資訊專(zhuān)欄INFORMATION COLUMN

摘要:陳建平說(shuō)訓(xùn)練是十分重要的,尤其是對(duì)關(guān)注算法本身的研究者。代碼生成其實(shí)在中也十分簡(jiǎn)單,陳建平不僅利用車(chē)道線識(shí)別模型向我們演示了如何使用生成高效的代碼,同時(shí)還展示了在脫離環(huán)境下運(yùn)行代碼進(jìn)行推斷的效果。
近日,Mathworks 推出了包含 MATLAB 和 Simulink 產(chǎn)品系列的 Release 2017b(R2017b),該版本大大加強(qiáng)了 MATLAB 對(duì)深度學(xué)習(xí)的支持,并簡(jiǎn)化了工程師、研究人員及其他領(lǐng)域?qū)<以O(shè)計(jì)、訓(xùn)練和部署模型的方式。該更新版本從數(shù)據(jù)標(biāo)注、模型搭建、訓(xùn)練與推斷還有最后的模型部署方面完整地支持深度學(xué)習(xí)開(kāi)發(fā)流程。此外,MATLAB 這次更新較大的亮點(diǎn)是新組件 GPU Coder,它能自動(dòng)將深度學(xué)習(xí)模型代碼轉(zhuǎn)換為 NVIDIA GPU 的 CUDA 代碼,GPU Coder 轉(zhuǎn)換后的 CUDA 代碼可以脫離 MATLAB 環(huán)境直接高效地執(zhí)行推斷。經(jīng) MATLAB 內(nèi)部基準(zhǔn)測(cè)試顯示,GPU Coder 產(chǎn)生的 CUDA 代碼,比 TensorFlow 的性能高 7 倍,比 Caffe2 的性能高 4.5 倍。
對(duì)此,機(jī)器之心采訪了 MathWorks 中國(guó)資深應(yīng)用工程師陳建平,陳建平從 MATLAB 中的數(shù)據(jù)標(biāo)注開(kāi)始沿著深度學(xué)習(xí)模型的開(kāi)發(fā)、訓(xùn)練、調(diào)試到最后使用 GPU Coder 部署高性能模型,為我們介紹了 MATLAB 這一次更新針對(duì)深度學(xué)習(xí)所做的努力。本文將沿著 MATLAB 深度學(xué)習(xí)開(kāi)發(fā)過(guò)程簡(jiǎn)要介紹這次更新的要點(diǎn),同時(shí)重點(diǎn)向大家展示能自動(dòng)將模型轉(zhuǎn)化為 CUDA 代碼的 GPU Coder 模塊。
數(shù)據(jù)標(biāo)注
對(duì)于計(jì)算機(jī)視覺(jué)來(lái)說(shuō),Computer Vision System Toolbox 中的 Ground Truth Labeler app 可提供一種交互式的方法半自動(dòng)地標(biāo)注一系列圖像。除了目標(biāo)檢測(cè)與定位外,該工具箱現(xiàn)在還支持語(yǔ)義分割,它能對(duì)圖像中的像素區(qū)域進(jìn)行分類(lèi)。陳建平說(shuō):「我們現(xiàn)在的標(biāo)注工具可以直接半自動(dòng)地完成任務(wù),它可以像 Photoshop 中的魔棒工具一樣自動(dòng)標(biāo)注出像素層級(jí)的類(lèi)別,我們選中圖片后工具會(huì)自動(dòng)將對(duì)象摳出來(lái)。在我們完成初始化的圖像語(yǔ)義分割后,工具會(huì)使用自動(dòng)化的手段把后續(xù)行駛過(guò)程中的其它元素都摳出來(lái)。因?yàn)橹虚g和后續(xù)過(guò)程都是以機(jī)器為主導(dǎo)完成的,所以我們只需要在前期使用少量的人力就能完成整個(gè)標(biāo)注過(guò)程。」
