資訊專欄INFORMATION COLUMN

摘要:近幾年來,目標檢測算法取得了很大的突破。本文主要講述算法的原理,特別是算法的訓練與預測中詳細細節,最后將給出如何使用實現算法。但是結合卷積運算的特點,我們可以使用實現更高效的滑動窗口方法。這其實是算法的思路。下面將詳細介紹算法的設計理念。
1、前言
當我們談起計算機視覺時,首先想到的就是圖像分類,沒錯,圖像分類是計算機視覺最基本的任務之一,但是在圖像分類的基礎上,還有更復雜和有意思的任務,如目標檢測,物體定位,圖像分割等,見圖1所示。其中目標檢測是一件比較實際的且具有挑戰性的計算機視覺任務,其可以看成圖像分類與定位的結合,給定一張圖片,目標檢測系統要能夠識別出圖片的目標并給出其位置,由于圖片中目標數是不定的,且要給出目標的較精確位置,目標檢測相比分類任務更復雜。目標檢測的一個實際應用場景就是無人駕駛,如果能夠在無人車上裝載一個有效的目標檢測系統,那么無人車將和人一樣有了眼睛,可以快速地檢測出前面的行人與車輛,從而作出實時決策。

圖1 計算機視覺任務(來源: cs231n)
在介紹Yolo算法之前,首先先介紹一下滑動窗口技術,這對我們理解Yolo算法是有幫助的。采用滑動窗口的目標檢測算法思路非常簡單,它將檢測問題轉化為了圖像分類問題。其基本原理就是采用不同大小和窗口在整張圖片上以一定的步長進行滑動,然后對這些窗口對應的區域做圖像分類,這樣就可以實現對整張圖片的檢測了,如下圖3所示,如DPM就是采用這種思路。但是這個方法有致命的缺點,就是你并不知道要檢測的目標大小是什么規模,所以你要設置不同大小的窗口去滑動,而且還要選取合適的步長。但是這樣會產生很多的子區域,并且都要經過分類器去做預測,這需要很大的計算量,所以你的分類器不能太復雜,因為要保證速度。解決思路之一就是減少要分類的子區域,這就是R-CNN的一個改進策略,其采用了selective search方法來找到最有可能包含目標的子區域(Region Proposal),其實可以看成采用啟發式方法過濾掉很多子區域,這會提升效率。
近幾年來,目標檢測算法取得了很大的突破。比較流行的算法可以分為兩類,一類是基于Region Proposal的R-CNN系算法(R-CNN,Fast R-CNN, Faster R-CNN),它們是two-stage的,需要先使用啟發式方法(selective search)或者CNN網絡(RPN)產生Region Proposal,然后再在Region Proposal上做分類與回歸。而另一類是Yolo,SSD這類one-stage算法,其僅僅使用一個CNN網絡直接預測不同目標的類別與位置。第一類方法是準確度高一些,但是速度慢,但是第二類算法是速度快,但是準確性要低一些。