資訊專欄INFORMATION COLUMN

前言
近年來,大語言模型(Large Models, LLMs)受到學術界和工業界的廣泛關注,得益于其在各種語言生成任務上的出色表現,大語言模型推動了各種人工智能應用(例如ChatGPT、Copilot等)的發展。然而,大模型的落地應用受到其較大的推理開銷的限制,對部署資源、用戶體驗、經濟成本都帶來了巨大挑戰。
大模型壓縮,即將大模型“瘦身”后塞進資源受限的場景,以減少模型存儲、訪存和計算開銷。在盡量不損失模型性能的前提下,提高大模型推理吞吐速度,使大模型在物聯網邊緣設備、嵌入式機器人、離線移動應用等邊、端場景中保持優秀的推理性能和功耗表現。
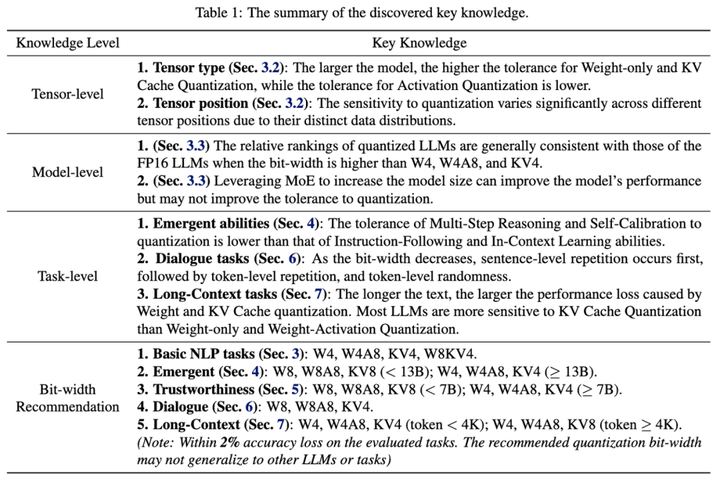
就在最近,來自清華大學電子工程系、無問芯穹和上海交通大學的研究團隊展開了一次量化方案的“大摸底”,在《Evaluating Quantized Large Language Models 》(Qllm-Eval)這項工作中評估了不同模型、量化不同張量類型、使用不同量化方法、在不同任務上的性能,本篇工作已被ICML'24接收。Qllm-Eval列舉出很多大模型落地環節應當關注的模型能力,對產業中的模型量化工作實踐,比如如何選取量化方法、針對哪些層或組件進行優化等問題具有指導意義,下圖是羅列的一些重要知識點。
訓練后量化(Post-Training Quantization,PTQ)
大模型推理過程包括兩個階段:Prefill階段和Decoding階段:
Prefill階段的主要算子為矩陣-矩陣乘(GEMM),其推理速度受限于計算速度。
Decoding階段的主要算子為矩陣-向量乘(GEMV),其推理速度主要受限于訪存速度。
當處理涉及長文本或大批量大小的任務時,KV Cache的存儲開銷會超過權重的存儲開銷。
訓練后量化(Post-Training Quantization,PTQ)是大模型壓縮的常用技術,其核心原理是將大模型的權重、激活值、KV Cache使用低精度格式表示,從而降低大模型在存儲和計算上的開銷。
在深度學習模型中,權重(weights)、激活值(activations)和鍵值緩存(KV Cache)等數值通常以32位或16位的浮點數(floats)來表示,這些浮點數可以有非常精確的數值,但同時也意味著模型會占用較大的存儲空間,并且需要比較多的計算資源來處理。
如果將浮點數從16位轉換成8位或者更低,好處是模型的大小會顯著減少,因為每個參數只需要不到50%的存儲空間,同時,使用整數進行計算通常比浮點數更快。
不同量化方式給大模型帶來的影響
但量化壓縮通常是有損的,不同量化方式的設計會對模型性能帶來不同的影響。為了探究不同量化方式對不同模型究竟會產生什么樣的影響,并幫助特定模型選擇更適合的量化方案,來自清華大學電子工程系、無問芯穹和上海交通大學的研究團隊展開了一次量化方案的“大摸底”,在《Evaluating Quantized Large Language Models 》(Qllm-Eval)這項工作中評估了不同模型、量化不同張量類型、使用不同量化方法、在不同任務上的性能。
Qllm-Eval評測的量化張量類型包括權重(W)、權重-激活(WA)、KV Cache(KV),通過評估 PTQ 對 11 個系列模型(包括 OPT、LLaMA2、Falcon、Bloomz、Mistral、ChatGLM、Vicuna、LongChat、StableLM、Gemma 和 Mamba)的權重、激活和 KV 緩存的影響,對這些因素進行了全面評估,覆蓋了從 125M 到 180B的參數范圍。另外還評估了最先進的 (SOTA) 量化方法,以驗證其適用性。同時在大量實驗的基礎上,系統總結了量化的效果,提出了應用量化技術的建議,并指出了大模型量化工作未來的發展方向。
大模型推理效率瓶頸分析
