資訊專欄INFORMATION COLUMN

摘要:深度學(xué)習(xí)理論在機(jī)器翻譯和字幕生成上取得了巨大的成功。在語音識別和視頻,特別是如果我們使用深度學(xué)習(xí)理論來捕捉多樣的時(shí)標(biāo)時(shí),會很有用。深度學(xué)習(xí)理論可用于解決長期的依存問題,讓一些狀態(tài)持續(xù)任意長時(shí)間。
Yoshua Bengio,電腦科學(xué)家,畢業(yè)于麥吉爾大學(xué),在MIT和AT&T貝爾實(shí)驗(yàn)室做過博士后研究員,自1993年之后就在蒙特利爾大學(xué)任教,與 Yann LeCun、 Geoffrey Hinton并稱為“深度學(xué)習(xí)三巨頭”,也是神經(jīng)網(wǎng)絡(luò)復(fù)興的主要的三個(gè)發(fā)起人之一,在預(yù)訓(xùn)練問題、為自動編碼器降噪等自動編碼器的結(jié)構(gòu)問題和生成式模型等等領(lǐng)域做出重大貢獻(xiàn)。他早先的一篇關(guān)于語言概率模型的論文開創(chuàng)了神經(jīng)網(wǎng)絡(luò)做語言模型的先河,啟發(fā)了一系列關(guān)于 NLP 的文章,進(jìn)而在工業(yè)界產(chǎn)生重大影響。此外,他的小組開發(fā)了 Theano 平臺。
下文是Yoshua Bengio 2016年5月11日在Twitter Boston的演講PPT實(shí)錄,由新智元整理翻譯,如果PPT看不過癮,你還可以復(fù)制鏈接直接觀看視頻:https://www.periscope.tv/hugo_larochelle/1MYxNDlQkPpGw

原標(biāo)題:自然語言詞義中的深度學(xué)習(xí)

從ML到AI的三個(gè)關(guān)鍵要素:
1. ?許多&許多的數(shù)據(jù)
2. ?非常靈活的模型
3. ?強(qiáng)大的先驗(yàn)知識,能打破“維度的詛咒”

突破“維度的詛咒”
我們需要在機(jī)器學(xué)習(xí)模型中創(chuàng)建組合詞
正如人類語言會分析組合詞,為組合詞的概念賦予表示和意義
對組合詞意挖掘,在指代的能力上獲得指數(shù)級的增長
分布式表示/嵌入:特征學(xué)習(xí)
深度架構(gòu):多層次的特征學(xué)習(xí)
先驗(yàn)知識(Prior):組合性在有效地描述我們所處的世界時(shí)非常有用

深度學(xué)習(xí)理論的進(jìn)展
分布式表示的指數(shù)級優(yōu)勢
深度的指數(shù)級優(yōu)勢
迷思:非凸性 ? 局部最小值
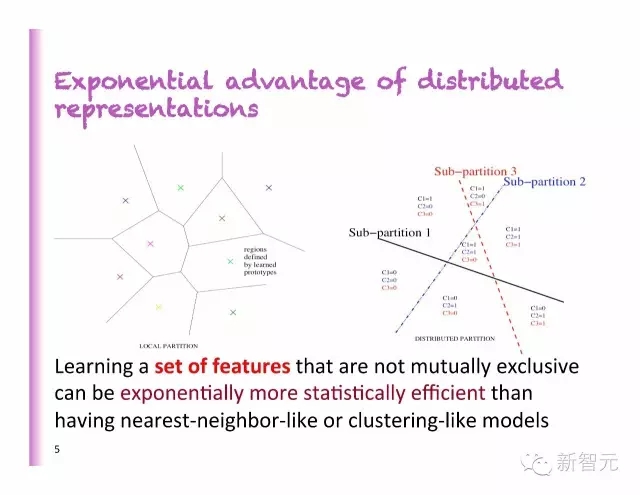
分布式表示的指數(shù)級優(yōu)勢
比起最近鄰法或分類法的模型,學(xué)習(xí)一系列不相互排斥的特征,在數(shù)據(jù)上更有效。

