資訊專欄INFORMATION COLUMN

摘要:于是,中將做了拆解,認(rèn)為中生成模型應(yīng)該包含的先驗(yàn)分成兩種不能再做壓縮的和可解釋地有隱含意義的一組隱變量,簡(jiǎn)寫(xiě)為。利用這種更加細(xì)致的隱變量建模控制,可以說(shuō)將的發(fā)展又推動(dòng)了一步。
摘要
在過(guò)去一兩年中,生成式模型 Generative Adversarial Networks(GAN)的新興為生成式任務(wù)帶來(lái)了不小的進(jìn)展。盡管 GAN 在被提出時(shí)存在訓(xùn)練不穩(wěn)定等諸多問(wèn)題,但后來(lái)的研究者們分別從模型、訓(xùn)練技巧和理論等方面對(duì)它做了改進(jìn)。本文旨在梳理這些相關(guān)工作。
盡管大部分時(shí)候,有監(jiān)督學(xué)習(xí)比無(wú)監(jiān)督的能獲得更好的訓(xùn)練效果。但真實(shí)世界中,有監(jiān)督學(xué)習(xí)需要的數(shù)據(jù)標(biāo)注(label)是相對(duì)少的。所以研究者們從未放棄去探索更好的無(wú)監(jiān)督學(xué)習(xí)策略,希望能從海量的無(wú)標(biāo)注數(shù)據(jù)中學(xué)到對(duì)于這個(gè)真實(shí)世界的表示(representation)甚至知識(shí),從而去更好地理解我們的真實(shí)世界。
評(píng)價(jià)無(wú)監(jiān)督學(xué)習(xí)好壞的方式有很多,其中生成任務(wù)就是最直接的一個(gè)。只有當(dāng)我們能生成/創(chuàng)造我們的真實(shí)世界,才能說(shuō)明我們是完完全全理解了它。然而,生成任務(wù)所依賴的生成式模型(generative models)往往會(huì)遇到兩大困難。首先是我們需要大量的先驗(yàn)知識(shí)去對(duì)真實(shí)世界進(jìn)行建模,其中包括選擇什么樣的先驗(yàn)、什么樣的分布等等。而建模的好壞直接影響著我們的生成模型的表現(xiàn)。另一個(gè)困難是,真實(shí)世界的數(shù)據(jù)往往很復(fù)雜,我們要用來(lái)擬合模型的計(jì)算量往往非常龐大,甚至難以承受。
而在過(guò)去一兩年中,有一個(gè)讓人興奮的新模型,則很好地避開(kāi)了這兩大困難。這個(gè)模型叫做 Generative Adversarial Networks(GAN),由 [1] 提出。在原始的 GAN paper [1] 中,作者是用博弈論來(lái)闡釋了 GAN 框架背后的思想。每一個(gè) GAN 框架,都包含著一對(duì)模型 —— 一個(gè)生成模型(G)和一個(gè)判別模型(D)。因?yàn)?D 的存在,才使得 GAN 中的 G 不再需要對(duì)于真實(shí)數(shù)據(jù)的先驗(yàn)知識(shí)和復(fù)雜建模,也能學(xué)習(xí)去逼近真實(shí)數(shù)據(jù),最終讓其生成的數(shù)據(jù)達(dá)到以假亂真的地步 —— D 也無(wú)法分別 —— 從而 G 和 D 達(dá)到了某種納什均衡。[1] 的作者曾在他們的 slides 中,給出過(guò)一個(gè)比喻:在 GAN 中,生成模型(G)和判別模型(D)是小偷與警察的關(guān)系。G 生成的數(shù)據(jù),目標(biāo)是要騙過(guò)身為警察的判別模型(D)。也就是說(shuō),G 作為小偷,要盡可能地提高自己的偷竊手段,而 D 作為警察也要盡可能地提高自己的業(yè)務(wù)水平防止被欺騙。所以,GAN 框架下的學(xué)習(xí)過(guò)程就變成了一種生成模型 (G) 和判別模型 (D) 之間的競(jìng)爭(zhēng)過(guò)程 —— 隨機(jī)從真實(shí)樣本和由生成模型 (G) 生成出的 “假樣本” 中取一個(gè),讓判別模型 (D) 去判斷是否為真。所以,體現(xiàn)在公式上,就是下面這樣一個(gè) minmax 的形式。
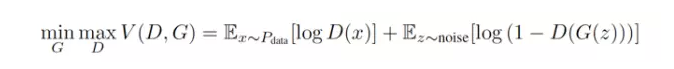
