資訊專欄INFORMATION COLUMN

摘要:最近,來自浙江大學(xué)悉尼大學(xué)等高校的研究人員,提出一種新穎的全局局部注意和語義保持的文本圖像文本框架來解決這個問題,這種框架稱為。目前,論文已被接收。喬婷婷,浙江大學(xué)計算機學(xué)院博士研究生,目前在悉尼大學(xué)陶大程教授研究小組工作。
GAN又開辟了新疆界。
去年英偉達的StyleGAN在生成高質(zhì)量和視覺逼真的圖像,騙過了無數(shù)雙眼睛,隨后一大批假臉、假貓、假房源隨之興起,可見GAN的威力。

StyleGAN生成假臉
雖然GAN在圖像方面已經(jīng)取得了重大進展,但是保證文本描述和視覺內(nèi)容之間的語義一致性上仍然是非常具有挑戰(zhàn)性的。
最近,來自浙江大學(xué)、悉尼大學(xué)等高校的研究人員,提出一種新穎的全局-局部注意和語義保持的文本-圖像-文本(text-to-image-to-text)框架來解決這個問題,這種框架稱為MirrorGAN。

MirrorGAN有多強?
在目前較為主流的數(shù)據(jù)集COCO數(shù)據(jù)集和CUB鳥類數(shù)據(jù)集上,MirrorGAN都取得了較好成績。
目前,論文已被CVPR2019接收。
MirrorGAN:解決文本和視覺之間語義一致性
文本生成圖像(T2I)在許多應(yīng)用領(lǐng)域具有巨大的潛力,已經(jīng)成為自然語言處理和計算機視覺領(lǐng)域的一個活躍的研究領(lǐng)域。
與基本圖像生成問題相反,T2I生成以文本描述為條件,而不是僅從噪聲開始。利用GAN的強大功能,業(yè)界已經(jīng)提出了不同的T2I方法來生成視覺上逼真的和文本相關(guān)的圖像。這些方法都利用鑒別器來區(qū)分生成的圖像和相應(yīng)的文本對以及ground-truth圖像和相應(yīng)的文本對。