相關(guān)推薦論文
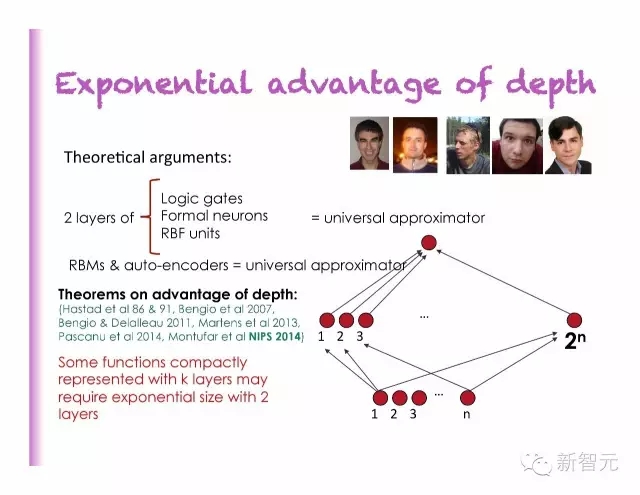
深度的指數(shù)級優(yōu)勢


迷思正在被打破:神經(jīng)網(wǎng)絡(luò)中的局部最小值
凸性并不是必須的
推薦論文
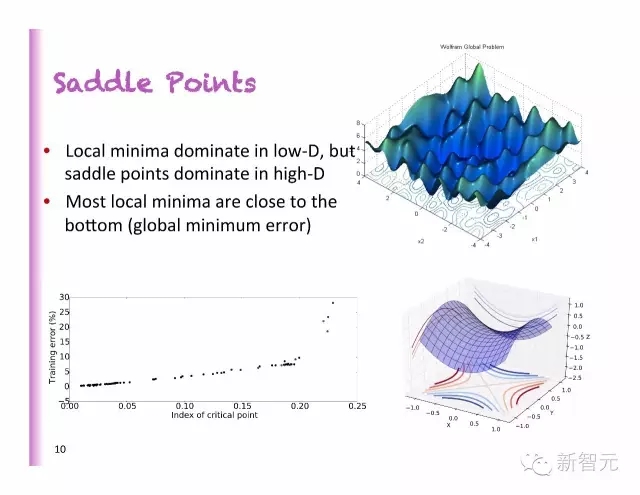
鞍點(diǎn)
局部最小值掌控著低維度,但是鞍點(diǎn)掌控高維度
大多數(shù)的局部最小值都很接近底部(全局最小值誤差)

為什么N-gram 在泛化上表現(xiàn)很差
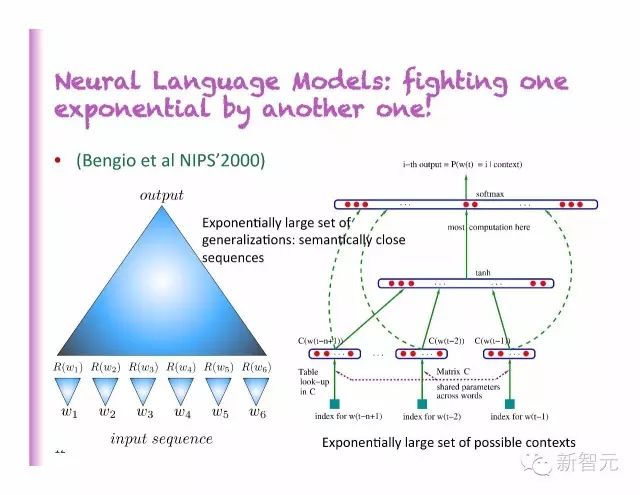
神經(jīng)語言模型

下一個(gè)挑戰(zhàn):詞序中豐富的語義表示
捕捉詞義上令人印象深刻的進(jìn)展
更容易的學(xué)習(xí):非參數(shù)的(查表)
繪制序列來實(shí)現(xiàn)更加豐富和完整的指稱進(jìn)行優(yōu)化的問題
好的測試案例:自動編碼框架的機(jī)器翻譯
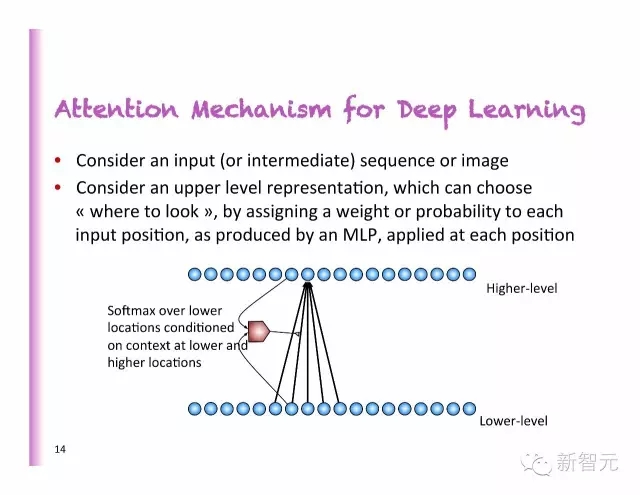
深度學(xué)習(xí)中的聚焦(Attention)機(jī)制
考慮一個(gè)輸入(或者中間的)序列或者圖像
考慮一個(gè)高層次的指稱,通過設(shè)置權(quán)重或者每個(gè)輸入位置的概率,正如MLP中所產(chǎn)生的那樣,運(yùn)用到每一個(gè)位置。

