資訊專欄INFORMATION COLUMN

摘要:本文介紹了如何利用上的免費資源更快地訓練模型。本文將介紹如何在上使用訓練已有的模型,其訓練速度是在上訓練速度的倍。使用靜態訓練模型,并將權重保存到文件。使用推理模型進行預測。
本文介紹了如何利用 Google Colab 上的免費 Cloud TPU 資源更快地訓練 Keras 模型。

很長一段時間以來,我在單個 GTX 1070 顯卡上訓練模型,其單精度大約為 8.18 TFlops。后來谷歌在 Colab 上啟用了免費的 Tesla K80 GPU,配備 12GB 內存,且速度稍有增加,為 8.73 TFlops。最近,Colab 的運行時類型選擇器中出現了 Cloud TPU 選項,其浮點計算能力為 180 TFlops。
本文將介紹如何在 Colab 上使用 TPU 訓練已有的 Keras 模型,其訓練速度是在 GTX 1070 上訓練速度的 20 倍。
我們首先構建一個易于理解但訓練過程比較復雜的 Keras 模型,以便「預熱」Cloud TPU。在 IMDB 情感分類任務上訓練 LSTM 模型是個不錯的選擇,因為 LSTM 的計算成本比密集和卷積等層高。
流程如下所示:
構建一個 Keras 模型,可使靜態輸入 batch_size 在函數式 API 中進行訓練。
將 Keras 模型轉換為 TPU 模型。
使用靜態 batch_size * 8 訓練 TPU 模型,并將權重保存到文件。
構建結構相同但輸入批大小可變的 Keras 模型,用于執行推理。
加載模型權重。
使用推理模型進行預測。
讀者閱讀本文時,可以使用 Colab Jupyter notebook Keras_LSTM_TPU.ipynb(https://colab.research.google.com/drive/1QZf1WeX3EQqBLeFeT4utFKBqq-ogG1FN)進行試驗。
首先,按照下圖的說明在 Colab 運行時選項中選擇激活 TPU。
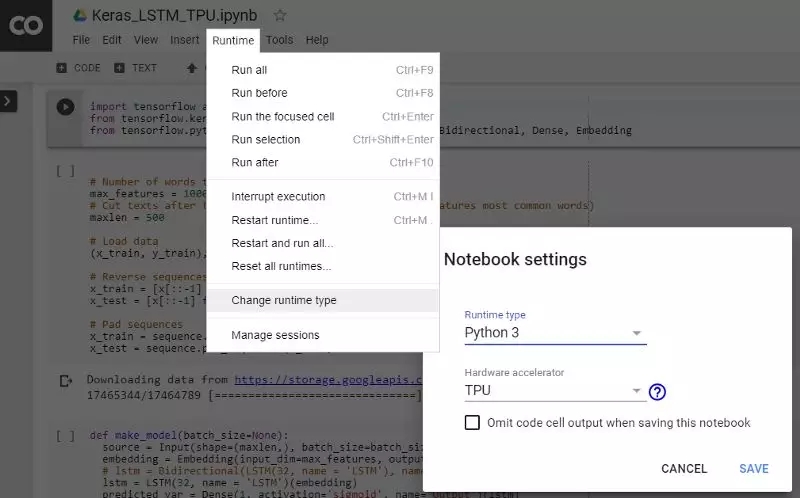
激活 TPU
靜態輸入 Batch Size
在 CPU 和 GPU 上運行的輸入管道大多沒有靜態形狀的要求,而在 XLA/TPU 環境中,則對靜態形狀和 batch size 有要求。
Could TPU 包含 8 個可作為獨立處理單元運行的 TPU 核心。只有八個核心全部工作,TPU 才算被充分利用。為通過向量化充分提高訓練速度,我們可以選擇比在單個 GPU 上訓練相同模型時更大的 batch size。最開始較好設定總 batch size 為 1024(每個核心 128 個)。
如果你要訓練的 batch size 過大,可以慢慢減小 batch size,直到它適合 TPU 內存,只需確保總的 batch size 為 64 的倍數即可(每個核心的 batch size 大小應為 8 的倍數)。
使用較大的 batch size 進行訓練也同樣有價值:通常可以穩定地提高優化器的學習率,以實現更快的收斂。(參考論文:https://arxiv.org/pdf/1706.02677.pdf)
在 Keras 中,要定義靜態 batch size,我們需使用其函數式 API,然后為 Input 層指定 batch_size 參數。請注意,模型在一個帶有 batch_size 參數的函數中構建,這樣方便我們再回來為 CPU 或 GPU 上的推理運行創建另一個模型,該模型采用可變的輸入 batch size。
import tensorflow as tf
from tensorflow.python.keras.layers import Input, LSTM, Bidirectional, Dense, Embedding
def make_model(batch_size=None):
? ? source = Input(shape=(maxlen,), batch_size=batch_size,
? ? ? ? ? ? ? ? ? ?dtype=tf.int32, name="Input")
? ? embedding = Embedding(input_dim=max_features,
? ? ? ? ? ? ? ? ? ? ? ? ? output_dim=128, name="Embedding")(source)
? ? lstm = LSTM(32, name="LSTM")(embedding)
? ? predicted_var = Dense(1, activation="sigmoid", name="Output")(lstm)
? ? model = tf.keras.Model(inputs=[source], outputs=[predicted_var])
? ? model.compile(
? ? ? ? optimizer=tf.train.RMSPropOptimizer(learning_rate=0.01),
? ? ? ? loss="binary_crossentropy",
? ? ? ? metrics=["acc"])
? ? return model
training_model = make_model(batch_size=128)
此外,使用 tf.train.Optimizer,而不是標準的 Keras 優化器,因為 Keras 優化器對 TPU 而言還處于試驗階段。
將 Keras 模型轉換為 TPU 模型
tf.contrib.tpu.keras_to_tpu_model 函數將 tf.keras 模型轉換為同等的 TPU 模型。
import os
import tensorflow as tf
# This address identifies the TPU we"ll use when configuring TensorFlow.
TPU_WORKER = "grpc://" + os.environ["COLAB_TPU_ADDR"]
tf.logging.set_verbosity(tf.logging.INFO)
tpu_model = tf.contrib.tpu.keras_to_tpu_model(
? ? training_model,
? ? strategy=tf.contrib.tpu.TPUDistributionStrategy(
? ? ? ? tf.contrib.cluster_resolver.TPUClusterResolver(TPU_WORKER)))
然后使用標準的 Keras 方法來訓練、保存權重并評估模型。請注意,batch_size 設置為模型輸入 batch_size 的八倍,這是為了使輸入樣本在 8 個 TPU 核心上均勻分布并運行。
history = tpu_model.fit(x_train, y_train,
? ? ? ? ? ? ? ? ? ? ? ? epochs=20,
? ? ? ? ? ? ? ? ? ? ? ? batch_size=128 * 8,
? ? ? ? ? ? ? ? ? ? ? ? validation_split=0.2)
tpu_model.save_weights("./tpu_model.h5", overwrite=True)
tpu_model.evaluate(x_test, y_test, batch_size=128 * 8)
我設置了一個實驗,比較在 Windows PC 上使用單個 GTX1070 和在 Colab 上運行 TPU 的訓練速度,結果如下。
GPU 和 TPU 都將輸入 batch size 設為 128,
GPU:每個 epoch 需要 179 秒。20 個 epoch 后驗證準確率達到 76.9%,總計 3600 秒。
TPU:每個 epoch 需要 5 秒,第一個 epoch 除外(需 49 秒)。20 個 epoch 后驗證準確率達到 95.2%,總計 150 秒。
20 個 epoch 后,TPU 上訓練模型的驗證準確率高于 GPU,這可能是由于在 GPU 上一次訓練 8 個 batch,每個 batch 都有 128 個樣本。
在 CPU 上執行推理
一旦我們獲得模型權重,就可以像往常一樣加載它,并在 CPU 或 GPU 等其他設備上執行預測。我們還希望推理模型接受靈活的輸入 batch size,這可以使用之前的 make_model() 函數來實現。
inferencing_model = make_model(batch_size=None)
inferencing_model.load_weights("./tpu_model.h5")
inferencing_model.summary()
可以看到推理模型現在采用了可變的輸入樣本。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
Input (InputLayer) (None, 500) 0
_________________________________________________________________
Embedding (Embedding) (None, 500, 128) 1280000
_________________________________________________________________
LSTM (LSTM) (None, 32) 20608
_________________________________________________________________
Output (Dense) (None, 1) 33
=================================================================
然后,你可以使用標準 fit()、evaluate() 函數與推理模型。
結論
本快速教程介紹了如何利用 Google Colab 上的免費 Cloud TPU 資源更快地訓練 Keras 模型。
原文鏈接:https://www.kdnuggets.com/2019/03/train-keras-model-20x-faster-tpu-free.html
聲明:本文版權歸原作者所有,文章收集于網絡,為傳播信息而發,如有侵權,請聯系小編及時處理,謝謝!商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4868.html