然而,由于文本和圖像之間的區(qū)域差異,當(dāng)僅依賴于這樣的鑒別器時,對每對內(nèi)的基礎(chǔ)語義一致性進行建模是困難且低效的。
近年來,針對這一問題,人們利用注意機制來引導(dǎo)生成器在生成不同的圖像區(qū)域時關(guān)注不同的單詞。然而,由于文本和圖像模式的多樣性,僅使用單詞級的注意并不能確保全局語義的一致性。如圖1(b)所示:
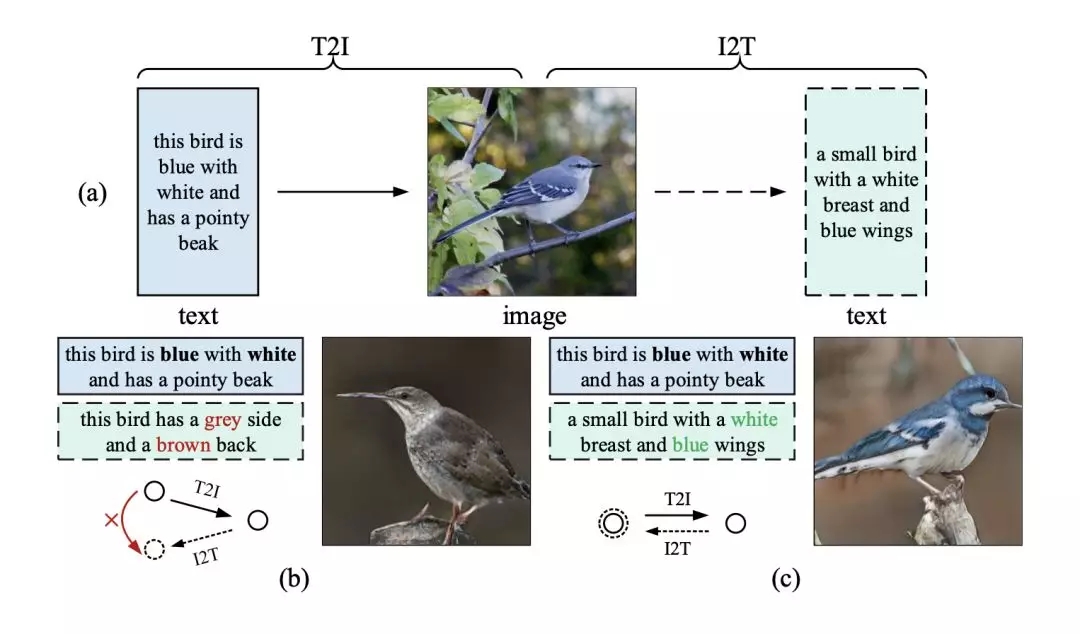
圖1 ?(a)鏡像結(jié)構(gòu)的說明,體現(xiàn)了通過重新描述學(xué)習(xí)文本到圖像生成的思想;(b)-(c)前人的研究成果與本文提出的MirrorGAN分別生成的語義不一致和一致的圖像/重新描述。
T2I生成可以看作是圖像標題(或圖像到文本生成,I2T)的逆問題,它生成給定圖像的文本描述。考慮到處理每個任務(wù)都需要對這兩個領(lǐng)域的底層語義進行建模和對齊,因此在統(tǒng)一的框架中對這兩個任務(wù)進行建模以利用底層的雙重規(guī)則是自然和合理的。
如圖1 (a)和(c)所示,如果T2I生成的圖像在語義上與給定的文本描述一致,則I2T對其重新描述應(yīng)該與給定的文本描述具有完全相同的語義。換句話說,生成的圖像應(yīng)該像一面鏡子,準確地反映底層文本語義。
基于這一觀察結(jié)果,論文提出了一個新的文本-圖像-文本的框架——MirrorGAN來改進T2I生成,它利用了通過重新描述學(xué)習(xí)T2I生成的思想。
