資訊專欄INFORMATION COLUMN

摘要:團隊昨天發布的一個模型學會一切論文背后,有一個用來訓練模型的模塊化多任務訓練庫。模塊化的多任務訓練庫利用工具來開發,定義了一個深度學習系統中需要的多個部分數據集模型架構優化工具學習速率衰減計劃,以及超參數等等。
Google Brain團隊昨天發布的“一個模型學會一切”論文背后,有一個用來訓練MultiModel模型的模塊化多任務訓練庫:Tensor2Tensor。
今天,Google Brain高級研究員?ukasz Kaiser就在官方博客上發文,詳細介紹了新開源的T2T庫。
以下內容編譯自Google Research的官方博客:
深度學習推動了許多技術的快速發展,例如機器翻譯、語音識別和對象檢測。在科研領域,人們可以查找作者開源的代碼,從而復現他們的研究成果,推動深度學習技術的進一步發展。
然而,這些深度學習系統大部分都采用了獨特配置,需要大量的工程開發,并且可能只適用于特定的問題或架構,導致很難嘗試新的實驗并比較結果。
今天,我們很高興發布Tensor2Tensor (T2T),一個用于在TensorFlow中訓練深度學習模型的開源系統。
T2T有助于開發頂尖水平的模型,并適用各類機器學習應用,例如翻譯、分析和圖像標注等。這意味著,對各種不同想法的探索要比以往快得多。
此次發布的這個版本還提供了由數據集和模型構成的庫文件,包括近期幾篇論文中最優秀的模型(文末列舉了這幾篇論文),從而推動你自己的深度學習研究。
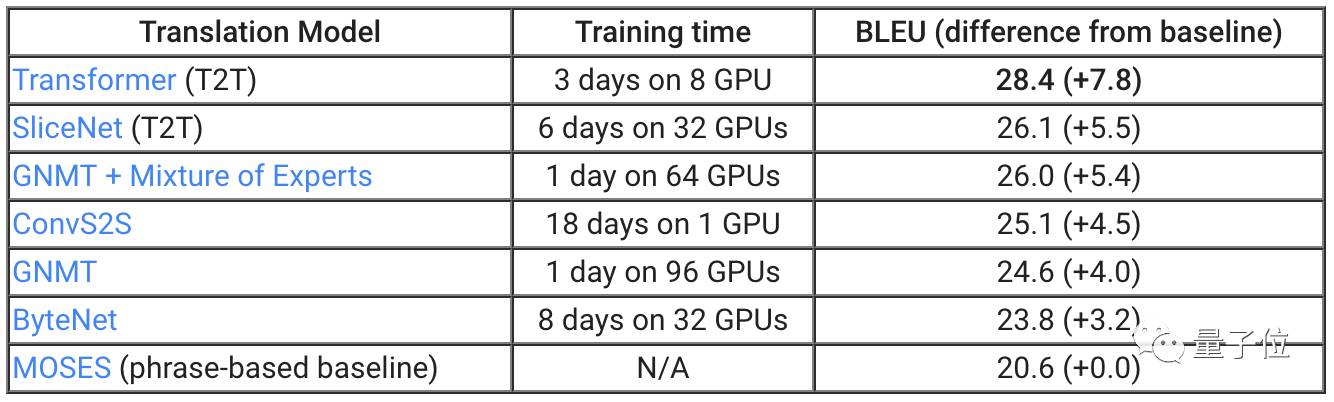
為了證明T2T可以帶來的改進,我們將庫文件應用于機器翻譯。正如上表所顯示的,兩個不同的T2T模型,SliceNet和Transformer,超過了此前表現較好的系統GNMT+MoE。
我們最優秀的T2T模型Transformer,比標準GNMT模型高出3.8分,而GNMT自身要比作為基準的翻譯系統MOSES高出4分。
值得注意的是,通過T2T,你可以使用單個GPU,在一天時間里獲得此前最漂亮的結果:小規模Transformer模型基于單個GPU在一天的訓練后獲得了24.9 BLEU。
目前,所有擁有GPU的研究者都可以自行探索最強大的翻譯模型。我們在Github上介紹了如何去做。
模塊化的多任務訓練
T2T庫利用TensorFlow工具來開發,定義了一個深度學習系統中需要的多個部分:數據集、模型架構、優化工具、學習速率衰減計劃,以及超參數等等。
最重要的是,T2T在所有這些部分之間實現了標準接口,并配置了當前機器學習的較佳行為方式。
因此,你可以選擇任意數據集、模型、優化工具,以及一套超參數,隨后運行訓練,看看效果如何。
我們實現了架構的模塊化,因此輸入數據和預期輸出結果之間所有部分都是張量到張量的函數。
如果你對模型的架構有新想法,那么不需要替換所有設置。你可以保留嵌入的部分,用自己的函數來替換模型體。這樣的函數以張量為輸入,并返回張量。
這意味著T2T很靈活,訓練不再局限于特定模型或數據集。
這也非常簡單,例如知名的LSTM序列到序列模型可以用幾十行代碼來定義。你也可以用不同類型的多任務來訓練單個模型。在一定的限制下,單個模型甚至可以使用所有數據集來訓練。
例如,我們的MultiModel模型用這種方式在T2T中進行了訓練,在許多任務中取得了良好的結果。這一模型使用的訓練數據集包括ImageNet(圖像分類)、MS COCO(圖像標注)、WSJ(語音識別)、WMT(翻譯),以及Penn Treebank分析語料庫。
這是首次證明,單個模型能同時執行所有這些任務。