這可以在圖2中看到。本文介紹的是Yolo算法,其全稱是You Only Look Once: Unified, Real-Time Object Detection,其實個人覺得這個題目取得非常好,基本上把Yolo算法的特點概括全了:You Only Look Once說的是只需要一次CNN運算,Unified指的是這是一個統一的框架,提供end-to-end的預測,而Real-Time體現是Yolo算法速度快。這里我們談的是Yolo-v1版本算法,其性能是差于后來的SSD算法的,但是Yolo后來也繼續進行改進,產生了Yolo9000算法。本文主要講述Yolo-v1算法的原理,特別是算法的訓練與預測中詳細細節,最后將給出如何使用TensorFlow實現Yolo算法。
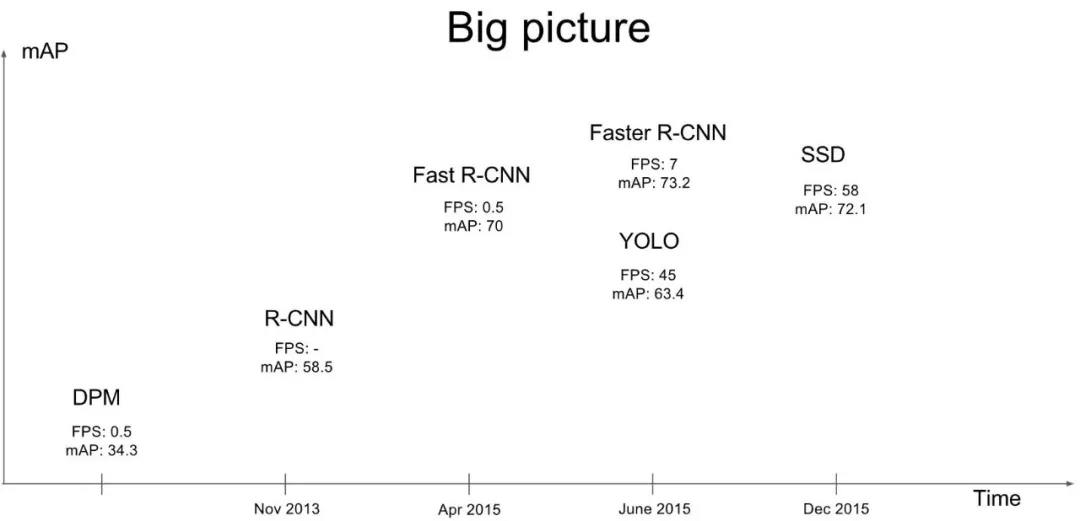
圖2 目標檢測算法進展與對比
2、滑動窗口與CNN
在介紹Yolo算法之前,首先先介紹一下滑動窗口技術,這對我們理解Yolo算法是有幫助的。采用滑動窗口的目標檢測算法思路非常簡單,它將檢測問題轉化為了圖像分類問題。其基本原理就是采用不同大小和窗口在整張圖片上以一定的步長進行滑動,然后對這些窗口對應的區域做圖像分類,這樣就可以實現對整張圖片的檢測了,如下圖3所示,如DPM就是采用這種思路。但是這個方法有致命的缺點,就是你并不知道要檢測的目標大小是什么規模,所以你要設置不同大小的窗口去滑動,而且還要選取合適的步長。但是這樣會產生很多的子區域,并且都要經過分類器去做預測,這需要很大的計算量,所以你的分類器不能太復雜,因為要保證速度。解決思路之一就是減少要分類的子區域,這就是R-CNN的一個改進策略,其采用了selective search方法來找到最有可能包含目標的子區域(Region Proposal),其實可以看成采用啟發式方法過濾掉很多子區域,這會提升效率。

圖3 采用滑動窗口進行目標檢測(來源:deeplearning.ai)
如果你使用的是CNN分類器,那么滑動窗口是非常耗時的。但是結合卷積運算的特點,我們可以使用CNN實現更高效的滑動窗口方法。這里要介紹的是一種全卷積的方法,簡單來說就是網絡中用卷積層代替了全連接層,如圖4所示。輸入圖片大小是16x16,經過一系列卷積操作,提取了2x2的特征圖,但是這個2x2的圖上每個元素都是和原圖是一一對應的,如圖上藍色的格子對應藍色的區域,這不就是相當于在原圖上做大小為14x14的窗口滑動,且步長為2,共產生4個字區域。最終輸出的通道數為4,可以看成4個類別的預測概率值,這樣一次CNN計算就可以實現窗口滑動的所有子區域的分類預測。這其實是overfeat算法的思路。之所可以CNN可以實現這樣的效果是因為卷積操作的特性,就是圖片的空間位置信息的不變性,盡管卷積過程中圖片大小減少,但是位置對應關系還是保存的。說點題外話,這個思路也被R-CNN借鑒,從而誕生了Fast R-CNN算法。

