資訊專欄INFORMATION COLUMN

摘要:年以來(lái),深度學(xué)習(xí)方法開(kāi)始在目標(biāo)跟蹤領(lǐng)域展露頭腳,并逐漸在性能上超越傳統(tǒng)方法,取得巨大的突破。值得一提的是,目前大部分深度學(xué)習(xí)目標(biāo)跟蹤方法也歸屬于判別式框架。

開(kāi)始本文之前,我們首先看上方給出的3張圖片,它們分別是同一個(gè)視頻的第1,40,80幀。在第1幀給出一個(gè)跑步者的邊框(bounding-box)之后,后續(xù)的第40幀,80幀,bounding-box依然準(zhǔn)確圈出了同一個(gè)跑步者。以上展示的其實(shí)就是目標(biāo)跟蹤(visual object tracking)的過(guò)程。目標(biāo)跟蹤(特指單目標(biāo)跟蹤)是指:給出目標(biāo)在跟蹤視頻第一幀中的初始狀態(tài)(如位置,尺寸),自動(dòng)估計(jì)目標(biāo)物體在后續(xù)幀中的狀態(tài)。
人眼可以比較輕松的在一段時(shí)間內(nèi)跟住某個(gè)特定目標(biāo)。但是對(duì)機(jī)器而言,這一任務(wù)并不簡(jiǎn)單,尤其是跟蹤過(guò)程中會(huì)出現(xiàn)目標(biāo)發(fā)生劇烈形變、被其他目標(biāo)遮擋或出現(xiàn)相似物體干擾等等各種復(fù)雜的情況。過(guò)去幾十年以來(lái),目標(biāo)跟蹤的研究取得了長(zhǎng)足的發(fā)展,尤其是各種機(jī)器學(xué)習(xí)算法被引入以來(lái),目標(biāo)跟蹤算法呈現(xiàn)百花齊放的態(tài)勢(shì)。2013年以來(lái),深度學(xué)習(xí)方法開(kāi)始在目標(biāo)跟蹤領(lǐng)域展露頭腳,并逐漸在性能上超越傳統(tǒng)方法,取得巨大的突破。本文首先簡(jiǎn)要介紹主流的傳統(tǒng)目標(biāo)跟蹤方法,之后對(duì)基于深度學(xué)習(xí)的目標(biāo)跟蹤算法進(jìn)行介紹,最后對(duì)深度學(xué)習(xí)在目標(biāo)跟蹤領(lǐng)域的應(yīng)用進(jìn)行總結(jié)和展望。
經(jīng)典目標(biāo)跟蹤方法
目前跟蹤算法可以被分為產(chǎn)生式(generative model)和判別式(discriminative model)兩大類別。
產(chǎn)生式方法運(yùn)用生成模型描述目標(biāo)的表觀特征,之后通過(guò)搜索候選目標(biāo)來(lái)最小化重構(gòu)誤差。比較有代表性的算法有稀疏編碼(sparse coding),在線密度估計(jì)(online density estimation)和主成分分析(PCA)等。產(chǎn)生式方法著眼于對(duì)目標(biāo)本身的刻畫,忽略背景信息,在目標(biāo)自身變化劇烈或者被遮擋時(shí)容易產(chǎn)生漂移。
與之相對(duì)的,判別式方法通過(guò)訓(xùn)練分類器來(lái)區(qū)分目標(biāo)和背景。這種方法也常被稱為tracking-by-detection。近年來(lái),各種機(jī)器學(xué)習(xí)算法被應(yīng)用在判別式方法上,其中比較有代表性的有多示例學(xué)習(xí)方法(multiple instance learning), boosting和結(jié)構(gòu)SVM(structured SVM)等。判別式方法因?yàn)轱@著區(qū)分背景和前景的信息,表現(xiàn)更為魯棒,逐漸在目標(biāo)跟蹤領(lǐng)域占據(jù)主流地位。值得一提的是,目前大部分深度學(xué)習(xí)目標(biāo)跟蹤方法也歸屬于判別式框架。
近年來(lái),基于相關(guān)濾波(correlation filter)的跟蹤方法因?yàn)樗俣瓤?效果好吸引了眾多研究者的目光。相關(guān)濾波器通過(guò)將輸入特征回歸為目標(biāo)高斯分布來(lái)訓(xùn)練 filters。并在后續(xù)跟蹤中尋找預(yù)測(cè)分布中的響應(yīng)峰值來(lái)定位目標(biāo)的位置。相關(guān)濾波器在運(yùn)算中巧妙應(yīng)用快速傅立葉變換獲得了大幅度速度提升。目前基于相關(guān)濾波的拓展方法也有很多,包括核化相關(guān)濾波器(kernelized correlation filter, KCF), 加尺度估計(jì)的相關(guān)濾波器(DSST)等。
基于深度學(xué)習(xí)的目標(biāo)跟蹤方法
