資訊專欄INFORMATION COLUMN

摘要:反饋檢測到的每個人的置信度值以及檢測到的每個姿勢關鍵點。姿勢置信度這決定了姿勢判斷的整體置信度。在較高級別,這將控制回饋的姿勢較低置信度分數。只有在調整姿勢置信度得分不夠好的情況下,為了過濾掉不太準確的姿勢,該數值應該增加或減少。
文 / Dan Oved,Google Creative Lab 的自由創意技術專家,紐約大學 ITP 的研究生。
編輯和插圖 / 創意技術專家 Irene Alvarado 和 Google Creative Lab 的自由平面設計師 Alexis Gallo
通過與 Google 創意實驗室的合作,我很高興地宣布 TensorFlow.js 版本的 PoseNet1,2 發布了,這是一個允許在瀏覽器中進行實時人體姿勢判斷的機器學習模型。 訪問 這里 嘗試一下在線演示吧。
注:這里鏈接
https://storage.googleapis.com/tfjs-models/demos/posenet/camera.html

PoseNet 可以使用單一姿勢或多種姿勢算法檢測到圖像和視頻中的人物 - 所有這些均來自瀏覽器
?
那么究竟什么是姿勢判斷呢? 姿勢判斷是指在圖像和視頻中檢測人物形象的計算機視覺技術,比如可以確定某個人的肘部出現在圖像中的位置。 需要澄清的是,這項技術無法識別圖像中的人物到底是誰 – 因為沒有任何與識別身份相關的個人身份信息。 該運算法則僅僅是判斷人體主要關節的位置。
?
好吧,知道為什么這是一個令人興奮的開始? 姿勢判斷有許多用途,從對身體做出反應的交互式裝置到增強現實,動畫,健身用途等等。 我們希望此模型的可訪問性能夠激發更多開發人員和制造商嘗試將姿態檢測應用到他們自己的項目中去。 雖然許多可選的姿勢檢測系統都已開源,但都需要配備專門的硬件和/或攝像頭,以及繁復的系統設置。?
PensNet 在 TensorFlow.js 上運行后,只要配備適合網絡攝像頭的 PC 或手機,任何人可以在網絡瀏覽器中體驗這項技術。 由于我們已經開源了該模型,因此 Javascript 開發人員只要通過幾行代碼就能修補和使用這項技術。更重要的是,這實際上還能有助保護用戶隱私。由于 TensorFlow.js 上的 PoseNet 是在瀏覽器中運行,因此任何姿勢數據都不會留在用戶的計算機上。
?
在深入研究該如何使用這個模型之前,對于那些將該項目付諸實現的人們,讓我們大聲歡呼向他們致敬:發布在 Wild and PersonLab 上有關于準確的多人姿勢判斷的文章《自下而上,基于部分的幾何嵌入模型進行人物姿勢判斷及實例分割》背后的谷歌研發人員 George Papandreou 和 Tyler Zhu, 以及 TensorFlow.js 庫背后的 Google Brain 團隊的工程師 Nikhil Thorat 和 Daniel Smilkov。
PoseNet 入門
PoseNet 可用于判斷單一姿勢或多個姿勢, 這就意味著會有一個檢測圖像/視頻中單人算法版本以及另一個可以檢測圖像/視頻中多個人的版本。 為什么有兩個版本? 單人姿勢檢測器更快更簡單,但是需要圖像中只有一個主體(稍后會深入探討)。 我們首先來講一講簡單易用的單一姿勢版本。
?
姿勢判斷在上層會分成兩個階段進行:
1. 輸入 RGB 圖像通過卷積神經網絡饋送。
2. 單一姿勢或多姿勢解碼算法用于從模型輸出解碼姿勢,姿勢置信度得分,關鍵點位置和關鍵點置信度得分。
?
稍等一下,這些關鍵字的含義是什么? 讓我們回顧一下最重要的內容:
姿勢 - 在別,PoseNet 將每個檢測到的人的關鍵點列表和實例級置信度分數反饋給一個姿勢對象。

PoseNet 反饋檢測到的每個人的置信度值以及檢測到的每個姿勢關鍵點。 Image Credit:“Microsoft Coco:Context Dataset 中的公共對象”,https://cocodataset.org。
姿勢置信度 – 這決定了姿勢判斷的整體置信度。 范圍介于 0.0 到 1.0 之間。 它可以用來隱藏那些幅度不夠大的姿勢。
?