圖4 滑動窗口的CNN實現(來源:deeplearning.ai)
上面盡管可以減少滑動窗口的計算量,但是只是針對一個固定大小與步長的窗口,這是遠遠不夠的。Yolo算法很好的解決了這個問題,它不再是窗口滑動了,而是直接將原始圖片分割成互不重合的小方塊,然后通過卷積最后生產這樣大小的特征圖,基于上面的分析,可以認為特征圖的每個元素也是對應原始圖片的一個小方塊,然后用每個元素來可以預測那些中心點在該小方格內的目標,這就是Yolo算法的樸素思想。下面將詳細介紹Yolo算法的設計理念。
這就是Yolo算法的樸素思想。下面將詳細介紹Yolo算法的設計理念。
3、設計理念
整體來看,Yolo算法采用一個多帶帶的CNN模型實現end-to-end的目標檢測,整個系統如圖5所示:首先將輸入圖片resize到448x448,然后送入CNN網絡,最后處理網絡預測結果得到檢測的目標。相比R-CNN算法,其是一個統一的框架,其速度更快,而且Yolo的訓練過程也是end-to-end的。

圖5 Yolo檢測系統
具體來說,Yolo的CNN網絡將輸入的圖片分割成S*S網格,然后每個單元格負責去檢測那些中心點落在該格子內的目標,如圖6所示,可以看到狗這個目標的中心落在左下角一個單元格內,那么該單元格負責預測這個狗。每個單元格會預測B個邊界框(bounding box)以及邊界框的置信度(confidence score)。所謂置信度其實包含兩個方面,一是這個邊界框含有目標的可能性大小,二是這個邊界框的準確度。前者記為Pr(object),當該邊界框是背景時(即不包含目標),此時Pr(object)=0。而當該邊界框包含目標時,Pr(object)=1。邊界框的準確度可以用預測框與實際框(ground truth)的IOU(intersection over union,交并比)來表征,記為IOU。因此置信度可以定義為Pr(object)*IOU。很多人可能將Yolo的置信度看成邊界框是否含有目標的概率,但是其實它是兩個因子的乘積,預測框的準確度也反映在里面。邊界框的大小與位置可以用4個值來表征:(x,y,h,w),其中(x,y)是邊界框的中心坐標,而和是邊界框的寬與高。還有一點要注意,中心坐標的預測值(x,y)是相對于每個單元格左上角坐標點的偏移值,并且單位是相對于單元格大小的,單元格的坐標定義如圖6所示。而邊界框的w和h預測值是相對于整個圖片的寬與高的比例,這樣理論上4個元素的大小應該在[0,1]范圍。這樣,每個邊界框的預測值實際上包含5個元素:(x,y,w,h,c),其中前4個表征邊界框的大小與位置,而最后一個值是置信度。