這種半自動(dòng)方法確實(shí)可以大大提升標(biāo)注的效率,特別是標(biāo)注車(chē)道邊界線和汽車(chē)邊界框等視覺(jué)系統(tǒng)目標(biāo)。在這種自動(dòng)標(biāo)注框架下,算法可以快速地完成整個(gè)數(shù)據(jù)集的標(biāo)注,而隨后我們只需要少量的監(jiān)督與驗(yàn)證就能構(gòu)建一個(gè)較精確的數(shù)據(jù)集。如下所示,MATLAB 文檔向我們展示了如何創(chuàng)建車(chē)道線自動(dòng)標(biāo)注。

我們可以使用不同的算法,如能自動(dòng)檢測(cè)車(chē)道線特征的 Auto Lane Detection、使用聚合通道特征(Aggregate Channel Features/ACF)檢測(cè)車(chē)輛的 ACF Vehicle Detector 和使用 Kanade-Lucas_Tomasi(KLT)在小間隔內(nèi)追蹤一個(gè)或多個(gè) ROI 的算法等。如果我們選擇自動(dòng)算法,那么接下來(lái)設(shè)置 ROI、較大車(chē)道數(shù)、車(chē)道線寬度等參數(shù)后就可以直接運(yùn)行自動(dòng)標(biāo)注。若視頻經(jīng)過(guò)人工微調(diào)與校驗(yàn),并達(dá)到不錯(cuò)的效果,我們就可以選擇「Accept」完成標(biāo)注任務(wù)。
模型構(gòu)建
在模型構(gòu)建方面,Neural Network Toolbox 增加了對(duì)復(fù)雜架構(gòu)的支持,包括有向無(wú)環(huán)圖(DAG)和長(zhǎng)短期記憶(LSTM)網(wǎng)絡(luò)等,并提供對(duì) GoogLeNet 等流行的預(yù)訓(xùn)練模型的訪問(wèn)方式。陳建平表示:「其實(shí) MATLAB 在 2016 年的時(shí)候就已經(jīng)支持一些深度學(xué)習(xí)模型,而現(xiàn)在不僅支持 VGGNet 和 GoogleNet 等流行的預(yù)訓(xùn)練模型,同時(shí)還支持使用 Caffe Model Importer 直接從 Caffe 中導(dǎo)入。」
因?yàn)槲覀兛梢灾苯訌?Caffe Model Zoo 中導(dǎo)入各種優(yōu)秀與前沿的模型,所以 MATLAB 在模型方面可以提供廣泛的支持。但直接從 Caffe 中導(dǎo)入模型又會(huì)產(chǎn)生一個(gè)疑惑,即如果我們?cè)?Python 環(huán)境下使用 Caffe 構(gòu)建了一個(gè)模型,那么導(dǎo)入 MATLAB 是不是需要轉(zhuǎn)寫(xiě)代碼,會(huì)不會(huì)需要做一些額外的工作以完成導(dǎo)入?對(duì)此,陳建平解答到:「假設(shè)我們使用 Python 和 Caffe 完成了一個(gè)模型,并保存以 Caffe 格式,那么 Caffe Model Importer 會(huì)直接從保存的 Caffe 格式中讀取模型。在這個(gè)過(guò)程中,Caffe 并不需要為 MATLAB 做額外的工作,所有的轉(zhuǎn)換結(jié)果都是 MATLAB 完成的。」
在導(dǎo)入模型后,我們可以直接使用類(lèi)似于 Keras 的高級(jí) API 修改模型或重建模型。下面將簡(jiǎn)要介紹如何導(dǎo)入預(yù)訓(xùn)練 AlexNet,并修改完成遷移學(xué)習(xí)。
首先我們需要導(dǎo)入 AlexNet,如果 Neural Network Toolbox 中沒(méi)有安裝 AlexNet,那么軟件會(huì)提供下載地址。
net?
=
?alexnet
;
net
.
