資訊專欄INFORMATION COLUMN

摘要:八月初,我有幸有機會參加了蒙特利爾深度學(xué)習(xí)暑期學(xué)校的課程,由最知名的神經(jīng)網(wǎng)絡(luò)研究人員組成的為期天的講座。另外,當(dāng)損失函數(shù)接近全局最小時,概率會增加。降低訓(xùn)練過程中的學(xué)習(xí)率。對抗樣本的訓(xùn)練據(jù)最近信息顯示,神經(jīng)網(wǎng)絡(luò)很容易被對抗樣本戲弄。
8月初的蒙特利爾深度學(xué)習(xí)暑期班,由Yoshua Bengio、 Leon Bottou等大神組成的講師團奉獻了10天精彩的講座,劍橋大學(xué)自然語言處理與信息檢索研究組副研究員Marek Rei參加了本次課程,在本文中,他精煉地總結(jié)了學(xué)到的26個有代表性的知識點,包括分布式表示,tricks的技巧,對抗樣本的訓(xùn)練,Neural Machine Translation,以及Theano、Nvidia Digits等,非常具有參考價值。
八月初,我有幸有機會參加了蒙特利爾深度學(xué)習(xí)暑期學(xué)校的課程,由最知名的神經(jīng)網(wǎng)絡(luò)研究人員組成的為期10天的講座。在此期間,我學(xué)到了很多,用一篇博客也說不完。我不會用60個小時的時間來講解神經(jīng)網(wǎng)絡(luò)知識的價值,而會以段落的方式來總結(jié)我學(xué)到的一些有趣的知識點。
在撰寫本文時,暑期學(xué)校網(wǎng)站仍可以訪問,并附有全部的演示文稿。所有的資料和插圖都是來自原作者。暑期學(xué)校的講座已經(jīng)錄制成了視頻,它們也可能會被上傳到網(wǎng)站上。
好了,我們開始吧。
1、分布式表示(distributed representations)的需要
在Yoshua Bengio開始的講座上,他說“這是我重點講述的幻燈片”。下圖就是這張幻燈片:
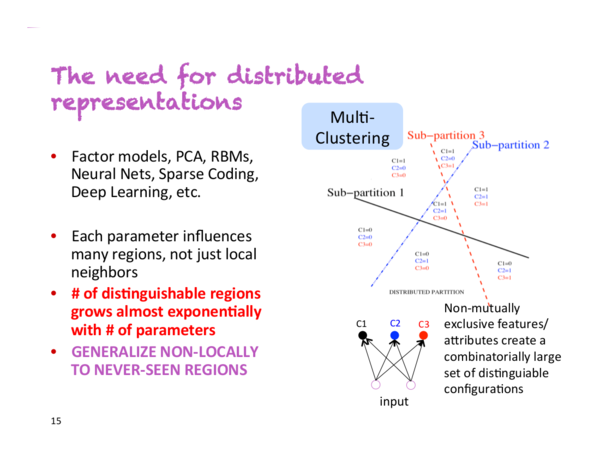
假設(shè)你有一個分類器,需要分類人們是男性還是女性,佩戴眼鏡還是不佩戴眼鏡,高還是矮。如果采用非分布式表示,你就在處理2*2*2=8類人。為訓(xùn)練精準(zhǔn)度高的分類器,你需要為這8類收集足夠的訓(xùn)練數(shù)據(jù)。但是,如果采用分布式表示,每一個屬性都會在其他不同維度中有所展現(xiàn)。這意味著即使分類器沒有碰到佩戴眼鏡的高個子,它也能成功地識別他們,因為它學(xué)會了從其他樣本中多帶帶學(xué)習(xí)識別性別,佩戴眼鏡與否和身高。
2、局部最小在高維度不是問題