關鍵點 – 它是判斷人體姿勢的一部分,例如鼻子,右耳,左膝,右腳等。它包含了位置和關鍵點置信度分數。 PoseNet 目前可檢測到下圖所示的 17 個關鍵點:
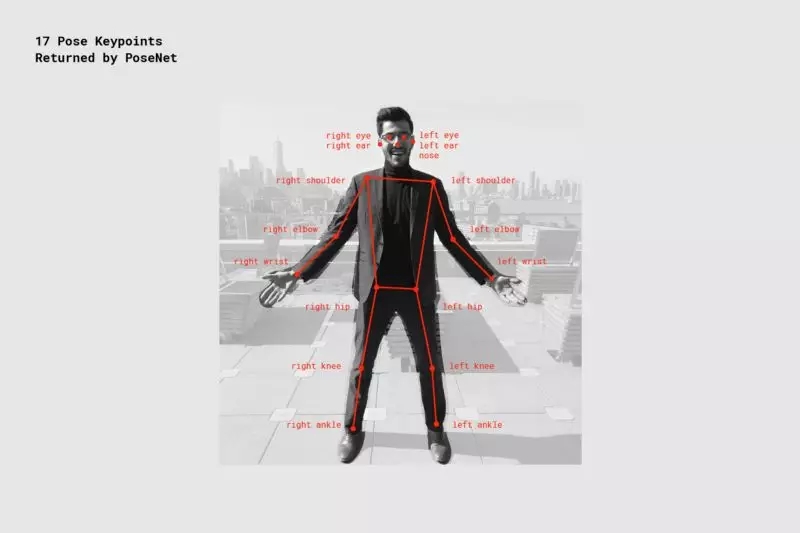
PoseNet 檢測到的 17 個姿勢關鍵點
關鍵點置信度得分 - 這決定了估計關鍵點位置準確的置信度。 范圍在 0.0 到 1.0 之間。 它可用于隱藏那些不夠強大的關鍵點。
?
關鍵點位置 – 檢測到的關鍵單在原始輸入圖像中的 ?x 和 y 二維坐標。
第1步:導入 TensorFlow.js 和 PoseNet 庫
將模型的復雜性抽象化并將功能封裝為易于使用的方法,這方面已經做了很多的工作。 讓我們回顧一下如何設置 PoseNet 項目的基礎知識。
該庫可以使用 npm 安裝:
npm install @tensorflow-models/posenet
并使用 es6 模塊導入:
import * as posenet from "@tensorflow-models/posenet";
const net = await posenet.load();
或通過頁面中的 bundle:
? ?
? ? ? ?
? ? ? ?
? ? ? ?
? ? ? ?
? ? ? ?
? ? ?
第 2a 步:單人姿態判斷

應用于圖像的單人姿勢判斷算法示例
Image Credit:“Microsoft Coco:Context Dataset 中的通用對象”,https://cocodataset.org
如前所述,兩個版本中,單一姿勢判斷算法更簡單,更快速。 它的理想場景是只有一個人居于輸入圖像或視頻中間。 缺點是,如果圖像中有多個人,那么來自兩個人的關鍵點可能被判斷為同一個單一姿勢的一部分 – 意思就是,例如,第 1 個人的左臂和第 2 個人的右膝通過算法被判斷屬于相同的姿勢而被混淆。 如果輸入圖像中包含多人,則應該使用多姿勢判斷的算法。
?
讓我們回顧一下單一姿勢判斷算法的輸入:?
輸入圖像元素 - 包含用于預測姿勢的圖像的 html 元素,例如視頻或圖像標簽。 重要的一點是,輸入的圖像或視頻元素必須是方形的。
?
圖像比例系數 – 是介于 0.2 和 1 之間的數字。默認為 0.50。 在輸入到網絡之前的縮放圖像比例。 將此數值設置得較低可以縮小圖像,以犧牲精度為代價從而提高速度。
?
水平翻轉 - 默認為 false。 姿勢應該是水平翻轉/鏡像。 對于視頻默認水平翻轉的視頻(即網絡攝像頭),如果您希望姿勢得以正確的方向回饋,應將此設置為 true。
?