然而,GAN 雖然不再需要預(yù)先建模,但這個(gè)優(yōu)點(diǎn)同時(shí)也帶來(lái)了一些麻煩。那就是盡管它用一個(gè) noise z 作為先驗(yàn),但生成模型如何利用這個(gè) z,是無(wú)法控制的。也就是說(shuō),GAN 的學(xué)習(xí)模式太過(guò)于自由了,使得 GAN 的訓(xùn)練過(guò)程和訓(xùn)練結(jié)果很多時(shí)候都不太可控。為了穩(wěn)定 GAN ,后來(lái)的研究者們分別從 heuristic 、 模型改進(jìn)和理論分析的角度上提出了許多訓(xùn)練技巧和改進(jìn)方法。
比如在原始 GAN 論文 [1] 中,每次學(xué)習(xí)參數(shù)的更新過(guò)程,被設(shè)為 D 更新 k 回, G 才更新 1 回,就是出于減少 G 的 “自由度” 的考慮。

另一篇重量級(jí)的關(guān)于 GAN 訓(xùn)練技巧的研究的工作便是 Deep Convolutional Generative Adversarial Networks(DCGAN)[6] 。[6] 中總結(jié)了許多對(duì)于 GAN 這的網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)和針對(duì) CNN 這種網(wǎng)絡(luò)的訓(xùn)練經(jīng)驗(yàn)。比如,他們用 strided convolutional networks 替代傳統(tǒng) CNN 中的 pooling 層,從而將 GAN 中的生成模型 (G)變成了 fully differentiable 的,結(jié)果使得 GAN 的訓(xùn)練更加穩(wěn)定和可控。
為了提高訓(xùn)練的穩(wěn)定性,另一個(gè)很自然的角度就是改變學(xué)習(xí)方法。把純無(wú)監(jiān)督的 GAN 變成半監(jiān)督或者有監(jiān)督的。這便可以為 GAN 的訓(xùn)練加上一點(diǎn)點(diǎn)束縛,或者說(shuō)加上一點(diǎn)點(diǎn)目標(biāo)。[2] 中提出的 Conditional Generative Adversarial Nets (CGAN)便是十分直接的模型改變,在生成模型(G)和判別模型(D)的建模中均引入 conditional variable y,這個(gè) y 就是數(shù)據(jù)的一種 label。也因此,CGAN 可以看做把無(wú)監(jiān)督的 GAN 變成有監(jiān)督的模型的一種改進(jìn)。這個(gè)簡(jiǎn)單直接的改進(jìn)被證明非常有效,并廣泛用于后續(xù)的相關(guān)工作中。
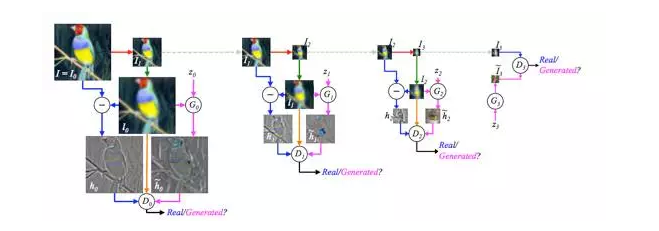
第三種改進(jìn) GAN 過(guò)于自由的思路,和第一種會(huì)比較相似。既然太難控制 GAN 的學(xué)習(xí),不如我們就拆解一下,不要讓 GAN 一次學(xué)完全部的數(shù)據(jù),而是讓 GAN 一步步完成這個(gè)學(xué)習(xí)過(guò)程。具體到圖片生成來(lái)說(shuō)就是,不要讓 GAN 中的生成模型(G)每次都直接生成一整張圖片,而是讓它生成圖片的一部分。這個(gè)思想可以認(rèn)為是 DeepMind 也很有名的工作 DRAW 的一種變形。DRAW 的論文 [3] 開(kāi)篇就說(shuō),我們?nèi)祟愒诶L制一張圖片時(shí),很少是一筆完成的。既然我們?nèi)祟惗疾皇沁@樣,為什么我們要寄希望于機(jī)器可以做到呢?論文 [4] 中提出的 LAPGAN 就是基于這個(gè)思想,將 GAN 的學(xué)習(xí)過(guò)程變成了 sequential “序列式” 的。 具體上,LAPGAN 采用了 Laplacian Pyramid 實(shí)現(xiàn)了 “序列化” ,也因此起名做 LAPGAN 。值得一提的是,這個(gè) LAPGAN 中也有 “殘差” 學(xué)習(xí)的思想(與后來(lái)大火的 ResNet 也算是有一點(diǎn)關(guān)聯(lián))。在學(xué)習(xí)序列中,LAPGAN 不斷地進(jìn)行 downsample 和 upsample 操作,然后在每一個(gè) Pyramid level 中,只將殘差傳遞給判別模型(D)進(jìn)行判斷。這樣的 sequential + 殘差結(jié)合的方式,能有效減少 GAN 需要學(xué)習(xí)的內(nèi)容和難度,從而達(dá)到了 “輔助” GAN 學(xué)習(xí)的目的。