圖6 網格劃分

總結一下,每個單元格需要預測(B*5+C)個值。如果將輸入圖片劃分為S*S網格,那么最終預測值為S*S*(B*5+C)大小的張量。整個模型的預測值結構如下圖所示。對于PASCALVOC數據,其共有20個類別,如果使用S=7,B=2,那么最終的預測結果就是7*7*30大小的張量。在下面的網絡結構中我們會詳細講述每個單元格的預測值的分布位置。
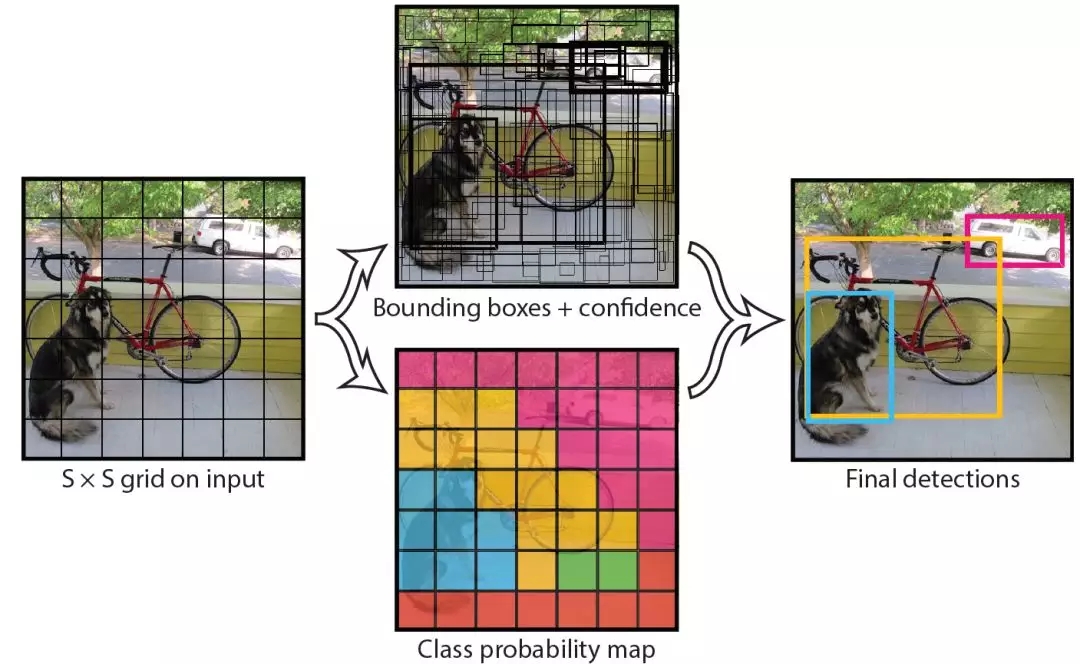
圖7 模型預測值結構
4、網絡設計
Yolo采用卷積網絡來提取特征,然后使用全連接層來得到預測值。網絡結構參考GooLeNet模型,包含24個卷積層和2個全連接層,如圖8所示。對于卷積層,主要使用1x1卷積來做channle reduction,然后緊跟3x3卷積。對于卷積層和全連接層,采用Leaky ReLU激活函數:max(x,0)。但是最后一層卻采用線性激活函數。除了上面這個結構,文章還提出了一個輕量級版本Fast Yolo,其僅使用9個卷積層,并且卷積層中使用更少的卷積核。

圖8 網絡結構

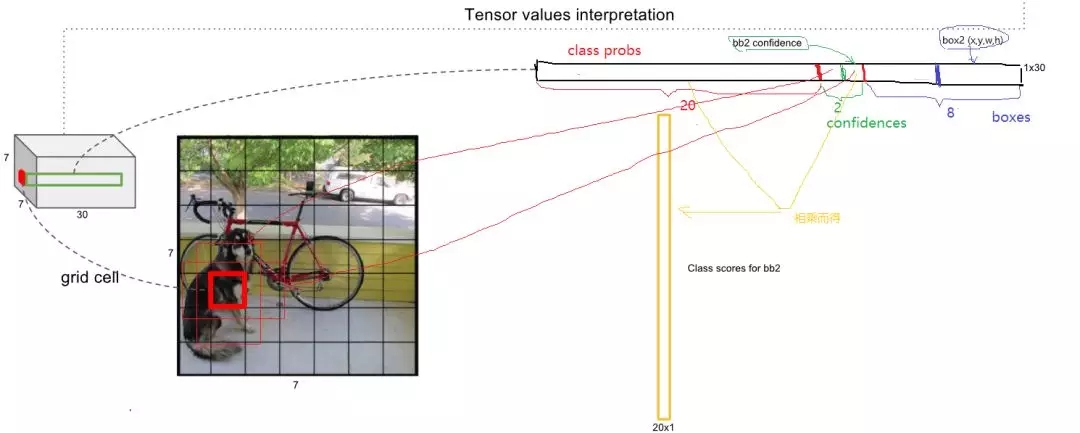
圖9 預測張量的解析
5、網絡訓練
在訓練之前,先在ImageNet上進行了預訓練,其預訓練的分類模型采用圖8中前20個卷積層,然后添加一個average-pool層和全連接層。預訓練之后,在預訓練得到的20層卷積層之上加上隨機初始化的4個卷積層和2個全連接層。由于檢測任務一般需要更高清的圖片,所以將網絡的輸入從224x224增加到了448x448。整個網絡的流程如下圖所示:
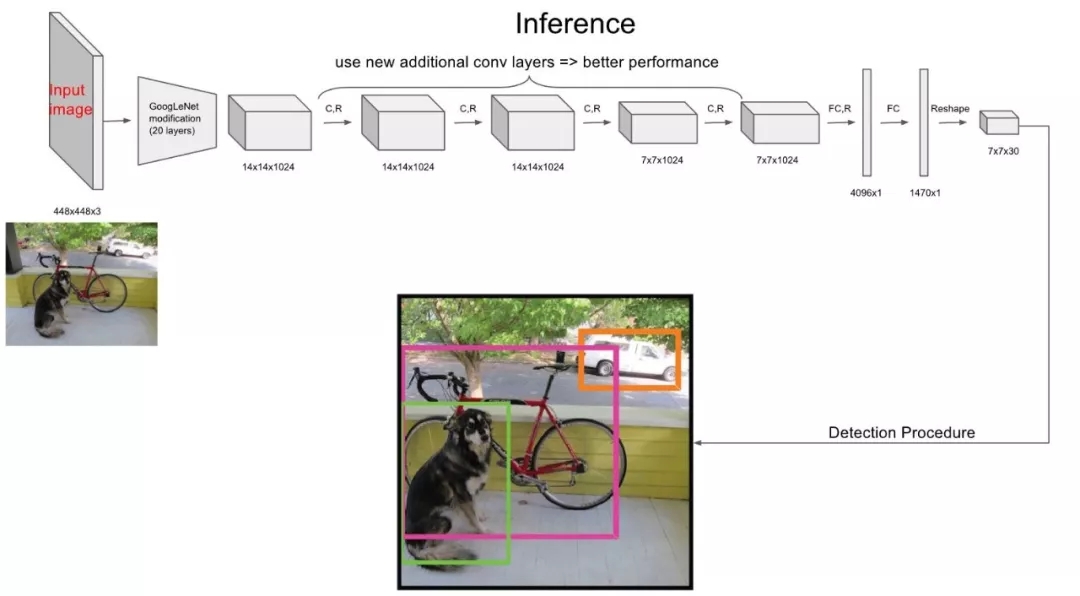
圖10 Yolo網絡流程

另外一點時,由于每個單元格預測多個邊界框。但是其對應類別只有一個。那么在訓練時,如果該單元格內確實存在目標,那么只選擇與ground truth的IOU較大的那個邊界框來負責預測該目標,而其它邊界框認為不存在目標。這樣設置的一個結果將會使一個單元格對應的邊界框更加專業化,其可以分別適用不同大小,不同高寬比的目標,從而提升模型性能。大家可能會想如果一個單元格內存在多個目標怎么辦,其實這時候Yolo算法就只能選擇其中一個來訓練,這也是Yolo算法的缺點之一。要注意的一點時,對于不存在對應目標的邊界框,其誤差項就是只有置信度,左標項誤差是沒法計算的。而只有當一個單元格內確實存在目標時,才計算分類誤差項,否則該項也是無法計算的。?
綜上討論,最終的損失函數計算如下:?