不同于檢測(cè)、識(shí)別等視覺(jué)領(lǐng)域深度學(xué)習(xí)一統(tǒng)天下的趨勢(shì),深度學(xué)習(xí)在目標(biāo)跟蹤領(lǐng)域的應(yīng)用并非一帆風(fēng)順。其主要問(wèn)題在于訓(xùn)練數(shù)據(jù)的缺失:深度模型的魔力之一來(lái)自于對(duì)大量標(biāo)注訓(xùn)練數(shù)據(jù)的有效學(xué)習(xí),而目標(biāo)跟蹤僅僅提供第一幀的bounding-box作為訓(xùn)練數(shù)據(jù)。這種情況下,在跟蹤開(kāi)始針對(duì)當(dāng)前目標(biāo)從頭訓(xùn)練一個(gè)深度模型困難重重。目前基于深度學(xué)習(xí)的目標(biāo)跟蹤算法采用了幾種思路來(lái)解決這個(gè)問(wèn)題,下面將依據(jù)思路的不同展開(kāi)介紹,并在最后介紹目前跟蹤領(lǐng)域出現(xiàn)的運(yùn)用遞歸神經(jīng)網(wǎng)絡(luò)(recurrent neural network)解決目標(biāo)跟蹤問(wèn)題的新思路。
利用輔助圖片數(shù)據(jù)預(yù)訓(xùn)練深度模型,在線跟蹤時(shí)微調(diào)
在目標(biāo)跟蹤的訓(xùn)練數(shù)據(jù)非常有限的情況下,使用輔助的非跟蹤訓(xùn)練數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練,獲取對(duì)物體特征的通用表示(general representation ),在實(shí)際跟蹤時(shí),通過(guò)利用當(dāng)前跟蹤目標(biāo)的有限樣本信息對(duì)預(yù)訓(xùn)練模型微調(diào)(fine-tune), 使模型對(duì)當(dāng)前跟蹤目標(biāo)有更強(qiáng)的分類性能,這種遷移學(xué)習(xí)的思路極大的減少了對(duì)跟蹤目標(biāo)訓(xùn)練樣本的需求,也提高了跟蹤算法的性能。
這個(gè)方面代表性的作品有DLT和SO-DLT,都出自香港科技大學(xué)王乃巖博士。
DLT(NIPS2013)
Learning a Deep Compact Image Representation for Visual Tracking
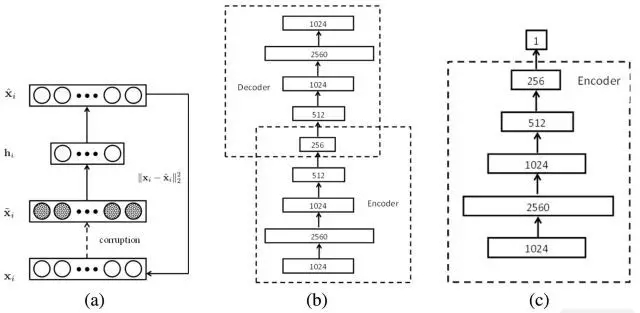
DLT是第一個(gè)把深度模型運(yùn)用在單目標(biāo)跟蹤任務(wù)上的跟蹤算法。它的主體思路如上圖所示:
(1) ? 先使用棧式降噪自編碼器(stacked denoising autoencoder,SDAE)在Tiny Images dataset這樣的大規(guī)模自然圖像數(shù)據(jù)集上進(jìn)行無(wú)監(jiān)督的離線預(yù)訓(xùn)練來(lái)獲得通用的物體表征能力。預(yù)訓(xùn)練的網(wǎng)絡(luò)結(jié)構(gòu)如上圖(b)所示,一共堆疊了4個(gè)降噪自編碼器, 降噪自編碼器對(duì)輸入加入噪聲,通過(guò)重構(gòu)出無(wú)噪聲的原圖來(lái)獲得更魯棒的特征表達(dá)能力。SDAE1024-2560-1024-512-256這樣的瓶頸式結(jié)構(gòu)設(shè)計(jì)也使獲得的特征更加compact。
(2) ? 之后的在線跟蹤部分結(jié)構(gòu)如上圖(c)所示,取離線SDAE的encoding部分疊加sigmoid分類層組成了分類網(wǎng)絡(luò)。此時(shí)的網(wǎng)絡(luò)并沒(méi)有獲取對(duì)當(dāng)前被跟蹤物體的特定表達(dá)能力。此時(shí)利用第一幀獲取正負(fù)樣本,對(duì)分類網(wǎng)絡(luò)進(jìn)行fine-tune獲得對(duì)當(dāng)前跟蹤目標(biāo)和背景更有針對(duì)性的分類網(wǎng)絡(luò)。在跟蹤過(guò)程中,對(duì)當(dāng)前幀采用粒子濾波(particle filter)的方式提取一批候選的patch(相當(dāng)于detection中的proposal),這些patch輸入分類網(wǎng)絡(luò)中,置信度較高的成為最終的預(yù)測(cè)目標(biāo)。
(3) ? 在目標(biāo)跟蹤非常重要的模型更新策略上,該論文采取限定閾值的方式,即當(dāng)所有粒子中較高的confidence低于閾值時(shí),認(rèn)為目標(biāo)已經(jīng)發(fā)生了比較大的表觀變化,當(dāng)前的分類網(wǎng)絡(luò)已經(jīng)無(wú)法適應(yīng),需要進(jìn)行更新。
小結(jié):DLT作為第一個(gè)將深度網(wǎng)絡(luò)運(yùn)用于單目標(biāo)跟蹤的跟蹤算法,首先提出了“離線預(yù)訓(xùn)練+在線微調(diào)”的思路,很大程度的解決了跟蹤中訓(xùn)練樣本不足的問(wèn)題,在CVPR2013提出的OTB50數(shù)據(jù)集上的29個(gè)跟蹤器中排名第5。
但是DLT本身也存在一些不足:
(1) ? 離線預(yù)訓(xùn)練采用的數(shù)據(jù)集Tiny Images dataset只包含32*32大小的圖片,分辨率明顯低于主要的跟蹤序列,因此SDAE很難學(xué)到足夠強(qiáng)的特征表示。
(2) ? 離線階段的訓(xùn)練目標(biāo)為圖片重構(gòu),這與在線跟蹤需要區(qū)分目標(biāo)和背景的目標(biāo)相差甚大。
