資訊專欄INFORMATION COLUMN

摘要:自從年深秋,他開始在上撰寫并公開分享他感興趣的機(jī)器學(xué)習(xí)論文。本文選取了上篇閱讀注釋的機(jī)器學(xué)習(xí)論文筆記。希望知名專家注釋的深度學(xué)習(xí)論文能使一些很復(fù)雜的概念更易于理解。主要講述的是奧德賽因?yàn)榧づ撕I癫ㄙ惗喽兄聻?zāi)禍。
Hugo Larochelle博士是一名謝布克大學(xué)機(jī)器學(xué)習(xí)的教授,社交媒體研究科學(xué)家、知名的神經(jīng)網(wǎng)絡(luò)研究人員以及深度學(xué)習(xí)狂熱愛好者。自從2015年深秋,他開始在arXiv上撰寫并公開分享他感興趣的機(jī)器學(xué)習(xí)論文。在這篇文章發(fā)布之前,他已經(jīng)分享了10篇論文筆記。

本文選取了arXiv上5篇Hugo閱讀注釋的機(jī)器學(xué)習(xí)論文筆記。為使我們更好地理解這些內(nèi)容,每篇論文介紹了摘要并附上了Hugo的筆記。希望知名專家注釋的深度學(xué)習(xí)論文能使一些很復(fù)雜的概念更易于理解。
1.非回溯遞歸網(wǎng)絡(luò)訓(xùn)練
Training recurrent networks online without backtracking
作者:Yann Ollivier、Guillaume Charpiat
arXiv上發(fā)布日期:2015年7月28日
摘要(摘錄):我們引入「非回溯」算法來訓(xùn)練類似遞歸神經(jīng)網(wǎng)絡(luò)這樣的動(dòng)態(tài)系統(tǒng)的參數(shù)。這個(gè)算法在線上、無內(nèi)存的條件下運(yùn)行,因此不需要反向時(shí)間傳播,有可拓展性,避免了保持當(dāng)前狀態(tài)參數(shù)的全向梯度所需要的大量的計(jì)算和內(nèi)存成本。[…]先前在簡(jiǎn)單任務(wù)上的測(cè)試表明,相對(duì)于保持全向梯度,引入梯度隨機(jī)近似算法后,似乎并沒有給軌跡引入過多噪聲,可以確認(rèn)具有優(yōu)良性能和保證在卡爾曼版本的非回溯算法上的可拓展性。
Hugo的注釋(摘錄):
RNN線上訓(xùn)練是一個(gè)宏大而未解決的問題。
人們現(xiàn)今使用的方法是把回溯截?cái)酁閹讉€(gè)過去的步長(zhǎng),這更多是一種探索性的做法。
這篇論文在原則方法基礎(chǔ)上更近了一步。我很欣賞方程式7的「秩一技巧」,很精致可愛!這也是這個(gè)方法的中心,把這些點(diǎn)聯(lián)系到了一起,干得真好!
作者介紹這項(xiàng)工作只是初步的,他們確實(shí)并沒有和截?cái)嗷厮荼容^。我迫切希望他們?cè)谖磥淼墓ぷ髦凶鱿卤容^,并且,我不贊同『隨機(jī)梯度下降理論在此處可以應(yīng)用到』這個(gè)論點(diǎn)。
2.基于梯形網(wǎng)絡(luò)的半監(jiān)督學(xué)習(xí)
Semi-Supervised Learning with Ladder Network
作者:Antti Rasmus、Harri Valpola、Mikko Honkala、Mathias Berglund,、Tapani Raiko
arXiv上發(fā)布日期:2015年7月9日
摘要:在深度神經(jīng)網(wǎng)絡(luò)中,我們把監(jiān)督學(xué)習(xí)和無監(jiān)督學(xué)習(xí)結(jié)合到一起。我們首先訓(xùn)練提出的模型在使用反向傳播后可以同時(shí)最小化監(jiān)督和無監(jiān)督消耗函數(shù),從而省去了逐層預(yù)先訓(xùn)練步驟的必要。我們的工作建立在Valpola2015年提出的梯形網(wǎng)絡(luò)基礎(chǔ)上,我們把這個(gè)模型和監(jiān)督結(jié)合起來進(jìn)行了拓展。我們展示了拓展模型在各種任務(wù)中:半監(jiān)督條件下MNIST和CIFAR-10分類,半監(jiān)督和全標(biāo)簽條件下的定量MNIST的排列過程,都達(dá)到藝術(shù)級(jí)性能。