Layers
上面的語(yǔ)句將導(dǎo)入 AlexNet,并如下所示展示整個(gè) CNN 的神經(jīng)網(wǎng)絡(luò)架構(gòu)。其中 MATLAB 會(huì)展示所有的操作層,每一層都給出了層級(jí)名、操作類(lèi)型和層級(jí)參數(shù)等關(guān)鍵信息。例如第二個(gè)操作層『conv1』表示一個(gè)卷積運(yùn)算,該運(yùn)算采用了 96 個(gè)卷積核,每一個(gè)卷積核的尺寸為 11×11×3、步幅為 4,該卷積運(yùn)算采用了 padding。

這種描述不僅有利于我們了解整個(gè)神經(jīng)網(wǎng)絡(luò)的架構(gòu),同時(shí)還有助于調(diào)整架構(gòu)以匹配特定的任務(wù)。由上可知最后的全連接層、softmax 層和分類(lèi)輸出層是與 ImageNet 任務(wù)相關(guān)聯(lián)的配置,因此我們需要去除這三個(gè)層級(jí)并重新構(gòu)建與當(dāng)前任務(wù)相關(guān)聯(lián)的層級(jí)。MATLAB 可以十分簡(jiǎn)潔地實(shí)現(xiàn)這一過(guò)程:
layersTransfer?
=
?net
.
Layers
(
1
:
end
-
3
);
numClasses?
=
?numel
(
categories
(
trainingImages
.
Labels
))
layers?
=
?
[
?layersTransfer
?fullyConnectedLayer
(
numClasses
,
"WeightLearnRateFactor"
,
20
,
"BiasLearnRateFactor"
,
20
)
?softmaxLayer
?classificationLayer
];
由上面的代碼可知我們只提取了 AlexNet 預(yù)訓(xùn)練模型的前 22 層,而后依次新建了全連接層、softmax 層和分類(lèi)輸出層。完成整個(gè)層級(jí)重構(gòu)后,剩下的就只需使用以下代碼訓(xùn)練新的模型。其中 trainingImages 為當(dāng)前任務(wù)的訓(xùn)練樣本、layers 為前面修正的層級(jí),而 options 是我們?cè)O(shè)置的一組訓(xùn)練參數(shù),包括優(yōu)化算法、最小批量大小、初始化學(xué)習(xí)率、繪制訓(xùn)練過(guò)程和驗(yàn)證集配置等設(shè)定。
netTransfer?
=
?trainNetwork
(
trainingImages
,
layers
,
options
);
由上,我們發(fā)現(xiàn) MATLAB 的深度學(xué)習(xí)代碼非常簡(jiǎn)潔,調(diào)用高級(jí) API 能快速完成模型的搭建。陳建平說(shuō):「MATLAB 上的高級(jí) API 是一個(gè)完整的體系,它們完全是針對(duì)深度學(xué)習(xí)而設(shè)計(jì)的。當(dāng)然我們還是會(huì)用基礎(chǔ)的運(yùn)算,因?yàn)?MATLAB 這么多年的累積可以充分體現(xiàn)在基礎(chǔ)運(yùn)算上,但是深度學(xué)習(xí)這一套高級(jí) API 確實(shí)是新設(shè)計(jì)的。」
其實(shí)不只是 AlexNet,很多 Caffe 模型都能夠?qū)氲?MATLAB。那么,MATLAB 為什么會(huì)選擇 Caffe 作為對(duì)接的深度學(xué)習(xí)框架,而不是近來(lái)十分流行的 TensorFlow?
