服務器平均無故障時間SEARCH AGGREGATION


回答:首先咱們需要明白這兩個的概念平均差平均差是表示各個變量值之間差異程度的數值之一。指各個變量值同平均數的的離差絕對值的算術平均數。標準差標準差是離均差平方的算術平均數的平方根,用σ表示。標準差是方差的算術平方根。標準差能反映一個數據集的離散程度。那我們為什么使用標準差而非平均差來反映離散程度呢?之前問過很多人這個問題,但一直沒有得到滿意的解答。大部分的回答集中為以下兩條:1,兩者都能反映離散程度,只...
 tracy
|
3009人閱讀
tracy
|
3009人閱讀

... 前不久,我們討論了運維不容錯過的 4個關鍵指標,其中平均解決時間(MTTR)被認為是衡量業務的最佳標準,隨后也分析了「告警等級」對MTTR的重要性。 正確看待 MTTR MTTR 為從故障發生到故障修復所經歷的時間。總故障時間是...
...包括應用是否能以足夠好的性能處理請求。對于一個大型服務器而言,重啟 MySQL 后,可能需要幾個小時才能預熱數據以保證請求的響應時間。這里的幾個小時也應該包括在宕機時間內。 到此為止,我們應該有個大致的印象,可...
...包括應用是否能以足夠好的性能處理請求。對于一個大型服務器而言,重啟 MySQL 后,可能需要幾個小時才能預熱數據以保證請求的響應時間。這里的幾個小時也應該包括在宕機時間內。 到此為止,我們應該有個大致的印象,可...
...應該是,actionable的。 告警的實質可以用下圖表明: 服務器的設計應該是以這樣的無人值守為目的的。假設所有的運維全部放假了,服務也能7*24自動運轉。 告警的實質就是把人當服務用。在一些事情還沒有辦法做到程...
...統的可用性有兩個指標:1. MTBF (Mean Time Between Failure)即平均多長時間不出故障;2. MTTR (Mean Time To Recovery)即出故障后的平均恢復時間。通過這兩個指標可以計算出可用性,也就是我們大家比較熟悉的幾個9。因此提升系統...
...獲取贊譽,而是經營一個不會出現大量突發事故的健康的服務器環境。由「平均恢復前時間」所驅動的生產運作系統管理通常會誤認為,一個迅速解決大量突發事故的團隊十分高效,而實際上這更有可能意味著該團隊的基礎設施...
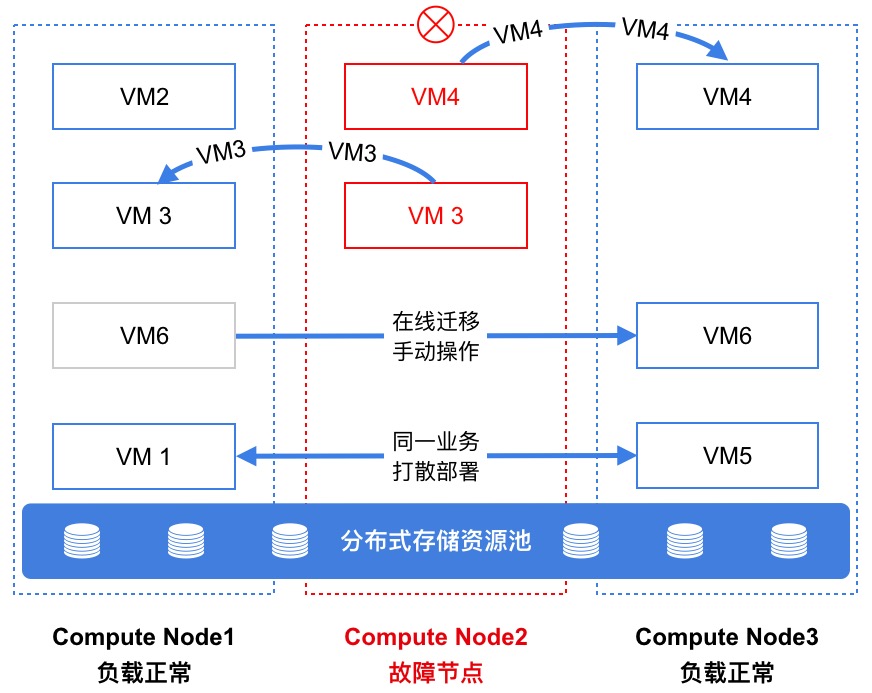
...度任務的控制和管理,用于決策虛擬機運行在哪一臺物理服務器上,同時管理虛擬機狀態及遷移計劃,保證虛擬機可用性和可靠性。智能調度系統實時監測集群所有計算節點計算、存儲、網絡等負載信息,作為虛擬機調度和管理...
調查研究表明,當數據中心停機時間的損失平均每分鐘近9,000美元時,避免這種事件是節省數據中心成本的首個也是效果最為顯著的方法。不過,以下有四種方法可以幫助組織的數據中心避免停機,并優化性能。1.調試數據中...
...以通過周報/日報進行數據的性能分析,而不是告警。 平均解決事件( MTTR ) 解決時間是衡量業務準備的最佳標準。當事件發生時,你的團隊需要多長時間才能解決? 宕機不僅會影響你的收入,還會傷害客戶用戶體驗和忠誠...
...業硬件平臺上構建其服務,而不是以前的 Sun Solaris / Sparc服務器。 雖然商業硬件的成本要低得多,但是它也經常故障。 這兩個因素從根本上改變了工程團隊如何考慮可用性,并且引導eBay創建其彈性設計模式,以建立最大化...
ChatGPT和Sora等AI大模型應用,將AI大模型和算力需求的熱度不斷帶上新的臺階。哪里可以獲得...
大模型的訓練用4090是不合適的,但推理(inference/serving)用4090不能說合適,...
圖示為GPU性能排行榜,我們可以看到所有GPU的原始相關性能圖表。同時根據訓練、推理能力由高到低做了...




 劉明
劉明 elisa.yang
elisa.yang 高勝山
高勝山 馬永翠
馬永翠 劉福
劉福