聚焦機(jī)制在翻譯、語音、圖像、視頻和存儲中的應(yīng)用

端對端的機(jī)器翻譯
傳統(tǒng)的機(jī)器翻譯:通過相似度的較大化對若干個(gè)模型進(jìn)行獨(dú)立地訓(xùn)練,在N型圖中獲的頂部、底部獲得邏輯回歸。
神經(jīng)語言模型已經(jīng)被證明在普遍化的能力上優(yōu)于N型圖模型。
為什么不訓(xùn)練一個(gè)神經(jīng)翻譯模型,端對端地評估P(目標(biāo)句子|源句子)

2014:神經(jīng)機(jī)器翻譯獲得突破的一年
主要論文
早期的工作
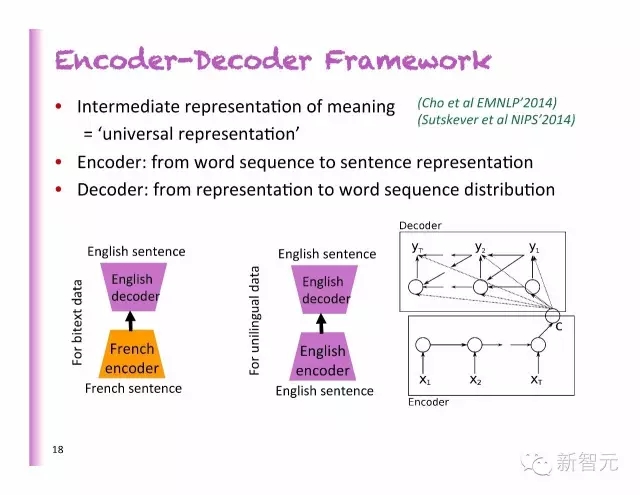
編碼-解碼框架
中間的意義表示=普遍的表示
編碼:從詞的排列到句子代表
解碼:從代表到詞序的分布
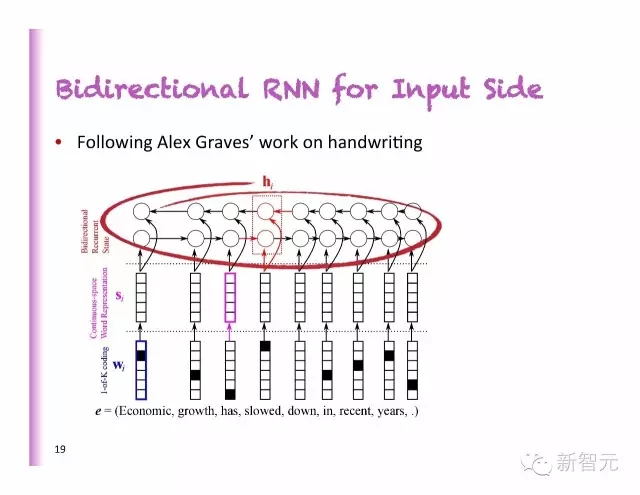
輸入側(cè)的雙向RNN
模仿Alex Graves在手寫體上的工作

