資訊專欄INFORMATION COLUMN

摘要:本文來自搜狗資深研究員舒鵬在攜程技術中心主辦的深度學習中的主題演講,介紹了深度學習在搜狗無線搜索廣告中的應用及成果。近年來,深度學習在很多領域得到廣泛應用并已取得較好的成果,本次演講就是分享深度學習如何有效的運用在搜狗無線搜索廣告中。
本文來自搜狗資深研究員舒鵬在攜程技術中心主辦的深度學習Meetup中的主題演講,介紹了深度學習在搜狗無線搜索廣告中的應用及成果。重點講解了如何實現基于多模型融合的CTR預估,以及模型效果如何評估。

搜索引擎廣告是用戶獲取網絡信息的渠道之一,同時也是互聯網收入的來源之一,通過傳統的淺層模型對搜索廣告進行預估排序已不能滿足市場需求。近年來,深度學習在很多領域得到廣泛應用并已取得較好的成果,本次演講就是分享深度學習如何有效的運用在搜狗無線搜索廣告中。
本次分享主要介紹深度學習在搜狗無線搜索廣告中有哪些應用場景,以及分享了我們的一些成果,重點講解了如何實現基于多模型融合的CTR預估,以及模型效果如何評估,最后和大家探討DL、CTR預估的特點及未來的一些方向。
深度學習在搜索廣告中有哪些應用場景
比較典型的深度學習應用場景包括語音識別、人臉識別、博奕等,也可以應用于搜索廣告中。首先介紹下搜索廣告的基本架構,如下圖:
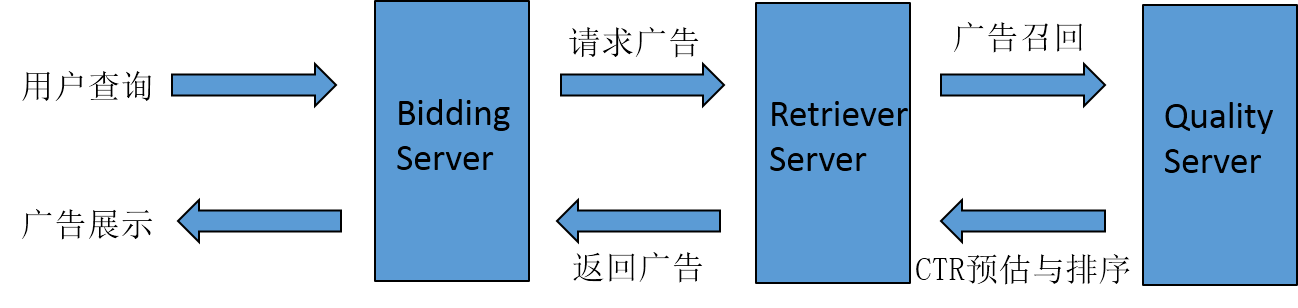
首先用戶查詢。
查詢詞給Bidding Server處理,Bidding Server主要負責業務邏輯。例如某種廣告在什么情況下不能展現,或這個客戶同一個廣告在什么時間段什么地域展現。