目前主流的大語言模型都是基于Transformer架構進行設計。通常來說,一個完整的模型架構由多個相同結構的Transformer塊組成,每個Transformer塊則包含多頭自注意力(Multi-Head Self-Attention, MHSA)模塊、前饋神經網絡(Feed Forward Network, FFN)和層歸一化(Layer Normalization,LN)操作。
大語言模型通常自回歸(Auto-regressive)的方式生成輸出序列,即模型逐個詞塊生成,且生成每個詞塊時需要將前序的所有詞塊(包括輸入詞塊和前面已生成的詞塊)全部作為模型的輸入。因此,隨著輸出序列的增長,推理過程的開銷顯著增大。為了解決該問題,KV緩存技術被提出,該技術通過存儲和復用前序詞塊在計算注意力機制時產生的Key和Value向量,減少大量計算上的冗余,用一定的存儲開銷換取了顯著的加速效果。基于KV緩存技術,通常可以將大語言模型的推理過程劃分為兩個階段(分別如下左圖和右圖所示):
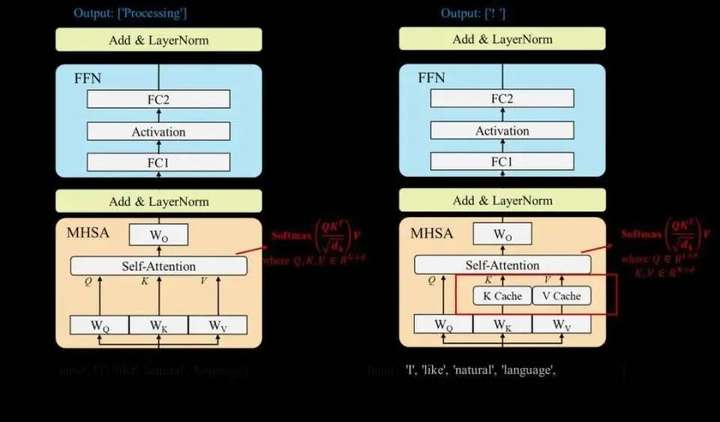
左:預填充(Prefilling)階段:大語言模型計算并存儲輸入序列中詞塊的Key和Value向量,并生成第一個輸出詞塊。
右:解碼(Decoding)階段:大語言模型利用KV緩存技術逐個生成輸出詞塊,并在每步生成后存儲新詞塊的Key和Value向量。
數據層優化技術
數據層優化技術可以劃分為兩大類:輸入壓縮(Input Compression)和輸出規劃(Output Organization)。
輸入壓縮技術
在實際利用大語言模型做回答時,通常會在輸入提示詞中加入一些輔助內容來增強模型的回答質量,例如,上下文學習技術(In-Context Learning,ICL)提出在輸入中加入多個相關的問答例子來教模型如何作答。然而,這些技術不可避免地會增長輸入詞提示的長度,導致模型推理的開銷增大。為了解決該問題,輸入壓縮技術通過直接減小輸入的長度來優化模型的推理效率。
本綜述將該類技術進一步劃分為四個小類,分別為:
提示詞剪枝(Prompt Pruning):通常根據設計好的重要度評估指標刪除輸入提示詞中不重要的詞塊、句子或文段,對被壓縮的輸入提示詞執行在線壓縮。
提示詞總結(Prompt Summary):通過對輸入提示詞做文本總結任務,在保證其語義信息相同地情況下縮短輸入的長度。該壓縮過程通常也是在線執行的。
基于軟提示詞的壓縮(Soft Prompt-based Compression):通過微調訓練的方式得到一個長度較短的軟提示詞,代替原先的輸入提示詞(在線執行)或其中固定的一部分內容(離線執行)。其中,軟提示詞指連續的、可學習的詞塊序列,可以通過訓練的方式學習得到。
檢索增強生成(Retrieval-Augmented Generation):通過檢索和輸入相關的輔助內容,并只將這些相關的內容加入到輸入提示詞中,來降低原本的輸入長度(相比于加入所有輔助內容)。
輸出規劃技術
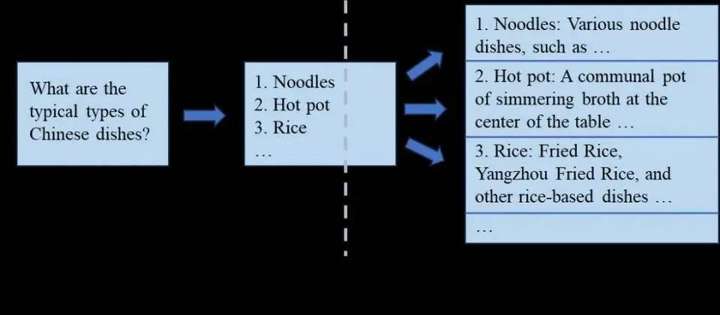
傳統的生成解碼方式是完全串行的,輸出規劃技術通過規劃輸出內容,并行生成某些部分的的輸出來降低端到端的推理延時。以該領域最早的工作“思維骨架”(Skeleton-of-Thought,以下簡稱SoT)為例,SoT技術的核心思想是讓大語言模型自行規劃輸出的并行結構,并基于該結構進行并行解碼,提升硬件利用率,減少端到端生成延時。
具體來說,如下圖所示,SoT將大語言模型的生成分為兩個階段:在提綱階段,SoT通過設計的提示詞讓大語言模型輸出答案的大綱;在分點擴展階段,SoT讓大語言模型基于大綱中的每一個分點并行做擴展,最后將所有分點擴展的答案合并起來。SoT技術讓包含LLaMA-2、Vicuna模型在內的9種主流大語言模型的生成過程加速1.9倍以上,最高可達2.39倍。在SoT技術發布后,一些研究工作通過微調大語言模型、前后端協同優化等方式優化輸出規劃技術,達到了更好的加速比和回答質量之間的權衡點。