另一個(gè)基于 sequential 思想去改進(jìn) GAN 的工作來(lái)自于 [5] 中的 GRAN。與 LAPGAN [4] 每一個(gè) sequential step(Pyramid level)都是獨(dú)立訓(xùn)練的不同的是,GRAN 把 GAN 和 LSTM 結(jié)合,讓 sequence 中的每一步學(xué)習(xí)和生成能充分利用上一步的結(jié)果。具體上來(lái)看,GRAN 的每一步都有一個(gè)像 LSTM 中的 cell,C_t,它決定了每一步生成的內(nèi)容和結(jié)果;GRAN 中的 h_{c,t} 也如 LSTM 一樣,代表著 hidden states 。既然是結(jié)合 LSTM 和 GAN,那么說(shuō)完了 LSTM 方面的引入,便是 GAN 方面的了。GRAN 將 GAN 中生成模型(G)的先驗(yàn)也進(jìn)行了建模,變成了 hidden of prior h_z;然后將 h_z 和 h_{c,t} 拼接(concatenate)之后傳遞給每一步的 C_t。
 最后一種改進(jìn) GAN 的訓(xùn)練穩(wěn)定性的方式則更加貼近本質(zhì),也是的研究成果。這便是號(hào)稱 openAI 近期五大突破之一的 infoGAN [7] 。InfoGAN [7] 的出發(fā)點(diǎn)是,既然 GAN 的自由度是由于僅有一個(gè) noise z,而無(wú)法控制 GAN 如何利用這個(gè) z。那么我們就盡量去想辦法在 “如何利用 z” 上做文章。于是,[7] 中將 z 做了拆解,認(rèn)為 GAN 中生成模型(G)應(yīng)該包含的 “先驗(yàn)” 分成兩種: (1)不能再做壓縮的 noise z;(2)和可解釋地、有隱含意義的一組隱變量 c_1, c_2, …, c_L,簡(jiǎn)寫(xiě)為 c 。這里面的思想主要是,當(dāng)我們學(xué)習(xí)生成圖像時(shí),圖像有許多可控的有含義的維度,比如筆劃的粗細(xì)、圖片的光照方向等等,這些便是 c ;而剩下的不知道怎么描述的便是 z 。這樣一來(lái),[7] 實(shí)際上是希望通過(guò)拆解先驗(yàn)的方式,讓 GAN 能學(xué)出更加 disentangled 的數(shù)據(jù)表示(representation),從而既能控制 GAN 的學(xué)習(xí)過(guò)程,又能使得學(xué)出來(lái)的結(jié)果更加具備可解釋性。為了引入這個(gè) c ,[7] 利用了互信息的建模方式,即 c 應(yīng)該和生成模型 (G)基于 z 和 c 生成的圖片,即 G ( z,c ),高度相關(guān) —— 互信息大。利用這種更加細(xì)致的隱變量建模控制,infoGAN 可以說(shuō)將 GAN 的發(fā)展又推動(dòng)了一步。首先,它們證明了 infoGAN 中的 c 對(duì)于 GAN 的訓(xùn)練是有確實(shí)的幫助的,即能使得生成模型(G)學(xué)出更符合真實(shí)數(shù)據(jù)的結(jié)果。其次,他們利用 c 的天然特性,控制 c 的維度,使得 infoGAN 能控制生成的圖片在某一個(gè)特定語(yǔ)義維度的變化。
最后一種改進(jìn) GAN 的訓(xùn)練穩(wěn)定性的方式則更加貼近本質(zhì),也是的研究成果。這便是號(hào)稱 openAI 近期五大突破之一的 infoGAN [7] 。InfoGAN [7] 的出發(fā)點(diǎn)是,既然 GAN 的自由度是由于僅有一個(gè) noise z,而無(wú)法控制 GAN 如何利用這個(gè) z。那么我們就盡量去想辦法在 “如何利用 z” 上做文章。于是,[7] 中將 z 做了拆解,認(rèn)為 GAN 中生成模型(G)應(yīng)該包含的 “先驗(yàn)” 分成兩種: (1)不能再做壓縮的 noise z;(2)和可解釋地、有隱含意義的一組隱變量 c_1, c_2, …, c_L,簡(jiǎn)寫(xiě)為 c 。