資訊專欄INFORMATION COLUMN

摘要:谷歌團隊還研究使用該模型進行噪聲輸入,其中以不同混合比例將兩個揚聲器的單聲道混合語音作為模型的輸入。結論在本文中,谷歌團隊引入了一種新的在線序列到序列模型的訓練方式,并將其應用于具有噪音輸入的環境。
近日谷歌團隊發布了一篇關于在線語音識別的序列到序列模型論文,雷鋒網了解到,該模型可以實現在線實時的語音識別功能,并且對來自不同揚聲器的聲音具有識別能力。
論文摘要
生成式模型一直是語音識別的主要方法。然而,這些模型的成功依賴于使用的精密的組合和復雜方法。最近,關于深入學習方面的研究已經產生了一種可以替代生成式模型的識別模型,稱為“序列到序列模型”。這種模型的準確性幾乎可以與較先進的生成模型相匹配。該模型在機器翻譯,語音識別,圖像標題生成等方面取得了相當大的經驗成果。由于這些模型可以在同一個步驟中端對端地進行培訓,因此該模型是非常易于訓練的,但它們在實踐中卻具有限制,即只能用于離線識別。這是因為該模型要求在一段話開始時就輸入序列的整體以供使用,然而這對實時語音識別等任務來說是沒有任何意義的。

圖. 1:本文使用的模型的總體架構
為了解決這個問題,谷歌團隊最近引入了在線序列模型。這種在線序列模型具有將產生的輸出作為輸入的 特性,同時還可以保留序列到序列模型的因果性質。這些模型具有在任何時間t產生的輸出將會影響隨后計算結果的特征。其中,有一種模型將使用二進制隨機變量來選擇產生輸出的時間步長。該團隊將這個模型稱為神經自回歸傳感器(NAT)。這個模型將使用策略梯度方法來訓練隨機變量。

圖. 2:熵正則化對排放位置的影響。 每行顯示為輸入示例的發射預測,每個符號表示3個輸入時間步長。 "x"表示模型選擇在時間步長發出輸出,而“ - ”則表示相反的情況。 頂線 - 沒有熵懲罰,模型在輸入的開始或結束時發出符號,并且無法獲得有意義的梯度來學習模型。 中線 – 使用熵正規化,該模型及時避免了聚類排放預測,并學習有意義地擴散排放和學習模型。 底線 - 使用KL發散規則排放概率,同時也可以緩解聚類問題,盡管不如熵正則化那樣有效。
通過使用估計目標序列相對于參數模型的對數概率的梯度來訓練該模型。 雖然這個模型并不是完全可以微分的,因為它使用的是不可微分的二進制隨機單元,但是可以通過使用策略梯度法來估計關于模型參數的梯度。更詳細地說,通過使用監督學習來訓練網絡進行正確的輸出預測,并使用加強學習以訓練網絡來決定何時發出各種輸出。
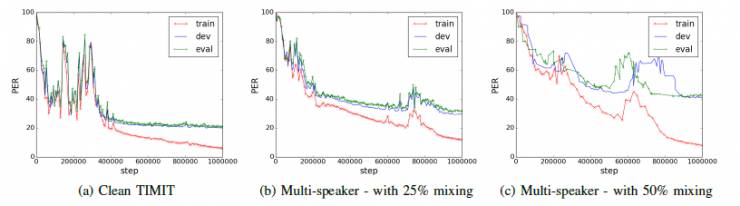
圖. 3:在TIMIT上運行示例培訓
圖3b和3c分別示出了混合比例分別為0.25和0.5的兩種情況的訓練曲線的實例。 在這兩種情況下,都可以看出,該模型學習了過適合數據。
谷歌團隊還研究使用該模型進行噪聲輸入,其中以不同混合比例將兩個揚聲器的單聲道混合語音作為模型的輸入。
實驗和結果
使用這個模型對兩種不同的語音語料庫進行了實驗。 第一組實驗是對TIMIT進行了初步實驗,以評估可能導致模型穩定行為的超參數。 第二組實驗是在不同混合比例下從兩個不同的揚聲器(一個男性和一個女性)混合的語音進行的。 這些實驗被稱為Multi-TIMIT。
A:TIMIT
TIMIT數據集是音素識別任務,其中必須從輸入音頻語音推斷音素序列。有關訓練曲線的示例,請參見圖3。 可以看出,在學習有意義的模型之前,該模型需要更多的更新(> 100K)。 然而,一旦學習開始,即使模型受到策略梯度的訓練,實現了穩定的過程。
表I顯示了通過這種方法與其他更成熟的模型對TIMIT實現的結果。 可以看出,該模型與其他單向模型比較,如CTC,DNN-HMM等。如果結合更復雜的功能,如卷積模型應該可以產生更好的結果。 此外,該模型具有吸收語言模型的能力,因此,應該比基于CTC和DNNHMM的模型更適合端到端的培訓,該模型不能固有地捕獲語言模型。