Bidding Server請求Retriever Server,Retriever Server主要負責召回,廣告庫很龐大(搜狗的廣告庫大概在幾十億這個規模),因為數據量非常大,所以需要根據一些算法從中找出和當前查詢詞最相關的一批廣告,這就是Retriever Server做的事情。
Retriever Server處理完后,會把這些比較好的廣告回傳給Quality Server,Quality Server主要負責點擊率預估和排序,此時的候選集數量相對較少,Quality Server會采用復雜的算法針對每條廣告預估它當前場景的點擊率,并據此排序。
Quality Server將排序結果的top回傳給Retriever Server。
Retriever Server回傳給Bidding Server。
Bidding Server做封裝最后展示給用戶。
以上過程中可應用到深度學習的場景如下:

基于多模型融合的CTR預估
CTR預估流程
CTR預估的流程圖如下:
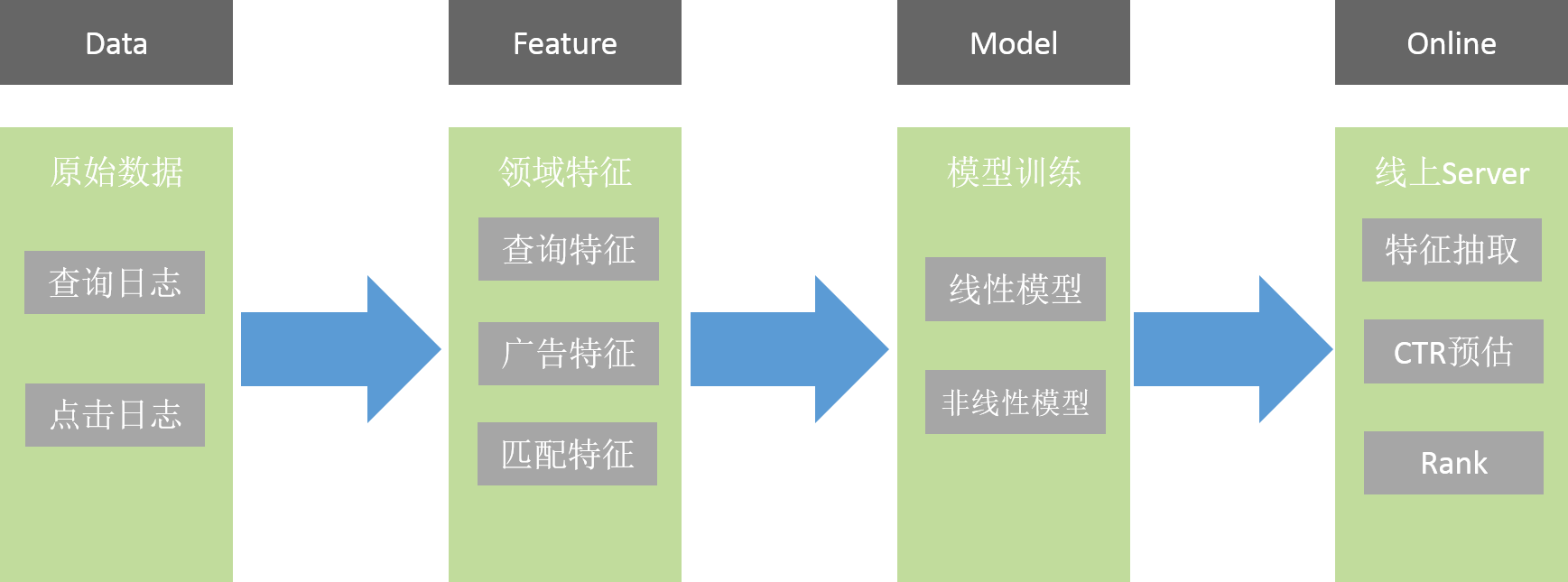
Data是原始數據,包括點擊及查詢日志,從這些原始數據里抽出一些特征。
Feature包括查詢特征、廣告特征、匹配特征。?
查詢特征是和查詢詞相關的特征,查詢發生的地域、時間等。廣告特征是指廣告本身的信息,例如:來自哪個客戶,是哪個行業的,它的關鍵詞是什么,它的標題、描述、網址是什么等各種信息。匹配特征是指查詢詞和廣告的匹配關系。
然后會進行模型的訓練,包括線性和非線性。
模型在線下訓練完后會到線上,線上Server會實時做特征抽取并預估。?