Yoshua Bengio的團隊通過實驗發(fā)現(xiàn),優(yōu)化高維度神經(jīng)網(wǎng)絡(luò)參數(shù)時,就沒有局部最小。相反,在某些維度上存在鞍點,它們是局部最小的,但不是全局最小。這意味著,在這些點訓(xùn)練會減慢許多,直到網(wǎng)絡(luò)知道如何離開這些點,但是我們愿意等足夠長的時間的話,網(wǎng)絡(luò)總會找到方法的。
下圖展示了在網(wǎng)絡(luò)訓(xùn)練過程中,兩種狀態(tài)的震動情況:靠近鞍點和離開鞍點。
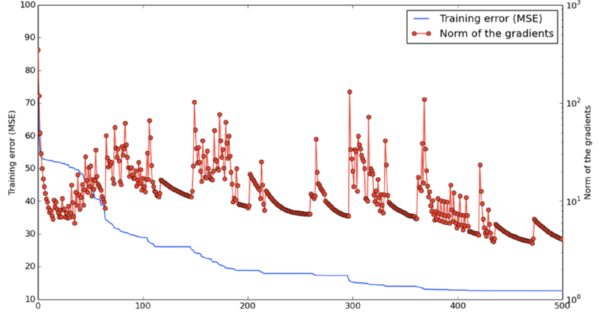
給定一個指定的維度,小概率p表示點是局部最小的可能性,但不是此維度上全局最小。在1000維度空間里的點不是局部最小的概率和就會是,這是一個非常小的值。但是,在某些維度里,這個點是局部最小的概率實際上比較高。而且當(dāng)我們同時得到多維度下的最小值時,訓(xùn)練可能會停住直到找到正確的方向。
另外,當(dāng)損失函數(shù)接近全局最小時,概率p會增加。這意味著,如果我們找到了真正的局部最小,那么它將非常接近全局最小,這種差異是無關(guān)緊要的。
3、導(dǎo)函數(shù),導(dǎo)函數(shù),導(dǎo)函數(shù)
Leon Bottou列出了一些有用的表格,關(guān)于激活函數(shù),損失函數(shù),和它們相應(yīng)的導(dǎo)函數(shù)。我將它們先放在這里以便后續(xù)使用。
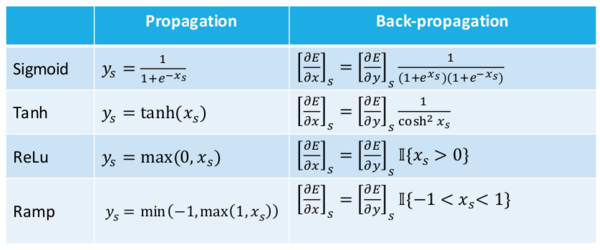
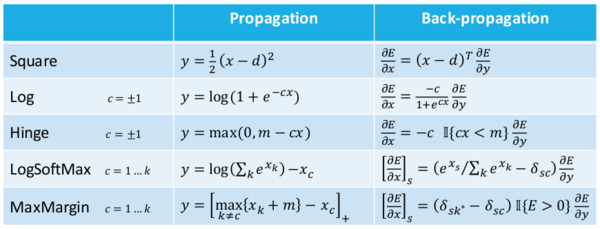
更新:根據(jù)評論指出,斜率公式中的最小較大函數(shù)應(yīng)該調(diào)換。
4、權(quán)重初始化策略
目前在神經(jīng)網(wǎng)絡(luò)中建議使用的權(quán)重初始化策略是將值歸一化到范圍[-b,b],b為:
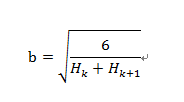
由Hugo Larochelle推薦,Glorot和Bengio發(fā)布(2010)。
5、神經(jīng)網(wǎng)絡(luò)訓(xùn)練技巧
Hugo Larochelle給出的一些實用建議:
歸一化實值數(shù)據(jù)。減去平均值,再除以標(biāo)準(zhǔn)差。
降低訓(xùn)練過程中的學(xué)習(xí)率。
更新使用小批量數(shù)據(jù),梯度會更穩(wěn)定。
使用動量,通過停滯期。
6、梯度檢測
如果你手動實現(xiàn)了反向傳播算法但是它不起作用,那么有99%的可能是梯度計算中存在Bug。那么就用梯度檢測來定位問題。主要思想是運用梯度的定義:如果我們稍微增加某個權(quán)重值,模型的誤差將會改變多少。

