資訊專欄INFORMATION COLUMN

摘要:前面我們通過幾個數值展示了幾個比較經典的網絡的一些特性,下面我們就花一點時間來仔細觀察網絡的變化,首先是在網絡結構上的一些思考,其次是對于單層網絡內部的擴展,最后我們再來看看對于網絡計算的改變。和這類結構主要看中的是模型在局部的擬合能力。
前面我們通過幾個數值展示了幾個比較經典的網絡的一些特性,下面我們就花一點時間來仔細觀察CNN網絡的變化,首先是VGG在網絡結構上的一些思考,其次是Inception Module對于單層網絡內部的擴展,最后我們再來看看ResidualNet對于網絡計算的改變。當然,我們在介紹這些模型的同時還會聊一些同時代其他的模型。
VGG模型
介紹VGG模型的文章中自夸了VGG模型的幾個特點,下面我們來仔細說說,
首先是卷積核變小。實際上在VGG之前已經有一些模型開始嘗試小卷積核了,VGG模型只是成功案例之中的一個。
那么小卷積核有什么好處呢?文章中提出了兩個好處,首先是參數數量變少,過去一個7*7的卷積核需要49個參數,而現在3個3*3的卷積核有27個參數,看上去參數數量降低了不少;第二是非線性層的增加,過去7*7的卷積層只有1層非線性層與其相配,現在有3個3*3的卷積層有3個非線性層。非線性層的增加會使模型變得更加復雜,因此模型的表現力也有了提高。
同時在文章還提出了VGG的模型收斂速度比之前的AlexNet還要快些,從后來人的角度來看,參數訓練的速度和本層參數的數量相關。之前我們分析過CNN模型參數的方差,我們假設對于某一層,這層的輸入維度為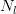 ,輸出維度為
,輸出維度為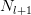 那么該層網絡中每個參數的方差應該控制在
那么該層網絡中每個參數的方差應該控制在 。如果輸入輸出層的維度比較大,那么參數的理想方差就需要限定的更小,所以參數可以取值的范圍就比較小,那么優化起來就比較費勁;如果輸入輸出維度比較小,那么每個參數的理想方差就會相對大一些,那么可以取值的范圍就比較大,優化起來就相對容易些。從這個角度來看,減小每一層參數的數量對于優化來說是有意義的。
。如果輸入輸出層的維度比較大,那么參數的理想方差就需要限定的更小,所以參數可以取值的范圍就比較小,那么優化起來就比較費勁;如果輸入輸出維度比較小,那么每個參數的理想方差就會相對大一些,那么可以取值的范圍就比較大,優化起來就相對容易些。從這個角度來看,減小每一層參數的數量對于優化來說是有意義的。
其次就是卷積層參數的規律。首先卷積層的操作不會改變輸入數據的維度,這里的維度主要指feature map的長和寬。對于3*3的kernel,卷積層都會配一個大小為1的pad。同時stride被設為1。這樣經過卷積層變換,長寬沒有發生變化。這和之前的卷積層設計有些不同。而且每做一次pooling,feature map的長寬各縮小一倍,channel層就會增加一倍。這樣的設計對于不同的feature map維度來說適配起來都比較容易。對于一些通過卷積減小維度的模型來說,對于不同的輸入,卷積后的輸出各不一樣,所以適配起來有可能不太方便,而現在只有pooling層改變長寬維度,整體模型的維度計算就方便了許多。于是在論文中有輸入為256和384等維度,模型不需要根據不同的輸入維度設計不同的卷積結構,使用同樣的結構或者直接加深網絡深度就可以了。
此外,模型也提到了1*1的卷積核,這個卷積核我們在后面還會提到。這種卷積核也不會改變feature map的長寬,同時又可以進一步地增加模型的非線性層,也就增加了模型的表現能力。
上面就是VGGNet在架構上做的這些改變,這些改變也被后面一些的模型所接納。
豐富模型層的內部結構
提到模型的內部結構,我們就來到了GoogLeNet模型(這個英文單詞是在致敬LeNet?),模型中最核心的地方就是它的Inception Module。在此之前還有一個研究模型層內部結構的文章,叫做Network In Network,其中的道理也比較相似。
Network in Network和Inception Module這類結構主要看中的是模型在局部的擬合能力。有些模型在結構上是采用“一字長蛇陣”的方法,對于某一個特定的尺度,模型只采用一個特定尺度的卷積核進行處理,而上面兩種模型卻認為,采用一種尺度處理可能不太夠,一張圖象通常具有總體特征特征和細節特征這兩類特征,我們用小卷積核能夠更好地捕捉一些細節特征,而隨著小卷積不斷地卷下去,慢慢地一些總體特征也就被發現。
可是這里有一個問題,那就是我們在網絡前段只有細節特征,后段才慢慢有一些總體特征,而有時候我們想讓兩方面的特征匯集在一起,同時出現發揮作用。那么采用單一的卷積核恐怕不太容易解決這樣的問題。
于是上面兩種模型開始考慮,與其把模型加深,不如把模型加厚(其實深度差不多),每一次feature map尺度的變化前后,我都盡可能地多做分析,把想得到的不同來源的信息都盡可能得到,這樣的特征應該會更有價值吧!