聚焦:相關(guān)論文和舊論文
?
軟聚焦VS隨機(jī)硬聚焦
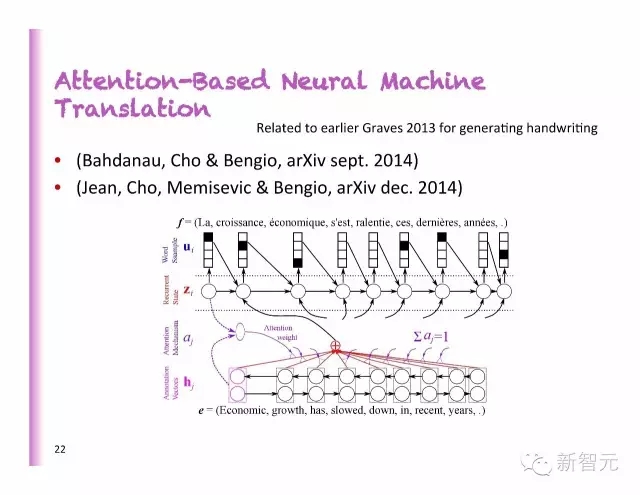
聚焦為基礎(chǔ)的神經(jīng)機(jī)器翻譯
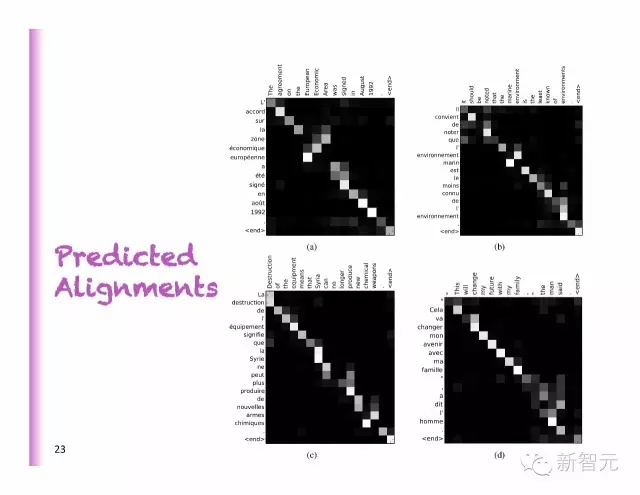
預(yù)測對齊

法語和德語不同的對齊

在純AE模型上的提升
RNNenc:對整個(gè)句子進(jìn)行編碼
RNNsearch:預(yù)測平面圖
BLEU 在全部的測試集中賦分(包括UNK)

周期性網(wǎng)絡(luò)和聚焦機(jī)制下的端對端機(jī)器翻譯
從零開始,一年后的現(xiàn)狀:

英語到德語
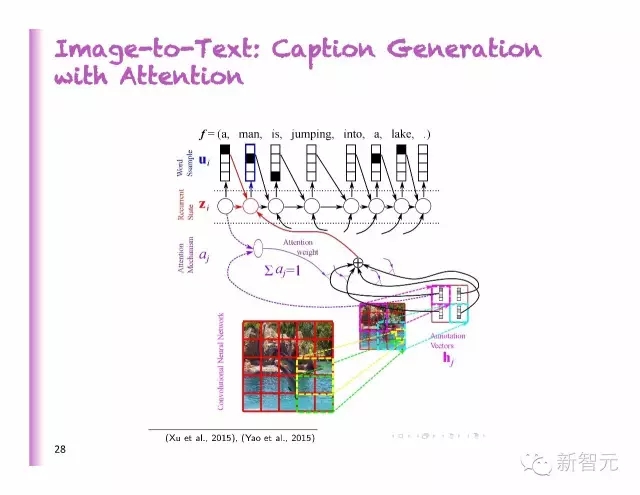
從圖像到文字:聚焦模型下的字幕生成

聚焦選擇部分圖像,同時(shí),生成對應(yīng)描述詞

說出看到的東西
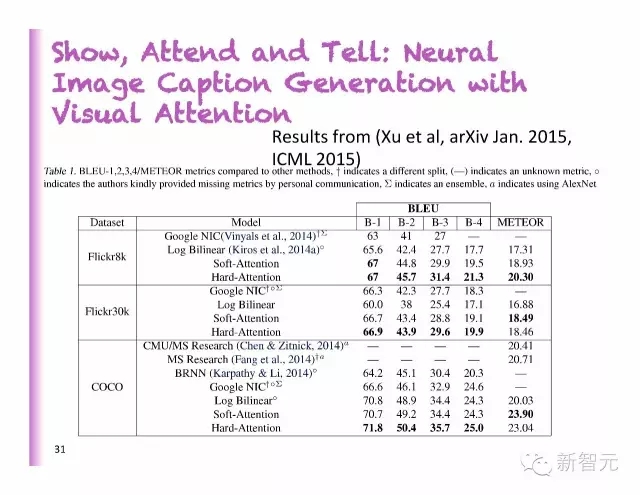
展示、參加和講述:用視覺聚焦來達(dá)到神經(jīng)圖像字幕生成