Hugo的注釋(摘錄):
我認(rèn)為,性能是這篇論文最令人興奮的。在MNIST上,僅僅通過100個(gè)標(biāo)簽樣本,它達(dá)到1.13%的錯(cuò)誤率。這與訓(xùn)練集上訓(xùn)練的堆疊去噪自編碼的性能相媲美(盡管它出現(xiàn)在這篇文章使用的ReLUs和批標(biāo)準(zhǔn)化之前)!盡管應(yīng)用到許多標(biāo)簽的數(shù)據(jù)集的深度學(xué)習(xí)進(jìn)展并不依賴任何無監(jiān)督學(xué)習(xí)(不像在2000-2010年中期深度學(xué)習(xí)剛開始時(shí)),這篇論文確認(rèn)了深度學(xué)習(xí)中一個(gè)當(dāng)前思路,即無監(jiān)督學(xué)習(xí)可能對(duì)半監(jiān)督條件下低標(biāo)簽數(shù)據(jù)的成功起著關(guān)鍵作用。
不幸的是,作者披露實(shí)驗(yàn)中存在一個(gè)很小的問題:雖然他們使用很少的標(biāo)簽樣本來訓(xùn)練,在驗(yàn)證集中模型選擇的確使用了1萬(wàn)個(gè)標(biāo)簽。這的確很不現(xiàn)實(shí)。
3.面向基于神經(jīng)網(wǎng)絡(luò)的分析
Towards Neural Network-based Reasoning
作者:Baolin Peng,、Zhengdong Lu、 Hang Li、Kam-Fai Wong
arXiv上發(fā)布日期:2015年8月22日
摘要(摘錄):我們建議推出神經(jīng)推理器,這是一個(gè)基于神經(jīng)網(wǎng)絡(luò)的推理自然語(yǔ)言的框架。只要給定一個(gè)問題,神經(jīng)推理器能根據(jù)多種支持的事實(shí)進(jìn)行推斷并以特殊的方式找到答案。神經(jīng)推理器具備:1)一個(gè)特別的互動(dòng)池機(jī)制,允許它檢驗(yàn)多重事實(shí),2)一個(gè)深度架構(gòu),允許它在推理作業(yè)中模化復(fù)雜的邏輯關(guān)系。假定問題和事實(shí)并不存在特殊的結(jié)構(gòu),神經(jīng)推斷器能夠容納不同類型的推斷和不同的語(yǔ)言表達(dá)形式。[…]經(jīng)驗(yàn)研究表明,在兩種不同人工作業(yè)上(定位和尋路),神經(jīng)推斷器能在很大程度上超越現(xiàn)有神經(jīng)推斷系統(tǒng)。
Hugo的注釋(摘錄):
在我看來,這篇論文最有趣的方面可能是證明通過使用一些從屬任務(wù),比如無監(jiān)督的“起點(diǎn)”,可以顯著提高在尋路任務(wù)上的表現(xiàn)。對(duì)我來說最令人興奮的莫過于這篇論文中強(qiáng)調(diào)的,未來可能極其光明的研究方向。
我也欣賞文中模型展示的方式。理解模型并沒有花費(fèi)我太多的時(shí)間,實(shí)際上我發(fā)現(xiàn)他比記憶網(wǎng)絡(luò)模型更易于消化,盡管這兩個(gè)模型很相似。我認(rèn)為這個(gè)模型確實(shí)比記憶模型更簡(jiǎn)單點(diǎn),這很好。論文還提出這個(gè)問題的另一種解決辦法,這個(gè)方法里不僅問題表征會(huì)隨著正向傳播更新,事實(shí)表征也會(huì)更新。
4.基于遞歸神經(jīng)網(wǎng)絡(luò)的定時(shí)采樣序列預(yù)測(cè)
Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks
作者:Samy Bengio、Oriol Vinyals、Navdeep Jaitly、Noam Shazeer
arXiv上發(fā)布日期:2015年6月9日
摘要(摘錄):我們可以訓(xùn)練周期神經(jīng)網(wǎng)絡(luò),使它在給予一定輸入時(shí)產(chǎn)生符號(hào)序列,正如機(jī)器翻譯和圖像識(shí)別的結(jié)果例證的一樣。當(dāng)前訓(xùn)練它們的方法包括,在給定當(dāng)前(遞歸)狀態(tài)和先前符號(hào)時(shí),較大化每個(gè)符號(hào)序列的相似性,。在推導(dǎo)上,未知的先前符號(hào)被模型產(chǎn)生的符號(hào)代替。訓(xùn)練和推導(dǎo)的內(nèi)容不符會(huì)產(chǎn)生誤差,誤差會(huì)隨著產(chǎn)生的序列迅速累積。我們提出了一個(gè)課程學(xué)習(xí)策略,從一個(gè)完全引導(dǎo)的方案,柔和過度到不完全引導(dǎo)方案,前者完全使用正確的前符號(hào),后者主要使用系統(tǒng)自己生成的符號(hào)。一些序列預(yù)測(cè)作業(yè)試驗(yàn)顯示這個(gè)方法可帶來很大改善。
Hugo的注釋(摘錄):
超愛這篇論文。它甄別到目前序列預(yù)測(cè)訓(xùn)練方法的一個(gè)重要缺點(diǎn),最重要的是,同時(shí)提出了一個(gè)簡(jiǎn)單有效的解決方案。我也相信這個(gè)方法在谷歌圖像識(shí)別生成贏家系統(tǒng)以及微軟COCO競(jìng)賽中起著不可忽視的作用。
關(guān)于定時(shí)采樣有助的原因,我的另一個(gè)理解是:ML訓(xùn)練并不會(huì)告知模型自己產(chǎn)生的誤差的相對(duì)質(zhì)量。就ML而言,把高概率放在一個(gè)僅有一個(gè)錯(cuò)誤令牌的輸出序列和把相同概率放在一個(gè)有全部錯(cuò)誤令牌的序列上同樣糟糕。然而就圖像識(shí)別來說,輸出僅有一個(gè)錯(cuò)字的語(yǔ)句明顯比有許多錯(cuò)字的語(yǔ)句(某種也反映在性能矩陣的東西,比如BLEU)更為可取。
通過訓(xùn)練模型在面對(duì)自身錯(cuò)誤的系統(tǒng)穩(wěn)定性,定時(shí)采樣可確保誤差不會(huì)累積,并且(幫助系統(tǒng))做出八九不離十的預(yù)測(cè)。
5.LSTM:一個(gè)空間搜索奧德賽
LSTM_ A Search Space Odyssey
作者:Klaus Treff、Rupesh Kumar Srivastava、Jan Koutník、Bas R. Steunebrink、 Jürgen Schmidhuber
arXiv上發(fā)布日期:2015年5月13日
譯者按:奧德賽是古希臘史詩(shī)中重要一部。主要講述的是奧德賽因?yàn)榧づ撕I癫ㄙ惗喽兄聻?zāi)禍。最后利用智慧歷經(jīng)重重磨難得以回家的故事。文中指富有偉大意義卻艱辛的科學(xué)探索之旅。
摘要(摘錄):本文在3個(gè)代表性任務(wù)測(cè)試:語(yǔ)音識(shí)別,手寫字體識(shí)別和復(fù)調(diào)音樂建模上,首次大規(guī)模使用8LSTM變量分析。使用隨機(jī)搜索,多帶帶優(yōu)化每個(gè)作業(yè)的所有LSTM變量的超參數(shù),并且使用強(qiáng)大的fANOVA結(jié)構(gòu)評(píng)估它們的重要性。我們一共總結(jié)了5400次試驗(yàn)運(yùn)行結(jié)果(CPU時(shí)間大概15年),這使我們的研究成為同類LSTM網(wǎng)絡(luò)研究中規(guī)模較大的。我們的結(jié)果表明,在標(biāo)準(zhǔn)LSTM架構(gòu)上沒有一種變量能顯著提高,并且可以證明忘記門和激勵(lì)函數(shù)的輸出結(jié)果是它最重要的部分。我們進(jìn)一步觀察到這些被研究的超參數(shù)是實(shí)質(zhì)上是獨(dú)立的,并在為它們的有效調(diào)整制定了指導(dǎo)方針。
