資訊專欄INFORMATION COLUMN

摘要:本文介紹支付寶中的深度學習引擎。因而無論在運行速度和內(nèi)存占用等性能指標還是在兼容性上,支付寶的移動端都必須做到極致,才能較大幅度地降低使用門檻。五大目標支付寶是針對國民環(huán)境定制開發(fā)的移動端解決方案,項目制定了如下技術(shù)目標。
本文介紹支付寶App中的深度學習引擎——xNN。xNN通過模型和計算框架兩個方面的優(yōu)化,解決了深度學習在移動端落地的一系列問題。xNN的模型壓縮工具 (xqueeze) 在業(yè)務(wù)模型上實現(xiàn)了近50倍的壓縮比, 使得在包預算極為有限的移動App中大規(guī)模部署深度學習算法成為可能。xNN的計算性能經(jīng)過算法和指令兩個層面的深度優(yōu)化,極大地降低了移動端DL的機型門檻。 ??

深度學習——云端還是移動端?
近來,深度學習(DL)在圖像識別、語音識別、自然語言處理等諸多領(lǐng)域都取得了突破性進展。DL通常給人以計算復雜、模型龐大的印象——從Siri語音助手到各種聊天機器人、再到支付寶“掃五福”,移動端收集數(shù)據(jù)+云端加工處理似乎成為一種常識。然而對很多應(yīng)用來說,這種模式其實只是無奈之選。

去年春節(jié)的“掃五福”活動中,為了識別手寫“福”字,支付寶多媒體團隊調(diào)動了近千臺服務(wù)器用于部署圖像識別模型。可是如此規(guī)模的集群也沒能抵擋住全國人民集五福的萬丈熱情。為了防止云端計算能力超載,活動中后期不得不啟動了降級預案——用計算量小但精度也較低的傳統(tǒng)視覺算法替代了DL模型。降級雖然不妨礙大伙繼續(xù)熱火朝天地收集福卡,但對用戶體驗無疑是有一定影響的,比如一些不可言說的漢字也被誤判成了“福”字。