解剖MirrorGAN三大核心模塊
對于T2I這一任務(wù)來說,主要的目標有兩個:
視覺真實性;
語義
且二者需要保持一致性。
MirrorGAN利用了“文本到圖像的重新描述學(xué)習(xí)生成”的思想,主要由三個模塊組成:
語義文本嵌入模塊(STEM);
級聯(lián)圖像生成的全局-局部協(xié)同關(guān)注模塊(GLAM);
語義文本再生與對齊模塊(STREAM)。
STEM生成單詞級和句子級的嵌入;GLAM有一個級聯(lián)的架構(gòu),用于從粗尺度到細尺度生成目標圖像,利用局部詞注意和全局句子注意,逐步增強生成圖像的多樣性和語義一致性;STREAM試圖從生成的圖像中重新生成文本描述,該圖像在語義上與給定的文本描述保持一致。
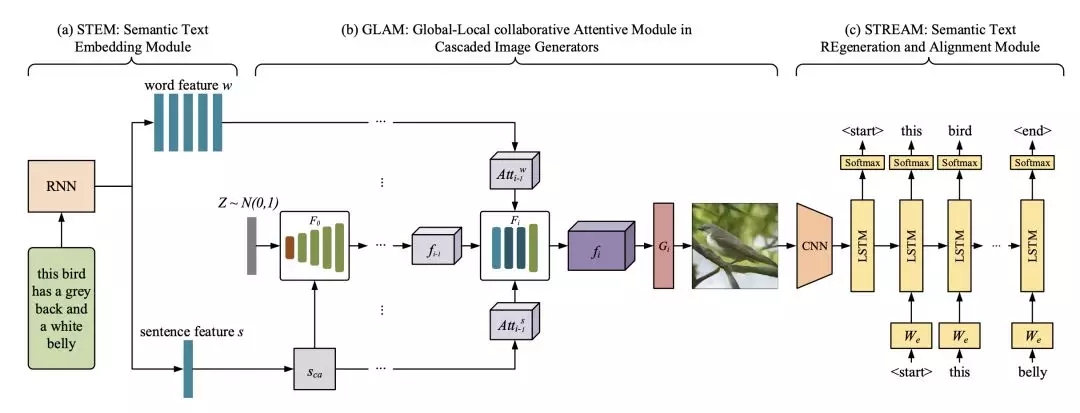
圖2 ?MirrorGAN原理圖
如圖2所示,MirrorGAN通過集成T2I和I2T來體現(xiàn)鏡像結(jié)構(gòu)。
它利用了通過重新描述來學(xué)習(xí)T2I生成的想法。 生成圖像后,MirrorGAN會重新生成其描述,該描述將其基礎(chǔ)語義與給定的文本描述對齊。
以下是MirrorGAN三個模塊組成:STEM,GLAM和STREAM。
STEM:語義文本嵌入模塊
首先,引入語義文本嵌入模塊,將給定的文本描述嵌入到局部詞級特征和全局句級特征中。
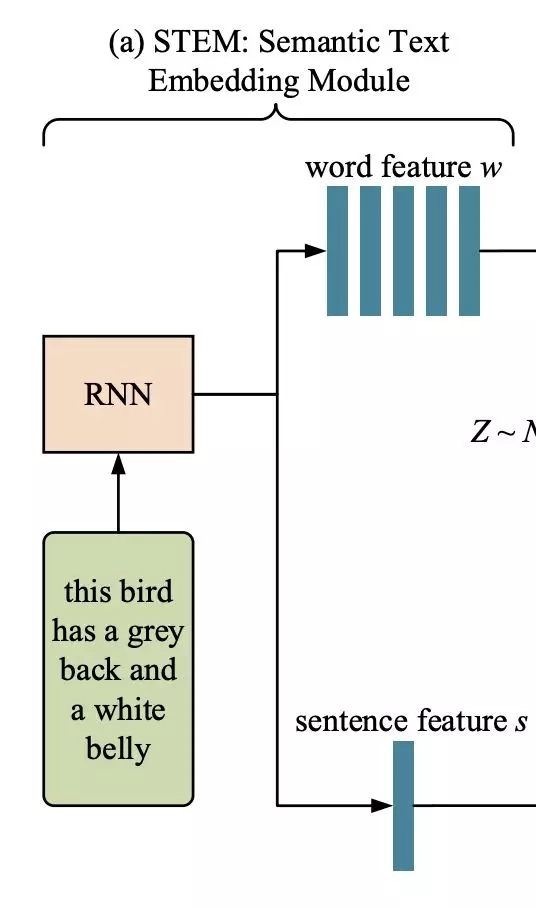
如圖2最左邊所示(即上圖),使用一個遞歸神經(jīng)網(wǎng)絡(luò)(RNN)從給定的文本描述中提取語義嵌入T,包括一個嵌入w的單詞和一個嵌入s的句子。