6、網絡預測
在說明Yolo算法的預測過程之前,這里先介紹一下非極大值抑制算法(non maximum suppression, NMS),這個算法不單單是針對Yolo算法的,而是所有的檢測算法中都會用到。NMS算法主要解決的是一個目標被多次檢測的問題,如圖11中人臉檢測,可以看到人臉被多次檢測,但是其實我們希望最后僅僅輸出其中一個較好的預測框,比如對于美女,只想要紅色那個檢測結果。那么可以采用NMS算法來實現這樣的效果:首先從所有的檢測框中找到置信度較大的那個框,然后挨個計算其與剩余框的IOU,如果其值大于一定閾值(重合度過高),那么就將該框剔除;然后對剩余的檢測框重復上述過程,直到處理完所有的檢測框。Yolo預測過程也需要用到NMS算法。
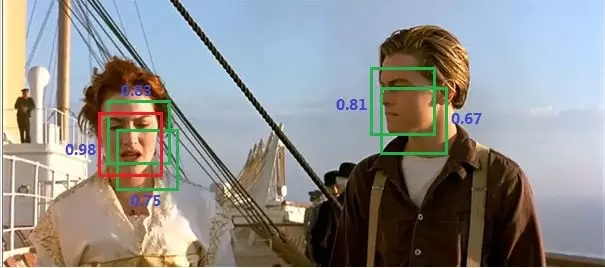
圖11 NMS應用在人臉檢測
下面就來分析Yolo的預測過程,這里我們不考慮batch,認為只是預測一張輸入圖片。根據前面的分析,最終的網絡輸出是7*7*30,但是我們可以將其分割成三個部分:類別概率部分為[7,7,20],置信度部分為[7,7,2,2],而邊界框部分為[7,7,2,4](對于這部分不要忘記根據原始圖片計算出其真實值)。然后將前兩項相乘可以得到類別置信度值為[7,7,2,20],這里總共預測了7*7*2=98邊界框。
所有的準備數據已經得到了,那么我們先說第一種策略來得到檢測框的結果,我認為這是最正常與自然的處理。首先,對于每個預測框根據類別置信度選取置信度較大的那個類別作為其預測標簽,經過這層處理我們得到各個預測框的預測類別及對應的置信度值,其大小都是[7,7,2]。一般情況下,會設置置信度閾值,就是將置信度小于該閾值的box過濾掉,所以經過這層處理,剩余的是置信度比較高的預測框。最后再對這些預測框使用NMS算法,最后留下來的就是檢測結果。一個值得注意的點是NMS是對所有預測框一視同仁,還是區分每個類別,分別使用NMS。Ng在deeplearning.ai中講應該區分每個類別分別使用NMS,但是看了很多實現,其實還是同等對待所有的框,我覺得可能是不同類別的目標出現在相同位置這種概率很低吧。
上面的預測方法應該非常簡單明了,但是對于Yolo算法,其卻采用了另外一個不同的處理思路(至少從C源碼看是這樣的),其區別就是先使用NMS,然后再確定各個box的類別。其基本過程如圖12所示。對于98個boxes,首先將小于置信度閾值的值歸0,然后分類別地對置信度值采用NMS,這里NMS處理結果不是剔除,而是將其置信度值歸為0。最后才是確定各個box的類別,當其置信度值不為0時才做出檢測結果輸出。這個策略不是很直接,但是貌似Yolo源碼就是這樣做的。Yolo論文里面說NMS算法對Yolo的性能是影響很大的,所以可能這種策略對Yolo更好。但是我測試了普通的圖片檢測,兩種策略結果是一樣的。
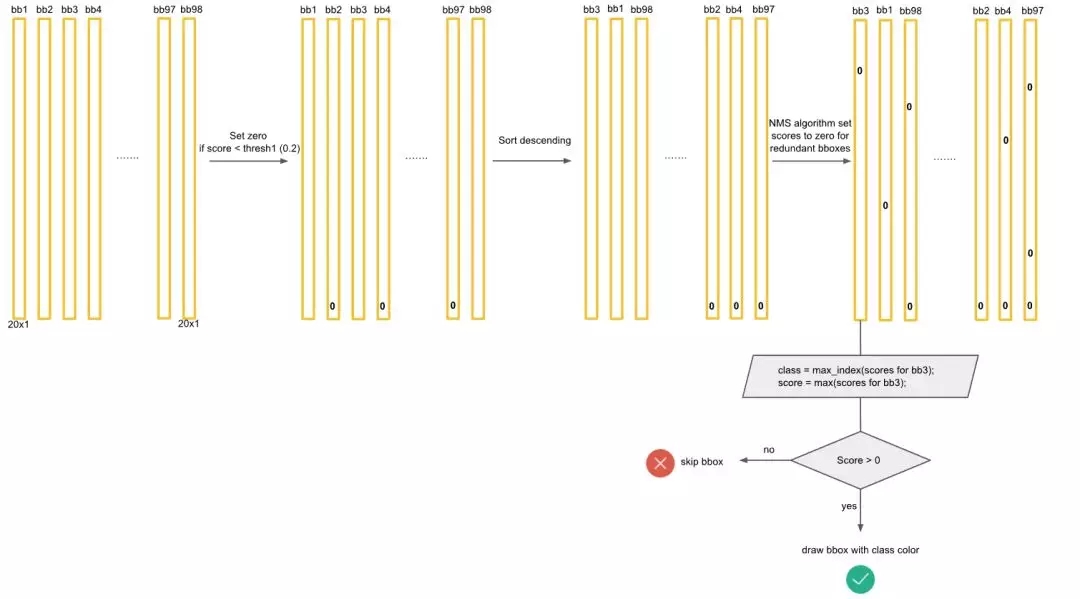