另一方面,DL在云端則意味著數(shù)據(jù)必須上傳。即使不考慮計算壓力,從網(wǎng)絡(luò)延時、流量、隱私保護等角度也給用戶體驗帶來種種限制。因此,對相當多的應(yīng)用來說,DL模型前移到移動端部署可以看作是一種剛需。
兩大挑戰(zhàn)
最近,隨著手機處理器性能的提升和模型輕量化技術(shù)的發(fā)展,移動端DL正在變得越來越可行,并得到了廣泛的關(guān)注。蘋果和谷歌已經(jīng)分別宣布了各自操作系統(tǒng)上的DL框架Core ML和Tensorflow Lite,這無疑將極大地促進移動端DL的發(fā)展。但是,尤其對于支付寶這樣的國民App來說,仍然存在一些嚴峻的挑戰(zhàn)是無法通過直接套用廠商方案來解決的。
1. 機型跨度大:支付寶App擁有數(shù)億受眾群體,在其中落地的業(yè)務(wù)必須對盡可能多的用戶、盡可能多的機型提供優(yōu)質(zhì)的體驗。對支付寶來說,參考Core ML只將功能開放給少數(shù)高端機型的做法是不合適的。因而無論在運行速度和內(nèi)存占用等性能指標、還是在兼容性上,支付寶的移動端DL都必須做到極致,才能較大幅度地降低使用門檻。
2. 包尺寸要求嚴:支付寶App集成了眾多的業(yè)務(wù)功能,安裝包資源非常緊張,一個新模型要集成進安裝包往往意味著需要下線其他的功能。而即便通過動態(tài)下發(fā)的形式進行部署,DL模型的大小也會強烈影響用戶的體驗。隨著移動端智能化程度的不斷提升,直接在端上運行的DL應(yīng)用必然會越來越多,這以當前單個模型大小就動輒數(shù)十、數(shù)百M的尺寸來看幾乎是不可想象的。同時,移動端DL引擎本身的SDK也需要盡可能地瘦身。
五大目標
支付寶xNN是針對國民App環(huán)境定制開發(fā)的移動端DL解決方案,項目制定了如下技術(shù)目標。
1. 輕模型:通過高效的模型壓縮算法,在保證算法精度的前提下大幅減小模型尺寸。
2. 小引擎:移動端SDK的深度裁減。
3. 快速:結(jié)合指令層和算法層的優(yōu)化,綜合提升DL計算的效率。
4. 通用:為保證較大的機型覆蓋率,以更為通用的CPU而非性能更強勁的GPU作為重點優(yōu)化平臺。不僅支持經(jīng)典的CNN、DNN網(wǎng)絡(luò),也支持RNN、LSTM等網(wǎng)絡(luò)形態(tài)。
5. 易用:工具鏈對業(yè)務(wù)保持高度友好——使得算法工程師們能更好地專注于算法本身,在不需要成為模型壓縮專家和移動端開發(fā)專家的情況下都能快速完成云端模型到移動端模型的轉(zhuǎn)換和部署。
主要特性一覽
xNN為DL模型提供了從壓縮到部署、再到運行時的統(tǒng)計監(jiān)控這一全生命周期的解決方案。xNN環(huán)境由開發(fā)后臺和部署前臺兩部分組成。
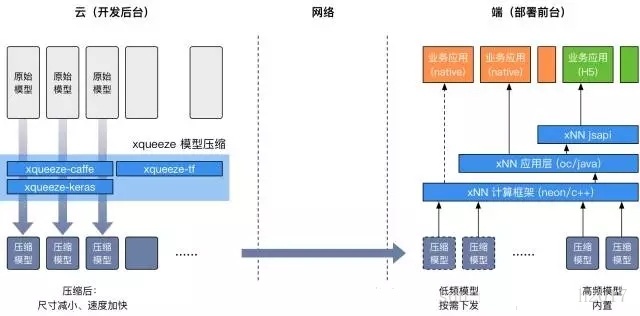
開發(fā)后臺以xqueeze工具鏈為核心,支持多種訓練框架。業(yè)務(wù)可以使用xqueeze壓縮、優(yōu)化自己的DL模型,得到尺寸大幅減小、運行速度顯著加快的模型版本。壓縮后的模型根據(jù)使用場景,可以通過App安裝包內(nèi)置或按需下發(fā)的形式部署到移動端。
在部署前臺,xNN的計算框架提供高效的前向預測能力。xNN的應(yīng)用層在計算的基礎(chǔ)上還提供了模型下發(fā)、數(shù)據(jù)統(tǒng)計、錯誤上報等一站式能力。xNN還通過一個jsapi提供了直接對接H5應(yīng)用的能力——通過DL模型的動態(tài)下發(fā)和H5,能夠?qū)崿F(xiàn)完全的動態(tài)化,從而在客戶端不發(fā)版的情況下完成算法+邏輯的同時更新。
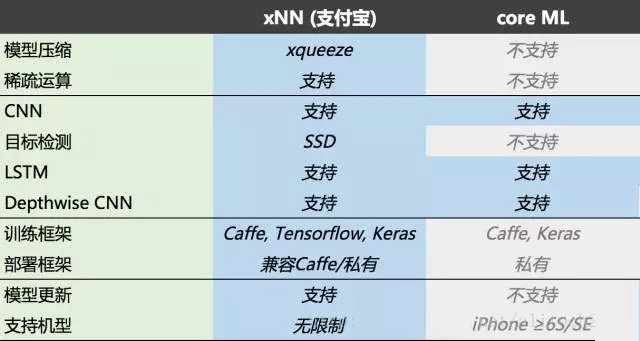
上圖給出了xNN的主要特性。在xqueeze模型壓縮的基礎(chǔ)上,xNN還支持通過快速處理稀疏網(wǎng)絡(luò)來提高性能。xNN支持了豐富的網(wǎng)絡(luò)結(jié)構(gòu)類型,包括經(jīng)典CNN/DNN、SSD目標檢測和LSTM。xNN的部署框架原生兼容Caffe,業(yè)務(wù)可以在不做轉(zhuǎn)換的情況下直接在移動端運行已有的Caffe模型,以快速評估效果。而經(jīng)過壓縮的私有格式模型更小、更快。在Tensorflow和Keras平臺上訓練的模型也能夠在原有的環(huán)境上進行壓縮,然后轉(zhuǎn)換為xNN支持的格式部署到移動端。不同于core ML,xNN理論上支持安卓和iOS上的所有機型。
xqueeze模型壓縮