(3) ? SDAE全連接的網(wǎng)絡(luò)結(jié)構(gòu)使其對(duì)目標(biāo)的特征刻畫能力不夠優(yōu)秀,雖然使用了4層的深度模型,但效果仍低于一些使用人工特征的傳統(tǒng)跟蹤方法如Struck等。
SO-DLT(arXiv2015)
Transferring Rich Feature Hierarchies for Robust Visual Tracking
SO-DLT延續(xù)了DLT利用非跟蹤數(shù)據(jù)預(yù)訓(xùn)練加在線微調(diào)的策略,來(lái)解決跟蹤過(guò)程中訓(xùn)練數(shù)據(jù)不足的問(wèn)題,同時(shí)也對(duì)DLT存在的問(wèn)題做了很大的改進(jìn)。

(1) ? 使用CNN作為獲取特征和分類的網(wǎng)絡(luò)模型。如上圖所示,SO-DLT使用了的類似AlexNet的網(wǎng)絡(luò)結(jié)構(gòu),但是有幾大特點(diǎn):一、針對(duì)跟蹤候選區(qū)域的大小將輸入縮小為100*100,而不是一般分類或檢測(cè)任務(wù)中的224*224。 二、網(wǎng)絡(luò)的輸出為50*50大小,值在0-1之間的概率圖(probability map),每個(gè)輸出像素對(duì)應(yīng)原圖2*2的區(qū)域,輸出值越高則該點(diǎn)在目標(biāo)bounding-box中的概率也越高。這樣的做法利用了圖片本身的結(jié)構(gòu)化信息,方便直接從概率圖確定最終的bounding-box,避免向網(wǎng)絡(luò)輸入數(shù)以百計(jì)的proposal,這也是SO-DLT structured output得名的由來(lái)。三、在卷積層和全連接層中間采用SPP-NET中的空間金字塔采樣(spatial pyramid pooling)來(lái)提高最終的定位準(zhǔn)確度。
(2) ? 在離線訓(xùn)練中使用ImageNet 2014的detection數(shù)據(jù)集使CNN獲得區(qū)分object和非object(背景)的能力。
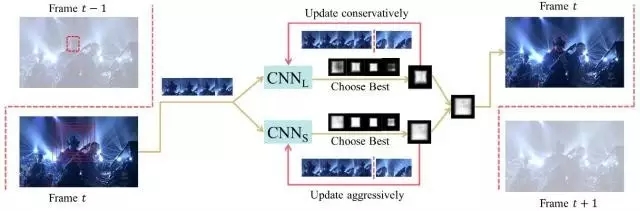
SO-DLT在線跟蹤的pipeline如上圖所示:
(1) ? 處理第t幀時(shí),首先以第t-1幀的的預(yù)測(cè)位置為中心,從小到大以不同尺度crop區(qū)域放入CNN當(dāng)中,當(dāng)CNN輸出的probability map的總和高于一定閾值時(shí),停止crop, 以當(dāng)前尺度作為較佳的搜索區(qū)域大小。
(2) ? 選定第t幀的較佳搜索區(qū)域后,在該區(qū)域輸出的probability map上采取一系列策略確定最終的bounding-box中心位置和大小。
(3) ? 在模型更新方面,為了解決使用不準(zhǔn)確結(jié)果fine-tune導(dǎo)致的drift問(wèn)題,使用了long-term 和short-term兩個(gè)CNN,即CNNS和CNNL。CNNS更新頻繁,使其對(duì)目標(biāo)的表觀變化及時(shí)響應(yīng)。CNNL更新較少,使其對(duì)錯(cuò)誤結(jié)果更加魯棒。二者結(jié)合,取最confident的結(jié)果作為輸出。從而在adaptation和drift之間達(dá)到一個(gè)均衡。
小結(jié):SO-DLT作為large-scale CNN網(wǎng)絡(luò)在目標(biāo)跟蹤領(lǐng)域的一次成功應(yīng)用,取得了非常優(yōu)異的表現(xiàn):在CVPR2013提出的OTB50數(shù)據(jù)集上OPE準(zhǔn)確度繪圖(precision plot)達(dá)到了0.819, OPE成功率繪圖(success plot)達(dá)到了0.602。遠(yuǎn)超當(dāng)時(shí)其它的state of the art。
SO-DLT有幾點(diǎn)值得借鑒:
(1) ? 針對(duì)tracking問(wèn)題設(shè)計(jì)了有針對(duì)性的網(wǎng)絡(luò)結(jié)構(gòu)。
(2) ? 應(yīng)用CNNS和CNNL用ensemble的思路解決update 的敏感性,特定參數(shù)取多值做平滑,解決參數(shù)取值的敏感性。這些措施目前已成為跟蹤算法提高評(píng)分的殺手锏。
但是SO-DLT離線預(yù)訓(xùn)練依然使用的是大量無(wú)關(guān)聯(lián)圖片,作者認(rèn)為使用更貼合跟蹤實(shí)質(zhì)的時(shí)序關(guān)聯(lián)數(shù)據(jù)是一個(gè)更好的選擇。
利用現(xiàn)有大規(guī)模分類數(shù)據(jù)集預(yù)訓(xùn)練的CNN分類網(wǎng)絡(luò)提取特征