這里有更詳細的解釋:Gradient checking and advanced optimization。
7、動作跟蹤
人體動作跟蹤可以達到非常高的精準(zhǔn)度。下圖是來自Graham Taylor等人(2010)發(fā)表的論文Dynamical Binary Latent Variable Models for 3D Human Pose Tracking中的例子。該方法使用的是條件受限的玻爾茲曼機。

8、使用語法還是不使用語法?(即“需要考慮語法嗎?”)
Chris Manning和Richard Socher已經(jīng)投入了大量的精力來開發(fā)組合模型,它將神經(jīng)嵌入與更多傳統(tǒng)的分析方法組合起來。這在Recursive Neural Tensor Network這篇論文中達到了極致,它使用加法和乘法的互動將詞義與語法解析樹組合。
然后,該模型被Paragraph向量(Le和Mikolov,2014)打敗了(以相當(dāng)大的差距),Paragraph向量對語句結(jié)構(gòu)和語法完全不了解。Chris Manning將這個結(jié)果稱作“創(chuàng)造‘好的’組合向量的一次失敗”。
然而,最近越來越多的使用語法解析樹的工作成果改變了那一結(jié)果。Irsoy和Cardie(NIPS,2014)在多維度上使用更深層的網(wǎng)絡(luò)成功地打敗了Paragraph向量。最后,Tai等人(ACL,2015)將LSTM網(wǎng)絡(luò)與語法解析樹結(jié)合,進一步改進了結(jié)果。
這些模型在斯坦福5類情感數(shù)據(jù)集上結(jié)果的精準(zhǔn)度如下:

從目前來看,使用語法解析樹的模型比簡單方法更勝一籌。我很好奇下一個不基于語法的方法何時出現(xiàn),它又將會如何推動這場比賽。畢竟,許多神經(jīng)模型的目標(biāo)不是丟棄底層的語法,而是隱式的將它捕獲在同一個網(wǎng)絡(luò)中。
9、分布式與分配式
Chris Manning本人澄清了這兩個詞之間的區(qū)別。
分布式:在若干個元素中的連續(xù)激活水平。比如密集詞匯嵌入,而不是1-hot向量。
分配式:表示的是使用上下文。word2vec是分配式的,當(dāng)我們使用詞匯的上下文來建模語義時,基于計數(shù)的詞匯向量也是分配式的。
10、依賴狀態(tài)分析
Penn Treebank中的依賴分析器比較:
Parser | Unlabelled Accuracy | Labelled Acccuracy | Speed (sent/s) |
MaltParser | 89.8 | 87.2 | 469 |
MSTParser | 91.4 | 88.1 | 10 |
TurboParser | 92.3 | 89.6 | 8 |
Stanford Neural Dependency Parser? | 92.0 | 89.7 | 654 |
94.3 | 92.4 | ? |
最后一個結(jié)果是從谷歌“提取出所有stops”得到的,將海量數(shù)據(jù)源來訓(xùn)練斯坦福神經(jīng)語法解析器。
11、Theano

我之前對Theano有所了解,但是我在暑期學(xué)校學(xué)習(xí)到了更多。而且它實在是太棒了。
由于Theano起源自蒙特利爾,直接請教Theano的開發(fā)者會很有用。
關(guān)于它大多數(shù)的信息都可以在網(wǎng)上找到,以交互式Python教程的形式。
12、Nvidia Digits
英偉達有一個叫做Digits的工具包,它可以訓(xùn)練并可視化復(fù)雜的神經(jīng)網(wǎng)絡(luò)模型而不需要寫任何代碼。并且他們正在出售DevBox,這是一款定制機器,可以運行Digits和其他深度學(xué)習(xí)軟件(Theano,Caffe等)。它有4塊Titan X GPU,目前售價15,000美元。
13、Fuel
Fuel是一款管理數(shù)據(jù)集迭代的工具,它可以將數(shù)據(jù)集切分成若干小部分,進行shuffle操作,執(zhí)行多種預(yù)處理步驟等。對于一些建立好的數(shù)據(jù)集有預(yù)置的功能,比如MNIST,CIFAR-10和谷歌的10億詞匯語料庫。它主要是與Blocks結(jié)合使用,Blocks是使用Theano簡化網(wǎng)絡(luò)結(jié)構(gòu)的工具。
14、多模型語言學(xué)規(guī)律
記得“國王-男性+女性=女王”嗎?事實上圖片也能這么處理(Kiros等人,2015)。