xNN-xqueeze的模型壓縮流程如下圖之(a)所示,包括神經(jīng)元剪枝 (neuron pruning)、突觸剪枝 (synapse pruning)、量化 (quantization)、網(wǎng)絡(luò)結(jié)構(gòu)變換 (network transform)、自適應(yīng)Huffman編碼 (adaptive Huffman)、共5個步驟。其中前三步理論上是有損的,而使用xqueeze對網(wǎng)絡(luò)權(quán)重和壓縮超參進行finetune,能夠?qū)⒕鹊南陆当3衷诳煽厣踔量珊雎缘某潭取:髢刹絼t完全不影響網(wǎng)絡(luò)的輸出精度。整個流程不僅會減小模型的尺寸,還通過網(wǎng)絡(luò)的稀疏化和結(jié)構(gòu)優(yōu)化,顯著提高前向預測的速度。
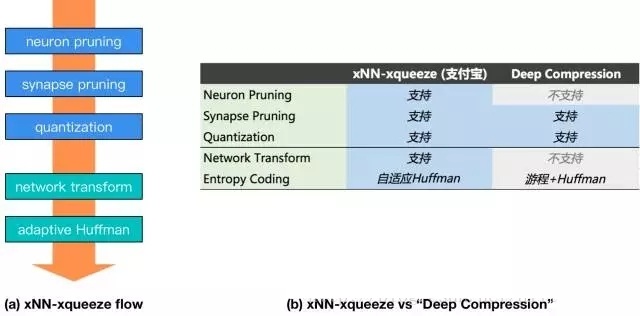
在領(lǐng)域的經(jīng)典方案DeepCompression的基礎(chǔ)上,xqueeze 進一步擴充了neuronpruning和network transform的能力。其中,neuron pruning能夠逐次裁剪掉“不重要”的神經(jīng)元和與之對應(yīng)的權(quán)重參數(shù)。通過neuron pruning和synapse pruning的結(jié)合,在模型精度和壓縮比之間達成更好的平衡。xqueeze還具有network transform——在網(wǎng)絡(luò)的宏觀層面進行優(yōu)化的能力,networktransform腳本掃描整個網(wǎng)絡(luò),診斷出可優(yōu)化的點,包括在有條件的情況下自動地進行層 (layer) 的組合與等效替換。此外,xqueeze通過自適應(yīng)地使用Huffman編碼,有效提升不同稀疏程度的模型之壓縮比。
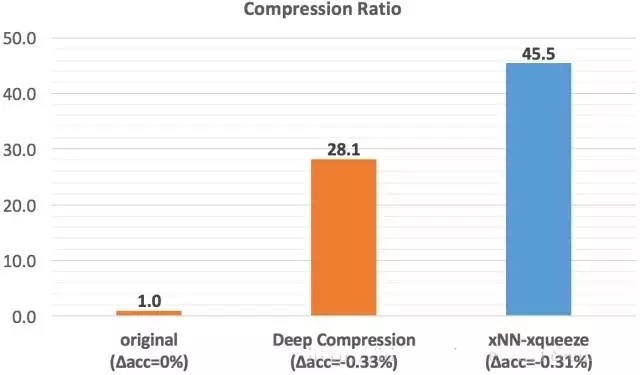
如下圖所示,對于業(yè)務(wù)分類模型,使用xqueeze工具鏈能夠?qū)崿F(xiàn)45.5倍的壓縮,在同等程度的精度損失下,壓縮率超越經(jīng)典方案達60%。
xNN計算性能優(yōu)化
xNN的性能優(yōu)化不局限于底層,而是通過與xqueeze工具鏈的配合,在算法和指令兩個層面同步發(fā)力,為更為深入的優(yōu)化創(chuàng)造空間。
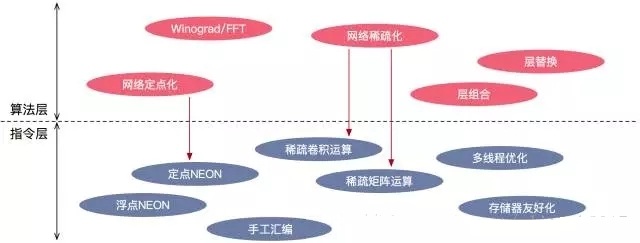
如下圖所示,在算法層,xqueeze的剪枝在壓縮模型尺寸的同時,也促進了網(wǎng)絡(luò)的稀疏化——即催生出大量的零值權(quán)重。相應(yīng)地,xNN在指令層實現(xiàn)了稀疏運算模塊,在卷積和全連接計算中,自動忽略這些零值權(quán)重,減小計算開銷,提升速度。又如之前已經(jīng)提到的,在xqueeze的network transform階段,會對網(wǎng)絡(luò)進行宏觀層面的優(yōu)化,包括將相鄰的層進行結(jié)果上等效的組合與替換,來減少計算的冗余度和提高訪問存儲器的效率。要充分發(fā)揮network transform的效能,也離不開指令層實現(xiàn)的支持。
在以SqueezeNet為基礎(chǔ)的業(yè)務(wù)分類模型上,xNN在Qualcomm 820 CPU上能夠輸出29.4 FPS的前向預測幀率,在蘋果A10 CPU (iPhone 7)上的幀率則達到52.6 FPS,比CPU與GPU并用的Core ML還要更快。
業(yè)務(wù)落地
支付寶App已經(jīng)集成了xNN。在支付寶的“AR掃一掃”入口,90%以上的Android和iOS機型都在使用xNN來完成前置物品分類,向用戶推薦“AR掃花識花”等便利功能。xNN本身的健壯性也經(jīng)受住了“七夕送你一朵花”這樣高強度、廣機型覆蓋的大型運營活動的考驗。該模型的版本在確保精度的前提下,尺寸已壓縮到100KB以下。Android平臺上,全功能xNN的SDK包增量僅200KB出頭,若根據(jù)特定應(yīng)用做裁剪,將能夠輕松減小到100多KB。
?
xNN上線后,已在螞蟻和阿里內(nèi)部引起了強烈反響,一大波移動端DL應(yīng)用正在基于xNN緊張開發(fā)中,并在未來的幾個月中逐步提供給用戶使用。歡迎加入本站公開興趣群
商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4645.html

閱讀 2185·2021-11-18 10:02
閱讀 3288·2021-11-11 16:55
閱讀 2694·2021-09-14 18:02
閱讀 2426·2021-09-04 16:41
閱讀 2054·2021-09-04 16:40
閱讀 1165·2019-08-30 15:56
閱讀 2212·2019-08-30 15:54
閱讀 3160·2019-08-30 14:15