未來方向
本文進一步總結了未來的四個關鍵應用場景,并討論了高效性研究在這些場景中的重要性:
智能體和多模型框架。在最近的研究中,大語言模型智能體和多模型協同框架受到了許多關注,這類技術可以提升大語言模型的應用能力,使得模型能更好地服務于人類。然而模型的數量增多,以及輸入到模型中的指令變長,都會使得智能體或框架系統的推理效率變低。因此需要面向這些框架和場景進行大模型的推理效率優化。
長文本場景。隨著輸入模型文本變得越來越長,大語言模型的效率優化需求變得愈發提升。目前在數據層、模型層和系統層均有相關的技術來優化長文本場景下大語言模型的推理效率,其中設計Transformer的替代新架構受到了許多關注,然而這類架構還未被充分探索,其是否能匹敵傳統的Transformer模型仍未清楚。
邊緣端部署。最近,許多研究工作開始關注于將大語言模型部署到邊緣設備上,例如移動手機。一類工作致力于設計將大模型變小,通過直接訓練小模型或模型壓縮等途徑達到該目的;另一類工作聚焦于系統層的優化,通過算子融合、內存管理等技術,直接將70億參數規模的大模型成功部署到移動手機上。
安全-效率協同優化。除了任務精度和推理效率外,大語言模型的安全性也是一個需要被考量的指標。當前的高效性研究均未考慮優化技術對模型安全性的影響。若這些優化技術對模型的安全性產生了負面影響,一個可能的研究方向就是設計新的優化方法,或改進已有的方法,使得模型的安全性和效率能一同被考量。
推薦使用NVIDIA RTX 40 顯卡做模型推理:
http://specialneedsforspecialkids.com/site/active/gpu.html?ytag=seo
https://www.compshare.cn/?ytag=seo
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/131114.html
摘要:論文可遷移性對抗樣本空間摘要對抗樣本是在正常的輸入樣本中故意添加細微的干擾,旨在測試時誤導機器學習模型。這種現象使得研究人員能夠利用對抗樣本攻擊部署的機器學習系統。 現在,卷積神經網絡(CNN)識別圖像的能力已經到了出神入化的地步,你可能知道在 ImageNet 競賽中,神經網絡對圖像識別的準確率已經超過了人。但同時,另一種奇怪的情況也在發生。拿一張計算機已經識別得比較準確的圖像,稍作調整,...
摘要:節目中,鹿班將接受設計領域的兩輪檢驗,如果鹿班的作品被現場觀眾成功找出,則認為鹿班通過檢驗。 近期,央視《機智過人》的舞臺上來了位三超設計師——設計能力超強;出圖能力超快;抗壓能力超強,成功迷惑嘉賓和現場觀眾,更讓撒貝寧出錯三連。 節目一開場,這位設計師就為現場嘉賓:主持人撒貝寧、演員韓雪、神經科學家魯白生成了三張獨具特色的海報。幾乎是說話的瞬間,海報立即生成,出圖速度之快讓撒貝寧驚呼...
摘要:調研首先要確定微博領域的數據,關于微博的數據可以這樣分類用戶基礎數據年齡性別公司郵箱地點公司等。這意味著深度學習在推薦領域應用的關鍵技術點已被解決。 當2012年Facebook在廣告領域開始應用定制化受眾(Facebook Custom Audiences)功能后,受眾發現這個概念真正得到大規模應用,什么叫受眾發現?如果你的企業已經積累了一定的客戶,無論這些客戶是否關注你或者是否跟你在Fa...

閱讀 157·2024-12-10 11:51
閱讀 303·2024-11-07 17:59
閱讀 329·2024-09-27 16:59
閱讀 466·2024-09-23 10:37
閱讀 540·2024-09-14 16:58
閱讀 335·2024-09-14 16:58
閱讀 531·2024-08-29 18:47
閱讀 812·2024-08-16 14:40