內置的較佳行為方式
在最初版本中,我們還提供了腳本,用于生成在研究領域廣泛使用的數據集,少量模型,大量的超參數配置,以及其他一些技巧的配置。
考慮一下這樣的任務:將英語語句解析為語法選區樹。這個問題的研究已有幾十年歷史,并誕生了許多有競爭力的解決辦法。這可以被視為一個序列到序列問題,并使用神經網絡來解決。不過,這需要大量的調節優化。通過T2T,我們只需幾天時間,就可以添加解析數據集生成器,并調整我們的注意力轉換模型,針對這個問題來訓練。驚喜的是,我們在一周時間里就取得了很好的結果。
相關資源
Tensor2Tensor GitHub:
https://github.com/tensorflow/tensor2tensor
Google Research Blog原文:
https://research.googleblog.com/2017/06/accelerating-deep-learning-research.html
文中提到“近期幾篇論文中最優秀的模型”,這幾篇論文分別是:
Attention Is All You Need
https://arxiv.org/abs/1706.03762
Depthwise Separable Convolutions for Neural Machine Translation
https://arxiv.org/abs/1706.03059
One Model to Learn Them All
https://arxiv.org/abs/1706.05137
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4565.html
摘要:機器學習作為時下最為火熱的技術之一受到了廣泛的關注。文中給出的個建議都是針對機器學習系統的,沒有包含通用軟件工程里那些單元測試,發布流程等內容,在實踐中這些傳統最佳實踐也同樣非常重要。 圖片描述 「觀遠AI實戰」欄目文章由觀遠數據算法天團傾力打造,觀小編整理編輯。這里將不定期推送關于機器學習,數據挖掘,特征重要性等干貨分享。本文8千多字,約需要16分鐘閱讀時間。 機器學習作為時下最為火...
摘要:本文內容節選自由主辦的第七屆,北京一流科技有限公司首席科學家袁進輝老師木分享的讓簡單且強大深度學習引擎背后的技術實踐實錄。年創立北京一流科技有限公司,致力于打造分布式深度學習平臺的事實工業標準。 本文內容節選自由msup主辦的第七屆TOP100summit,北京一流科技有限公司首席科學家袁進輝(老師木)分享的《讓AI簡單且強大:深度學習引擎OneFlow背后的技術實踐》實錄。 北京一流...
摘要:它可以用來做語音識別,使得一個處理語音,另一個瀏覽它,使其在生成文本時可以集中在相關的部分上。它對模型使用的計算量予以處罰。 本文的作者是 Google Brain 的兩位研究者 Chris Olah 和 Shan Carter,重點介紹了注意力和增強循環神經網絡,他們認為未來幾年這些「增強 RNN(augmented RNN)」將在深度學習能力擴展中發揮重要的作用。循環神經網絡(recur...

閱讀 2929·2021-10-18 13:33
閱讀 846·2019-08-30 14:20
閱讀 2628·2019-08-30 13:14
閱讀 2518·2019-08-29 18:38
閱讀 2887·2019-08-29 16:44
閱讀 1211·2019-08-29 15:23
閱讀 3482·2019-08-29 13:28
閱讀 1915·2019-08-28 18:00




