資訊專欄INFORMATION COLUMN

摘要:首先,我們一起來開一個腦洞想象一個最理想的深度學習引擎應該是什么樣子的,或者說深度學習引擎的終極形態是什么看看這會給深度學習框架和專用芯片研發帶來什么啟發。眾所周知,現在是深度學習領域應用最廣的計算設備,據說比更加強大,不過目前只有可以用。
首先,我們一起來開一個腦洞:想象一個最理想的深度學習引擎應該是什么樣子的,或者說深度學習引擎的終極形態是什么?看看這會給深度學習框架和AI專用芯片研發帶來什么啟發。
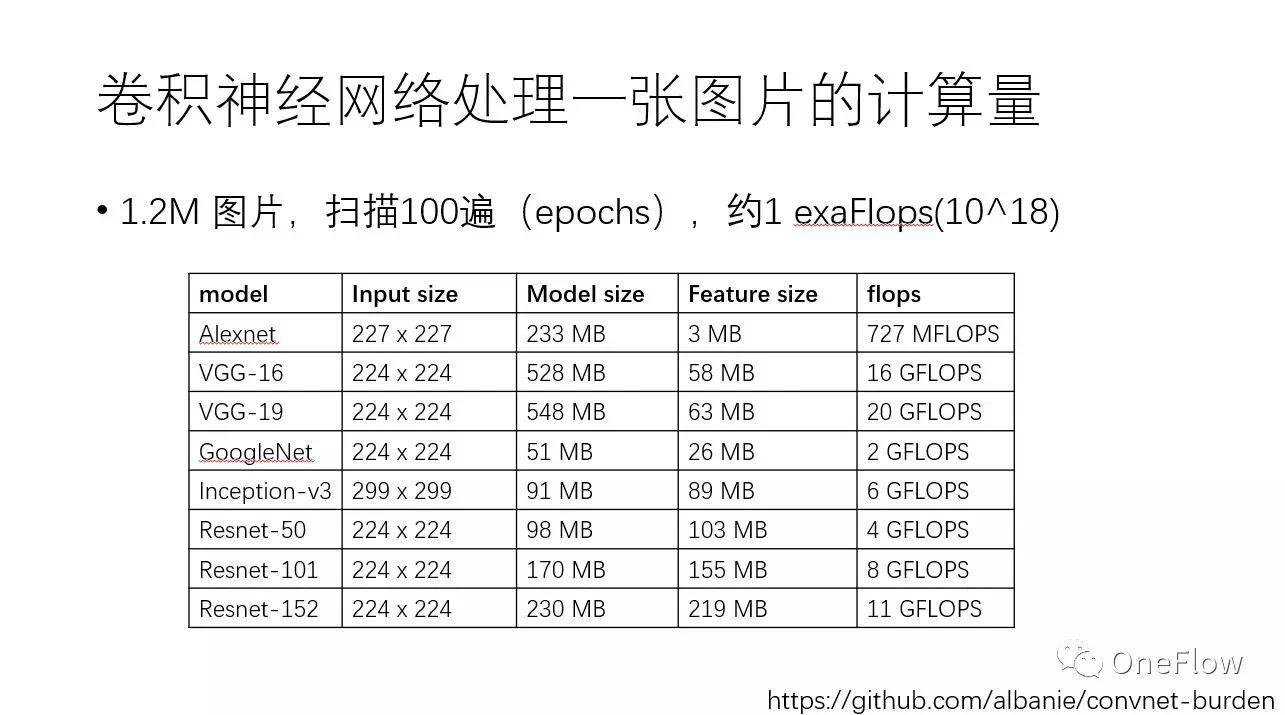
以大家耳熟能詳的卷積神經網絡CNN 為例,可以感覺一下目前訓練深度學習模型需要多少計算力。下方這張表列出了常見CNN模型處理一張圖片需要的內存容量和浮點計算次數,譬如VGG-16網絡處理一張圖片就需要16Gflops。值得注意的是,基于ImageNet數據集訓練CNN,數據集一共大約120萬張圖片,訓練算法需要對這個數據集掃描100遍(epoch),這意味著10^18次浮點計算,即1exaFlops。簡單演算一下可發現,基于一個主頻為2.0GHz的CPU core來訓練這樣的模型需要好幾年的時間。
下圖列了幾種最常使用的計算設備——CPU、 GPU、 TPU等。眾所周知,現在GPU是深度學習領域應用最廣的計算設備,TPU 據說比GPU 更加強大,不過目前只有Google 可以用。我們可以討論下為什么CPU < GPU < TPU,以及存不存在比TPU更加強大的硬件設備。 主頻為2GHz的單核CPU 只能串行執行指令,1秒可以執行數千萬到數億次操作。隨著摩爾定律終結,人們通過在一個CPU上集成更多的核心來提高計算力,譬如一個CPU上集成20個計算核心(所謂多核,muti-core)可以把CPU計算能力提高幾十倍。GPU 比多核更進一步,采用眾核(many-core),在一個芯片上集成數千計算核心(core),盡管每個核心的主頻要比CPU核心主頻低(通常不到1GHz),并行度還是提升了百倍,而且訪存帶寬要比CPU高10倍以上,因此做稠密計算的吞吐率可以達到CPU的10倍乃至100倍。GPU 被詬病的一點是功耗太高,為解決這個問題,TPU 這樣的專用AI芯片橫空出世,專用芯片可以在相同的面積里集成更多深度學習需要的運算單元,甚至用專用電路實現某些特定運算使得完成同樣計算需要的時間更短 。有比TPU更快的專用芯片嗎? 肯定有,極端情況下,任給一個神經網絡,都不計成本去專門實現一款芯片,一定比TPU這種用來支持最廣泛神經網絡類型的芯片要效率高得多。