好的識別

壞的識別

有趣的延伸
用重要性抽樣近似值高效地處理大量的詞匯(最小批的詞=負(fù)面的例子)(Jean al, ACL’2015)
多語種 NMT:共享的編碼器和解碼器,在語言配對中,聚焦機(jī)制是一個(gè)條件
字符層次的NMT

用共享聚焦機(jī)制達(dá)成的多語言神經(jīng)機(jī)器翻譯
?
每一種語言對應(yīng)1 編碼器+ 1解碼器
一個(gè)共享的聚焦模型,還有每一種語言編碼和解碼規(guī)定的“代表翻譯函數(shù)”
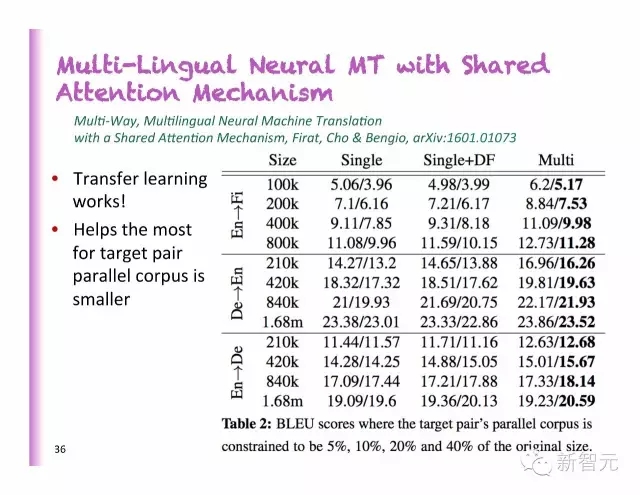
用共享聚焦機(jī)制達(dá)成的多語言神經(jīng)機(jī)器翻譯
遷移學(xué)習(xí)起了作用
在大多數(shù)情況下,對定位成對的平行語料庫有益

基于字符的模型
在基于N型圖的模型中幾乎是不可能的;
但是,對于處理開放詞匯問題、拼寫錯(cuò)誤而、音譯、數(shù)字等端對端的問題卻是有必要的;
對于詞匯并沒有清晰的區(qū)分或者組合線(讓詞匯量顯示)的語言來說是有必要的;
在詞的規(guī)律(前綴、后綴、連接等)上進(jìn)行時(shí)是有必要的;
障礙:
對于RNNs:更長期的依賴性
較差的容量和計(jì)算率
2年前的前期實(shí)驗(yàn):比起基于詞匯的模型,可持續(xù)性要更差?
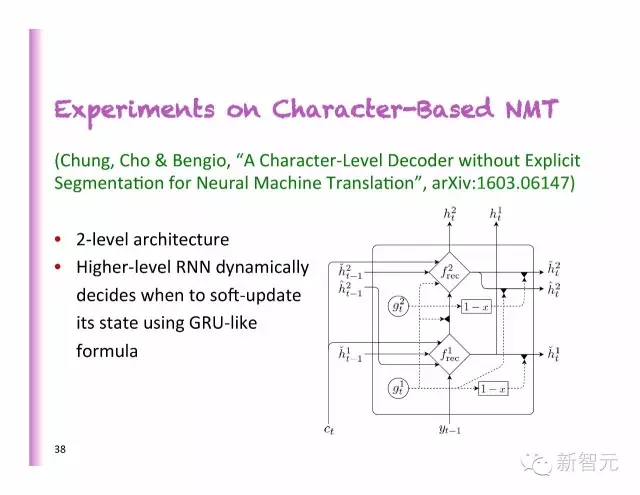
基于字符的NMT實(shí)驗(yàn)
2層的架構(gòu)
更高級別的RNN動態(tài)地決定了何時(shí)使用類似GRU的公式軟性地更新狀態(tài)