15、泰勒級數(shù)逼近
當(dāng)我們在點處,向移動時,那么我們可以通過計算導(dǎo)函數(shù)來估計函數(shù)在新位置的值,我們將使用泰勒級數(shù)逼近:
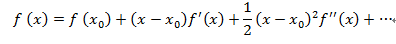
同樣地,當(dāng)我們將參數(shù)更新到時,我們可以估計損失函數(shù):
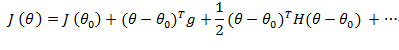
其中g(shù)是對θ的導(dǎo)數(shù),H是對θ的二階Hessian導(dǎo)數(shù)。
這是二階泰勒逼近,但是我們可以通過采用更高階導(dǎo)數(shù)來增加準(zhǔn)確性
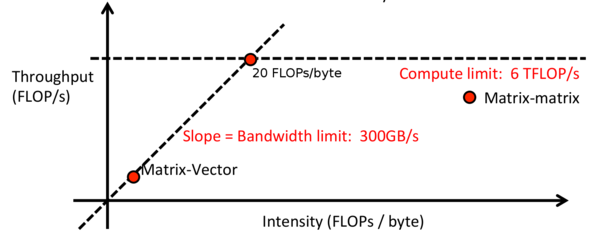
16、計算強度
Adam Coates 提出了一種分析GPU上矩陣操作速度的策略。這是一個簡化的模型,可以顯示花在讀取內(nèi)存或者進行計算的時間。假設(shè)你可以同時計算這兩個值,那么我們就可以知道那一部分耗費時間更多。
假設(shè)我們將矩陣和一個向量相乘:

如果M=1024,N=512,那么我們需要讀取和存儲的字節(jié)數(shù)是:
4 bytes ×(1024×512+512+1024)=2.1e6 bytes
計算次數(shù)是:
2×1024×512=1e6 FLOPs
如果我們有塊6TFLOP/s的GPU,帶寬300GB/s的內(nèi)存,那么運行總時間是:
max{2.1e6 bytes /(300e9 bytes/s),1e6 FLOPs/(6e12 FLOP/s)}=max{7μs,0.16μs}
這意味著處理過程的瓶頸在于從內(nèi)存中復(fù)制或向內(nèi)存中寫入消耗的7μs,而且使用更快的GPU也不會提升速度了。你可能會猜到,在進行矩陣-矩陣操作時,當(dāng)矩陣/向量變大時,這一情況會有所好轉(zhuǎn)。
Adam同樣給出了計算操作強度的算法:
強度= (#算術(shù)操作)/(#字節(jié)加載或存儲數(shù))
在之前的場景中,強度是這樣的:
強度= (1e6 FLOPs)/(2.1e6 bytes)= 0.5FLOPs/bytes
低強度意味著系統(tǒng)受內(nèi)存大小的牽制,高強度意味著受GPU速度的牽制。這可以被可視化,由此來決定應(yīng)該改進哪個方面來提升整體系統(tǒng)速度,并且可以觀察較佳點的位置。
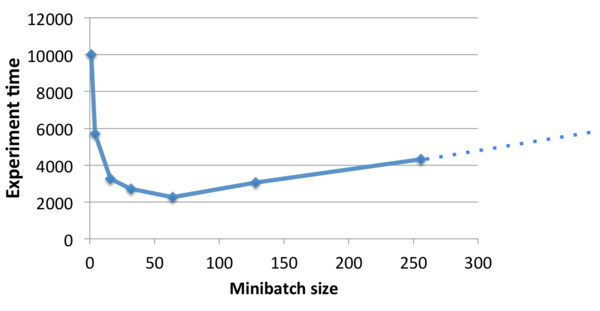
17、小批量
繼續(xù)說說計算強度,增加網(wǎng)絡(luò)強度的一種方式(受計算而不是內(nèi)存限制)是,將數(shù)據(jù)分成小批量。這可以避免一些內(nèi)存操作,GPU也擅長并行處理大矩陣計算。
然而,增加批次的大小的話可能會對訓(xùn)練算法有影響,并且合并需要更多時間。重要的是要找到一個很好的平衡點,以在最短的時間內(nèi)獲得較好的效果。
18、對抗樣本的訓(xùn)練
據(jù)最近信息顯示,神經(jīng)網(wǎng)絡(luò)很容易被對抗樣本戲弄。在下面的案例中,左邊的圖片被正確分類成金魚。但是,如果我們加入中間圖片的噪音模式,得到了右邊這張圖片,分類器認(rèn)為這是一張雛菊的圖片。圖片來自于Andrej Karpathy的博客 “Breaking Linear Classifiers on ImageNet”,你可以從那了解更多。