輸出步幅 - 必須為 32,16 或 8。默認值為 16。在內部,此參數會影響神經網絡中圖層的高度和寬度。 在上層來看,它會影響姿勢判斷的精度和速度。 輸出值越低,精度越高但速度越慢;輸出值越高,速度越快但精度越低。 查看輸出步幅對輸出質量影響的較佳方法是嘗試使用這個單一姿勢判斷的實例。
?
現在讓我們回顧一下單一姿勢判斷算法的輸出:
包含姿勢置信度得分和 17 個關鍵點數組的姿勢。
?
每個關鍵點包含關鍵點位置和關鍵點置信度得分。 同樣,所有關鍵點位置在輸入圖像空間中都有 x 和 y 坐標,并且可以直接映射到圖像上。
?
這個簡短的代碼塊展示了如何使用單一姿勢判斷算法:
const imageScaleFactor = 0.50;
const flipHorizontal = false;
const outputStride = 16;
const imageElement = document.getElementById("cat");
// load the posenet model
const net = await posenet.load();
const pose = await net.estimateSinglePose(imageElement, scaleFactor, flipHorizontal, outputStride)
示例輸出姿勢如下所示:
{
?"score": 0.32371445304906,
?"keypoints": [
? ?{ // nose
? ? ?"position": {
? ? ? ?"x": 301.42237830162,
? ? ? ?"y": 177.69162777066
? ? ?},
? ? ?"score": 0.99799561500549
? ?},
? ?{ // left eye
? ? ?"position": {
? ? ? ?"x": 326.05302262306,
? ? ? ?"y": 122.9596464932
? ? ?},
? ? ?"score": 0.99766051769257
? ?},
? ?{ // right eye
? ? ?"position": {
? ? ? ?"x": 258.72196650505,
? ? ? ?"y": 127.51624706388
? ? ?},
? ? ?"score": 0.99926537275314
? ?},
? ?...
?]
}
第 2b 步: 多人姿勢判斷

應用于圖像的示例多人姿勢判斷算法
Image Credit: “Microsoft Coco: Common Objects in Context Dataset”,?https://cocodataset.org
多人姿勢判斷算法可以判斷圖像中許多的姿勢/人。 它比單一姿勢算法更為復雜,且速度稍慢,不過它的優點是,如果圖片中出現多個人,他們檢測到的關鍵點不太可能與錯誤的姿勢相關聯。 因此,即使用例是檢測單個人的姿勢,這個算法可能更合乎需要。
?
此外,該運算法則一個引人入勝的特性是其性能不會因輸入圖像中的人數多少而受到影響。 不管是檢測 15 個人或 5 個人,計算的時間是相同的。
?
我們來看一下輸入:
輸入圖像元素 - 與單一姿勢判斷相同
圖像比例系數 - 與單一姿勢判斷相同
水平翻轉 - 與單一姿勢判斷相同
輸出步幅 - 與單一姿勢判斷相同?
幅度較大的姿勢檢測 - 整數。 默認為 5. 要檢測的幅度較大的姿勢數值。
姿勢置信度得分閾值 - 0.0 到 1.0。 默認為 0.5。 在較高級別,這將控制回饋的姿勢較低置信度分數。?
非較大抑制(NMS)半徑 – 這是一個以像素為單位的數字。在上層,它會控制返回姿勢之間的最小距離。其默認值為 20,這在大多數情況下均表現良好。只有在調整姿勢置信度得分不夠好的情況下,為了過濾掉不太準確的姿勢,該數值應該增加或減少。
?
查看這些參數影響的較佳方法是嘗試一下多姿勢判斷的演示。
?
讓我們再看一下輸出:
一個通過一系列姿勢來解決的承諾。
每個姿勢包含與單人判斷算法中相同描述的信息。
?
這個短代碼塊展示了如何使用多姿勢判斷算法:
const imageScaleFactor = 0.50;
const flipHorizontal = false;
const outputStride = 16;
// get up to 5 poses
const maxPoseDetections = 5;
// minimum confidence of the root part of a pose
const scoreThreshold = 0.5;
// minimum distance in pixels between the root parts of poses
const nmsRadius = 20;
const imageElement = document.getElementById("cat");
// load posenet
const net = await posenet.load();
const poses = await net.estimateMultiplePoses(
? ? ?imageElement, imageScaleFactor, flipHorizontal, outputStride, ? ?
? ? ?maxPoseDetections, scoreThreshold, nmsRadius);
姿勢的示例輸出數組如下所示:
// array of poses/persons
[?