GLAM:級聯(lián)圖像生成的全局-局部協(xié)同關(guān)注模塊
接下來,通過連續(xù)疊加三個圖像生成網(wǎng)絡(luò),構(gòu)造了一個多級級聯(lián)發(fā)生器。
本文采用了《Attngan: Fine-grained text to image generation with attentional generative adversarial networks》中描述的基本結(jié)構(gòu),因為它在生成逼真的圖像方面有很好的性能。
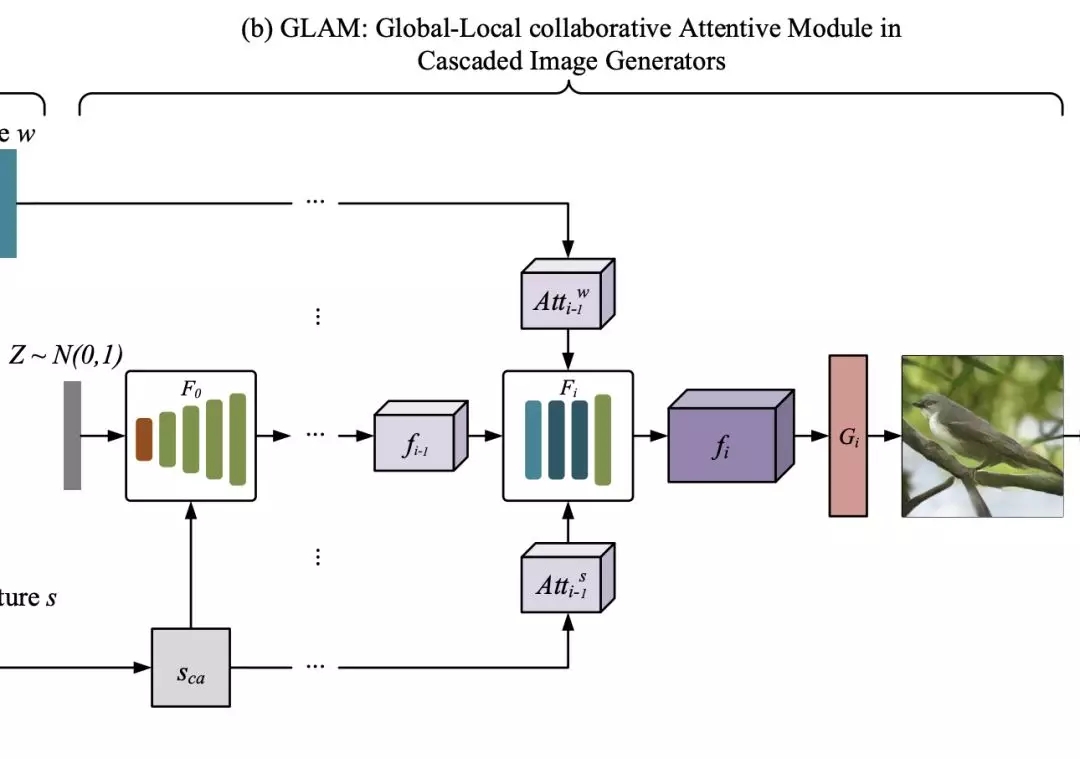
使用{F0,F(xiàn)1,…,F(xiàn)m-1}來表示m個視覺特征變換器,并使用{G0,G1,…,Gm-1}來表示m個圖像生成器。 每個階段中的視覺特征Fi和生成的圖像Ii可以表示為:
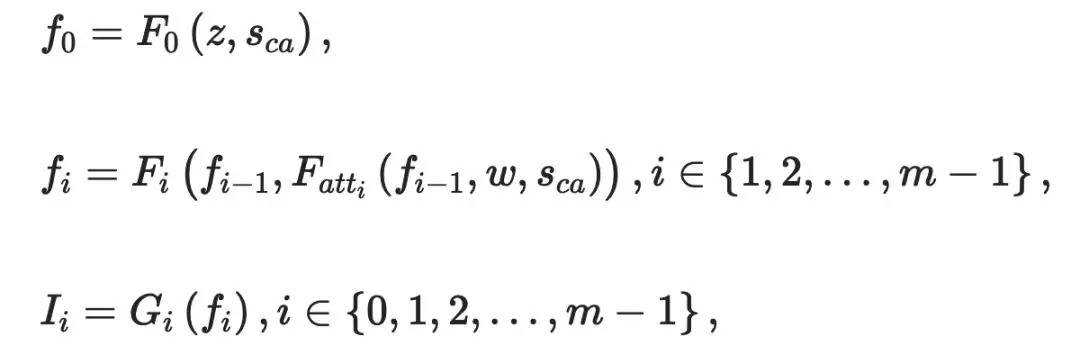
STREAM:語義文本再生與對齊模塊
如上所述,MirrorGAN包括語義文本再生和對齊模塊(STREAM),以從生成的圖像重新生成文本描述,其在語義上與給定的文本描述對齊。
具體來說,采用了廣泛使用的基于編碼器解碼器的圖像標題框架作為基本的STREAM架構(gòu)。
圖像編碼器是在ImageNet上預(yù)先訓(xùn)練的卷積神經(jīng)網(wǎng)絡(luò)(CNN),解碼器是RNN。由末級生成器生成的圖像Im-1輸入CNN編碼器和RNN解碼器如下:
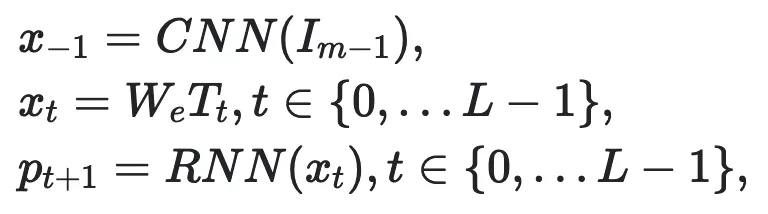
實驗結(jié)果:COCO數(shù)據(jù)集上成績較佳
那么,MirrorGAN的性能有多強呢?
