hbase管理指南SEARCH AGGREGATION


回答:安裝 HBase(Hadoop Database)是在 Linux 操作系統上進行大規模數據存儲和處理的一種分布式數據庫解決方案。以下是在 Linux 上安裝 HBase 的一般步驟: 步驟 1:安裝 Java 在 Linux 上安裝 HBase 需要 Java 運行時環境(JRE)或 Java 開發工具包(JDK)。您可以通過以下命令安裝 OpenJDK: 對于 Ubuntu/Debian...
 hyuan
|
916人閱讀
hyuan
|
916人閱讀
回答:一、區別:1、Hbase: 基于Hadoop數據庫,是一種NoSQL數據庫;HBase表是物理表,適合存放非結構化的數據。2、hive:本身不存儲數據,通過SQL來計算和處理HDFS上的結構化數據,依賴HDFS和MapReduce;hive中的表是純邏輯表。Hbase主要解決實時數據查詢問題,Hive主要解決數據處理和計算問題,二者通常協作配合使用。二、適用場景:1、Hbase:海量明細數據的隨機...
 wizChen
|
2467人閱讀
wizChen
|
2467人閱讀
問題描述:[hadoop@usdp01 ~]$ hbase shellSLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/opt/usdp-srv/srv/udp/2.0.0.0/hdfs/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]...
回答:1. 如果你對數據的讀寫要求極高,并且你的數據規模不大,也不需要長期存儲,選redis;2. 如果你的數據規模較大,對數據的讀性能要求很高,數據表的結構需要經常變,有時還需要做一些聚合查詢,選MongoDB;3. 如果你需要構造一個搜索引擎或者你想搞一個看著高大上的數據可視化平臺,并且你的數據有一定的分析價值或者你的老板是土豪,選ElasticSearch;4. 如果你需要存儲海量數據,連你自己都...
 xiao7cn
|
946人閱讀
xiao7cn
|
946人閱讀
回答:MySQL是單機性能很好,基本都是內存操作,而且沒有任何中間步驟。所以數據量在幾千萬級別一般都是直接MySQL了。hadoop是大型分布式系統,最經典的就是MapReduce的思想,特別適合處理TB以上的數據。每次處理其實內部都是分了很多步驟的,可以調度大量機器,還會對中間結果再進行匯總計算等。所以數據量小的時候就特別繁瑣。但是數據量一旦起來了,優勢也就來了。
 李世贊
|
514人閱讀
李世贊
|
514人閱讀

...件存儲系統——HDFS 分布式計算框架——MapReduce 集群資源管理器——YARN Hadoop單機偽集群環境搭建 Hadoop集群環境搭建 HDFS常用Shell命令 HDFS Java API的使用 基于Zookeeper搭建Hadoop高可用集群 二、Hive Hive簡介及核心概念 Linux環境下Hive...

...上,無縫集成云端 IaaS 資源能力,通過自研的 USDP Manager 管理工具,支持用戶創建資源獨享的大數據集群,在集群中部署 Hadoop、Hive、HBase、Spark、Flink、Presto 等開源的大數據組件,并對這些組件進行配置管理、監控告警、故障診...
...上,無縫集成云端 IaaS 資源能力,通過自研的 USDP Manager 管理工具,支持用戶創建資源獨享的大數據集群,在集群中部署 Hadoop、Hive、HBase、Spark、Flink、Presto 等開源的大數據組件,并對這些組件進行配置管理、監控告警、故障診...
...上,無縫集成云端 IaaS 資源能力,通過自研的 USDP Manager 管理工具,支持用戶創建資源獨享的大數據集群,在集群中部署 Hadoop、Hive、HBase、Spark、Flink、Presto 等開源的大數據組件,并對這些組件進行配置管理、監控告警、故障診...
...MySQL王者晉級之路》 《深入淺出MySQL 數據庫開發、優化與管理維護》 《MongoDB權威指南(第2版)》 Redis類 《Redis開發與運維》 《Redis設計與實現(第二版)》 《Redis深度歷險:核心原理與應用實踐》 Spring類 《Spring 5核心原理與30個...
...上,無縫集成云端 IaaS 資源能力,通過自研的 USDP Manager 管理工具,支持用戶創建資源獨享的大數據集群,在集群中部署 Hadoop、Hive、HBase、Spark、Flink、Presto 等開源的大數據組件,并對這些組件進行配置管理、監控告警、故障診...
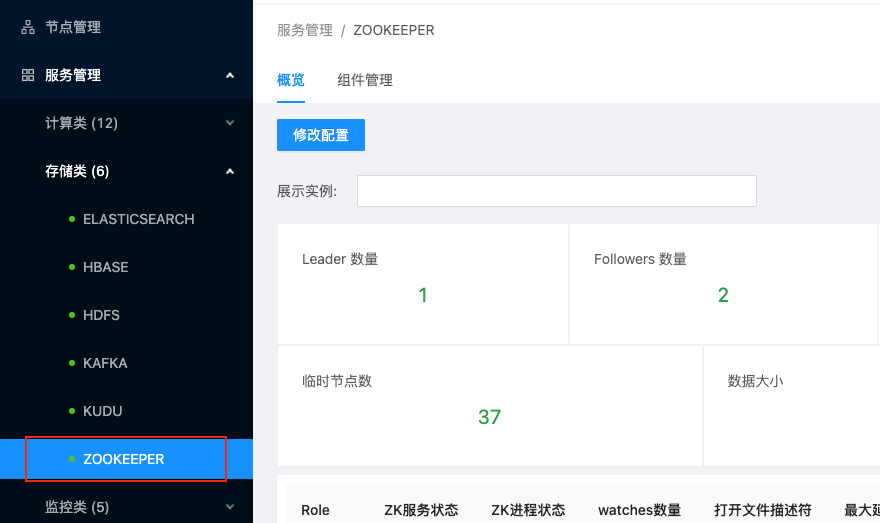
存儲類服務管理本篇目錄Zookeeper服務管理HDFS服務管理其他存儲類服務管理在USDP1.0.0.0版本中,集群存儲類服務組件主要有Elasticsearch、HBase、HDFS、Kafka、KUDU、Zookeeper在內的6個服務組件,下面將以Zookeeper及HDFS為代表展示存儲類組...
...如果build失敗,那肯定是缺少Make或者Autotools等東西,用包管理器安裝即可。 $ git clone git://github.com/OpenTSDB/opentsdb.git$ cd opentsdb$ ./build.sh 創建表OpenTSDB所需要的表結構: $ env COMPRESSION=NONE ./src/create_table.sh2016-01-08...
...rafodion集群中安裝并啟動Sqoop。更多信息,請參閱Scoop用戶指南。 安裝必需軟件 在Trafodion集群中安裝JDK 1.8 and the Oracle JDBC 驅動,僅用于將數據從RDBMS導入Hive表。請設置以下環境變量: export JAVA_HOME=/opt/java/jdk1.8.0_11 export JAVA_OPTIONS=...
...ls torchvision.transforms torchvision.utils HBase 參考指南 3.0 翻譯活動 參與方式:https://github.com/apachecn/h... 整體進度:https://github.com/apachecn/h... 項目倉庫:https://github.com/apachecn/h... ...
ChatGPT和Sora等AI大模型應用,將AI大模型和算力需求的熱度不斷帶上新的臺階。哪里可以獲得...
大模型的訓練用4090是不合適的,但推理(inference/serving)用4090不能說合適,...
圖示為GPU性能排行榜,我們可以看到所有GPU的原始相關性能圖表。同時根據訓練、推理能力由高到低做了...















