資訊專欄INFORMATION COLUMN

Apache MXNet v0.12來了。
今天凌晨,亞馬遜宣布了MXNet新版本,在這個版本中,MXNet添加了兩個重要新特性:
支持英偉達Volta GPU,大幅減少用戶訓練和推理神經網絡模型的時間。
在存儲和計算效率方面支持稀疏張量(Sparse Tensor),讓用戶通過稀疏矩陣訓練模型。
下面,量子位將分別詳述這兩個新特性。

Tesla V100 加速卡內含 Volta GV100 GPU
支持英偉達Volta GPU架構
MXNet v0.12增加了對英偉達Volta V100 GPU的支持,讓用戶訓練深度神經網絡的速度比在Pascal GPU上快3.5倍。這些運算通常用單精度(FP32)實現高準確率。
然而,最近的研究顯示,用戶可以用半精度(FP16)達到相同的準確率。
Volta GPU架構中引入了張量核(Tensor Core),每個張量核每小時能處理64次積和熔加運算(fused-multiply-add,FMA),每小時將CUDA每個核心FLOPS(每秒浮點運算)大致翻至四倍。
每個張量核都執行下圖所示的D=AxB+C運算,其中A和B是半較精確的矩陣,C和D可以是半或單精度矩陣,從而進行混合精度訓練。
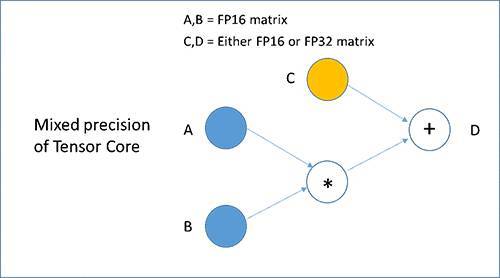
新混合精度訓練可在不降低準確性的情況下實現較佳訓練性能,神經網絡中大部分層精度為FP16,且只在必要時用更高精度的數據類型。
MXNet利用Volta張量核使用戶輕松用FP16訓練模型。舉個例子,用戶將以下命令選項傳遞到train_imagenet,可在MXNet中啟用FP16 train_imagenet.py腳本。

支持稀疏張量
MXNet v0.12增加了對稀疏張量的支持,來有效存儲和計算大多數元素為0的張量。
我們熟悉的亞馬遜推薦系統就是基于深度學習的推薦引擎,它包含了稀疏矩陣的乘法和加法,其中大多數元素都是0。
在稀疏矩陣中執行萬億次矩陣運算,與在密集矩陣之間執行的方式相同。在密集矩陣的存儲和計算效率不高,在默認密結構中存儲和操作稀疏矩陣,會導致在不必要的處理上浪費內存。
為了解決這些問題,MXNet開始支持稀疏張量,讓用戶在保持存儲和計算效率的方式下執行稀疏矩陣操作,更快地訓練深度學習模型。MXNet v0.12支持兩種主要的稀疏數據格式:壓縮稀疏矩陣(CSR)和行稀疏(RSP)。
CSR格式被優化來表示矩陣中的大量列,其中每行只有幾個非零元素。經過優化的RSP格式用來表示矩陣中的大量行,其中的大部分行切片都是零。
例如,可以用CSR格式對推薦引擎輸入數據的特征向量進行編碼,而RSP格式可在訓練期間執行稀疏梯度更新。
這個版本支持大多數在CPU上常用運算符的稀疏操作,比如矩陣點乘積和元素級運算符。在未來版本中,將增加對更多運算符的稀疏支持。
相關資料
最后,附官方介紹地址:
https://amazonaws-china.com/cn/blogs/ai/apache-mxnet-release-adds-support-for-new-nvidia-volta-gpus-and-sparse-tensor/
MXNet使用指南:
http://mxnet.incubator.apache.org/get_started/install.html
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4658.html
摘要:是由華盛頓大學在讀博士陳天奇等人提出的深度學習自動代碼生成方法,去年月機器之心曾對其進行過簡要介紹。目前的堆棧支持多種深度學習框架以及主流以及專用深度學習加速器。 TVM 是由華盛頓大學在讀博士陳天奇等人提出的深度學習自動代碼生成方法,去年 8 月機器之心曾對其進行過簡要介紹。該技術能自動為大多數計算硬件生成可部署優化代碼,其性能可與當前最優的供應商提供的優化計算庫相比,且可以適應新型專用加...
摘要:亞馬遜和華盛頓大學今天合作發布了開源的端到端深度學習編譯器。項目作者之一陳天奇在微博上這樣介紹這個編譯器我們今天發布了基于工具鏈的深度學習編譯器。陳天奇團隊對的性能進行了基準測試,并與進行了比較。 亞馬遜和華盛頓大學今天合作發布了開源的端到端深度學習編譯器NNVM compiler。先提醒一句,NNVM compiler ≠ NNVM。NNVM是華盛頓大學博士陳天奇等人2016年發布的模塊化...
摘要:幸運的是,這些正是深度學習所需的計算類型。幾乎可以肯定,英偉達是目前執行深度學習任務較好的選擇。今年夏天,發布了平臺提供深度學習支持。該工具適用于主流深度學習庫如和。因為的簡潔和強大的軟件包擴展體系,它目前是深度學習中最常見的語言。 深度學習初學者經常會問到這些問題:開發深度學習系統,我們需要什么樣的計算機?為什么絕大多數人會推薦英偉達 GPU?對于初學者而言哪種深度學習框架是較好的?如何將...
摘要:深度學習是一個對算力要求很高的領域。這一早期優勢與英偉達強大的社區支持相結合,迅速增加了社區的規模。對他們的深度學習軟件投入很少,因此不能指望英偉達和之間的軟件差距將在未來縮小。 深度學習是一個對算力要求很高的領域。GPU的選擇將從根本上決定你的深度學習體驗。一個好的GPU可以讓你快速獲得實踐經驗,而這些經驗是正是建立專業知識的關鍵。如果沒有這種快速的反饋,你會花費過多時間,從錯誤中吸取教訓...
摘要:據悉,在舊金山舉行的高通活動上,這家巨頭正式宣布進軍云計算市場,并發布了面向人工智能推理計算的專用加速器。沒有任何預告,繼谷歌亞馬遜和英偉達之后,高通成為第四家成功在云端推理上正式發布芯片的公司。提起高通,業內對它的直接印象就是移動芯片領域的巨頭。一直以來,高通也確實只在移動通信領域深耕,并從芯片到底層平臺一攬子都包下。而現在,高通冷不丁扔出的一枚炸彈也將一改以往大家對它的認知。據悉,在舊金...

閱讀 1495·2023-04-26 01:28
閱讀 3314·2021-11-22 13:53
閱讀 1420·2021-09-04 16:40
閱讀 3189·2019-08-30 15:55
閱讀 2676·2019-08-30 15:54
閱讀 2488·2019-08-30 13:47
閱讀 3365·2019-08-30 11:27
閱讀 1145·2019-08-29 13:21