2015年以來(lái),在目標(biāo)跟蹤領(lǐng)域應(yīng)用深度學(xué)習(xí)興起了一股新的潮流。即直接使用ImageNet這樣的大規(guī)模分類數(shù)據(jù)庫(kù)上訓(xùn)練出的CNN網(wǎng)絡(luò)如VGG-Net獲得目標(biāo)的特征表示,之后再用觀測(cè)模型(observation model)進(jìn)行分類獲得跟蹤結(jié)果。這種做法既避開(kāi)了跟蹤時(shí)直接訓(xùn)練large-scale CNN樣本不足的困境,也充分利用了深度特征強(qiáng)大的表征能力。這樣的工作在ICML15,ICCV15,CVPR16均有出現(xiàn)。下面介紹兩篇發(fā)表于ICCV15的工作。
FCNT(ICCV15)
Visual Tracking with Fully Convolutional Networks
作為應(yīng)用CNN特征于物體跟蹤的代表作品,F(xiàn)CNT的亮點(diǎn)之一在于對(duì)ImageNet上預(yù)訓(xùn)練得到的CNN特征在目標(biāo)跟蹤任務(wù)上的性能做了深入的分析,并根據(jù)分析結(jié)果設(shè)計(jì)了后續(xù)的網(wǎng)絡(luò)結(jié)構(gòu)。
FCNT主要對(duì)VGG-16的Conv4-3和Conv5-3層輸出的特征圖譜(feature map)做了分析,并得出以下結(jié)論:
(1) ? CNN 的feature map可以用來(lái)做跟蹤目標(biāo)的定位。
(2) ? CNN 的許多feature map存在噪聲或者和物體跟蹤區(qū)分目標(biāo)和背景的任務(wù)關(guān)聯(lián)較小。
(3) ? CNN不同層的特征特點(diǎn)不一。高層(Conv5-3)特征擅長(zhǎng)區(qū)分不同類別的物體,對(duì)目標(biāo)的形變和遮擋非常魯棒,但是對(duì)類內(nèi)物體的區(qū)分能力非常差。低層(Conv4-3)特征更關(guān)注目標(biāo)的局部細(xì)節(jié),可以用來(lái)區(qū)分背景中相似的distractor,但是對(duì)目標(biāo)的劇烈形變非常不魯棒。
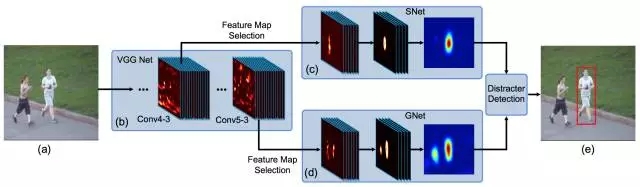
依據(jù)以上分析,F(xiàn)CNT最終形成了如上圖所示的框架結(jié)構(gòu):
(1) ? 對(duì)于Conv4-3和Conv5-3特征分別構(gòu)建特征選擇網(wǎng)絡(luò)sel-CNN(1層dropout加1層卷積),選出和當(dāng)前跟蹤目標(biāo)最相關(guān)的feature map channel。
(2) ? 對(duì)篩選出的Conv5-3和Conv4-3特征分別構(gòu)建捕捉類別信息的GNet和區(qū)分distractor(背景相似物體)的SNet(都是兩層卷積結(jié)構(gòu))。
(3) ? 在第一幀中使用給出的bounding-box生成熱度圖(heat map)回歸訓(xùn)練sel-CNN, GNet和SNet。
(4) ? 對(duì)于每一幀,以上一幀預(yù)測(cè)結(jié)果為中心crop出一塊區(qū)域,之后分別輸入GNet和SNet,得到兩個(gè)預(yù)測(cè)的heatmap,并根據(jù)是否有distractor決定使用哪個(gè)heatmap 生成最終的跟蹤結(jié)果。
小結(jié):FCNT根據(jù)對(duì)CNN不同層特征的分析,構(gòu)建特征篩選網(wǎng)絡(luò)和兩個(gè)互補(bǔ)的heat-map預(yù)測(cè)網(wǎng)絡(luò)。達(dá)到有效抑制distractor防止跟蹤器漂移,同時(shí)對(duì)目標(biāo)本身的形變更加魯棒的效果,也是ensemble思路的又一成功實(shí)現(xiàn)。在CVPR2013提出的OTB50數(shù)據(jù)集上OPE準(zhǔn)確度繪圖(precision plot)達(dá)到了0.856,OPE成功率繪圖(success plot)達(dá)到了0.599,準(zhǔn)確度繪圖有較大提高。實(shí)際測(cè)試中FCNT的對(duì)遮擋的表現(xiàn)不是很魯棒,現(xiàn)有的更新策略還有提高空間。
Hierarchical Convolutional Features for Visual Tracking(ICCV15)
這篇是作者在2015年度看到的最簡(jiǎn)潔有效的利用深度特征做跟蹤的論文。其主要思路是提取深度特征,之后利用相關(guān)濾波器確定最終的bounding-box。
這篇論文簡(jiǎn)要分析了VGG-19特征( Conv3_4, Conv4_4, Conv5_4 )在目標(biāo)跟蹤上的特性,得出的結(jié)論和FCNT有異曲同工之處,即:
(1) ? 高層特征主要反映目標(biāo)的語(yǔ)義特性,對(duì)目標(biāo)的表觀變化比較魯棒。
(2) ? 低層特征保存了更多細(xì)粒度的空間特性,對(duì)跟蹤目標(biāo)的較精確定位更有效。
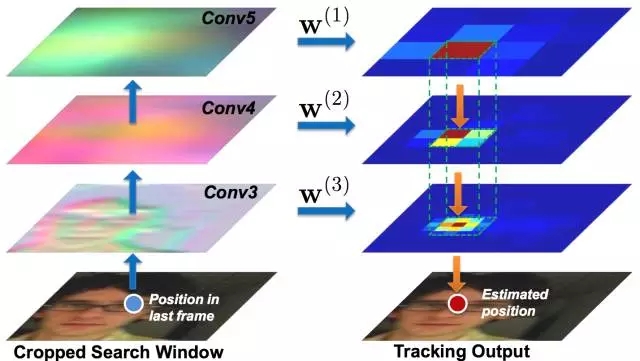