基于字符的NMT實(shí)驗(yàn)
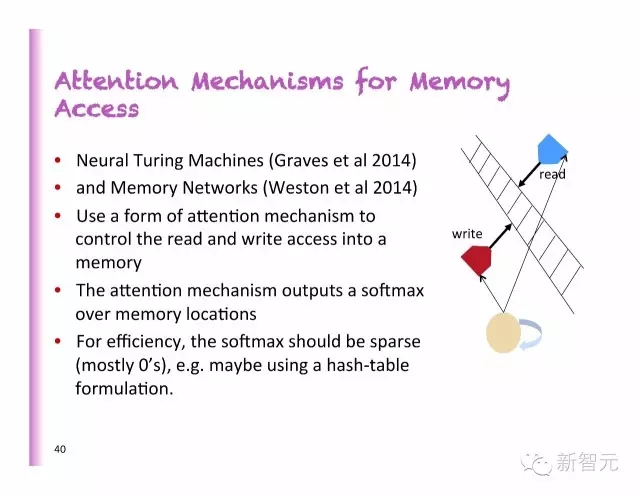
內(nèi)存訪問中的聚焦模型
神經(jīng)圖靈機(jī)器
內(nèi)存網(wǎng)絡(luò)
使用一個(gè)聚焦機(jī)制形式來控制對存儲器的讀取和寫入
聚焦機(jī)制在內(nèi)存上輸出一個(gè)softmax
從效率上看,softmax必須是稀疏的(大多數(shù)情況下是0),例如,或許可以使用一個(gè)混合圖表格式。
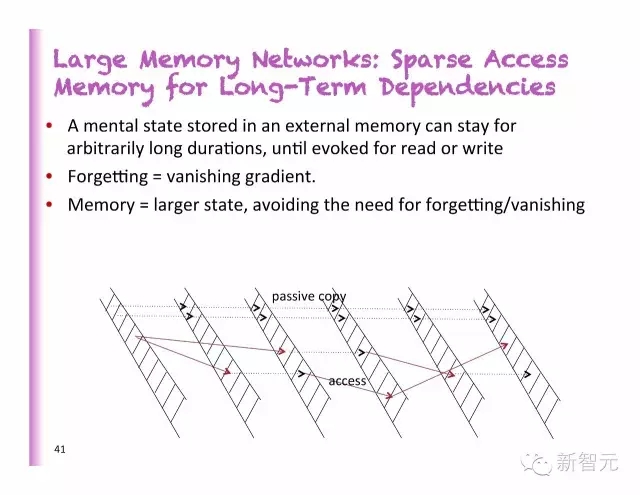
大型內(nèi)存網(wǎng)絡(luò):長期依存的稀疏內(nèi)存訪問
一個(gè)外部存儲器中的狀態(tài),可以保存任意長的時(shí)間,直到被讀取或?qū)懭?/p>
忘記=消失的梯度
內(nèi)存=更大的狀態(tài),避免遺忘或者消失的必要

延遲不代表能更進(jìn)一步
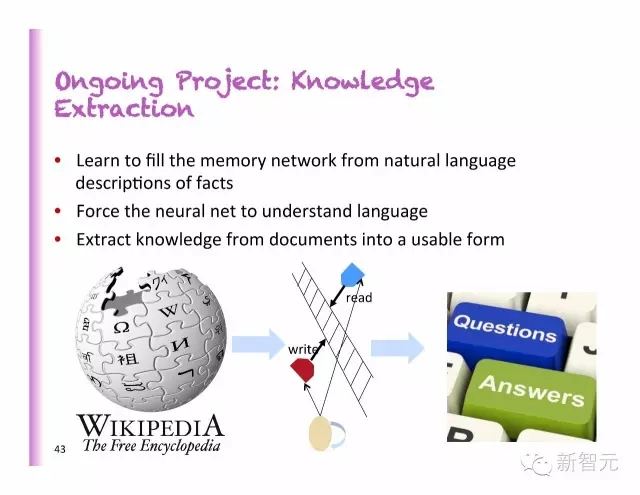
在運(yùn)行的項(xiàng)目:知識提取
學(xué)習(xí)從自然語言對事實(shí)的描述中填入記憶網(wǎng)絡(luò)
強(qiáng)迫神經(jīng)網(wǎng)絡(luò)理解語言
從檔案中提取知識,并濃縮成可使用的格式

下一個(gè)大難題:非監(jiān)督式學(xué)習(xí)
最近的突破大多數(shù)都是在監(jiān)督式深度學(xué)習(xí)中
非監(jiān)督式學(xué)習(xí)中的真實(shí)挑戰(zhàn)
潛在的好處:
能處理海量的非標(biāo)簽數(shù)據(jù)
針對觀察的變量,回答新的問題
正則化矩陣——遷移學(xué)習(xí)——領(lǐng)域自適應(yīng)
更容易優(yōu)化(局部訓(xùn)練信號)
結(jié)構(gòu)性的輸出
對于沒有特定模型或在主要模擬的RL來說很有必要