專用硬件比通用硬件(如CPU、GPU)快,有多種原因,主要包括:(1)通用芯片一般經歷“取指-譯碼-執行”(甚至包括“取數據”)的步驟才能完成一次運算,專用硬件大大減小了“取指-譯碼”等開銷,數據到達即執行;(2)專用硬件控制電路復雜度低,可以在相同的面積下集成更多對運算有用的器件,可以在一個時鐘周期內完成通用硬件需要數千上萬個時鐘周期才能完成的操作;(3)專用硬件和通用硬件內都支持流水線并行,硬件利用率高;(4)專用硬件片內帶寬高,大部分數據在片內傳輸。顯然,如果不考慮物理現實,不管什么神經網絡,不管問題的規模有多大,都實現一套專用硬件是效率較高的做法。問題是,這行得通嗎?
如果對任何一個神經網絡都實現一套專用硬件,運行效率較高,可是開發效率不高,需求一變更(神經網絡拓撲結構,層數,神經元個數),就需要重新設計電路,而硬件研發周期臭名昭著的長。這讓人聯想起馮諾依曼發明“存儲程序”計算機之前的電子計算機(下圖即第一臺電子計算機ENIAC 的照片),計算機的功能通過硬連線(hard-wired)電路實現,要改變計算機的功能就需要重新組織器件間的連線,這種“編程”方式又慢又難以調試。