陳建平解釋說(shuō):「MATLAB 選擇 Caffe 其實(shí)是有很多歷史原因的,因?yàn)?Caffe 在 CNN 上做得非常好,傳統(tǒng)上它在圖像方面就是一個(gè)非常優(yōu)秀的框架,從這個(gè)角度我們優(yōu)先選擇了 Caffe 作為支持的深度學(xué)習(xí)框架。當(dāng)然,MATLAB 在很快也會(huì)有針對(duì) TensorFlow 的導(dǎo)入功能。」
訓(xùn)練與推斷
對(duì)于模型訓(xùn)練來(lái)說(shuō),最重要的可能就是能支持大規(guī)模分布式訓(xùn)練。因?yàn)槟壳暗纳疃饶P投加蟹浅6嗟膮?shù)和層級(jí),每一次正向或反向傳播都擁有海量的矩陣運(yùn)算,所以這就要求 MATLAB 能高效地執(zhí)行并行運(yùn)算。當(dāng)然,我們知道 MATLAB 在并行運(yùn)算上有十分雄厚的累積,那么在硬件支持上,目前其支持 CPU 和 GPU 之間的自動(dòng)選擇、單塊 GPU、本地或計(jì)算機(jī)集群上的多塊 GPU。此外,由于近來(lái)采用大批量 SGD 進(jìn)行分布式訓(xùn)練的方法取得了十分優(yōu)秀的結(jié)果,我們可以使用 MATLAB 調(diào)用整個(gè)計(jì)算機(jī)集群上的 GPU,并使用層級(jí)對(duì)應(yīng)的適應(yīng)率縮放(Layer-wise Adaptive Rate Scaling/LARS)那樣的技術(shù)快速完成整個(gè)模型的訓(xùn)練。
在模型訓(xùn)練中,另外一個(gè)比較重要的部分就是可視化,我們需要可視化整個(gè)訓(xùn)練過(guò)程中的模型準(zhǔn)確度、訓(xùn)練損失、驗(yàn)證損失、收斂情況等信息。當(dāng)然 MATLAB 一直以來(lái)就十分重視可視化,在上例執(zhí)行遷移學(xué)習(xí)時(shí),我們也能得到整個(gè)訓(xùn)練過(guò)程的可視化信息。如下所示,上部分為訓(xùn)練準(zhǔn)確度和驗(yàn)證準(zhǔn)確度隨迭代數(shù)的變化趨勢(shì),下部分為訓(xùn)練損失和驗(yàn)證損失隨迭代數(shù)的變化趨勢(shì),該遷移學(xué)習(xí)基本上到第 3 個(gè) epoch 就已經(jīng)收斂。
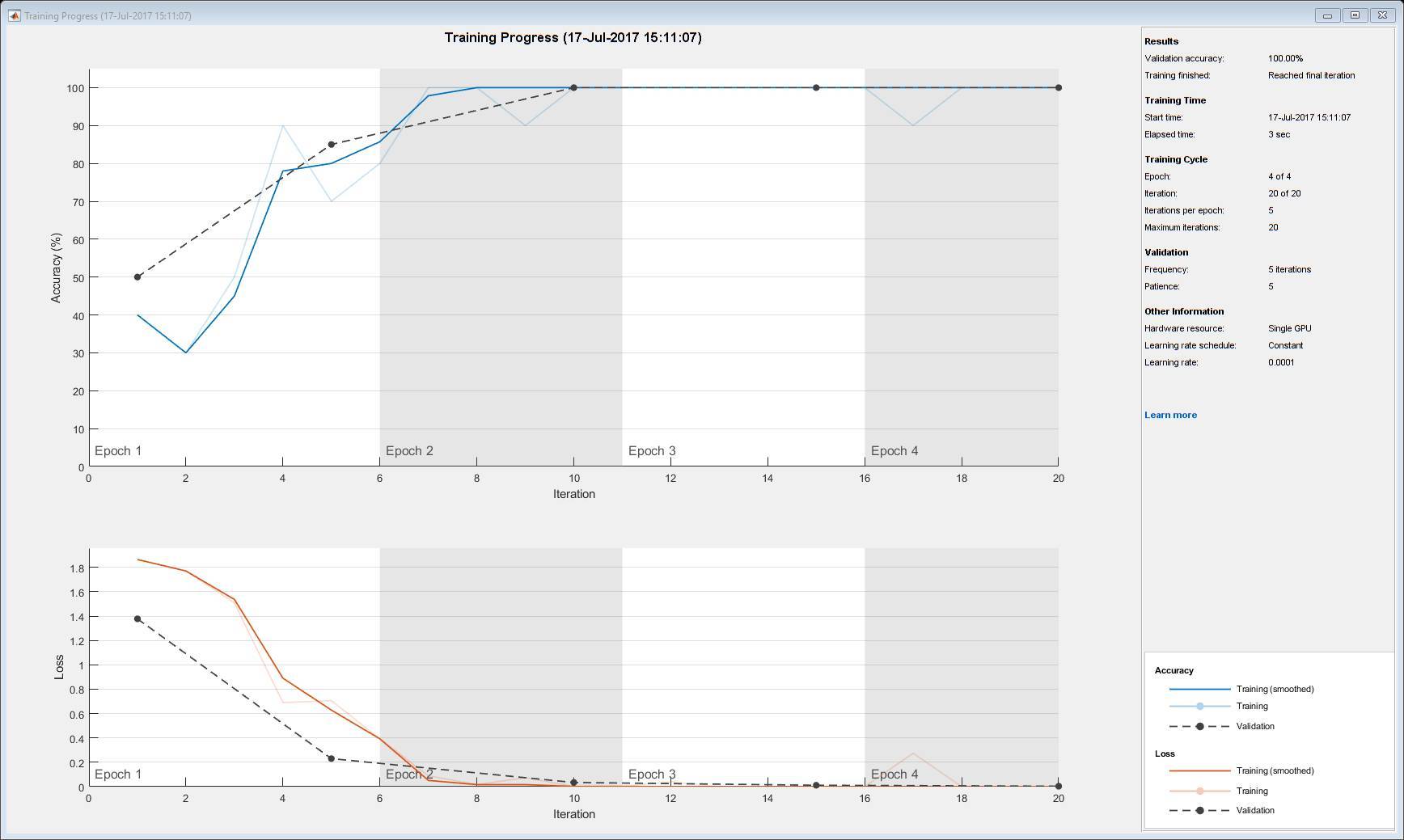
陳建平說(shuō):「訓(xùn)練是十分重要的,尤其是對(duì)關(guān)注算法本身的研究者。但如果我們考慮模型部署,那么也許推斷會(huì)變得更加重要。」