例如:線上實時收到查詢請求后,就會知道查詢詞是什么。前面講的Retriever Server,它會召回一系列廣告,并抽出相關信息,比如廣告的標題、關鍵詞、描述等信息,有了這些信息后會利用加載的模型給出預估CTR,最終會進行Rank排序,從而篩選出滿足指定條件的一些廣告進行展示。
特征設計
離散特征
離散特征是指把東西分散出來表示,比如OneHot,非常直觀,例如用戶當天所處的時間段,他和最終點擊率有關系,那么我把一天24小時分成24個點,他在哪個小時就把哪個點點亮置1,這個特征就設計完了。它的刻畫比較細致,設計比較簡單,但他的特征非常稀疏,我們線上特征空間非常大,有上十億,但任何一個請求場景到來,它真正有效的特征大概只有幾百個,絕大部分都是空的。因為特征量非常大,不能設計太復雜的模型,否則無法用于線上。
離散特征總結:容易設計,刻畫細致,特征稀疏,特征量巨大,模型復雜度受限。
連續特征
還是以時間舉例,離散特征會把它變成24個點,連續特征就會變成一個值,比如1、2、3、4、5一直到24,它只會占一個位置。需要仔細設計,很難找到一個直接的方法來描述查詢詞中包括哪些東西。它是定長的,所以一個請求場景到來,它有多少特征是固定的。不像離散特征是不定長,查詢詞不一樣,有的是兩個特征或三個特征,對于特征點可能有兩個或三個,這對于我們后面的工作也有一定的影響。連續特征比較稠密,每個位置都會有值,它特征量相對較小,如果用連續特征設計的話可能需要幾百維就可以,因此可以使用多種模型來訓練。
連續特征總結:需要仔細設計,定長,特征稠密,特征量相對較小,可以使用多種模型訓練。
模型類別
線性
優點:簡單、處理特征量大、穩定性好。?
缺點:不能學習特征間的交叉關系,需要自己去設計。比較典型的如Logistic Regression,有開源的工具包,部署簡單且效果不錯。
非線性
優點:能夠學習特征間非線性關系。?
缺點:模型復雜、計算耗時。
比如LR模型就算特征再多,它只是查表加在一起做指數運算就出來了,像DNN、GBDT就會非常復雜,導致計算過程比較慢。
總結:Logistic Regression即能處理連續值又能處理離散值。DNN幾乎不能處理離散值,除非做特殊的預處理。
模型融合
前面講過每個模型都有自己的特點:Logistic Regression處理特征量大,大概在2010年前后開始大量應用于業界,很難有模型能完全超越它;DNN可以挖掘原來沒有的東西。我們就想這兩個模型能不能將優點進行融合,揚長避短,從而得到更好的結果。
第一種方案:CTR Bagging
有多個模型,將多個模型的輸出CTR加權平均。
實現方法簡單,模型之間不產生耦合。
可調參數有限,只能調Bagging權重的參數,不能調其他東西,所以改進空間相對較小。
第二種方案:模型融合
任一模型的輸出作為另一模型的特征輸入,彼此進行交叉。
實現方法復雜,模型之間有依賴關系,因依賴關系復雜,風險也比較高。
好處是實驗方案較多,改進空間較大。
我們選了后一種方案,因為單純CTR Bagging太過簡單粗暴了。
模型融合的工程實現
目標
可支持多個不同模型的加載和計算
可支持模型之間的交叉和CTR的bagging
可通過配置項隨時調整模型融合方案
避免不必要的重復操作,減少時間復雜度
解決方法(引入ModelFeature的概念)
模型本身也看做一個抽象特征
模型特征依賴于其他特征,通過計算得到新的特征
