資訊專欄INFORMATION COLUMN

摘要:在本文中,我將用裸體檢測問題來展示訓練現代版的卷積神經網絡模型與過去的研究有何區別。論文在年代中期發表,它反映了計算機視覺研究者們在使用卷積神經網絡之前所做的典型工作。
著名人工智能公司Clarifai近日推出了識別成人內容的模型和API NSFW,該模型能夠很準確地識別含有裸體和半裸的圖片和視頻,在Clarifai的這篇博文中,作者用裸體檢測問題來展示訓練現代版的卷積神經網絡模型 (convnets) 與過去的研究有何區別。
上周,我們在Clarifai上正式公布了 Not Safe for Work (NSFW) 成人內容識別模型。本周,我們一位數據科學家將帶你探索計算機是如何學會分辨裸體人物的。
警告聲明:本文內含有用于科研用途的裸體圖片。如果你未滿十八周歲或者不宜瀏覽裸體圖片,請立即停止閱讀。
過去二十年里,裸體圖片的自動檢測一直是計算機視覺領域的焦點問題,由于其豐富的研究歷史和明確的目標,該問題是了解整個領域發展變化的極好例子。在本文中,我將用裸體檢測問題來展示訓練現代版的卷積神經網絡模型 (convnets) 與過去的研究有何區別。
警告:本文內含有未打碼的裸體圖片,敬請注意!
早在1996年:

此領域的一項開創性工作是Fleck等人完成的一個項目,戲稱為“尋找裸體人”。論文在90年代中期發表,它反映了計算機視覺研究者們在使用卷積神經網絡之前所做的典型工作。在論文的第二段,他們概括了這種技術:
算法:?
— 首先,篩選出含有大量膚色區域的圖片;?
— 其次,在這些區域內尋找長條狀區域,按照人體結構的信息用專用組合器把它們組合成可能的肢體部位,并且連接這些肢體部位。
皮膚檢測是通過對色彩空間過濾來實現,組合皮膚區域是通過對人體建模來實現,它將人體建模成“由相鄰圓柱體組合而成的物體,每個獨立部分的幾何形狀和各個部分之間的比例都符合人體骨架”(論文第二節)。為了更好地理解實現這類算法的工程技術,我們來看論文的圖1,作者展示了一部分他們人為構造的組合規則:
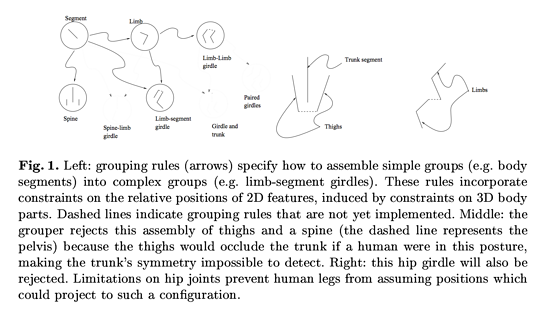
圖1. 左圖:組合規則(箭頭)說明了如何合并簡單的組合(如軀干)形成復雜的組合(如四肢和身體的連接)。這些規則受限于它們在2維空間的相對位置,這是由于它們在3維空間有特定的組合分布。虛線表示了還未實現的組合規則。中圖:組合器拒絕將大腿和脊椎(虛線表示的是盆骨)組合在一起,因為如果人在這種姿勢下大腿會遮蓋軀干,使得軀干不容易被檢測到。右圖:這個臀部連接也被拒絕了。髖骨連接的限制阻止了人的大腿如此擺放。
論文中提到“在138張無限制裸體照片的測試集上,準確率達到了60%,召回率達到52%”。他們還給出了一些真陽性和假陽性的圖片例子,并標明算法檢測到的相關特征:
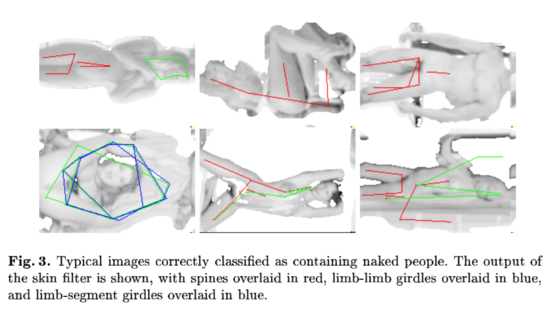
圖3. 成功檢測出裸體人物的典型圖片。皮膚過濾器的輸出結果如圖所示,脊椎用紅線表示,肢體連接用藍線表示,肢體與軀干連接用綠線表示。