對(duì)于推斷來(lái)說(shuō),新產(chǎn)品 GPU Coder 可自動(dòng)將深度學(xué)習(xí)模型轉(zhuǎn)換為 NVIDIA GPU 的 CUDA 代碼。內(nèi)部基準(zhǔn)測(cè)試顯示,GPU Coder 產(chǎn)生的 CUDA 代碼,比 TensorFlow 的性能提高 7 倍,比 Caffe2 的性能提高 4.5 倍。
陳建平說(shuō):「其實(shí)我們將 MATLAB 和其它框架做了一些基準(zhǔn)對(duì)比,MATLAB 在測(cè)試中比 TensorFlow 快 2.5 倍,比 Caffe 快 40% 左右。而我們還有一種方法讓模型的推斷速度變得更快,也就是使用 GPU Coder 將模型轉(zhuǎn)化為脫離 MATLAB 環(huán)境的 CUDA 代碼。我們已經(jīng)在一臺(tái) GPU 工作站上測(cè)試 GPU Coder 的效果,基本上它要比 TensorFlow 的性能高 7 倍,比 Caffe2 的性能高 4.5 倍。實(shí)際上在轉(zhuǎn)換代碼時(shí)我們剔除了很多額外的交互過(guò)程。其實(shí) GPU Coder 對(duì)產(chǎn)品部署是十分有用的,因?yàn)?CUDA 代碼對(duì)需要考慮很多限制的嵌入式系統(tǒng)十分重要,例如 CUDA 代碼能高效地控制嵌入式系統(tǒng)的功耗。」
下圖展示了內(nèi)部基準(zhǔn)測(cè)試的結(jié)果:

該測(cè)試使用 TitanXP GPU 和 Intel(R) Xeon(R) CPU E5-1650 v4 @ 3.60GHz 對(duì) AlexNet 的推斷性能進(jìn)行了內(nèi)部基準(zhǔn)測(cè)試。使用的軟件版本或框架是 MATLAB(R2017b)、TensorFlow(1.2.0) 和 Caffe2(0.8.1)。每個(gè)軟件或框架都是使用 GPU 加速版來(lái)進(jìn)行基準(zhǔn)測(cè)試,所有測(cè)試均在 Windows 10 上運(yùn)行。
模型部署
在 MATLAB 部署模型其實(shí)也很簡(jiǎn)單,MATLAB 很早就支持生成獨(dú)立于其開(kāi)發(fā)環(huán)境的其它語(yǔ)言,比如利用 MATLAB Coder 可以將 MATLAB 代碼轉(zhuǎn)換為 C 或 C++代碼。而該版提供了新的工具 GPU Coder,我們能利用它將生成的 CUDA 代碼部署到 GPU 中并進(jìn)行實(shí)時(shí)處理,這一點(diǎn)對(duì)于應(yīng)用場(chǎng)景是極其重要的。