?{ // pose #1
? ?"score": 0.42985695206067,
? ?"keypoints": [
? ? ?{ // nose
? ? ? ?"position": {
? ? ? ? ?"x": 126.09371757507,
? ? ? ? ?"y": 97.861720561981
? ? ? ? },
? ? ? ?"score": 0.99710708856583
? ? ?},
? ? ?...?
? ?]
?},
?{ // pose #2
? ?"score": 0.13461434583673,
? ?"keypositions": [
? ? ?{ // nose
? ? ? ?"position": {
? ? ? ? ?"x": 116.58444058895,
? ? ? ? ?"y": 99.772533416748
? ? ? ?},
? ? ?"score": 0.9978438615799
? ? ?},
? ? ?...
? ?]
?},
?...?
]
如果您已經閱讀過這篇文章,那么您就已經了解了 PoseNet 演示的全部內容。 這也許是一個很好的停止點。 如果您想深入了解有關模型和實施的技術細節的更多信息,我們邀請您繼續閱讀下文。
致孜孜不倦的鉆研者:技術深潛
在本節中,我們將詳細介紹單一姿勢判斷算法。在上層,該過程如下所示:
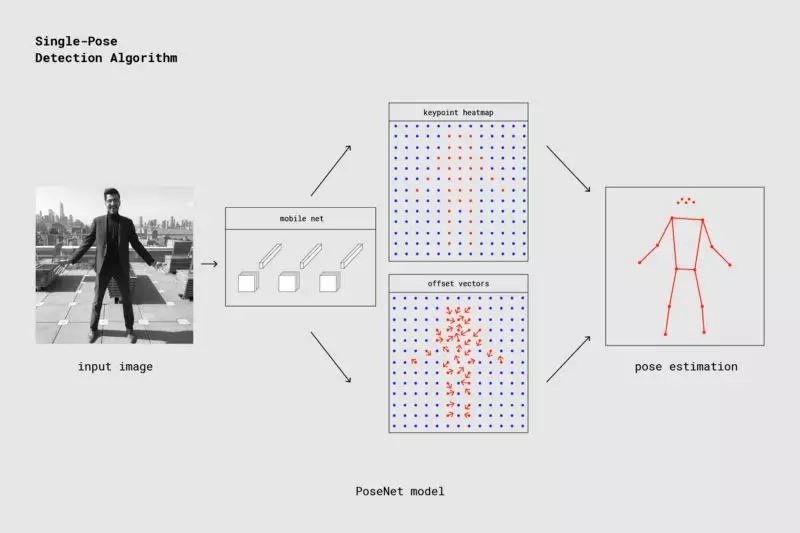
使用 PoseNet 的單人姿勢探測器通道
需要注意的一個重要細節是,研究人員同時訓練了 PoseNet 上的一個 ResNet 模型和一個 MobileNet 模型。 雖然 ResNet 模型具有更高的準確性,但對于實時應用程序來說,其大尺寸和多層面使頁面加載時間和推理時間變得不太理想。我們使用 MobileNet 模型,因為它是專為移動設備上運行而設計的。
注: ResNet 模型鏈接
https://arxiv.org/abs/1512.03385
MobileNet 模型鏈接
https://arxiv.org/abs/1704.04861
再看一下單一姿勢判斷算法
處理模型輸入:輸出步幅的解釋
首先,我們將討論如何通過輸出步幅來獲得 PoseNet 模型輸出(主要是熱圖和偏移矢量)。
?
PoseNet 模型可以方便地保持圖像大小恒定,意思是不管圖像是否縮小,它能夠以與原始圖像相同的比例預測姿勢位置。 這就意味著通過設置我們在運行上面提到的輸出步幅時,在犧牲了性能的情況下,可以將 PoseNet 配置成更高的精度。
?