剛才設想的無限大的專用硬件顯然面臨幾個現實問題:(1)芯片不可能無限大,必須考慮硬件制造工藝的限制(散熱,時鐘信號傳播范圍等);(2)硬連線的電路靈活性太差,改變功能需要重新連線;(3)改變連線后,流水線調度機制可能要做相應調整,才能較大化硬件利用率。因此,我們設想的“不計成本的”,“無限大的”專用硬件面臨了嚴峻挑戰,如何克服呢?
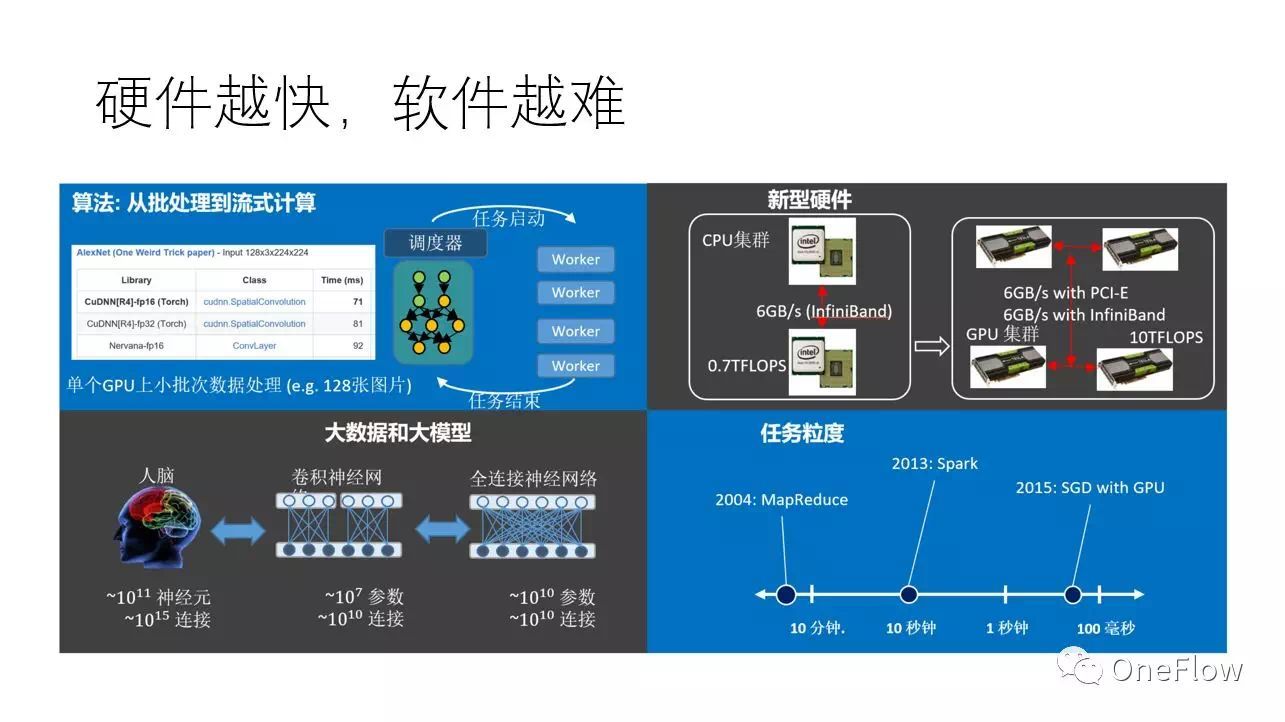
現實中,不管是通用硬件(如GPU)還是專用硬件(如TPU) 都可以通過高速互聯技術連接在一起,通過軟件協調多個設備來完成大規模計算。使用較先進的互聯技術,設備和設備之間傳輸帶寬可以達到100Gbps或者更多,這比設備內部帶寬低上一兩個數量級,不過幸好,如果軟件“調配得當”,在這個帶寬條件下也可能使得硬件計算飽和。當然,“調配得當”技術挑戰極大,事實上,單個設備速度越快,越難把多個設備“調配得當”。