當涉及到大規模的機器學習任務時,加速處理速度是至關重要的。Tensor Processing Units(TPUs)是一種專門為機器學習任務設計的硬件加速器,可以在訓練和推斷階段顯著提高TensorFlow模型的性能。 在本文中,我們將討論如何使用TPUs加速TensorFlow模型的訓練過程。首先,我們將簡要介紹TPUs的工作原理,然后探討如何在TensorFlow中使用TPUs進行訓練。 ...
摘要:首先,我們一起來開一個腦洞想象一個最理想的深度學習引擎應該是什么樣子的,或者說深度學習引擎的終極形態是什么看看這會給深度學習框架和專用芯片研發帶來什么啟發。眾所周知,現在是深度學習領域應用最廣的計算設備,據說比更加強大,不過目前只有可以用。 首先,我們一起來開一個腦洞:想象一個最理想的深度學習引擎應該是什么樣子的,或者說深度學習引擎的終極形態是什么?看看這會給深度學習框架和AI專用芯片研發帶...

閱讀 1061·2023-04-26 02:02
閱讀 2401·2021-09-26 10:11
閱讀 3553·2019-08-30 13:10
閱讀 3743·2019-08-29 17:12
閱讀 719·2019-08-29 14:20
閱讀 2187·2019-08-28 18:19
閱讀 2229·2019-08-26 13:52
閱讀 954·2019-08-26 13:43