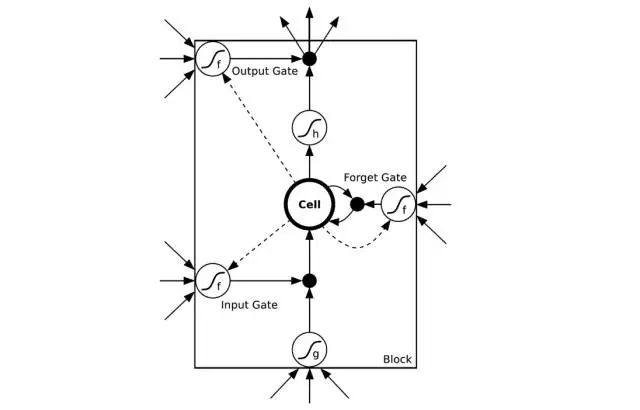
譯者注:如圖所示是一個(gè)LSTM簡(jiǎn)易版模型。其中input gate輸入門/output gate輸出門負(fù)責(zé)管理輸入及輸出數(shù)值。forget gate忘記門負(fù)責(zé)選擇性刪除一些系統(tǒng)以前記住的數(shù)值來確保可以更好記住近期數(shù)值。圖片來自CSDN
Hugo的注釋(摘錄):
這是一篇很有用的(幫你)熱身準(zhǔn)備的文章。對(duì)任何想要學(xué)習(xí)LSTMs的人,我都會(huì)推薦這篇文章必讀。首先,我發(fā)現(xiàn)它對(duì)LSTMs最初的發(fā)展史的描述很有趣并且很明了。但是,最重要的是,它展現(xiàn)了LSTMs一個(gè)很實(shí)用的圖景,這不僅可以為初次使用LSTMs的奠定優(yōu)良基礎(chǔ),還可以作為一個(gè)對(duì)LSTM每一部分重要性的很有見地的(數(shù)據(jù)支撐的)觀點(diǎn)闡述。
基于fANONA的分析(目前我還不了解)很精煉。可能最讓我震驚的發(fā)現(xiàn)是,勢(shì)頭的幫助實(shí)際上看起來并不大。研究超參數(shù)之間的二階互動(dòng)構(gòu)思很巧妙(通過表明同時(shí)調(diào)整學(xué)習(xí)頻率和隱藏層 可能并不重要,這很有見地)。圖4中的描述陳列出學(xué)習(xí)頻率/隱藏層大小/輸入噪聲變量和性能/訓(xùn)練時(shí)間之間可能存在的關(guān)系(帶有不確定性)也是很有用的信息。
前向傳播
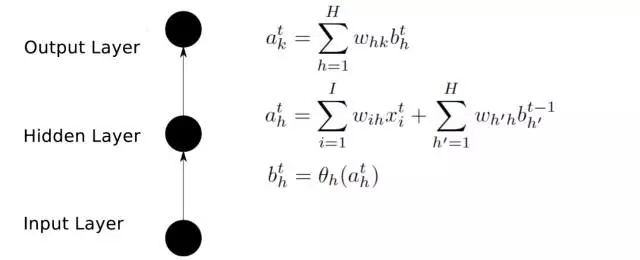
后向傳播

譯者注:
輸入層(Input layer),眾多神經(jīng)元(Neuron)接受大量非線形輸入信息。輸入的信息稱為輸入向量。
輸出層(Output layer),信息在神經(jīng)元鏈接中傳輸、分析、權(quán)衡,形成輸出結(jié)果。輸出的信息稱為輸出向量。
隱藏層(Hidden layer),簡(jiǎn)稱“隱層”,是輸入層和輸出層之間眾多神經(jīng)元和鏈接組成的各個(gè)層面。隱層可以有多層,習(xí)慣上會(huì)用一層。隱層的節(jié)點(diǎn)(神經(jīng)元)數(shù)目不定,但數(shù)目越多神經(jīng)網(wǎng)絡(luò)的非線性越顯著,從而神經(jīng)網(wǎng)絡(luò)的強(qiáng)健性
文章版權(quán)歸作者所有,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請(qǐng)注明本文地址:http://specialneedsforspecialkids.com/yun/4323.html
摘要:昨天,研究院開源了,業(yè)內(nèi)較佳水平的目標(biāo)檢測(cè)平臺(tái)。項(xiàng)目地址是實(shí)現(xiàn)頂尖目標(biāo)檢測(cè)算法包括的軟件系統(tǒng)。因此基本上已經(jīng)是最目前包含最全與最多目標(biāo)檢測(cè)算法的代碼庫(kù)了。 昨天,F(xiàn)acebook AI 研究院(FAIR)開源了 Detectron,業(yè)內(nèi)較佳水平的目標(biāo)檢測(cè)平臺(tái)。據(jù)介紹,該項(xiàng)目自 2016 年 7 月啟動(dòng),構(gòu)建于 Caffe2 之上,目前支持大量機(jī)器學(xué)習(xí)算法,其中包括 Mask R-CNN(何愷...