基于以上結(jié)論,作者給出了一個(gè)粗粒度到細(xì)粒度(coarse-to-fine)的跟蹤算法即:
(1) ? 第一幀時(shí),利用Conv3_4,Conv4_4,Conv5_4特征的插值分別訓(xùn)練得到3個(gè)相關(guān)濾波器。
(2) ? 之后的每幀,以上一幀的預(yù)測(cè)結(jié)果為中心crop出一塊區(qū)域,獲取三個(gè)卷積層的特征,做插值,并通過(guò)每層的相關(guān)濾波器預(yù)測(cè)二維的confidence score。
(3) ? 從Conv5_4開(kāi)始算出confidence score上較大的響應(yīng)點(diǎn),作為預(yù)測(cè)的bounding-box的中心位置,之后以這個(gè)位置約束下一層的搜索范圍,逐層向下做更細(xì)粒度的位置預(yù)測(cè),以較低層的預(yù)測(cè)結(jié)果作為最后輸出。具體公式如下:
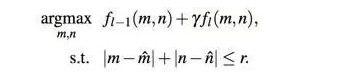
(4) ? 利用當(dāng)前跟蹤結(jié)果對(duì)每一層的相關(guān)濾波器做更新。
小結(jié):這篇文章針對(duì)VGG-19各層特征的特點(diǎn),由粗粒度到細(xì)粒度最終準(zhǔn)確定位目標(biāo)的中心點(diǎn)。在CVPR2013提出的OTB50數(shù)據(jù)集上OPE準(zhǔn)確度繪圖達(dá)到了0.891,OPE成功率繪圖達(dá)到了0.605,相較于FCNT和SO-DLT都有提高,實(shí)際測(cè)試時(shí)性能也相當(dāng)穩(wěn)定,顯示出深度特征結(jié)合相關(guān)濾波器的巨大優(yōu)勢(shì)。但是這篇文章中的相關(guān)濾波器并沒(méi)有對(duì)尺度進(jìn)行處理,在整個(gè)跟蹤序列中都假定目標(biāo)尺度不變。在一些尺度變化非常劇烈的測(cè)試序列上如CarScale上最終預(yù)測(cè)出的bounding-box尺寸大小和目標(biāo)本身大小相差較大。
以上兩篇文章均是應(yīng)用預(yù)訓(xùn)練的CNN網(wǎng)絡(luò)提取特征提高跟蹤性能的成功案例,說(shuō)明利用這種思路解決訓(xùn)練數(shù)據(jù)缺失和提高性能具有很高的可行性。但是分類任務(wù)預(yù)訓(xùn)練的CNN網(wǎng)絡(luò)本身更關(guān)注區(qū)分類間物體,忽略類內(nèi)差別。目標(biāo)跟蹤時(shí)只關(guān)注一個(gè)物體,重點(diǎn)區(qū)分該物體和背景信息,明顯抑制背景中的同類物體,但是還需要對(duì)目標(biāo)本身的變化魯棒。分類任務(wù)以相似的一眾物體為一類,跟蹤任務(wù)以同一個(gè)物體的不同表觀為一類,使得這兩個(gè)任務(wù)存在很大差別,這也是兩篇文章融合多層特征來(lái)做跟蹤以達(dá)到較理想效果的動(dòng)機(jī)所在。
利用跟蹤序列預(yù)訓(xùn)練,在線跟蹤時(shí)微調(diào)
1和2中介紹的解決訓(xùn)練數(shù)據(jù)不足的策略和目標(biāo)跟蹤的任務(wù)本身存在一定偏離。有沒(méi)有更好的辦法呢?VOT2015冠軍MDNet給出了一個(gè)示范。該方法在OTB50上也取得了OPE準(zhǔn)確度繪圖0.942,OPE成功率繪圖0.702的驚人得分。
MDNet(CVPR2016)
Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
意識(shí)到圖像分類任務(wù)和跟蹤之間存在巨大差別,MDNet提出直接用跟蹤視頻預(yù)訓(xùn)練CNN獲得general的目標(biāo)表示能力的方法。但是序列訓(xùn)練也存在問(wèn)題,即不同跟蹤序列跟蹤目標(biāo)完全不一樣,某類物體在一個(gè)序列中是跟蹤目標(biāo),在另外一個(gè)序列中可能只是背景。不同序列中目標(biāo)本身的表觀和運(yùn)動(dòng)模式、環(huán)境中光照、遮擋等情形相差甚大。這種情況下,想要用同一個(gè)CNN完成所有訓(xùn)練序列中前景和背景區(qū)分的任務(wù),困難重重。
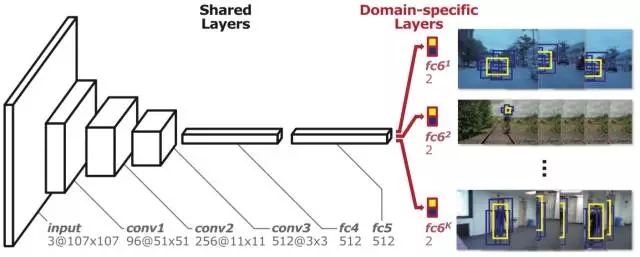
最終MDNet提出Multi-Domain的訓(xùn)練思路和如上圖所示的Multi-Domain Network。該網(wǎng)絡(luò)分為共享層和domain-specific層兩部分。即:將每個(gè)訓(xùn)練序列當(dāng)成一個(gè)多帶帶的domain,每個(gè)domain都有一個(gè)針對(duì)它的二分類層(fc6),用于區(qū)分當(dāng)前序列的前景和背景,而網(wǎng)絡(luò)之前的所有層都是序列共享的。這樣共享層達(dá)到了學(xué)習(xí)跟蹤序列中目標(biāo)general的特征表達(dá)的目的,而domain-specific層又解決了不同訓(xùn)練序列分類目標(biāo)不一致的問(wèn)題。