GPU 代碼生成其實(shí)在 MATLAB 中也十分簡(jiǎn)單,陳建平不僅利用車(chē)道線識(shí)別模型向我們演示了如何使用 GPU Coder 生成高效的 CUDA 代碼,同時(shí)還展示了在脫離 MATLAB 環(huán)境下運(yùn)行 CUDA 代碼進(jìn)行推斷的效果。
陳建平說(shuō):「本質(zhì)上車(chē)道線識(shí)別模型是通過(guò)遷移學(xué)習(xí)完成的,只不過(guò)在模型訓(xùn)練完成后,我們既不會(huì)直接在 CPU 上運(yùn)行模型并執(zhí)行推斷,也不會(huì)單純地通過(guò) MATLAB 環(huán)境編譯推斷過(guò)程。因此我們可以通過(guò) GPU Coder 和幾行語(yǔ)句基于已訓(xùn)練的模型來(lái)產(chǎn)生 CUDA 代碼。我們需要告訴 GPU Coder 各種信息,例如我們需要產(chǎn)生的外接包裝是 C++、目標(biāo)是產(chǎn)生一個(gè) CUDA 庫(kù)文件等。因?yàn)?C++ 需要定義嚴(yán)格的數(shù)據(jù)類(lèi)型,所以在我們輸入?yún)?shù)的信息后,Coder 會(huì)遞歸地推導(dǎo)輸入所涉及的所有數(shù)據(jù)類(lèi)型。最后 GPU Coder 會(huì)根據(jù)這些信息產(chǎn)生 CUDA 代碼。」
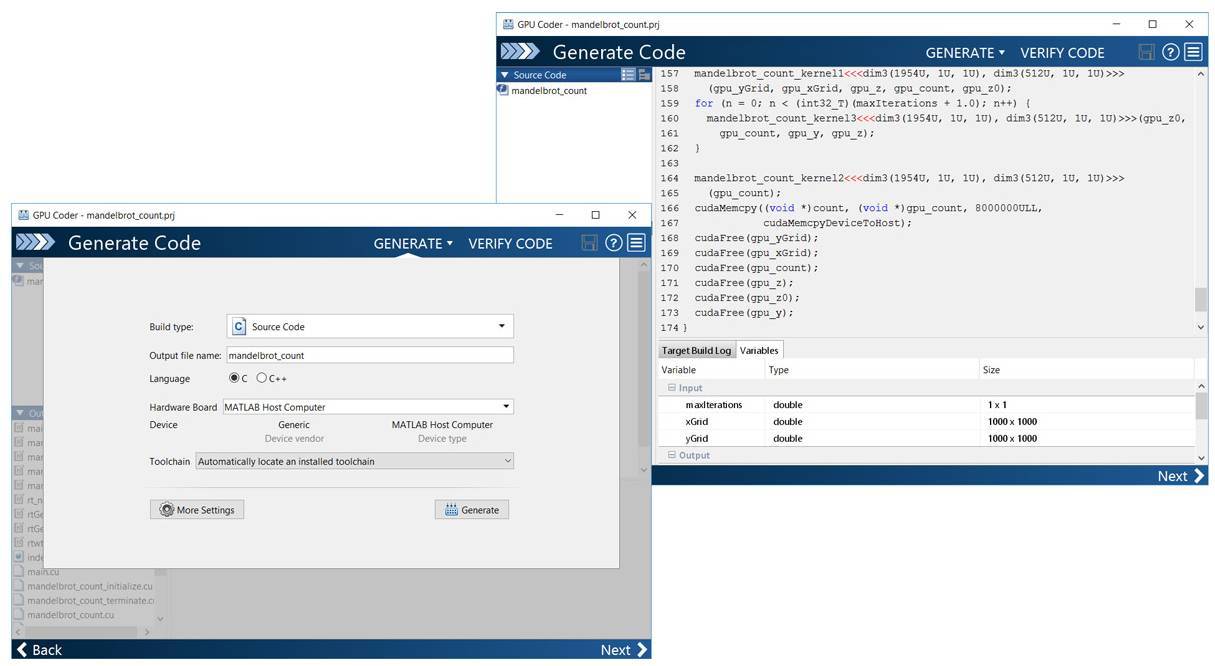
左圖為GPU Coder app,右圖展示了生成的CUDA代碼
如果 GPU Coder 能將模型轉(zhuǎn)化為 CUDA 代碼,那么它到底是如何將一個(gè)串行設(shè)計(jì)的模型轉(zhuǎn)換為并行的 CUDA 代碼?
陳建平解釋說(shuō):「推斷過(guò)程本質(zhì)上是一個(gè)并行過(guò)程,而推斷的每一步我們可以認(rèn)為是一個(gè)獨(dú)立循環(huán)體。而現(xiàn)在我們有辦法將這種獨(dú)立循環(huán)體展開(kāi)成大量的 CUDA 并發(fā)線程,這一過(guò)程都是自動(dòng)完成的。其實(shí) MATLAB 有工具能判斷 For 循環(huán)是不是獨(dú)立的,如果是的話它就會(huì)將這些 For 循環(huán)自動(dòng)并行化。所以 CUDA 其實(shí)就是一種超多線程的并發(fā)模型,而只有這種并行化才能充分利用 GPU 的計(jì)算資源以加快推斷速度。」