輸出步幅決定了我們相對于輸入圖像大小縮小輸出的程度。 它會影響圖層的大小和模型輸出。 輸出步幅越高,網絡中的層的分辨率和輸出越小,相應地它們的精度也越高。 在此應用中,輸出步幅可以取值 8,16 或 32。換句話說,在輸出步幅為 32 的情況下,能夠取得最快的表現但是精度卻是較低,而 8 則相反,精度較高但表現最慢。 我們建議從 16 開始。

輸出步幅決定了我們相對于輸入圖像大小縮小輸出的程度。 輸出步幅更高,表現更快,但精度更低
在后臺中,當輸出步幅設置為 8 或 16 時,減少層中步幅的輸入量就能創建更大的輸出分辨率。 然后使用帶孔卷積核使后續層中的卷積濾波器具有更寬的視場(當輸出步幅為 32 時不適用帶孔卷積核)。 雖然 Tensorflow 支持帶孔卷積核,但 TensorFlow.js 卻不支持,為此我們添加了一個 PR 來包含它。
模型輸出: 熱圖和偏移矢量
當 PoseNet 處理圖像時,實際上反饋的是熱圖以及偏移矢量,可以對其進行解碼,用以在圖像中找到與姿勢關鍵點對應的高置信度區域。 我們可以快速討論其中每一個意味著什么,但眼下我們在高級別情況下捕獲的如下圖演示了每個姿勢關鍵點如何與一個熱圖張量和偏移矢量張量相關聯。
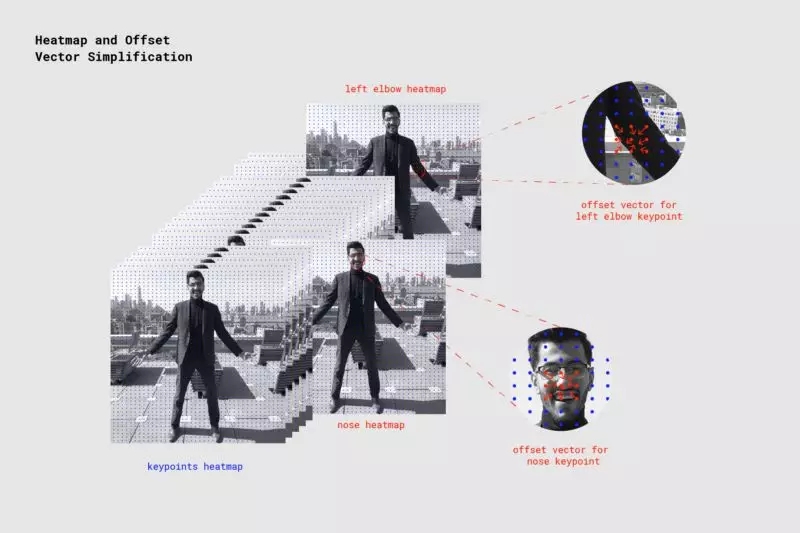
PoseNet 反饋的 17 個姿勢關鍵點中的每一個都與一個熱圖張量和一個偏移矢量張量相關聯,用于確定關鍵點的確切位置
這兩個輸出都是具有高度和寬度的 3D 張量,我們將其稱為分辨率。 分辨率根據以下公式由輸入圖像大小和輸出步幅決定:
Resolution = ((InputImageSize - 1) / OutputStride) + 1
// Example: an input image with a width of 225 pixels and an output
// stride of 16 results in an output resolution of 15
// 15 = ((225 - 1) / 16) + 1
熱圖
每個熱圖是尺寸為分辨率 x 分辨率 x 17 的 3D 張量,因為 17 是 PoseNet 檢測到的關鍵點的數量。 例如,圖像大小為 225,輸出步幅為 16,那么就是 15x15x17。 第三維(17)中的每個切片與特定關鍵點的熱圖對應。 該熱圖中的每個位置都有一個置信度分數,即該關鍵點類型的一部分存在于該位置的概率。 可以視作原始圖像被分解成 15x15 網格,而熱圖分數將對每個網格方塊中每個關鍵點存在的可能性進行分類。
偏移矢量
每個偏移矢量是尺寸分辨率 x 分辨率 x 34 的 3D 張量,其中 34 是關鍵點的數量 * 2。圖像尺寸為 225,輸出步幅為 16,那么就是 15x15x34。 由于熱圖是關鍵點所在的近似值,因此偏移矢量在位置上對應于熱圖點,并用于通過沿相應熱圖點的矢量行進來預測關鍵點的確切位置。 偏移矢量的前 17 個切片包含矢量的 x,最后的 17 個 y。 偏移矢量大小與原始圖像的比例相同。
從模型的輸出判斷姿勢
圖像通過模型后,我們會執行一系列計算來判斷輸出的姿勢。 例如,單一姿勢判斷算法會回饋姿勢置信度得分,其本身包含關鍵點陣列(由部件 ID 索引),每個關鍵點具有置信度得分和 x,y 位置。
?