這里面的思想主要是,當(dāng)我們學(xué)習(xí)生成圖像時(shí),圖像有許多可控的有含義的維度,比如筆劃的粗細(xì)、圖片的光照方向等等,這些便是 c ;而剩下的不知道怎么描述的便是 z 。這樣一來(lái),[7] 實(shí)際上是希望通過(guò)拆解先驗(yàn)的方式,讓 GAN 能學(xué)出更加 disentangled 的數(shù)據(jù)表示(representation),從而既能控制 GAN 的學(xué)習(xí)過(guò)程,又能使得學(xué)出來(lái)的結(jié)果更加具備可解釋性。為了引入這個(gè) c ,[7] 利用了互信息的建模方式,即 c 應(yīng)該和生成模型 (G)基于 z 和 c 生成的圖片,即 G ( z,c ),高度相關(guān) —— 互信息大。利用這種更加細(xì)致的隱變量建模控制,infoGAN 可以說(shuō)將 GAN 的發(fā)展又推動(dòng)了一步。首先,它們證明了 infoGAN 中的 c 對(duì)于 GAN 的訓(xùn)練是有確實(shí)的幫助的,即能使得生成模型(G)學(xué)出更符合真實(shí)數(shù)據(jù)的結(jié)果。其次,他們利用 c 的天然特性,控制 c 的維度,使得 infoGAN 能控制生成的圖片在某一個(gè)特定語(yǔ)義維度的變化。


然而實(shí)際上, infoGAN 并不是第一個(gè)將信息論的角度引入 GAN 框架的工作。這是因?yàn)椋?infoGAN 之前,還有一個(gè)叫做 f-GAN [8] 的工作。并且,GAN 本身也可以從信息論角度去解釋。如本文開(kāi)篇所說(shuō),在原始 GAN 論文 [1] 中,作者是通過(guò)博弈論的角度解釋了 GAN 的思想。然而,GAN 的生成模型(G)產(chǎn)生的數(shù)據(jù)和真實(shí)數(shù)據(jù)就可以看做一顆硬幣的兩面。當(dāng)拋硬幣拋到正面時(shí),我們就將一個(gè)真實(shí)數(shù)據(jù)樣本展示給判別模型(D);反之,則展示由生成模型 (G)生成的“假”樣本。而 GAN 的理想狀態(tài)是,判別模型(D)對(duì)于硬幣的判斷幾乎等同于隨機(jī),也就是生成模型(G)產(chǎn)生的數(shù)據(jù)完全符合真實(shí)數(shù)據(jù)。那么這時(shí)候,GAN 的訓(xùn)練過(guò)程實(shí)際在做的就是最小化這顆硬幣和真實(shí)數(shù)據(jù)之間的互信息。互信息越小,判別模型(D)能從觀察中獲得的信息越少,也就越只能像 “隨機(jī)” 一樣猜結(jié)果。既然有了這樣一個(gè)從互信息角度的對(duì)于 GAN 的理解,那么是否能對(duì) GAN 進(jìn)行更進(jìn)一步的改造呢?其實(shí)是可以的。比如可以把針對(duì)互信息的建模更進(jìn)一步地泛化為基于 divergence 的優(yōu)化目標(biāo)。這方面的討論和改進(jìn)可以見(jiàn)論文 [8],f-GAN 。
上面這些對(duì)于 GAN 的改進(jìn)工作都幾乎是在短短一年半時(shí)間內(nèi)完成的,尤其是近半年。這里面較大的原因就在于 GAN 相較于以前的 generative models,巧妙地將 “真假” 樣本轉(zhuǎn)換為一種隱性的 label,從而實(shí)現(xiàn)了一種 “無(wú)監(jiān)督” 的生成式模型訓(xùn)練框架。這種思想也可以從某種程度上看做 word2vec 中 Skip-Gram 的一種變形。未來(lái),不僅僅是 GAN 的更多改進(jìn)值得被期待,無(wú)監(jiān)督學(xué)習(xí)和生成式模型的發(fā)展也同樣值得關(guān)注。
References:
1.《Generative Adversarial Nets》
2.《Conditional Generative Adversarial Nets》
3.《DRAW: A Recurrent Neural Network For Image Generation》
4.《Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks》
5.《Generating Images with Recurrent Adversarial Networks》