首先來看一下MirrorGAN與其它較先進的T2I方法的比較,包括GAN-INT-CLS、GAWWN、StackGAN、StackGAN ++ 、PPGN和AttnGAN。
所采用的數(shù)據(jù)集是目前較為主流的數(shù)據(jù)集,分別是COCO數(shù)據(jù)集和CUB鳥類數(shù)據(jù)集:
CUB鳥類數(shù)據(jù)集包含8,855個訓(xùn)練圖像和2,933個屬于200個類別的測試圖像,每個鳥類圖像有10個文本描述;
OCO數(shù)據(jù)集包含82,783個訓(xùn)練圖像和40,504個驗證圖像,每個圖像有5個文本描述。?
結(jié)果如表1所示:

表1 ?在CUB和COCO數(shù)據(jù)集上,MirrorGAN和其它先進方法的結(jié)果比較
表2展示了AttnGAN和MirrorGAN在CUB和COCO數(shù)據(jù)集上的R精度得分。
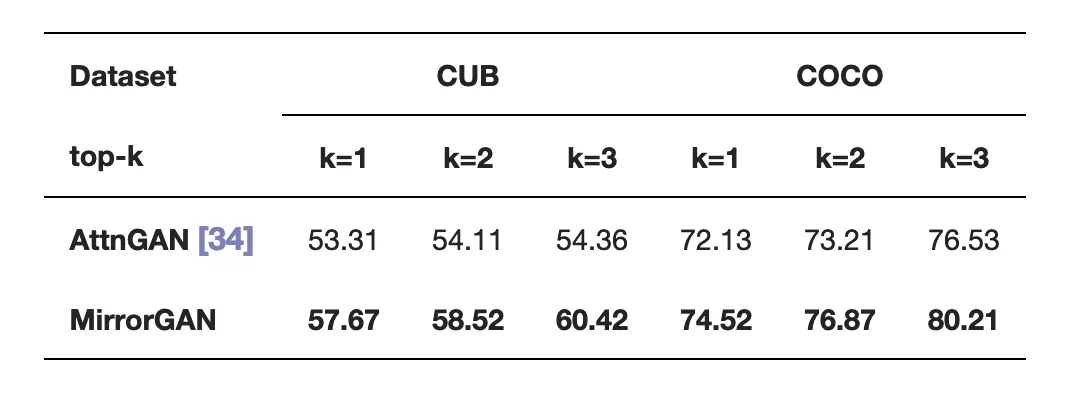
表2 ?在CUB和COCO數(shù)據(jù)集上,MirrorGAN和AttnGAN的R精度得分。
在所有實驗比較中,MirrorGAN都表現(xiàn)出了更大的優(yōu)勢,這表明了本文提出的文本到圖像到文本的框架和全局到本地的協(xié)作關(guān)注模塊的優(yōu)越性,因為MirrorGAN生成的高質(zhì)量圖像具有與輸入文本描述一致的語義。
作者介紹
最后再介紹一下論文的四位作者。
Tingting Qiao(喬婷婷),浙江大學(xué)計算機學(xué)院博士研究生,目前在悉尼大學(xué)陶大程教授研究小組工作。
喬婷婷(圖據(jù)LinkedIn)
Jing Zhang,博士,杭州電子科技大學(xué)講師,悉尼大學(xué)訪問學(xué)者。

Jing Zhang
許端清,浙江大學(xué)計算機與技術(shù)學(xué)院教授、博士生導(dǎo)師。

許端清
陶大程,悉尼大學(xué)工程及信息技術(shù)學(xué)院教授,優(yōu)必選悉尼大學(xué)AI中心主任。

陶大程
目前,喬婷婷和Jing Zhang都在參與陶大程教授的工作。
值得注意的是,許端清教授曾承擔(dān)國家社科基金重大項目(子課題)“敦煌遺書數(shù)據(jù)庫關(guān)鍵技術(shù)研究及軟件系統(tǒng)開發(fā)”, 建立敦煌藏文基本信息庫系統(tǒng),喬婷婷也是當(dāng)時的參與者之一。
兩年之后的2017年,“石窟寺文物數(shù)字化保護國家文物局重點科研基地”在浙大揭牌,聚焦“石窟寺文物數(shù)字化保護“。這篇MirrorGAN的論文,在文本和圖像的轉(zhuǎn)換中加入了對語義的研究,使得這項任務(wù)的精度再次提高。
AI技術(shù)在文物數(shù)字化相關(guān)工作中,讓古老的文字再添新生的活力,我們離歷史更近,離文化更近。
論文地址:
https://arxiv.org/abs/1903.05854
聲明:本文版權(quán)歸原作者所有,文章收集于網(wǎng)絡(luò),為傳播信息而發(fā),如有侵權(quán),請聯(lián)系小編及時處理,謝謝!