最后,MATLAB 會(huì)自動(dòng)完成代碼的并行化,并轉(zhuǎn)化為高效的 CUDA 代碼,因此我們能脫離 MATLAB 環(huán)境來(lái)執(zhí)行整個(gè)推斷過(guò)程。
結(jié)語(yǔ)
從數(shù)據(jù)源、模型構(gòu)建、訓(xùn)練與推斷到最終產(chǎn)品的部署,R2017B 補(bǔ)齊了整個(gè)開(kāi)發(fā)鏈條。MathWorks 的 MATLAB 市場(chǎng)營(yíng)銷(xiāo)總監(jiān) David Rich 表示,「借助 R2017b,工程和系統(tǒng)集成團(tuán)隊(duì)可以將 MATLAB 拓展用于深度學(xué)習(xí),以更好地保持對(duì)整個(gè)設(shè)計(jì)過(guò)程的控制,并更快地實(shí)現(xiàn)更高質(zhì)量的設(shè)計(jì)。他們可以使用預(yù)訓(xùn)練網(wǎng)絡(luò),協(xié)作開(kāi)發(fā)代碼和模型,然后部署到 GPU 和嵌入式設(shè)備。使用 MATLAB 可以改進(jìn)結(jié)果質(zhì)量,同時(shí)通過(guò)自動(dòng)化地真值標(biāo)注 App 來(lái)縮短模型開(kāi)發(fā)時(shí)間。」
歡迎加入本站公開(kāi)興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉(cāng)庫(kù),數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識(shí)
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請(qǐng)注明本文地址:http://specialneedsforspecialkids.com/yun/4646.html
摘要:此發(fā)行版還添加了新的重要的深度學(xué)習(xí)功能,可簡(jiǎn)化工程師研究人員及其他領(lǐng)域?qū)<以O(shè)計(jì)訓(xùn)練和部署模型的方式。內(nèi)部基準(zhǔn)測(cè)試顯示,在部署階段為深度學(xué)習(xí)模型產(chǎn)生的代碼,比的性能提高倍,比的性能提高倍。 MATLAB Release 2017b (R2017b) 今日正式推出,其中包括 MATLAB 和 Simulink 的若干新功能、六款新產(chǎn)品以及對(duì)其他 86 款產(chǎn)品的更新和修復(fù)補(bǔ)丁。此發(fā)行版還添加了新的...