要獲得姿勢的關鍵點:
在熱圖上進行 S 形激活以獲得分數。得分= heatmap.sigmoid()
argmax2d 在關鍵點置信度得分上完成,以獲得熱圖中的x和y索引,每個部分的得分較高,這實際上是該部分最可能存在的位置。這會產生一個大小為 17x2 的張量,每一行都是熱圖中的 y 和 x 索引,每個部分的得分較高。heatmapPositions = scores.argmax(y,x)
通過從對應于該部件的熱圖中的 x 和 y 索引的偏移量獲取 x 和 y 來檢索每個部件的偏移矢量。這會產生一個大小為 17x2 的張量,每行是相應關鍵點的偏移量。例如,對于索引 k 處的部分,當熱圖位置為 y 和 d 時,偏移矢量為:offsetVector = [offsets.get(y,x,k),offsets.get(y,x,17 + k)]
為了得到關鍵點,每個部件的熱圖 x 和 y 乘以輸出步幅,然后加到它們相應的偏移矢量,該矢量與原始圖像的比例相同。keypointPositions = heatmapPositions * outputStride + offsetVectors
最后,每個關鍵點置信度得分是其熱圖位置的置信度得分。姿勢置信度得分是關鍵點得分的平均值。
多人姿勢判斷
多姿勢判斷運算法則的詳細內容就不在本文中一一贅述。 大體來說,該運算法則的不同之處在于它使用了貪婪過程,通過沿著基于部分的圖形來跟隨位移矢量來將關鍵點分組成姿勢。 確切地說,就是它使用了研究論文 PersonLab 中的快速貪婪解碼算法:人物姿勢判斷和實例分割與自下而上,基于部分的幾何嵌入模型。 有關多姿勢運算法則的更多信息,請閱讀完整的研究論文或查看 代碼。
注:代碼鏈接
https://github.com/tensorflow/tfjs-models/tree/master/posenet/src
最后
我們希望隨著越來越多的模型被移植導入到 TensorFlow.js,機器學習的世界變得對新的編碼員和制造者來說更容易接近,更受歡迎,更有趣。 TensorFlow.js 上的 PoseNet 是一個小嘗試,使之成為可能。 我們將很樂意看到你的制作 - 并且不要忘記使用 #tensorflowjs 和 #posenet 來分享你的精彩項目!
聲明:文章收集于網絡,如有侵權,請聯系小編及時處理,謝謝!
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4801.html
摘要:文和,創意實驗室創意技術專家在機器學習和計算機視覺領域,姿勢預測或根據圖像數據探測人體及其姿勢的能力,堪稱最令人興奮而又最棘手的一個話題。使用,用戶可以直接在瀏覽器中運行機器學習模型,無需服務器。 文 / ?Jane Friedhoff 和 Irene Alvarado,Google 創意實驗室創意技術專家在機器學習和計算機視覺領域,姿勢預測或根據圖像數據探測人體及其姿勢的能力,堪稱最令人興...
摘要:而另一款網紅產品抖音,也在去年底上線過一個尬舞機的音樂體感游戲現在成了隱藏功能游戲開始后,隨著音樂會給出不同的動作提示,用戶按照提示擺出正確動作即可得分。 如今說到體感游戲,大家一定都不陌生,比如微軟的 Kinect、任天堂的 Switch,都曾是游戲業的革命性產品。而另一款網紅產品—抖音,也在去年底上線過一個尬舞機的音樂體感游戲(現在成了隱藏功能): showImg(https://...
摘要:萬萬沒想到,在圣誕節前夕,女神居然答應了在下的約會請求。想在下正如在座的一些看官一樣,雖玉樹臨風風流倜儻,卻總因猜不透女孩的心思,一不留神就落得個母胎單身。在內部將張量表示為基本數據類型的維數組。 showImg(https://segmentfault.com/img/remote/1460000017498745); 本文將結合移動設備攝像能力與 TensorFlow.js,在瀏覽...

閱讀 3593·2021-11-23 09:51
閱讀 2794·2021-11-23 09:51
閱讀 675·2021-10-11 10:59
閱讀 1672·2021-09-08 10:43
閱讀 3223·2021-09-08 09:36
閱讀 3288·2021-09-03 10:30
閱讀 3293·2021-08-21 14:08
閱讀 2195·2021-08-05 09:59