具體訓(xùn)練時(shí),MDNet的每個(gè)mini-batch只由一個(gè)特定序列的訓(xùn)練數(shù)據(jù)構(gòu)成,只更新共享層和針對(duì)當(dāng)前序列的特定fc6層。這樣共享層中獲得了對(duì)序列共有特征的表達(dá)能力,如對(duì)光照、形變等的魯棒性。MDNet的訓(xùn)練數(shù)據(jù)也非常有意思,即測(cè)試OTB100數(shù)據(jù)集時(shí),利用VOT2013-2015的不重合的58個(gè)序列來(lái)做預(yù)訓(xùn)練。測(cè)試VOT2014數(shù)據(jù)集時(shí),利用OTB100上不重合的89個(gè)序列做預(yù)訓(xùn)練。這種交替利用的思路也是第一次在跟蹤論文中出現(xiàn)。
在線跟蹤階段針對(duì)每個(gè)跟蹤序列,MDNet主要有以下幾步:
(1) ? 隨機(jī)初始化一個(gè)新的fc6層。
(2) ? 使用第一幀的數(shù)據(jù)來(lái)訓(xùn)練該序列的bounding box回歸模型。
(3) ? 用第一幀提取正樣本和負(fù)樣本,更新fc4, fc5和fc6層的權(quán)重。
(4) ? 之后產(chǎn)生256個(gè)候選樣本,并從中選擇置信度較高的,之后做bounding-box regression得到最終結(jié)果。
(5) ? 當(dāng)前幀最終結(jié)果置信度較高時(shí),采樣更新樣本庫(kù),否則根據(jù)情況對(duì)模型做短期或者長(zhǎng)期更新。
MDNet有兩點(diǎn)值得借鑒之處:
(1) ? MDNet應(yīng)用了更為貼合跟蹤實(shí)質(zhì)的視頻數(shù)據(jù)來(lái)做訓(xùn)練,并提出了創(chuàng)新的Multi-domain訓(xùn)練方法和訓(xùn)練數(shù)據(jù)交叉運(yùn)用的思路。
(2) ? 此外MDNet從檢測(cè)任務(wù)中借鑒了不少行之有效的策略,如難例挖掘(hard negative mining),bounding box回歸等。尤其是難例回歸通過(guò)重點(diǎn)關(guān)注背景中的難點(diǎn)樣本(如相似物體等)顯著減輕了跟蹤器漂移的問(wèn)題。這些策略也幫助MDNet在TPAMI2015 OTB100數(shù)據(jù)集上OPE準(zhǔn)確度繪圖從一開(kāi)始的0.825提升到0.908, OPE成功率繪圖從一開(kāi)始的0.589提升到0.673。
但是也可以發(fā)現(xiàn)MDNet的總體思路和RCNN比較類似,需要前向傳遞上百個(gè)proposal,雖然網(wǎng)絡(luò)結(jié)構(gòu)較小,速度仍較慢。且boundingbox回歸也需要多帶帶訓(xùn)練,因此MDNet還有進(jìn)一步提升的空間。
運(yùn)用遞歸神經(jīng)網(wǎng)絡(luò)進(jìn)行目標(biāo)跟蹤的新思路
近年來(lái)RNN尤其是帶有門結(jié)構(gòu)的LSTM,GRU等在時(shí)序任務(wù)上顯示出了突出的性能。不少研究者開(kāi)始探索如何應(yīng)用RNN來(lái)做解決現(xiàn)有跟蹤任務(wù)中存在的問(wèn)題,以下簡(jiǎn)要介紹兩篇在這方面比較有代表性的探索文章。
RTT(CVPR16)
Recurrently Target-Attending Tracking
這篇文章的出發(fā)點(diǎn)比較有意思,即利用多方向遞歸神經(jīng)網(wǎng)絡(luò)(multi-directional recurrent neural network)來(lái)建模和挖掘?qū)φw跟蹤有用的可靠目標(biāo)部分(reliable part),實(shí)際上是二維平面上的RNN建模,最終解決預(yù)測(cè)誤差累積和傳播導(dǎo)致的跟蹤漂移問(wèn)題。其本身也是對(duì)part-based跟蹤方法和相關(guān)濾波(correlation filter)方法的改進(jìn)和探索。
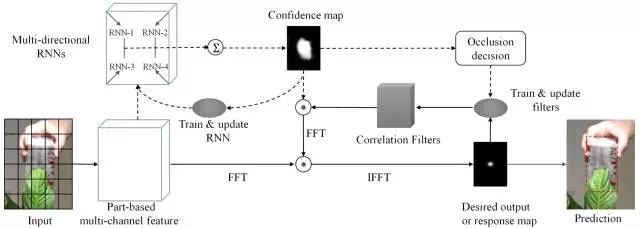
RTT的整體框架如上圖所示:
(1) ? 首先對(duì)每一幀的候選區(qū)域進(jìn)行網(wǎng)狀分塊,對(duì)每個(gè)分塊提取HOG特征,最終相連獲得基于塊的特征
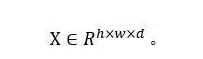
(2) ? 得到分塊特征以后,RTT利用前5幀訓(xùn)練多方向RNN來(lái)學(xué)習(xí)分塊之間大范圍的空間關(guān)聯(lián)。
通過(guò)在4個(gè)方向上的前向推進(jìn),RNN計(jì)算出每個(gè)分塊的置信度,最終每個(gè)塊的預(yù)測(cè)值組成了整個(gè)候選區(qū)域的置信圖(confidence map)。受益于RNN的recurrent結(jié)構(gòu),每個(gè)分塊的輸出值都受到其他關(guān)聯(lián)分塊的影響,相比于僅僅考慮當(dāng)前塊的準(zhǔn)確度更高,避免單個(gè)方向上遮擋等的影響,增加可靠目標(biāo)部分在整體置信圖中的影響。