圖12 Yolo的預測處理流程
7、算法性能分析
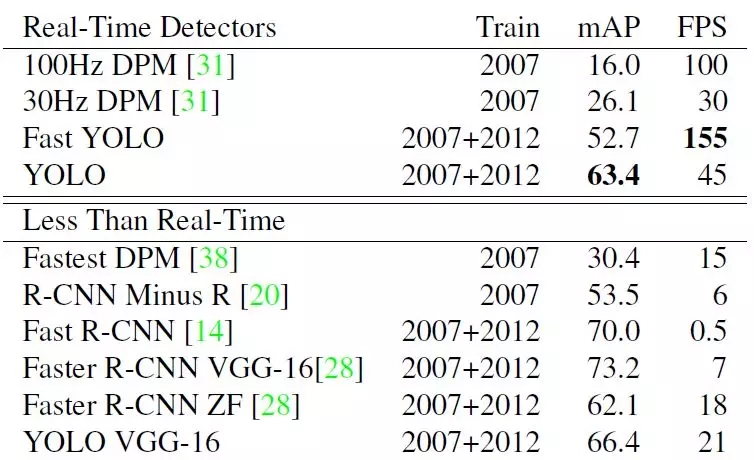
這里看一下Yolo算法在PASCAL VOC 2007數據集上的性能,這里Yolo與其它檢測算法做了對比,包括DPM,R-CNN,Fast R-CNN以及Faster R-CNN。其對比結果如表1所示。與實時性檢測方法DPM對比,可以看到Yolo算法可以在較高的mAP上達到較快的檢測速度,其中Fast Yolo算法比快速DPM還快,而且mAP是遠高于DPM。但是相比Faster R-CNN,Yolo的mAP稍低,但是速度更快。所以。Yolo算法算是在速度與準確度上做了折中。
表1 Yolo在PASCAL VOC 2007上與其他算法的對比?
為了進一步分析Yolo算法,文章還做了誤差分析,將預測結果按照分類與定位準確性分成以下5類:
Correct:類別正確,IOU>0.5;(準確度)
Localization:類別正確,0.1 < IOU<0.5(定位不準);
Similar:類別相似,IOU>0.1;
Other:類別錯誤,IOU>0.1;
Background:對任何目標其IOU<0.1。(誤把背景當物體)
Yolo與Fast R-CNN的誤差對比分析如下圖所示:
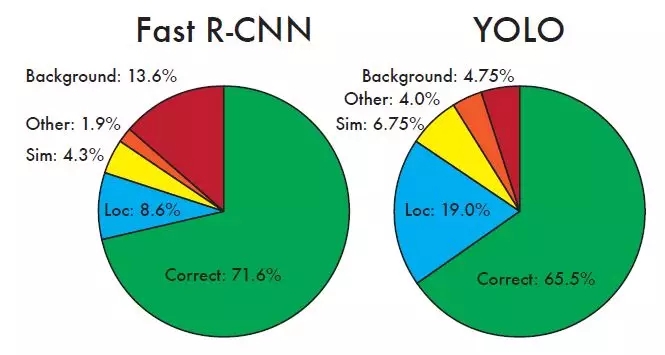
圖13 Yolo與Fast R-CNN的誤差對比分析?
可以看到,Yolo的Correct的是低于Fast R-CNN。另外Yolo的Localization誤差偏高,即定位不是很準確。但是Yolo的Background誤差很低,說明其對背景的誤判率較低。Yolo的那篇文章中還有更多性能對比,感興趣可以看看。
現在來總結一下Yolo的優缺點。首先是優點,Yolo采用一個CNN網絡來實現檢測,是單管道策略,其訓練與預測都是end-to-end,所以Yolo算法比較簡潔且速度快。第二點由于Yolo是對整張圖片做卷積,所以其在檢測目標有更大的視野,它不容易對背景誤判。其實我覺得全連接層也是對這個有貢獻的,因為全連接起到了attention的作用。另外,Yolo的泛化能力強,在做遷移時,模型魯棒性高。
最后不得不談一下Yolo的缺點,首先Yolo各個單元格僅僅預測兩個邊界框,而且屬于一個類別。對于小物體,Yolo的表現會不如人意。這方面的改進可以看SSD,其采用多尺度單元格。也可以看Faster R-CNN,其采用了anchor boxes。Yolo對于在物體的寬高比方面泛化率低,就是無法定位不尋常比例的物體。當然Yolo的定位不準確也是很大的問題。
8、算法的TF實現
Yolo的源碼是用C實現的,但是好在Github上有很多開源的TF復現。這里我們參考gliese581gg的實現來分析Yolo的Inference實現細節。我們的代碼將構建一個end-to-end的Yolo的預測模型,利用的已經訓練好的權重文件,你將可以用自然的圖片去測試檢測效果。?