模型特征輸出可作為CTR,也可作為特征為其他模型使用
限定ModelFeature的計算順序,即可實現bagging模型交叉等功能
模型融合
模型融合流程圖如下:
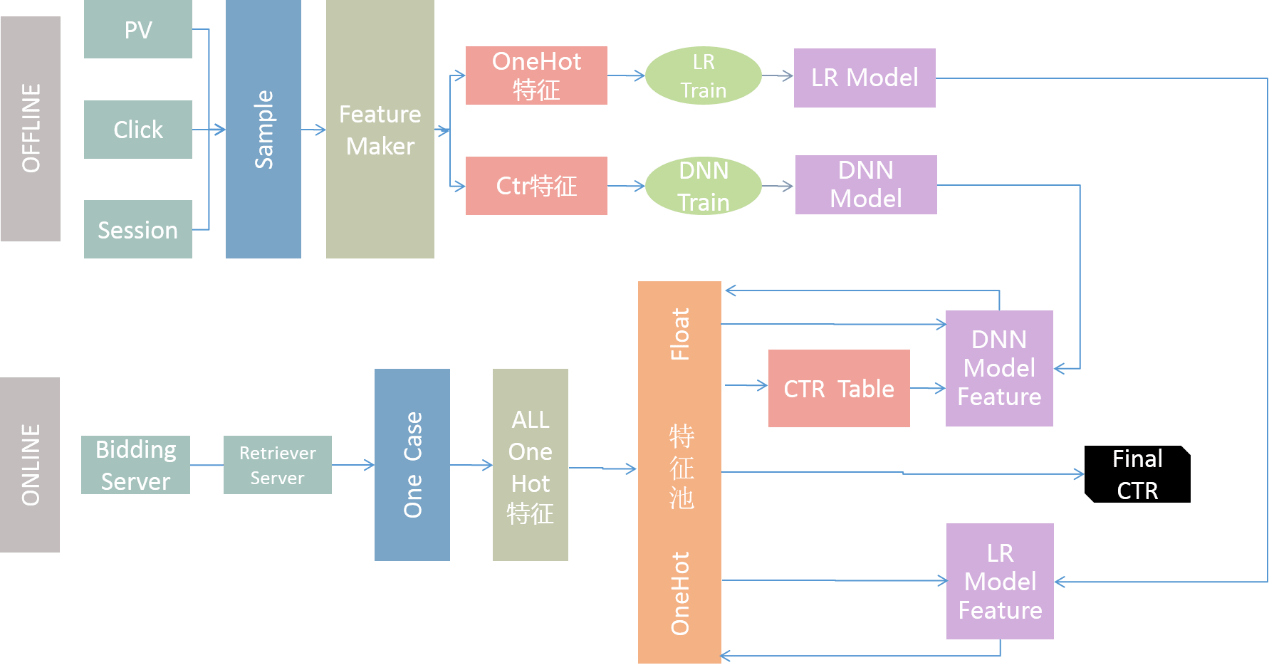
首先線下,將PV、Click、Session做成一個sample。
然后把sample做成特征,包括OneHot、CTR。
分別將OneHot、CTR傳送到各自模塊的train,就會得到相應的模型。
線上,Bidding Server 會經過 Retriever Server召回廣告。
然后傳給Quality Server進行計算,它是通過One Case存儲和這個查詢相關的所有信息。
Quality Server會把One Case里的信息轉換成One Hot特征。
然后將結果存到特征池,特征池包含所有特征。
LR模型從特征池里讀取數據,而后計算出CTR,還包括其他增量信息。
將這些回送到特征池。
此外DNN模型也會讀取特征池里的信息,并將最終計算結果回傳給特征池。
CTR可以從特征池里直接取出,然后進行后續的操作。
我們去年將這套框架部署到線上,并持續進行改進,在線上運行了半年多,基本能適用于業務的發展:曾經上線了LR和DNN的交叉,還上線了LR和GBDT的融合。GBDT會將過程信息回傳給LR,由LR完成最終輸出。此架構經過生產系統的檢驗,運轉正常。
模型效果評估
期間我們會做很多實驗,比如DNN訓練比較耗時,線上也比較耗時,因此我們會進行多種優化和評估。那么就涉及到一個問題,如何評估一個模型的好壞?線下指標主要采用AUC,定義如下圖所示:

我們來分析下這個圖,選定一系列閾值將對應一系列點對,形成一條曲線,曲線下方的面積總和就是AUC的值:紅線就是純隨機的結果,對應的AUC是0.5;模型越好,曲線離左上角就越近。這個值在我們模型評估里用得非常多,該值考察的是模型預估的排序能力,它會把模型預估排序結果和實際結果進行比對運算。該值很難優化,一般而言,AUC高,模型的排序能力就強。
線下指標AUC很重要,但我們發現單純靠這指標也是有問題的,不一定是我們的線上模型出了問題,可能是其他的問題。做廣告預估,AUC是線下指標,除此之外,最核心的指標是上線收益,有時這兩個指標會有不一致的地方,我們也嘗試去定位,可能的原因主要有:
Survivorship bias問題:線下訓練時所有的數據都是線上模型篩選過的比較好的樣本,是我們展示過的比較好的廣告,一次查詢三條左右,但實際上到了線上之后,面臨的場景完全不一樣。前面講過RS篩選出最多近千條廣告,這些廣告都會讓模型去評判它的CTR大概是多少,但實際上訓練的樣本只有最終的三條,對于特別差的廣告模型其實是沒有經驗的。如果一個模型只適用于對比較好的廣告進行排序,就會在線上表現很差,因為從來沒有見過那些特別差的廣告是什么樣的,就會做誤判。
特征覆蓋率的問題,例如:我們有個特征是和這個廣告自身ID相關的,該信息在在線下都能拿到,但真正到了線上之后,因為廣告庫非常大,很多廣告是未展示過的,相關的信息可能會缺失,原有的特征就會失效,線上該特征的覆蓋率比較低,最終將不會發揮作用。
并行化訓練
做DNN會遇到各種各樣的問題,尤其是數據量的問題。大家都知道模型依賴的數據量越大效果越好,因為能知道更多的信息,從而提升模型穩定性,所以我們就會涉及到并行化訓練的事情。