(3) ? 由RNN得出置信圖之后,RTT執(zhí)行了另外一條pipeline。即訓(xùn)練相關(guān)濾波器來(lái)獲得最終的跟蹤結(jié)果。值得注意的是,在訓(xùn)練過(guò)程中RNN的置信圖對(duì)不同塊的filter做了加權(quán),達(dá)到抑制背景中的相似物體,增強(qiáng)可靠部分的效果。
(4) ? RTT提出了一個(gè)判斷當(dāng)前跟蹤物體是否被遮擋的策略,用其判斷是否更新。即計(jì)算目標(biāo)區(qū)域的置信度和,并與歷史置信度和的移動(dòng)平均數(shù)(moving average)做一個(gè)對(duì)比,低于一定比例,則認(rèn)為受到遮擋,停止模型更新,防止引入噪聲。
小結(jié):RTT是第一個(gè)利用RNN來(lái)建模part-based跟蹤任務(wù)中復(fù)雜的大范圍關(guān)聯(lián)關(guān)系的跟蹤算法。在CVPR2013提出的OTB50數(shù)據(jù)集上OPE準(zhǔn)確度繪圖為0.827,OPE成功率繪圖達(dá)到了0.588。相比于其他基于傳統(tǒng)特征的相關(guān)濾波器算法有較大的提升,說(shuō)明RNN對(duì)關(guān)聯(lián)關(guān)系的挖掘和對(duì)濾波器的約束確實(shí)有效。RTT受制于參數(shù)數(shù)目的影響,只選用了參數(shù)較少的普通RNN結(jié)構(gòu)(采用HOG特征其實(shí)也是降低參數(shù)的另外一種折中策略)。結(jié)合之前介紹的解決訓(xùn)練數(shù)據(jù)缺失的措施,RTT可以運(yùn)用更好的特征和RNN結(jié)構(gòu),效果還有提升空間。
DeepTracking: Seeing Beyond Seeing Using Recurrent Neural Networks(AAAI16)
這篇文章的應(yīng)用場(chǎng)景是機(jī)器人視覺(jué),目標(biāo)是將傳感器獲得的有遮擋的環(huán)境信息還原為真實(shí)的無(wú)遮擋的環(huán)境信息。嚴(yán)格來(lái)說(shuō)這篇文章僅輸出還原后的圖片,沒(méi)有明確預(yù)測(cè)目標(biāo)的位置和尺寸等狀態(tài)信息,和之前介紹的所有文章的做法都不一樣,不妨稱為一種新的跟蹤任務(wù)。
在模型方面,不同于RTT用RNN建模二維平面關(guān)聯(lián),DeepTracking利用RNN來(lái)做序列關(guān)聯(lián)的建模,并最終實(shí)現(xiàn)了端到端的跟蹤算法。
傳統(tǒng)的貝葉斯跟蹤方法一般采用高斯分布(卡爾曼濾波Kalman filter)或者離散的采樣點(diǎn)權(quán)重(粒子濾波particle filter)來(lái)近似需要求解的后驗(yàn)概率 P(yt|x1:t) (yt 為需要預(yù)測(cè)的機(jī)器人周圍的真實(shí)場(chǎng)景, xt 為傳感器直接獲得的場(chǎng)景信息),其表達(dá)能力有限。DeepTracking拓展了傳統(tǒng)的貝葉斯跟蹤框架,并利用RNN強(qiáng)大的表征能力來(lái)建模后驗(yàn)概率。
具體而言DeepTracking引入了一個(gè)具有馬爾可夫性質(zhì)的隱變量 ht ,認(rèn)為其反映了真實(shí)環(huán)境的全部信息。最終需要預(yù)測(cè)的 yt 包含了 ht,包含了 ht 的部分信息,可由 ht 得到。假設(shè) Bt 為關(guān)于 ht 的信念(belief),對(duì)應(yīng)于后驗(yàn)概率:Bel(ht) = P(yt|ht) 。之后經(jīng)典貝葉斯跟蹤框架中由 P(yt-1|x1:t-1) 到 P(yt|x1:t) 到的時(shí)序更新在這里轉(zhuǎn)化為:Bt = F(Bt-1,xt)和 P(ty|x1:t) = P(yt|Bt)。
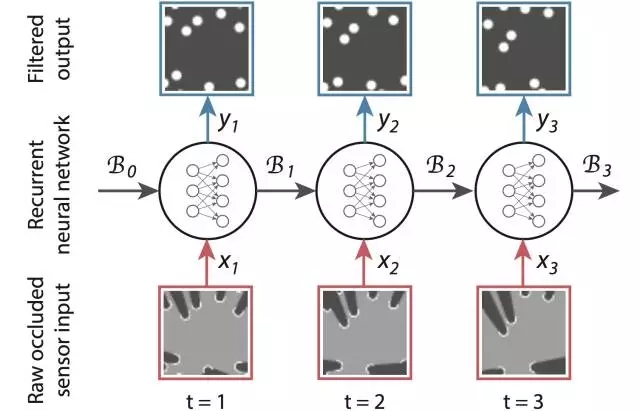
給出形式表達(dá)之后的關(guān)鍵是,如何將其對(duì)應(yīng)到RNN的框架中去。DeepTracking的核心思路是用利用兩個(gè)權(quán)重 WF 和 WP 來(lái)分別建模 F(Bt-1, xt)和P(yt|Bt ),將Bt 定義為RNN時(shí)序之間傳遞的memory 信息。此時(shí),如上圖所示RNN的各個(gè)狀態(tài)和推進(jìn)流程就和跟蹤任務(wù)完美的對(duì)接上了。
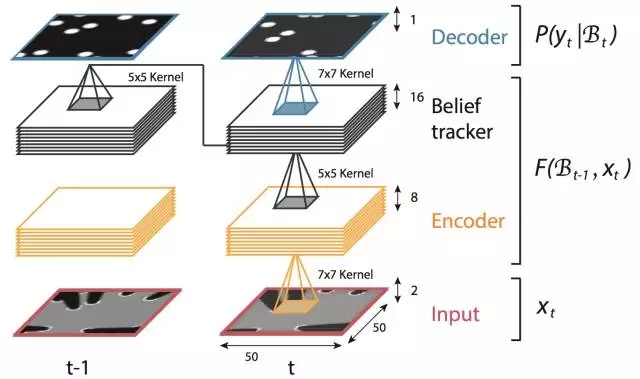
實(shí)驗(yàn)部分,DeepTracking采用模擬的2維傳感器數(shù)據(jù)和如上圖所示的3層RNN的網(wǎng)絡(luò)結(jié)構(gòu),Bt 對(duì)應(yīng)于第三層的網(wǎng)絡(luò)輸出。通過(guò)無(wú)監(jiān)督的預(yù)測(cè) xt+n 的任務(wù)來(lái)使網(wǎng)絡(luò)獲得預(yù)測(cè) yt 的潛在能力。
