輸入信息。當RNN接受一個新的輸入時,會把隱含的狀態矢量同新的輸入組合起來,生成依賴于整個序列的輸 出。RNN和CNN可以結合起來,形成對圖像的更全面準確的理解。
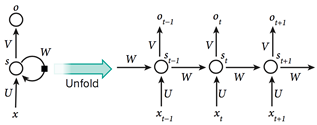
圖5 遞歸神經網絡
如圖5所示,如果我們把遞歸神經網絡按照不同的離散時間步展開,把不同時間步的輸出看作是網絡中不同神經元的輸出,那么RNN就可以被看做是一個很深的前 饋神經網絡,也就可以應用常規的反向傳播過程訓練這一網絡,這種按照時間步反向傳播的方法被稱為BPTT(Back Propagation Through Time)。但是盡管RNN是非常強大的動態系統,它的訓練過程仍會遇到一個很大的問題,因為梯度在每個時間步可能增長也可能下降,所以在經過許多時間步 的反向傳播之后,梯度常常會爆炸或消失,網絡的內部狀態對于長遠過去輸入的記憶作用十分微弱。
解決這個問題的一種方案是在網絡中增加一個顯式的記憶模塊,增強網絡對于長遠過去的記憶能力。長短時記憶模型(LSTM)就是這樣一類模型,LSTM引入 的一個核心元素就是Cell。LSTM網絡已被證明比常規RNN更有效,尤其是在網絡中每個時間步都具有若干層的時候。
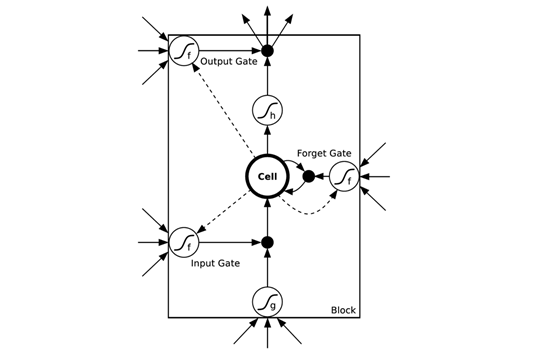
圖6 長短時記憶模型
如圖6所示,在LSTM的網絡結構中,前一層的輸入會通過更多的路徑作用于輸出,門(Gate)的引入使得網絡具有了聚焦作用。LSTM可以更加自然地記 住很長一段時間之前的輸入。存儲單元Cell是一個特殊的單元,作用就像一個累加器或一個“gated leaky neuron”:這個單元具有從上一個狀態到下一個狀態之間的直接連接,所以它可以復制自身的當前狀態并累積所有的外部信號,同時由于遺忘門 (Forget Gate)的存在,LSTM可以學習決定何時清除存儲單元的內容。
5、圖片描述的自動生成
如圖7所示,深度學習領域的一個匪夷所思的Demo結合了卷積網絡和遞歸網絡實現圖片標題的自動生成。首先通過卷積神經網絡(CNN)理解原始圖像,并把它轉換為語義的分布式表示。然后,遞歸神經網絡(RNN)會把這種高級表示轉換成為自然語言。
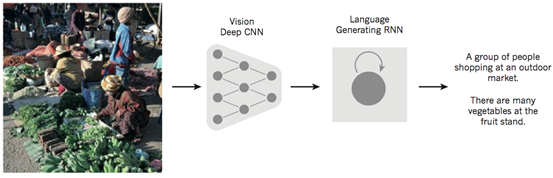
圖7 圖片描述的自動生成
除了利用RNN的記憶機制(memory),還可以增加聚焦機制(attention),通過把注意力放在圖片的不同部位,從而把圖片翻譯成不同的標題。 聚焦機制甚至可以讓模型更加可視化,類似于RNN機器翻譯的聚焦機制,在通過語義表示生成詞語的同時我們能解釋模型正在關注哪個部分。
6、未來展望
無監督學習曾經促進了深度學習領域的復興,但純粹的監督學習的所取得的巨大成功掩蓋了其作用。我們期待無監督學習能成為在長期看來的更重要的方法。人類和 動物的學習主要是無監督的方式:我們通過自主地觀察世界而不是被告知每個對象的名稱來發現世界的結構。我們期待未來大部分關于圖像理解的進步來自于訓練端 到端的模型,并且將常規的CNN和使用了強化學習的RNN結合起來,實現更好的聚焦機制。深度學習和強化學習系統的結合目前還處于起步階段,但他們已經在 分類任務上超越了被動視覺系統,并在學習視頻游戲領域中取得了不俗的成績。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4371.html

閱讀 422·2019-08-29 12:44
閱讀 3001·2019-08-26 17:49
閱讀 2395·2019-08-26 13:40
閱讀 1179·2019-08-26 13:39
閱讀 3655·2019-08-26 11:59
閱讀 1814·2019-08-26 10:59
閱讀 2454·2019-08-23 18:33
閱讀 2686·2019-08-23 18:30