噪音模式并不是隨機選擇的,而是為了戲弄網(wǎng)絡(luò)通過精心計算得到的。但是問題依然存在:右邊的圖像顯然是一張金魚而不是雛菊。
顯然,像集成模型,多掃視后投票和無監(jiān)督預(yù)訓(xùn)練的策略都不能解決這個漏洞。使用高度正則化會有所幫助,但會影響判斷不含噪聲圖像的準(zhǔn)確性。
Ian Goodfellow提出了訓(xùn)練這些對抗樣本的理念。它們可以自動的生成并添加到訓(xùn)練集中。下面的結(jié)果表明,除了對對抗樣本有所幫助之外,這也提高了原始樣本上的準(zhǔn)確性。
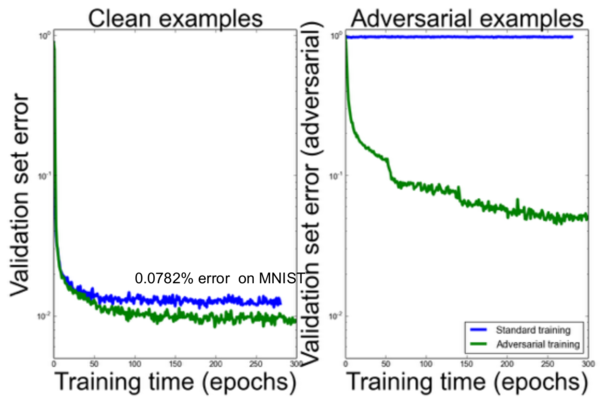
最后,我們可以通過懲罰原始預(yù)測分布與對抗樣本上的預(yù)測分布之間的KL發(fā)散來進一步改善結(jié)果。這將優(yōu)化網(wǎng)絡(luò)使之更具魯棒性,并能夠?qū)ο嗨疲▽沟模﹫D像預(yù)測相似類分布。
19、萬事萬物皆為語言建模
Phil Blunsom 提出,幾乎所有的NLP都可以構(gòu)建成語言模型。我們可以通過這種方式實現(xiàn),將輸出與輸入連接,并嘗試預(yù)測整個序列的概率。
翻譯:
P(Les chiens aiment les os || Dogs love bones)
問答:
P(What do dogs love? || bones .)
對話:
P(How are you? || Fine thanks. And you?)
后兩個必須建立在對世界已知事物了解的基礎(chǔ)上。第二部分甚至可以不是詞語,也可以是一些標(biāo)簽或者結(jié)構(gòu)化輸出,比如依賴關(guān)系。
20、SMT開頭難
當(dāng)Frederick Jelinek 和他在IBM的團隊在1988年提交了關(guān)于統(tǒng)計機器翻譯第一批之一的論文時,他們的到了如下的匿名評審:

正如作者提到的,早在1949年Weaver就肯定了統(tǒng)計(信息論)方法進行機器翻譯的有效性。而在1950年被普遍認(rèn)為是錯誤的(參見Hutchins, MT – Past, Present, Future, Ellis Horwood, 1986, p. 30ff 和參考文獻)。計算機的暴力解決并不是科學(xué)。該論文已經(jīng)超出了COLING的范圍。
21、神經(jīng)機器翻譯(Neural Machine Translation)現(xiàn)狀
顯然,一個非常簡單的神經(jīng)網(wǎng)絡(luò)模型可以產(chǎn)生出奇好的結(jié)果。下圖是Phil Blunsom的一張幻燈片,將中文翻譯成英文的例子:

在這個模型中,漢字向量簡單地相加在一起形成一個語句向量。解碼器包含一個條件性語言模型,將語句向量和兩個最近生成的英語單詞中的向量結(jié)合,然后生成譯文中下一個單詞。
然而,神經(jīng)模型仍然沒有將傳統(tǒng)機器翻譯系統(tǒng)性能發(fā)揮到極致。但是它們已經(jīng)相當(dāng)接近了。Sutskever等人(2014)在“Sequence to Sequence Learning with Neural Networks”中的結(jié)果:
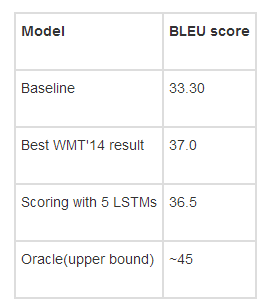
更新:@stanfordnlp指出,最近一些結(jié)果表明,神經(jīng)模型確實會將傳統(tǒng)機器翻譯系統(tǒng)性能發(fā)揮到極致。查看這篇論文“Effective Approaches to Attention-based Neural Machine Translation”(Luong等人,2015)
22、偉大人物的分類例子
Richard Socher演示了偉大人物圖像分類例子,你可以自己上傳圖像來訓(xùn)練。我訓(xùn)練了一個可以識別愛迪生和愛因斯坦(不能找到足夠的特斯拉個人相片)的分類器。每個類有5張樣本圖片,對每個類測試輸出圖像。似乎效果不錯。

23、優(yōu)化梯度更新
Mark Schmidt給出了兩份關(guān)于在不同情況下數(shù)值優(yōu)化的報告。
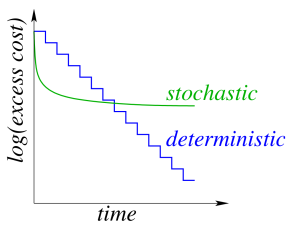
在確定性梯度方法中,我們在整個數(shù)據(jù)集上計算了梯度,然后更新它。迭代成本與數(shù)據(jù)集大小呈線性關(guān)系。
在隨機梯度方法中,我們在一個數(shù)據(jù)點上計算了梯度,然后更新它。迭代成本與數(shù)據(jù)集大小無關(guān)。
隨機梯度下降中的每次迭代要快許多,但是它通常需要更多的迭代來訓(xùn)練網(wǎng)絡(luò),如下圖所示:
為了達到這兩者較好效果,我們可以用批量處理。確切的說,我們可以對數(shù)據(jù)集先進行隨機梯度下降,為快速達到右邊的部分,然后開始增加批大小。梯度誤差隨著批大小的增加而減少,然而最終迭代成本大小還是會取決于數(shù)據(jù)集大小。
隨機平均梯度(SAG)可以避免這樣的情況,每次迭代只有1個梯度,從而得到線性收斂速度。不幸的是,這對于大型神經(jīng)網(wǎng)絡(luò)是不可行的,因為它們需要記住每一個數(shù)據(jù)點的梯度更新,這就會耗費大量內(nèi)存。隨機方差降低梯度(SVRG)可以減少這種內(nèi)存耗費的情況,并且每次迭代(加上偶然全部通過)只需要兩次梯度計算。
Mark表示,他的一位學(xué)生實現(xiàn)了各種優(yōu)化方法(AdaGrad,momentum,SAG等)。當(dāng)問及在黑盒神經(jīng)網(wǎng)絡(luò)系統(tǒng)中他會使用什么方法時,這位學(xué)生給出了兩種方法:Streaming SVRG(Frostig等人,2015),和一種他們還沒發(fā)布的方法。
24、Theano分析
如果你將“profile=true”賦值給THEANO_FLAGS,它將會分析你的程序,然后顯示花在每個操作上的時間。對尋找性能瓶頸很有幫助。
25、對抗性網(wǎng)絡(luò)框架
繼Ian Goodfellow關(guān)于對抗性樣本的演講之后,Yoshua Bengio 談到了用兩個系統(tǒng)相互競爭的案例。
系統(tǒng)D是一套判別性系統(tǒng),它的目的是分類真實數(shù)據(jù)和人工生成的數(shù)據(jù)。
系統(tǒng)G是一套生成系統(tǒng),它試圖生成可以讓系統(tǒng)D錯誤分類成真實數(shù)據(jù)的數(shù)據(jù)。
當(dāng)我們訓(xùn)練一個系統(tǒng)時,另外一個系統(tǒng)也要相應(yīng)的變的更好。在實驗中這的確有效,不過步長必須保持十分小,以便于系統(tǒng)D可以更上G的速度。下面是“Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks”中的一些例子——這個模型的一個更高級版本,它試圖生成教堂的圖片。