結(jié)論
深度學(xué)習(xí)理論在許多前沿地帶都取得了顯著的進(jìn)步:為什么能更好地泛化?為什么局部最小值不是人們考慮的問題?深度無監(jiān)督學(xué)習(xí)的概率解釋。
聚焦機(jī)制讓學(xué)習(xí)者模型更好地做選擇,不管是軟聚焦還硬聚焦。
深度學(xué)習(xí)理論在機(jī)器翻譯和字幕生成上取得了巨大的成功。
在語音識別和視頻,特別是如果我們使用深度學(xué)習(xí)理論來捕捉多樣的時(shí)標(biāo)時(shí),會很有用。
深度學(xué)習(xí)理論可用于解決長期的依存問題,讓一些狀態(tài)持續(xù)任意長時(shí)間。
 歡迎加入本站公開興趣群
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4335.html
摘要:但是在當(dāng)時(shí),幾乎沒有人看好深度學(xué)習(xí)的工作。年,與和共同撰寫了,這本因封面被人們親切地稱為花書的深度學(xué)習(xí)奠基之作,也成為了人工智能領(lǐng)域不可不讀的圣經(jīng)級教材。在年底,開始為深度學(xué)習(xí)的產(chǎn)業(yè)孵化助力。 蒙特利爾大學(xué)計(jì)算機(jī)科學(xué)系教授 Yoshua Bengio從法國來到加拿大的時(shí)候,Yoshua Bengio只有12歲。他在加拿大度過了學(xué)生時(shí)代的大部分時(shí)光,在麥吉爾大學(xué)的校園中接受了從本科到博士的完整...
摘要:年的深度學(xué)習(xí)研討會,壓軸大戲是關(guān)于深度學(xué)習(xí)未來的討論。他認(rèn)為,有潛力成為深度學(xué)習(xí)的下一個(gè)重點(diǎn)。認(rèn)為這樣的人工智能恐懼和奇點(diǎn)的討論是一個(gè)巨大的牽引。 2015年ICML的深度學(xué)習(xí)研討會,壓軸大戲是關(guān)于深度學(xué)習(xí)未來的討論。基于平衡考慮,組織方分別邀請了來自工業(yè)界和學(xué)術(shù)界的六位專家開展這次圓桌討論。組織者之一Kyunghyun Cho(Bengio的博士后)在飛機(jī)上憑記憶寫下本文總結(jié)了討論的內(nèi)容,...
摘要:八月初,我有幸有機(jī)會參加了蒙特利爾深度學(xué)習(xí)暑期學(xué)校的課程,由最知名的神經(jīng)網(wǎng)絡(luò)研究人員組成的為期天的講座。另外,當(dāng)損失函數(shù)接近全局最小時(shí),概率會增加。降低訓(xùn)練過程中的學(xué)習(xí)率。對抗樣本的訓(xùn)練據(jù)最近信息顯示,神經(jīng)網(wǎng)絡(luò)很容易被對抗樣本戲弄。 8月初的蒙特利爾深度學(xué)習(xí)暑期班,由Yoshua Bengio、 Leon Bottou等大神組成的講師團(tuán)奉獻(xiàn)了10天精彩的講座,劍橋大學(xué)自然語言處理與信息檢索研...
摘要:另外,當(dāng)損失函數(shù)接近全局最小時(shí),概率會增加。降低訓(xùn)練過程中的學(xué)習(xí)率。對抗樣本的訓(xùn)練據(jù)最近信息顯示,神經(jīng)網(wǎng)絡(luò)很容易被對抗樣本戲弄。使用高度正則化會有所幫助,但會影響判斷不含噪聲圖像的準(zhǔn)確性。 由 Yoshua Bengio、 Leon Bottou 等大神組成的講師團(tuán)奉獻(xiàn)了 10 天精彩的講座,劍橋大學(xué)自然語言處理與信息檢索研究組副研究員 Marek Rei 參加了本次課程,在本文中,他精煉地...

閱讀 823·2019-08-30 15:55
閱讀 1406·2019-08-30 13:55
閱讀 1982·2019-08-29 17:13
閱讀 2840·2019-08-29 15:42
閱讀 1329·2019-08-26 14:04
閱讀 1016·2019-08-26 13:31
閱讀 3270·2019-08-26 11:34
閱讀 828·2019-08-23 18:25