當前深度學習普遍采用隨機梯度下降算法(SGD),一般一個GPU處理一小塊兒數據只需要100毫秒的時間,那么問題的關鍵就成了,“調配”算法能否在100毫秒的時間內為GPU處理下一塊數據做好準備,如果可以的話,那么GPU就會一直保持在運算狀態,如果不可以,那么GPU就要間歇性的停頓,意味著設備利用率降低。理論上是可以的,有個叫運算強度(Arithmetic intensity)的概念,即flops per byte,表示一個字節的數據上發生的運算量,只要這個運算量足夠大,意味著傳輸一個字節可以消耗足夠多的計算量,那么即使設備間傳輸帶寬低于設備內部帶寬,也有可能使得設備處于滿負荷狀態。進一步,如果采用比GPU更快的設備,那么處理一塊兒數據的時間就比100毫秒更低,譬如10毫秒,在給定的帶寬條件下,“調配”算法能用10毫秒的時間為下一次計算做好準備嗎?事實上,即使是使用不那么快(相對于TPU 等專用芯片)的GPU,當前主流的深度學習框架在某些場景(譬如模型并行)已經力不從心了。
一個通用的深度學習軟件框架要能對任何給定的神經網絡和可用資源都能較高效的“調配”硬件,這需要解決三個核心問題:(1)資源分配,包括計算核心,內存,傳輸帶寬三種資源的分配,需要綜合考慮局部性和負載均衡的問題;(2)生成正確的數據路由(相當于前文想象的專用硬件之間的連線問題);(3)高效的運行機制,完美協調數據搬運和計算,硬件利用率較高。
事實上,這三個問題都很挑戰,本文暫不討論其解法,假設我們能夠解決這些問題的話,會有什么好處呢?
假設我們能解決前述的三個軟件上的難題,那就能“魚與熊掌兼得”:軟件發揮靈活性,硬件發揮高效率,任給一個深度學習任務,用戶不需要重新連線,就能享受那種“無限大專用硬件”的性能,何其美好。更令人激動的是,當這種軟件得以實現時,專用硬件可以比現在所有AI芯片都更簡單更高效。讀者可以先想象一下怎么實現這種美好的前景。

讓我們重申一下幾個觀點:(1)軟件真的非常關鍵;(2)我們對宏觀層次(設備和設備之間)的優化更感興趣;(3)深度學習框架存在一個理想的實現,正如柏拉圖心中那個最圓的圓,當然現有的深度學習框架還相距甚遠;(4)各行各業的公司,只要有數據驅動的業務,最終都需要一個自己的“大腦”,這種“大腦”不應該只被少數巨頭公司獨享。

商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4715.html
摘要:如果將小磁針看作神經元,磁針狀態看作激發與抑制,也可以用來構建深度學習的模型,或者玻爾茲曼機。這么多的基礎理論,展現了深度學習中的無處不在的物理本質。 最近朋友圈里有大神分享薛定諤的滾,一下子火了,當一個妹子叫你滾的時候,你永遠不知道她是在叫你滾還是叫你過來抱緊,這確實是一種十分糾結的狀態,而薛定諤是搞不清楚的,他連自己的貓是怎么回事還沒有弄清楚。雖然人們對于薛定諤頭腦中那只被放射性物質殘害...
摘要:經過近兩個小時的討論,很不幸我們得出了最后的結論在國內互聯網發展的這年間,短平快的發展模式造成了中國軟件工程領域架構師的嚴重斷層。中國真正的架構師在哪里在和產品組里的同學的討論過程中。 點擊上方藍色字體,選擇設為星標 回復面試獲取更多驚喜 背景 我先說下這篇文章的背景。 放假前的晚上,...
摘要:百度世界發布劃時代產品,軟硬件結合更懂智能生活月日,百度世界大會在北京盛大舉行。百度已與一汽集團簽署戰略合作協議,共同推動該項技術產品落地。渡鴉在會上同時公布了另外兩款即將面世的產品。 百度世界發布劃時代產品,軟硬件結合更懂智能生活 11 月 16 日,2017 百度世界大會在北京盛大舉行。百度在會上發布了手機百度 10.0 和全新人工智能硬件Raven H等軟硬件產品。百度董事長兼首...

閱讀 2664·2021-11-24 09:38
閱讀 1978·2019-08-30 15:53
閱讀 1234·2019-08-30 15:44
閱讀 3229·2019-08-30 14:10
閱讀 3578·2019-08-29 16:29
閱讀 1799·2019-08-29 16:23
閱讀 1099·2019-08-29 16:20
閱讀 1471·2019-08-29 11:13