26、arXiv.org編號
arXiv編號包含著論文提交的年份和月份,后面跟著序列號,比如論文1508.03854表示編號3854的論文在2015年8月份提交。很高興知道這個。
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4438.html
摘要:另外,當(dāng)損失函數(shù)接近全局最小時,概率會增加。降低訓(xùn)練過程中的學(xué)習(xí)率。對抗樣本的訓(xùn)練據(jù)最近信息顯示,神經(jīng)網(wǎng)絡(luò)很容易被對抗樣本戲弄。使用高度正則化會有所幫助,但會影響判斷不含噪聲圖像的準(zhǔn)確性。 由 Yoshua Bengio、 Leon Bottou 等大神組成的講師團奉獻了 10 天精彩的講座,劍橋大學(xué)自然語言處理與信息檢索研究組副研究員 Marek Rei 參加了本次課程,在本文中,他精煉地...
摘要:但是在當(dāng)時,幾乎沒有人看好深度學(xué)習(xí)的工作。年,與和共同撰寫了,這本因封面被人們親切地稱為花書的深度學(xué)習(xí)奠基之作,也成為了人工智能領(lǐng)域不可不讀的圣經(jīng)級教材。在年底,開始為深度學(xué)習(xí)的產(chǎn)業(yè)孵化助力。 蒙特利爾大學(xué)計算機科學(xué)系教授 Yoshua Bengio從法國來到加拿大的時候,Yoshua Bengio只有12歲。他在加拿大度過了學(xué)生時代的大部分時光,在麥吉爾大學(xué)的校園中接受了從本科到博士的完整...
摘要:的研究興趣涵蓋大多數(shù)深度學(xué)習(xí)主題,特別是生成模型以及機器學(xué)習(xí)的安全和隱私。與以及教授一起造就了年始的深度學(xué)習(xí)復(fù)興。目前他是僅存的幾個仍然全身心投入在學(xué)術(shù)界的深度學(xué)習(xí)教授之一。 Andrej Karpathy特斯拉 AI 主管Andrej Karpathy 擁有斯坦福大學(xué)計算機視覺博士學(xué)位,讀博期間師從現(xiàn)任 Google AI 首席科學(xué)家李飛飛,研究卷積神經(jīng)網(wǎng)絡(luò)在計算機視覺、自然語言處理上的應(yīng)...
摘要:今年月日收購了基于深度學(xué)習(xí)的計算機視覺創(chuàng)業(yè)公司。這項基于深度學(xué)習(xí)的計算機視覺技術(shù)已經(jīng)開發(fā)完成,正在測試。深度學(xué)習(xí)的誤區(qū)及產(chǎn)品化浪潮百度首席科學(xué)家表示目前圍繞存在著某種程度的夸大,它不單出現(xiàn)于媒體的字里行間,也存在于一些研究者之中。 在過去的三十年,深度學(xué)習(xí)運動一度被認(rèn)為是學(xué)術(shù)界的一個異類,但是現(xiàn)在, Geoff Hinton(如圖1)和他的深度學(xué)習(xí)同事,包括紐約大學(xué)Yann LeCun和蒙特...
摘要:毫無疑問,現(xiàn)在深度學(xué)習(xí)是主流。所以科技巨頭們包括百度等紛紛通過收購深度學(xué)習(xí)領(lǐng)域的初創(chuàng)公司來招攬人才。這項基于深度學(xué)習(xí)的計算機視覺技術(shù)已經(jīng)開發(fā)完成,正在測試。 在過去的三十年,深度學(xué)習(xí)運動一度被認(rèn)為是學(xué)術(shù)界的一個異類,但是現(xiàn)在,?Geoff Hinton(如圖1)和他的深度學(xué)習(xí)同事,包括紐約大學(xué)Yann LeCun和蒙特利爾大學(xué)的Yoshua Bengio,在互聯(lián)網(wǎng)世界受到前所未有的關(guān)注...

閱讀 2831·2023-04-26 02:23
閱讀 1570·2021-11-11 16:55
閱讀 3149·2021-10-19 11:47
閱讀 3352·2021-09-22 15:15
閱讀 1975·2019-08-30 15:55
閱讀 1033·2019-08-29 15:43
閱讀 1288·2019-08-29 13:16
閱讀 2188·2019-08-29 12:38