摘要:完整版地址我們的想法是創(chuàng)建一個(gè)深度學(xué)習(xí)框架的羅塞塔石碑假設(shè)你很了解某個(gè)深度學(xué)習(xí)框架,你就可以幫助別人使用任何框架。我們的目標(biāo)是創(chuàng)建深度學(xué)習(xí)框架的羅塞塔石碑,使數(shù)據(jù)科學(xué)家能夠在不同框架之間輕松運(yùn)用專(zhuān)業(yè)知識(shí)。 repo 1.0 完整版 GitHub 地址:https://github.com/ilkarman/DeepLearningFrameworks我們的想法是創(chuàng)建一個(gè)深度學(xué)習(xí)框架的羅塞塔石...
摘要:值得一提的是,基于百度自研的開(kāi)源深度學(xué)習(xí)平臺(tái)的實(shí)現(xiàn),參考了論文,增加了,等處理,精度相比于原作者的實(shí)現(xiàn)提高了個(gè)絕對(duì)百分點(diǎn),在此基礎(chǔ)上加入最終精度相比原作者提高個(gè)絕對(duì)百分點(diǎn)。 YOLO作為目標(biāo)檢測(cè)領(lǐng)域的創(chuàng)新技術(shù),一經(jīng)推出就受到開(kāi)發(fā)者的廣泛關(guān)注。值得一提的是,基于百度自研的開(kāi)源深度學(xué)習(xí)平臺(tái)PaddlePaddle的YOLO v3實(shí)現(xiàn),參考了論文【Bag of Tricks for Imag...
摘要:本報(bào)告面向的讀者是想要進(jìn)入機(jī)器學(xué)習(xí)領(lǐng)域的學(xué)生和正在尋找新框架的專(zhuān)家。其輸入需要重塑為包含個(gè)元素的一維向量以滿足神經(jīng)網(wǎng)絡(luò)。卷積神經(jīng)網(wǎng)絡(luò)目前代表著用于圖像分類(lèi)任務(wù)的較先進(jìn)算法,并構(gòu)成了深度學(xué)習(xí)中的主要架構(gòu)。 初學(xué)者在學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)的時(shí)候往往會(huì)有不知道從何處入手的困難,甚至可能不知道選擇什么工具入手才合適。近日,來(lái)自意大利的四位研究者發(fā)布了一篇題為《神經(jīng)網(wǎng)絡(luò)初學(xué)者:在 MATLAB、Torch 和 ...

閱讀 2561·2023-04-25 18:13
閱讀 768·2021-11-22 12:10
閱讀 2968·2021-11-22 11:57
閱讀 2137·2021-11-19 11:26
閱讀 2163·2021-09-22 15:40
閱讀 1460·2021-09-03 10:28
閱讀 2703·2019-08-30 15:53
閱讀 1949·2019-08-30 15:44