加大數據量,提升模型穩定性
我們做搜索廣告有一個重要指標:覆蓋率,是指此情況下是否需要顯示廣告。覆蓋率高了,用戶可能會不滿意,而且多出來那些廣告多半不太好;但如果覆蓋率很低,又等于沒賺到錢。這個指標很重要,所以我們希望融合模型上到線上后覆蓋率是可預測的。
我們發現這個融合模型會有自己的特點,上到線上之后會有些波動。例如:今天我們剛把模型覆蓋率調好了,但第二天它又變了。然后我們分析,可能是因為數據量的問題,需要在一個更大的數據集上訓練來提升模型的穩定性。
加大數據量,提升模型收益
其實就是見多識廣的意思,模型見得多,碰到的情況多,在遇到新問題的時候,就知道用什么方法去解決它,就能更合理的預估結果。
我們調研了一些方案,如下:
Caffe只支持單機單卡
TensorFlow不支持較大BatchSize
MxNet支持多機多卡,底層C++,上層Python接口
MxNet我們用得還不錯,基本能達到預期的效果。
若干思考
Deep Learing的強項
輸入不規整,而結果確定。
例如:圖像理解,這個圖像到底是什么,人很難描述出到底是哪些指標表明它是一個人臉還是貓或狗。但結果非常確定,任何人看一眼就知道圖片是什么,沒有爭議。
具體到我們的廣告場景,廣告特征都是有具體的含義。例如:時間信息,說是幾點就是幾點,客戶的關鍵詞信息,它寫的是什么就是什么,文本匹配度是多少,是高還是低,都有確定的含義。
CTR預估
輸入含義明確,場景相關,結果以用戶為導向。
例如:一個查詢詞,出現一條廣告,大家來評判它是好是壞,其實它的結果是因人而異的,有人覺得結果很好,而有人卻覺得一般,它沒有一個客觀度量的標準。所以我們認為CTR預估跟傳統的DL應用場景不太一樣。
我們DNN用到線上后,收益大概提升了百分之五左右,但相對Deep Learing在其他場景的應用,這個提升還是少了些。語音輸入法很早就有人做,因為準確率的問題一直沒有太大應用,但Deep Learing出來后,比如訊飛及我們搜狗的語音輸入法,用起來很不錯,準確率相比之前提高了一大截。
未來方向
Deep Learing既然有這些特性,我們會根據特定的業務場景進行應用,比如在某些情況下把它用上去效果會很好,我們還想做一些模型融合的事情。
我們做實驗發現把DNN和LR融合后,較好的結果相比LR本身,AUC大概高不到一個百分點。我們也嘗試過直接把DNN模型用到線上去,效果很差,就算在線下跟LR可比,但到線上后會有一系列問題,不管是從覆蓋率還是從最終收益都會有較大的差異,這是我們在搜狗無線搜索數據上得出的實驗結論,大家在各自的業務場景下可能有所區別。
如果你們沒有足夠經驗去手工做各種交叉特征的設計,直接用DNN可能會有好的成果。如果在非常成熟的模型上做,可能需要考慮下,收益預期不要太高。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4370.html

閱讀 2831·2021-09-28 09:45
閱讀 1507·2021-09-26 10:13
閱讀 897·2021-09-04 16:45
閱讀 3661·2021-08-18 10:21
閱讀 1084·2019-08-29 15:07
閱讀 2633·2019-08-29 14:10
閱讀 3146·2019-08-29 13:02
閱讀 2458·2019-08-29 12:31