首先,我們定義Yolo的模型參數:
class Yolo(object):
? ? def __init__(self, weights_file, verbose=True):
? ? ? ? self.verbose = verbose
? ? ? ? # detection params
? ? ? ? self.S = 7 ?# cell size
? ? ? ? self.B = 2 ?# boxes_per_cell
? ? ? ? self.classes = ["aeroplane", "bicycle", "bird", "boat", "bottle",
? ? ? ? ? ? ? ? ? ? ? ? "bus", "car", "cat", "chair", "cow", "diningtable",
? ? ? ? ? ? ? ? ? ? ? ? "dog", "horse", "motorbike", "person", "pottedplant",
? ? ? ? ? ? ? ? ? ? ? ? "sheep", "sofa", "train","tvmonitor"]
? ? ? ? self.C = len(self.classes) # number of classes
? ? ? ? # offset for box center (top left point of each cell)
? ? ? ? self.x_offset = np.transpose(np.reshape(np.array([np.arange(self.S)]*self.S*self.B),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? [self.B, self.S, self.S]), [1, 2, 0])
? ? ? ? self.y_offset = np.transpose(self.x_offset, [1, 0, 2])
? ? ? ? self.threshold = 0.2 ?# confidence scores threhold
? ? ? ? self.iou_threshold = 0.4
? ? ? ? # ?the maximum number of boxes to be selected by non max suppression
? ? ? ? self.max_output_size = 10
然后是我們模型的主體網絡部分,這個網絡將輸出[batch,7*7*30]的張量:
def _build_net(self):
? ? """build the network"""
? ? if self.verbose:
? ? ? ? print("Start to build the network ...")
? ? self.images = tf.placeholder(tf.float32, [None, 448, 448, 3])
? ? net = self._conv_layer(self.images, 1, 64, 7, 2)
? ? net = self._maxpool_layer(net, 1, 2, 2)
? ? net = self._conv_layer(net, 2, 192, 3, 1)
? ? net = self._maxpool_layer(net, 2, 2, 2)
? ? net = self._conv_layer(net, 3, 128, 1, 1)
? ? net = self._conv_layer(net, 4, 256, 3, 1)
? ? net = self._conv_layer(net, 5, 256, 1, 1)
? ? net = self._conv_layer(net, 6, 512, 3, 1)
? ? net = self._maxpool_layer(net, 6, 2, 2)
? ? net = self._conv_layer(net, 7, 256, 1, 1)
? ? net = self._conv_layer(net, 8, 512, 3, 1)
? ? net = self._conv_layer(net, 9, 256, 1, 1)
? ? net = self._conv_layer(net, 10, 512, 3, 1)
? ? net = self._conv_layer(net, 11, 256, 1, 1)
? ? net = self._conv_layer(net, 12, 512, 3, 1)
? ? net = self._conv_layer(net, 13, 256, 1, 1)
? ? net = self._conv_layer(net, 14, 512, 3, 1)
? ? net = self._conv_layer(net, 15, 512, 1, 1)
? ? net = self._conv_layer(net, 16, 1024, 3, 1)
? ? net = self._maxpool_layer(net, 16, 2, 2)
? ? net = self._conv_layer(net, 17, 512, 1, 1)
? ? net = self._conv_layer(net, 18, 1024, 3, 1)
? ? net = self._conv_layer(net, 19, 512, 1, 1)
? ? net = self._conv_layer(net, 20, 1024, 3, 1)
? ? net = self._conv_layer(net, 21, 1024, 3, 1)
? ? net = self._conv_layer(net, 22, 1024, 3, 2)
? ? net = self._conv_layer(net, 23, 1024, 3, 1)
? ? net = self._conv_layer(net, 24, 1024, 3, 1)
? ? net = self._flatten(net)
? ? net = self._fc_layer(net, 25, 512, activation=leak_relu)
? ? net = self._fc_layer(net, 26, 4096, activation=leak_relu)
? ? net = self._fc_layer(net, 27, self.S*self.S*(self.C+5*self.B))
? ? self.predicts = net
接下來,我們要去解析網絡的預測結果,這里采用了第一種預測策略,即判斷預測框類別,再NMS,多虧了TF提供了NMS的函數tf.image.non_max_suppression,其實實現起來很簡單,所有的細節前面已經交代了:
def _build_detector(self):
? ? """Interpret the net output and get the predicted boxes"""
? ? # the width and height of orignal image
? ? self.width = tf.placeholder(tf.float32, name="img_w")
? ? self.height = tf.placeholder(tf.float32, name="img_h")