圖6. 錯誤地識別出裸體人物的典型對照圖片。這些圖片含有與皮膚色彩接近的材料(動物皮膚、木材、面包、褪色的墻面)和容易誤判為脊椎或者腰帶的結構。組合器經常將平行線組合搞混。
人工構造特征的一個主要問題是特征的復雜性受到了研究院的耐心和想象力的限制。在下一節里,我們將會看到如何訓練卷積神經網絡來完成同樣的任務,更精細地表征相同的數據集。
到了2014年:
深度學習研究員不再發明各種規則來表征輸入的數據,而是設計網絡模型結構和數據集,使得人工智能系統能從數據中直接學到表征的方法。然而,由于深度學習研究員并沒有明確指定網絡模型該如何處理給定的數據集,新的問題就產生了:我們如何理解卷積神經網絡的行為?

理解卷積神經網絡模型的操作就需要解釋各層網絡的特征行為。我們將在本文的余下篇幅中介紹一個NSFW模型的早期版本,從模型頂層反推到原始輸入的像素空間。這樣能使我們明白原始輸入的什么模式能夠導致特征空間的某種特定激活(即為何一張圖片被標記為“NSFW”)。
遮擋靈敏度
下圖是我們在經過裁剪的Lena Soderberg圖像上使用NSFW模型,用64×64的平滑窗口,3像素移窗處理而成。

我們把每個窗口覆蓋的像素點傳入卷積模型,計算每個像素點的平均“NSFW”得分,得到左側的熱度圖。當卷積模型發現某一塊裁剪的區域都屬于皮膚,它就預測為“NSFW”,在圖片中Lena身上相應的位置顯示出一大片紅色區域。生成右側的熱度圖時,我們故意遮擋一部分原始圖片,輸出1減去平均“NSFW”得分之后的差值(即“SFW”得分)。當NSFW得分較高的區域被遮擋時,“SFW”得分隨之上升,我們在熱度圖中看到了顏色更紅的區域。下圖的兩個圖片例子分別表示在上述兩種實驗中傳入卷積模型的兩類圖片示例:

這些遮擋實驗的一個優點就是當分類器完全是一個黑盒的情況下照樣能夠進行實驗。下面是調用我們接口復現上述結果的代碼片段:
# NSFW occlusion experimentfrom StringIO import StringIOimport matplotlib.pyplot as pltimport numpy as npfrom PIL import Image, ImageDrawimport requestsimport scipy.sparse as spfrom clarifai.client import ClarifaiApi
CLARIFAI_APP_ID = "..."CLARIFAI_APP_SECRET = "..."clarifai = ClarifaiApi(app_id=CLARIFAI_APP_ID,
? ? ? ? ? ? ? ? ? ? ? ?app_secret=CLARIFAI_APP_SECRET,
? ? ? ? ? ? ? ? ? ? ? ?base_url="https://api.clarifai.com")def batch_request(imgs, bboxes):
? """use the API to tag a batch of occulded images"""
? assert len(bboxes) < 128
? #convert to image bytes
? stringios = [] ?for img in imgs:
? ? stringio = StringIO()
? ? img.save(stringio, format="JPEG")
? ? stringios.append(stringio) ?#call api and parse response
? output = []
? response = clarifai.tag_images(stringios, model="nsfw-v1.0") ?for result,bbox in zip(response["results"], bboxes):
? ? nsfw_idx = result["result"]["tag"]["classes"].index("sfw")
? ? nsfw_score = result["result"]["tag"]["probs"][nsfw_idx]
? ? output.append((nsfw_score, bbox)) ?return outputdef build_bboxes(img, boxsize=72, stride=25):
? """Generate all the bboxes used in the experiment"""
? width = boxsize
? height = boxsize
? bboxes = [] ?for top in range(0, img.size[1], stride): ? ?for left in range(0, img.size[0], stride):
? ? ? bboxes.append((left, top, left+width, top+height)) ?return bboxesdef draw_occulsions(img, bboxes):
? """Overlay bboxes on the test image"""
? images = [] ?for bbox in bboxes:
? ? img2 = img.copy()
? ? draw = ImageDraw.Draw(img2)
? ? draw.rectangle(bbox, fill=True)
? ? images.append(img2) ?return imagesdef alpha_composite(img, heatmap):
? """Blend a PIL image and a numpy array corresponding to a heatmap in a nice way"""
? if img.mode == "RBG":
? ? img.putalpha(100)
? cmap = plt.get_cmap("jet")
? rgba_img = cmap(heatmap)
? rgba_img[:,:,:][:] = 0.7 #alpha overlay
? rgba_img = Image.fromarray(np.uint8(cmap(heatmap)*255)) ?return Image.blend(img, rgba_img, 0.8)def get_nsfw_occlude_mask(img, boxsize=64, stride=25):
? """generate bboxes and occluded images, call the API, blend the results together"""
? bboxes = build_bboxes(img, boxsize=boxsize, stride=stride) ?print "api calls needed:{}".format(len(bboxes))
? scored_bboxes = []
? batch_size = 125
? for i in range(0, len(bboxes), batch_size):
? ? bbox_batch = bboxes[i:i + batch_size]
? ? occluded_images = draw_occulsions(img, bbox_batch)
? ? results = batch_request(occluded_images, bbox_batch)
? ? scored_bboxes.extend(results)
? heatmap = np.zeros(img.size)
? sparse_masks = [] ?for idx, (nsfw_score, bbox) in enumerate(scored_bboxes):
? ? mask = np.zeros(img.size)
? ? mask[bbox[0]:bbox[2], bbox[1]:bbox[3]] = nsfw_score?
? ? Asp = sp.csr_matrix(mask)
? ? sparse_masks.append(Asp)
? ? heatmap = heatmap + (mask - heatmap)/(idx+1) ? ?
? return alpha_composite(img, 80*np.transpose(heatmap)), np.stack(sparse_masks)#Download full Lena imager = requests.get("https://clarifai-img.s3.amazonaws.com/blog/len_full.jpeg")
stringio = StringIO(r.content)
img = Image.open(stringio, "r")
img.putalpha(1000)#set boxsize and stride (warning! a low stride will lead to thousands of API calls)boxsize= 64stride= 48blended, masks = get_nsfw_occlude_mask(img, boxsize=boxsize, stride=stride)#vizblended.show()
盡管這類實驗以非常直接的方式呈現了分類器的輸出結果,但缺點是輸出的結果很模糊。這使得我們不能完全深入了解模型的工作狀態以及發現訓練過程中的錯誤。
去卷積網絡模型
當我們用指定數據集訓練得到一個模型后,往往希望給出一張圖片和某個類別,然后想從模型中得到諸如“我們該如何改變這張圖片使其看起來更像是屬于那個類別的”之類的答案。針對這類問題,我們使用去卷積網絡模型(deconvnet),Zeiler和Fergus014年論文的第二節:

下圖展示的是我們用去卷積模型對Lena照片的處理結果,顯示了我們該如何修飾Lena圖片使其更像一張色情圖片(作者注:這類使用的去卷積模型需要傳入一張正方形的圖片 —— 我們將Lena的完整圖片填補成合適的尺寸):

Barbara 是Lena的G級(無限制級)版本。根據我們的去卷積模型,我們給她加上紅唇后看起來更像PG級(可能不適宜兒童)圖片。

這張圖片是Ursula Andress 在電影《007之諾博士》中飾演Honey Rider的劇照,2003年被英國調查評選為“銀幕上100個性感瞬間”的第一位:

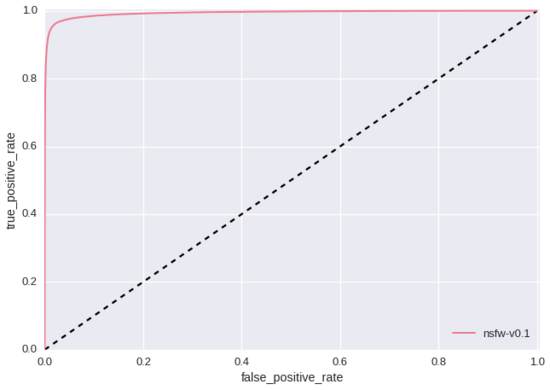
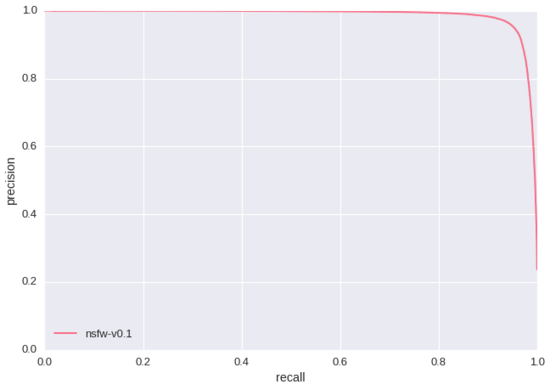
上述實驗的一個顯著特點就是卷積模型學習到了紅唇和肚臍是“NSFW”得分的指標。這似乎意味著我們“SFW”訓練數據集中所包含的紅唇和肚臍圖片還不夠。如果我們只是用準確率/召回率和ROC曲線(如下所示 – 測試集大小為428,271)來評價我們的模型,我們永遠也無法發現這個問題,因為我們的測試數據集有著同樣的缺陷。這里就是訓練基于規則的分類器與現代人工智能研究的本質差別之一。相對于重新人工構造特征,我們重新設計訓練數據集直到挖掘出更優質的特征。
最后,我們機智地在確定是色情圖片的數據集上運行去卷積模型,確保模型學到的特征真的和明顯的nsfw所對應:

這里,我們能清楚地看到卷積模型正確地學到了男女生殖器等器官 —— 我們模型應該標識的部位。而且,模型發現的特征遠比研究員人工構造的特征更細化和復雜,有助于我們理解使用卷積模型識別NSFW圖片的主要提升點。
來源:http://blog.clarifai.com/what-convolutional-neural-networks-see-at-when-they-see-nudity/#.Vy3EN4RcSkr
原文標題:WHAT CONVOLUTIONAL NEURAL NETWORKS LOOK AT WHEN THEY SEE NUDITY?
作者:Ryan Compton?
譯者:趙屹華 審校:劉翔宇?
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4336.html
摘要:以攻擊模型為例,介紹生成攻擊樣本的基本原理。總結本章介紹了對抗樣本的基本原理,并以最簡單的梯度下降算法演示了生成對抗樣本的基本過程,大家可能會因為它的效率如此低而印象深刻。 對抗樣本是機器學習模型的一個有趣現象,攻擊者通過在源數據上增加人類難以通過感官辨識到的細微改變,但是卻可以讓機器學習模型接受并做出錯誤的分類決定。一個典型的場景。概述對抗樣本是機器學習模型的一個有趣現象,攻擊者通過在源數...
摘要:在計算機視覺領域,對卷積神經網絡簡稱為的研究和應用都取得了顯著的成果。文章討論了在卷積神經網絡中,該如何調整超參數以及可視化卷積層。卷積神經網絡可以完成這項任務。 在深度學習中,有許多不同的深度網絡結構,包括卷積神經網絡(CNN或convnet)、長短期記憶網絡(LSTM)和生成對抗網絡(GAN)等。在計算機視覺領域,對卷積神經網絡(簡稱為CNN)的研究和應用都取得了顯著的成果。CNN網絡最...

摘要:而在卷積神經網絡中,這兩個神經元可以共用一套參數,用來做同一件事情。卷積神經網絡的基本結構卷積神經網絡的基本結構如圖所示從右到左,輸入一張圖片卷積層池化層卷積層池化層展開全連接神經網絡輸出。最近幾天陸續補充了一些線性回歸部分內容,這節繼續機器學習基礎部分,這節主要對CNN的基礎進行整理,僅限于基礎原理的了解,更復雜的內容和實踐放在以后再進行總結。卷積神經網絡的基本原理 前面對全連接神經網絡...
摘要:而使用某些特定的表示方法更容易從實例中學習任務例如,人臉識別或面部表情識別。維基百科關于深度學習的應用,網上有非常多的出色案例,伯樂在線在本文摘錄個。 深度學習是機器學習中一種基于對數據進行表征學習的方法。觀測值(例如一幅圖像)可以使用多種方式來表示,如每個像素強度值的向量,或者更抽象地表示成一系列邊、特定形狀的區域等。而使用某些特定的表示方法更容易從實例中學習任務(例如,人臉識別或面部表情...
摘要:而加快推動這一趨勢的,正是卷積神經網絡得以雄起的大功臣。卷積神經網絡面臨的挑戰對的深深的質疑是有原因的。據此,也斷言卷積神經網絡注定是沒有前途的神經膠囊的提出在批判不足的同時,已然備好了解決方案,這就是我們即將討論的膠囊神經網絡,簡稱。 本文作者 張玉宏2012年于電子科技大學獲計算機專業博士學位,2009~2011年美國西北大學聯合培養博士,現執教于河南工業大學,電子科技大學博士后。中國計...

閱讀 3419·2021-11-15 11:39
閱讀 1552·2021-09-22 10:02
閱讀 1309·2021-08-27 16:24
閱讀 3596·2019-08-30 15:52
閱讀 3412·2019-08-29 16:20
閱讀 824·2019-08-28 18:12
閱讀 550·2019-08-26 18:27
閱讀 715·2019-08-26 13:32