小結(jié):DeepTracking作為用RNN建模跟蹤時(shí)序任務(wù)的作品,其亮點(diǎn)主要在對(duì)RNN和貝葉斯框架融合的理論建模上。實(shí)驗(yàn)展示了該方法在模擬場(chǎng)景下的不錯(cuò)效果,但是模擬數(shù)據(jù)和真實(shí)場(chǎng)景差距很大,能否在實(shí)際應(yīng)用中有比較好的表現(xiàn)還有待商榷。
總結(jié)
本文介紹了深度學(xué)習(xí)在目標(biāo)跟蹤領(lǐng)域應(yīng)用的幾種不同思路。三種解決訓(xùn)練數(shù)據(jù)缺失的思路各有千秋,作者認(rèn)為使用序列預(yù)訓(xùn)練的方法更貼合跟蹤任務(wù)的本質(zhì)因此值得關(guān)注(近期也有應(yīng)用Siamese Network和視頻數(shù)據(jù)訓(xùn)練的跟蹤算法涌現(xiàn),具體參見(jiàn)王乃巖博士在VLASE公眾號(hào)上的介紹文章《Object Tracking新思路》)。總的來(lái)說(shuō),基于RNN的目標(biāo)跟蹤算法還有很大提升空間。此外,目前已有的深度學(xué)習(xí)目標(biāo)跟蹤方法還很難滿足實(shí)時(shí)性的要求,如何設(shè)計(jì)網(wǎng)絡(luò)和跟蹤流程達(dá)到速度和效果的提升,還有很大的研究空間。
致謝:本文作者特此感謝匿名審稿人和圖森科技首席科學(xué)家王乃巖博士對(duì)本文所提出的建設(shè)性意見(jiàn)。
歡迎加入本站公開(kāi)興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉(cāng)庫(kù),數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識(shí)
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請(qǐng)注明本文地址:http://specialneedsforspecialkids.com/yun/4405.html
摘要:本屆會(huì)議共收到論文篇,創(chuàng)下歷史記錄有效篇。會(huì)議接收論文篇接收率。大會(huì)共有位主旨演講人。同樣,本屆較佳學(xué)生論文斯坦福大學(xué)的,也是使用深度學(xué)習(xí)做圖像識(shí)別。深度學(xué)習(xí)選擇深度學(xué)習(xí)選擇不過(guò),也有人對(duì)此表示了擔(dān)心。指出,這并不是做學(xué)術(shù)研究的方法。 2016年的計(jì)算機(jī)視覺(jué)領(lǐng)域國(guó)際頂尖會(huì)議 Computer Vision and Pattern Recognition conference(CVPR2016...
摘要:這是機(jī)器學(xué)習(xí)課程中的一個(gè)典型例子,他把演講者的聲音和背景音樂(lè)分開(kāi)。雖然用于啟動(dòng)檢測(cè)的技術(shù)主要依賴于音頻特征工程和機(jī)器學(xué)習(xí),但在這里可以很容易地使用深度學(xué)習(xí)來(lái)優(yōu)化結(jié)果。 介紹 想象一個(gè)能理解你想要什么,且當(dāng)你打電話給客戶服務(wù)中心時(shí)能理解你的感受的機(jī)器--如果你對(duì)某件事感到不高興,你可以很快地和一個(gè)人交談。如果您正在尋找特定的信息,您可能不需要與某人交談(除非您愿意!)。 ...
早期成果卷積神經(jīng)網(wǎng)絡(luò)是各種深度神經(jīng)網(wǎng)絡(luò)中應(yīng)用最廣泛的一種,在機(jī)器視覺(jué)的很多問(wèn)題上都取得了當(dāng)前較好的效果,另外它在自然語(yǔ)言處理,計(jì)算機(jī)圖形學(xué)等領(lǐng)域也有成功的應(yīng)用。第一個(gè)真正意義上的卷積神經(jīng)網(wǎng)絡(luò)由LeCun在1989年提出[1],后來(lái)進(jìn)行了改進(jìn),它被用于手寫字符的識(shí)別,是當(dāng)前各種深度卷積神經(jīng)網(wǎng)絡(luò)的鼻祖。接下來(lái)我們介紹LeCun在早期提出的3種卷積網(wǎng)絡(luò)結(jié)構(gòu)。?文獻(xiàn)[1]的網(wǎng)絡(luò)由卷積層和全連接層構(gòu)成,網(wǎng)絡(luò)...

閱讀 1307·2021-11-04 16:09
閱讀 3504·2021-10-19 11:45
閱讀 2400·2021-10-11 10:59
閱讀 1015·2021-09-23 11:21
閱讀 2766·2021-09-22 10:54
閱讀 1139·2019-08-30 15:53
閱讀 2607·2019-08-30 15:53
閱讀 3481·2019-08-30 12:57