? ? # get class prob, confidence, boxes from net output
? ? idx1 = self.S * self.S * self.C
? ? idx2 = idx1 + self.S * self.S * self.B
? ? # class prediction
? ? class_probs = tf.reshape(self.predicts[0, :idx1], [self.S, self.S, self.C])
? ? # confidence
? ? confs = tf.reshape(self.predicts[0, idx1:idx2], [self.S, self.S, self.B])
? ? # boxes -> (x, y, w, h)
? ? boxes = tf.reshape(self.predicts[0, idx2:], [self.S, self.S, self.B, 4])
? ? # convert the x, y to the coordinates relative to the top left point of the image
? ? # the predictions of w, h are the square root
? ? # multiply the width and height of image
? ? boxes = tf.stack([(boxes[:, :, :, 0] + tf.constant(self.x_offset, dtype=tf.float32)) / self.S * self.width,
? ? ? ? ? ? ? ? ? ? ? (boxes[:, :, :, 1] + tf.constant(self.y_offset, dtype=tf.float32)) / self.S * self.height,
? ? ? ? ? ? ? ? ? ? ? tf.square(boxes[:, :, :, 2]) * self.width,
? ? ? ? ? ? ? ? ? ? ? tf.square(boxes[:, :, :, 3]) * self.height], axis=3)
? ? # class-specific confidence scores [S, S, B, C]
? ? scores = tf.expand_dims(confs, -1) * tf.expand_dims(class_probs, 2)
? ? scores = tf.reshape(scores, [-1, self.C]) ?# [S*S*B, C]
? ? boxes = tf.reshape(boxes, [-1, 4]) ?# [S*S*B, 4]
? ? # find each box class, only select the max score
? ? box_classes = tf.argmax(scores, axis=1)
? ? box_class_scores = tf.reduce_max(scores, axis=1)
? ? # filter the boxes by the score threshold
? ? filter_mask = box_class_scores >= self.threshold
? ? scores = tf.boolean_mask(box_class_scores, filter_mask)
? ? boxes = tf.boolean_mask(boxes, filter_mask)
? ? box_classes = tf.boolean_mask(box_classes, filter_mask)
? ? # non max suppression (do not distinguish different classes)
? ? # ref: https://tensorflow.google.cn/api_docs/python/tf/image/non_max_suppression
? ? # box (x, y, w, h) -> box (x1, y1, x2, y2)
? ? _boxes = tf.stack([boxes[:, 0] - 0.5 * boxes[:, 2], boxes[:, 1] - 0.5 * boxes[:, 3],
? ? ? ? ? ? ? ? ? ? ? ?boxes[:, 0] + 0.5 * boxes[:, 2], boxes[:, 1] + 0.5 * boxes[:, 3]], axis=1)
? ? nms_indices = tf.image.non_max_suppression(_boxes, scores,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?self.max_output_size, self.iou_threshold)
? ? self.scores = tf.gather(scores, nms_indices)
? ? self.boxes = tf.gather(boxes, nms_indices)
? ? self.box_classes = tf.gather(box_classes, nms_indices)
其他的就比較容易了,詳細代碼附在Github上了,歡迎給點個贊,權重文件在這里下載。?
最后就是愉快地測試你自己的圖片了:

當然,如果你對訓練過程感興趣,你可以參考這里的實現,如果你看懂了預測過程的代碼,這里也會很容易閱讀。
9、小結
這篇長文詳細介紹了Yolo算法的原理及實現,當然Yolo-v1還是有很多問題的,所以后續可以讀讀Yolo9000算法,看看其如何改進的。Ng說Yolo的paper是比較難讀的,其實是很多實現細節,如果不看代碼是很難理解的。所以,文章中如果有錯誤也可能是難免的,歡迎交流指正。
10、參考文獻
You Only Look Once: Unified, Real-Time Object Detection.
Yolo官網.
Yolo的TF實現.
YOLO: You only look once (How it works).(注:很多實現細節,需要墻)
Ng的deeplearning.ai課程.
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4716.html
摘要:將圖像到作為輸入,輸出,即將圖片劃分為,每個單元格獨立檢測。類別損失當有物體的中心點落在單元格中,此單元格就負責預測該物體。 YOLO-v1介紹 YOLO是一個端到端的目標檢測算法,不需要預先提取region proposal(RCNN目標檢測系列),通過一個網絡就可以輸出:類別,置信度,坐標位置,檢測速度很快,不過,定位精度相對低些,特別是密集型小目標。 showImg(https:...

閱讀 2721·2021-11-22 13:54
閱讀 1062·2021-10-14 09:48
閱讀 2292·2021-09-08 09:35
閱讀 1549·2019-08-30 15:53
閱讀 1166·2019-08-30 13:14
閱讀 606·2019-08-30 13:09
閱讀 2521·2019-08-30 10:57
閱讀 3333·2019-08-29 13:18