6.《Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks》
7.《InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets》
8.《f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization》
歡迎加入本站公開(kāi)興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉(cāng)庫(kù),數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識(shí)
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請(qǐng)注明本文地址:http://specialneedsforspecialkids.com/yun/4380.html
摘要:引用格式王坤峰,茍超,段艷杰,林懿倫,鄭心湖,王飛躍生成對(duì)抗網(wǎng)絡(luò)的研究與展望自動(dòng)化學(xué)報(bào),論文作者王坤峰,茍超,段艷杰,林懿倫,鄭心湖,王飛躍摘要生成式對(duì)抗網(wǎng)絡(luò)目前已經(jīng)成為人工智能學(xué)界一個(gè)熱門的研究方向。本文概括了的研究進(jìn)展并進(jìn)行展望。 3月27日的新智元 2017 年技術(shù)峰會(huì)上,王飛躍教授作為特邀嘉賓將參加本次峰會(huì)的 Panel 環(huán)節(jié),就如何看待中國(guó) AI學(xué)術(shù)界論文數(shù)量多,但大師級(jí)人物少的現(xiàn)...
摘要:我們將這些現(xiàn)象籠統(tǒng)稱為廣義的模式崩潰問(wèn)題。這給出了模式崩潰的直接解釋。而傳統(tǒng)深度神經(jīng)網(wǎng)絡(luò)只能逼近連續(xù)映射,這一矛盾造成了模式崩潰。 春節(jié)前夕,北美遭遇極端天氣,在酷寒中筆者來(lái)到哈佛大學(xué)探望丘成桐先生。新春佳節(jié),本是普天同慶的日子,但對(duì)于孤懸海外的游子而言,卻是更為凄涼難耐。遠(yuǎn)離父母親朋,遠(yuǎn)離故國(guó)家園,自然環(huán)境寒風(fēng)凜冽,飛雪漫天,社會(huì)環(huán)境疏離淡漠,冷清寂寥。在波士頓見(jiàn)到導(dǎo)師和朋友,倍感欣慰。筆...
摘要:判別器勝利的條件則是很好地將真實(shí)圖像自編碼,以及很差地辨識(shí)生成的圖像。 先看一張圖:下圖左右兩端的兩欄是真實(shí)的圖像,其余的是計(jì)算機(jī)生成的。過(guò)渡自然,效果驚人。這是谷歌本周在 arXiv 發(fā)表的論文《BEGAN:邊界均衡生成對(duì)抗網(wǎng)絡(luò)》得到的結(jié)果。這項(xiàng)工作針對(duì) GAN 訓(xùn)練難、控制生成樣本多樣性難、平衡鑒別器和生成器收斂難等問(wèn)題,提出了改善。尤其值得注意的,是作者使用了很簡(jiǎn)單的結(jié)構(gòu),經(jīng)過(guò)常規(guī)訓(xùn)練...
摘要:近日,谷歌大腦發(fā)布了一篇全面梳理的論文,該研究從損失函數(shù)對(duì)抗架構(gòu)正則化歸一化和度量方法等幾大方向整理生成對(duì)抗網(wǎng)絡(luò)的特性與變體。他們首先定義了全景圖損失函數(shù)歸一化和正則化方案,以及最常用架構(gòu)的集合。 近日,谷歌大腦發(fā)布了一篇全面梳理 GAN 的論文,該研究從損失函數(shù)、對(duì)抗架構(gòu)、正則化、歸一化和度量方法等幾大方向整理生成對(duì)抗網(wǎng)絡(luò)的特性與變體。作者們復(fù)現(xiàn)了當(dāng)前較佳的模型并公平地對(duì)比與探索 GAN ...

閱讀 3230·2023-04-26 02:27
閱讀 2146·2021-11-22 14:44
閱讀 4108·2021-10-22 09:54
閱讀 3205·2021-10-14 09:43
閱讀 759·2021-09-23 11:53
閱讀 12755·2021-09-22 15:33
閱讀 2715·2019-08-30 15:54
閱讀 2692·2019-08-30 14:04