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4873.html
摘要:最后,我們顯示了若干張圖像中所生成的趣味字幕。圖所提出的有趣字幕生成的體系結(jié)構(gòu)。我們將所提出的方法稱為神經(jīng)玩笑機器,它是與預(yù)訓(xùn)練模型相結(jié)合的。用戶對已發(fā)布的字幕的趣味性進行評估,并為字幕指定一至三顆星。 可以毫不夸張地說,笑是一種特殊的高階功能,且只有人類才擁有。那么,是什么引起人類的笑聲表達呢?最近,日本東京電機大學(xué)(Tokyo Denki University)和日本國家先進工業(yè)科學(xué)和技...
摘要:何愷明和兩位大神最近提出非局部操作為解決視頻處理中時空域的長距離依賴打開了新的方向。何愷明等人提出新的非局部通用網(wǎng)絡(luò)結(jié)構(gòu),超越。殘差連接是何愷明在他的年較佳論文中提出的。 Facebook何愷明和RGB兩位大神最近提出非局部操作non-local operations為解決視頻處理中時空域的長距離依賴打開了新的方向。文章采用圖像去噪中常用的非局部平均的思想處理局部特征與全圖特征點的關(guān)系。這種...
摘要:表示類別為,坐標是的預(yù)測熱點圖,表示相應(yīng)位置的,論文提出變體表示檢測目標的損失函數(shù)由于下采樣,模型生成的熱點圖相比輸入圖像分辨率低。模型訓(xùn)練損失函數(shù)使同一目標的頂點進行分組,損失函數(shù)用于分離不同目標的頂點。 本文由極市博客原創(chuàng),作者陳泰紅。 1.目標檢測算法概述 CornerNet(https://arxiv.org/abs/1808.01244)是密歇根大學(xué)Hei Law等人在發(fā)表E...
摘要:在本文中,快捷連接是為了實現(xiàn)恒等映射,它的輸出與一組堆疊層的輸出相加見圖。實驗表明見圖,學(xué)習(xí)得到的殘差函數(shù)通常都是很小的響應(yīng)值,表明將恒等映射作為先決條件是合理的。 ResNet Deep Residual Learning for Image RecognitionKaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun Caffe實現(xiàn):ht...
摘要:機器學(xué)習(xí)和深度學(xué)習(xí)的研究進展正深刻變革著人類的技術(shù),本文列出了自年以來這兩個領(lǐng)域發(fā)表的最重要被引用次數(shù)最多的篇科學(xué)論文,以饗讀者。注意第篇論文去年才發(fā)表要了解機器學(xué)習(xí)和深度學(xué)習(xí)的進展,這些論文一定不能錯過。 機器學(xué)習(xí)和深度學(xué)習(xí)的研究進展正深刻變革著人類的技術(shù),本文列出了自 2014 年以來這兩個領(lǐng)域發(fā)表的最重要(被引用次數(shù)最多)的 20 篇科學(xué)論文,以饗讀者。機器學(xué)習(xí),尤其是其子領(lǐng)域深度學(xué)習(xí)...

閱讀 2947·2023-04-25 22:16
閱讀 2093·2021-10-11 11:11
閱讀 3247·2019-08-29 13:26
閱讀 593·2019-08-29 12:32
閱讀 3409·2019-08-26 11:49
閱讀 2987·2019-08-26 10:30
閱讀 1939·2019-08-23 17:59
閱讀 1507·2019-08-23 17:57