從乘法模型到加法模型
ResNet的核心思路就是把曾經CNN模型中的乘法關系轉變成加法關系,讓模型有了點“Additive”的味道。關于這個問題,文章中采用一個極端的例子作說明。
假設我們已經有了一個較淺模型,我們的目標是去訓練一個更深的模型。理論上如果我們能夠找到一個靠譜的優化算法和足夠的數據,那么這個更深的模型理論上應該比那個較淺的模型具有更好的表達能力。如果拋開優化和可能的過擬合問題不管,這個道理還是可以成立的。
就算較深的模型不能夠超越較淺的模型,至少它是可以作到和具有較淺的模型同樣的表達能力。如果我們把較深模型分成兩部分——和較淺模型相同的部分,比較淺模型多出來的部分,那么我們保持和較淺模型相同的部分的參數完全相同,同時讓多出來的模型部分“失效”,只原樣傳遞數據而不做任何處理,那么較深模型就和較淺的模型完全一樣了。在論文中,這些多出來的模型部分變成了“Identity Mapping”,也就是輸入和輸出完全一樣。
好了,那么對于現在的架構來說,我們如何學習這些“Identity Mapping”呢?過去的學習方法就是按現在的乘法模式進行學習,我們一般的CNN模型都是一層套一層,層與層之間的關系是乘法,下一層的輸出是上一層輸入和卷積相乘得到的。學習這樣的“Identity Mapping”還是有一點困難的,因為只要是想學到一個具體數值,它就具有一定的難度,不論是“Identity Mapping”還是其他。
于是,ResNet對上面的問題做了一些改變。既然是要學習“Identity Mapping”,那么我們能不能把過去的乘法轉變為加法?我們假設多出來的層的函數形式是F(x),那么乘法關系學習“Identity Mapping”就變成了 ,由于學習的形式沒有變,對于乘法我們學習起來同過去一樣,但是對于加法就簡單多了——
,由于學習的形式沒有變,對于乘法我們學習起來同過去一樣,但是對于加法就簡單多了——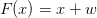 ,只要將參數學習成0就可以了,0和其他數值相比具有很大的優勢,這樣訓練難度就大大降低了。于是,我們也見到即使非常深的網絡也可以訓練,這也驗證了將乘法關系改為加法關系后對模型訓練帶來的顯著提升。
,只要將參數學習成0就可以了,0和其他數值相比具有很大的優勢,這樣訓練難度就大大降低了。于是,我們也見到即使非常深的網絡也可以訓練,這也驗證了將乘法關系改為加法關系后對模型訓練帶來的顯著提升。
在ResNet之前,還有一些網絡已經提出了類似的思想,比如Highway-Network。Highway-Network同樣具有加法的特點,但是它并不是一個純粹的加法,所以在優化過程總較ResNet弱一些。
這樣我們就回顧完了上次我們提到的幾個模型中的閃光點,如果想進一步地研究這些模型以及模型結構中的精妙之處,多多做實驗多多分析數據才是王道。
最后一點
為什么GoogLeNet和ResNet的層數很深且參數很少?因為他們的全連接層比較少。為什么呢?
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4406.html
摘要:一時之間,深度學習備受追捧。百度等等公司紛紛開始大量的投入深度學習的應用研究。極驗驗證就是將深度學習應用于網絡安全防御,通過深度學習建模學習人類與機器的行為特征,來區別人與機器,防止惡意程序對網站進行垃圾注冊,撞庫登錄等。 2006年Geoffery ?Hinton提出了深度學習(多層神經網絡),并在2012年的ImageNet競賽中有非凡的表現,以15.3%的Top-5錯誤率奪魁,比利用傳...
摘要:最后,我們顯示了若干張圖像中所生成的趣味字幕。圖所提出的有趣字幕生成的體系結構。我們將所提出的方法稱為神經玩笑機器,它是與預訓練模型相結合的。用戶對已發布的字幕的趣味性進行評估,并為字幕指定一至三顆星。 可以毫不夸張地說,笑是一種特殊的高階功能,且只有人類才擁有。那么,是什么引起人類的笑聲表達呢?最近,日本東京電機大學(Tokyo Denki University)和日本國家先進工業科學和技...
摘要:分組卷積的思想影響比較深遠,當前一些輕量級的網絡,都用到了分組卷積的操作,以節省計算量。得到新的通道之后,這時再對這批新的通道進行標準的跨通道卷積操作。 CNN從2012年的AlexNet發展至今,科學家們發明出各種各樣的CNN模型,一個比一個深,一個比一個準確,一個比一個輕量。作者對近幾年一些具有變革性的工作進行簡單盤點,從這些充滿革新性的工作中探討日后的CNN變革方向。本文只介紹其中具有...
摘要:本文詳細討論了自然語言理解的難點,并進一步針對自然語言理解的兩個核心問題,詳細介紹了規則方法和深度學習的應用。引言自然語言理解是人工智能的核心難題之一,也是目前智能語音交互和人機對話的核心難題。 摘要:自然語言理解是人工智能的核心難題之一,也是目前智能語音交互和人機對話的核心難題。之前寫過一篇文章自然語言理解,介紹了當時NLU的系統方案,感興趣的可以再翻一番,里面介紹過的一些內容不再贅...
摘要:近幾年以卷積神經網絡有什么問題為主題做了多場報道,提出了他的計劃。最初提出就成為了人工智能火熱的研究方向。展現了和玻爾茲曼分布間驚人的聯系其在論文中多次稱,其背后的內涵引人遐想。 Hinton 以深度學習之父 和 神經網絡先驅 聞名于世,其對深度學習及神經網絡的諸多核心算法和結構(包括深度學習這個名稱本身,反向傳播算法,受限玻爾茲曼機,深度置信網絡,對比散度算法,ReLU激活單元,Dropo...

閱讀 1976·2021-11-24 09:38
閱讀 3339·2021-11-22 12:07
閱讀 1903·2021-09-22 16:03
閱讀 1956·2021-09-02 15:41
閱讀 2618·2021-07-24 23:28
閱讀 2211·2019-08-29 13:17
閱讀 1547·2019-08-29 12:25
閱讀 2666·2019-08-29 11:10






