大數據處理方法SEARCH AGGREGATION


回答:最常見的方式就是為字段設置主鍵或唯一索引,當插入重復數據時,拋出錯誤,程序終止,但這會給后續處理帶來麻煩,因此需要對插入語句做特殊處理,盡量避開或忽略異常,下面我簡單介紹一下,感興趣的朋友可以嘗試一下:這里為了方便演示,我新建了一個user測試表,主要有id,username,sex,address這4個字段,其中主鍵為id(自增),同時對username字段設置了唯一索引:01insert ig...
 cpupro
|
1614人閱讀
cpupro
|
1614人閱讀
回答:目前階段大數據技術及體系已經逐漸趨于成熟,不再是以概念貫穿的模式,大數據越來越多的被使用,伴隨互聯網化的發展更多的企業信息化已經由IT時代轉變為DT時代,以數據為核心,用數據進行決策,基于數據驅動企業的創新與發展,相信在將來大數據也會有更廣泛的應用空間,對于大數據的理解主要分為以下幾個層面。1.數據來源:對于大數據時代而言更多強調基于業務數據的沉淀,在一定規模的數據上進行進一步的分析、處理、轉換,...
 arashicage
|
1225人閱讀
arashicage
|
1225人閱讀
回答:在大數據領域大概有四個大的工作方向,除了大數據平臺應用及開發、大數據分析與應用和大數據平臺集成與運維之外,還有大數據平臺架構與研發,除了以上四個大的工作方向之外,還有一個工作方向是大數據技術推廣和培訓,這部分工作目前也有不少人在從事。大數據平臺架構與研發主要的工作內容是研發底層的大數據平臺,這部分工作的難度較高,從事這部分工作的研發級崗位也并不多。現在不少技術研發團隊都以Hadoop、Spark平...
 zhangxiangliang
|
3463人閱讀
zhangxiangliang
|
3463人閱讀
回答:近幾年,大數據的概念逐漸深入人心,大數據的趨勢越來越火爆。但是,大數據到底是個啥?怎么樣才能玩好大數據呢?大數據的基本含義就是海量數據,麥肯錫全球研究所給出的定義是:一種規模大到在獲取、存儲、管理、分析方面大大超出了傳統數據庫軟件工具能力范圍的數據集合,具有海量的數據規模、快速的數據流轉、多樣的數據類型和價值密度低四大特征。數字經濟的要素之一就是大數據資源,現在大家聊得最多的大數據是基于已經存在的...
 khlbat
|
800人閱讀
khlbat
|
800人閱讀
回答:隨著大數據應用的逐漸落地,很多人都想從事大數據方面的工作,這其中自然就有很多非大數據相關專業(數學、計算機、統計學)的從業者,那么大數據到底能不能從零基礎開始學呢?答案是肯定的,但是也要根據自身的知識結構來選擇大數據的學習方向。大數據技術體系在2016年的時候已經趨于成熟,目前正處在落地應用的階段,大數據的細分崗位比較多,自然也就需要具備不同的知識結構。大數據的崗位集中在數據采集、整理、存儲、分析...
 wuyangnju
|
866人閱讀
wuyangnju
|
866人閱讀
回答:大數據是處理海量數據的一種技術,你說的寫SQL只能處理結構化數據,更多的是非結構化數據(文本數據),和半結構化數據。并且通過SQL處理的數據量一般很少,幾個T就根本不行,大數據涉及存儲(存儲級別為PB級別),資源調度(一般是分布式系統,不是一臺機器),計算框架(hadoop;storm;spark)這三部分,缺一不可,你說的寫SQL只是相當于計算框架(勉強算得上,性能差遠了)。
 tracymac7
|
778人閱讀
tracymac7
|
778人閱讀

...總數據量早已超出 ZB(1ZB=1024EB,1EB=1024PB)級別。傳統的數據處理方法是:隨著數據量的加大,不斷更新硬件指標,采用更加強大的CPU、更大容量的磁盤這樣的措施,但現實是:數據量增大的速度遠遠超出了單機計算和存儲能力...
...自公司的方方面面,也探索了他們利用這一新生的技術與方法進行轉型時所面臨的挑戰。我們調查的領導者非常幸運的能處于數據革命的前沿位置,這場革命有望徹底改變我們做生意的方式。?四、大數據的影響1.站在未行者的...
...者之一,但是整個會議的高潮部分,還是關于深度學習的方法論,其中經驗主義和數學推理中的矛盾部分。第一條是關于深度學習,討論的是背后的數學支撐,以及未來的方向。問題包括了模型的可解釋性和醫療領域的應用。到...
...者之一,但是整個會議的高潮部分,還是關于深度學習的方法論,其中經驗主義和數學推理中的矛盾部分。第一條是關于深度學習,討論的是背后的數學支撐,以及未來的方向。問題包括了模型的可解釋性和醫療領域的應用。到...
...一歸類,可點擊前往查看各類中相關組件服務的管理操作方法:計算類服務管理存儲類服務管理監控類服務管理可視化類服務管理對上述各類服務的配置文件管理,USDP有統一的方法說明,請參考如下方法:服務配置文件管理
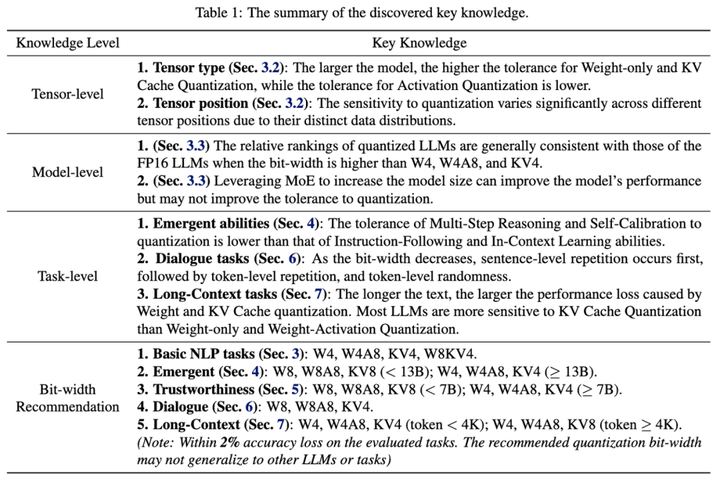
...作中評估了不同模型、量化不同張量類型、使用不同量化方法、在不同任務上的性能,本篇工作已被ICML'24接收。Qllm-Eval列舉出很多大模型落地環節應當關注的模型能力,對產業中的模型量化工作實踐,比如如何選取量化方法...
...,真實對象(Java3y)對外界來說是透明的。 2.2代理類自定義方法 程序員大V看到Java3y一直順風順水,賺大錢了。覺得是時候要加價了,于是在點贊完畢后就跟Java3y說每點完一次贊加100塊! 于是乎,程序員大V就增添了另外一個方法...
...總數據量早已超出 ZB(1ZB=1024EB,1EB=1024PB)級別。傳統的數據處理方法是:隨著數據量的加大,不斷更新硬件指標,采用更加強大的CPU、更大容量的磁盤這樣的措施,但現實是:數據量增大的速度遠遠超出了單機計算和存儲能力...
ChatGPT和Sora等AI大模型應用,將AI大模型和算力需求的熱度不斷帶上新的臺階。哪里可以獲得...
大模型的訓練用4090是不合適的,但推理(inference/serving)用4090不能說合適,...
圖示為GPU性能排行榜,我們可以看到所有GPU的原始相關性能圖表。同時根據訓練、推理能力由高到低做了...

