摘要:團(tuán)隊(duì)昨天發(fā)布的一個(gè)模型學(xué)會(huì)一切論文背后,有一個(gè)用來訓(xùn)練模型的模塊化多任務(wù)訓(xùn)練庫(kù)。模塊化的多任務(wù)訓(xùn)練庫(kù)利用工具來開發(fā),定義了一個(gè)深度學(xué)習(xí)系統(tǒng)中需要的多個(gè)部分?jǐn)?shù)據(jù)集模型架構(gòu)優(yōu)化工具學(xué)習(xí)速率衰減計(jì)劃,以及超參數(shù)等等。 Google Brain團(tuán)隊(duì)昨天發(fā)布的一個(gè)模型學(xué)會(huì)一切論文背后,有一個(gè)用來訓(xùn)練MultiModel模型的模塊化多任務(wù)訓(xùn)練庫(kù):Tensor2Tensor。今天,Google Brain...
摘要:對(duì)于大多數(shù)想上手深度學(xué)習(xí)的小伙伴來說,我應(yīng)當(dāng)從那篇論文開始讀起這是一個(gè)亙古不變的話題。接下來的論文將帶你深入理解深度學(xué)習(xí)方法深度學(xué)習(xí)在前沿領(lǐng)域的不同應(yīng)用。 對(duì)于大多數(shù)想上手深度學(xué)習(xí)的小伙伴來說,我應(yīng)當(dāng)從那篇論文開始讀起?這是一個(gè)亙古不變的話題。而對(duì)那些已經(jīng)入門的同學(xué)來說,了解一下不同方向的論文,也是不時(shí)之需。有沒有一份完整的深度學(xué)習(xí)論文導(dǎo)引,讓所有人都可以在里面找到想要的內(nèi)容呢?有!今天就給...
摘要:深度學(xué)習(xí)架構(gòu)清單現(xiàn)在我們明白了什么是高級(jí)架構(gòu),并探討了計(jì)算機(jī)視覺的任務(wù)分類,現(xiàn)在讓我們列舉并描述一下最重要的深度學(xué)習(xí)架構(gòu)吧。是較早的深度架構(gòu),它由深度學(xué)習(xí)先驅(qū)及其同僚共同引入。這種巨大的差距由一種名為的特殊結(jié)構(gòu)引起。 時(shí)刻跟上深度學(xué)習(xí)領(lǐng)域的進(jìn)展變的越來越難,幾乎每一天都有創(chuàng)新或新應(yīng)用。但是,大多數(shù)進(jìn)展隱藏在大量發(fā)表的 ArXiv / Springer 研究論文中。為了時(shí)刻了解動(dòng)態(tài),我們創(chuàng)建了...
摘要:我的核心觀點(diǎn)是盡管我提出了這么多問題,但我不認(rèn)為我們需要放棄深度學(xué)習(xí)。對(duì)于層級(jí)特征,深度學(xué)習(xí)是非常好,也許是有史以來效果較好的。認(rèn)為有問題的是監(jiān)督學(xué)習(xí),并非深度學(xué)習(xí)。但是,其他監(jiān)督學(xué)習(xí)技術(shù)同病相連,無法真正幫助深度學(xué)習(xí)。 所有真理必經(jīng)過三個(gè)階段:第一,被嘲笑;第二,被激烈反對(duì);第三,被不證自明地接受。——叔本華(德國(guó)哲學(xué)家,1788-1860)在上篇文章中(參見:打響新年第一炮,Gary M...

閱讀 3373·2023-04-26 01:40
閱讀 3080·2021-11-24 09:39
閱讀 1393·2021-10-27 14:19
閱讀 2638·2021-10-12 10:11
閱讀 1298·2021-09-26 09:47
閱讀 1840·2021-09-22 15:21
閱讀 2678·2021-09-06 15:00
閱讀 879·2021-08-10 09:44