表I:針對各種模型使用單向LSTM的TIMIT結果
B:Multi-TIMIT
通過從原始TIMIT數據混合男性聲音和女性聲音來生成新的數據集。 原始TIMIT數據對中的每個發音都有來自相反性別的聲音。

表II:Multi-TIMIT的結果:該表顯示了該模型在不同比例的混合中為干擾語音所實現的音素誤差率(PER)。 還顯示了深層LSTM 和RNN-自感器 的CTC的結果
表II顯示了使用混合揚聲器的不同混合比例的結果。 可以看出,隨著混合比例的增加,模型的結果越來越糟糕。 對于實驗而言,每個音頻輸入始終與相同的混音音頻輸入配對。 有趣的是,可以發現,將相同的音頻與多個混淆的音頻輸入配對會產生更差的結果,這是由于產生了更為糟糕的過度配對。 這可能是因為該模型強大到足以復制整個轉錄的結果。
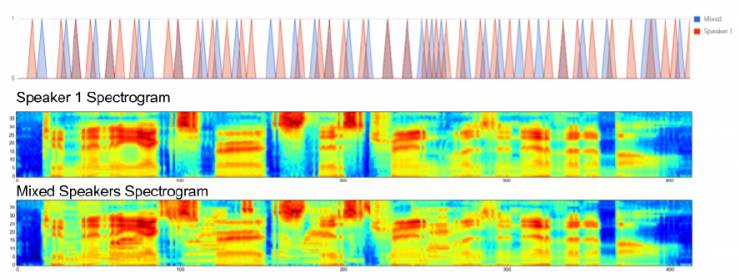
圖. 5:Multi-TIMIT的聲音分布:該圖顯示了在TIMIT中發出干凈話語的情況下發出令牌的概率以及Multi-TIMIT中對應的噪聲發音。 可以看出,對于Multi-TIMIT語句,該模型稍稍比TIMIT語句發出符號要晚一點。
圖5顯示為示例Multi-TIMIT話語的模型發出的符號。 并與一個干凈模型的發出進行比較。 一般來說,與TIMIT發出的模型相比,該模型選擇稍后再發布Multi-TIMIT。
結論
在本文中,谷歌團隊引入了一種新的在線序列到序列模型的訓練方式,并將其應用于具有噪音輸入的環境。 作為因果模型的結果,這些模型可以結合語言模型,并且還可以為相同的音頻輸入生成多個不同的 轉錄結果。 這使它成為一類非常強大的模型。 即使在與TIMIT一樣小的數據集上,該模型依然能夠適應混合語音。 從實驗分析的角度來說,每個揚聲器只耦合到一個干擾揚聲器,因此數據集的大小是有限的。 通過將每個揚聲器與多個其他揚聲器配對,并將每個揚聲器預測為輸出,應該能夠實現更強的魯棒性。 由于這種能力,該團隊希望可以將這些模型應用到未來的多通道、多揚聲器識別中。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4582.html
摘要:目前較好的語音識別系統采用雙向長短時記憶網絡,,這種網絡能夠對語音的長時相關性進行建模,從而提高識別正確率。因而科大訊飛使用深度全序列卷積神經網絡來克服雙向的缺陷。 人工智能的應用中,語音識別在今年來取得顯著進步,不管是英文、中文或者其他語種,機器的語音識別準確率在不斷上升。其中,語音聽寫技術的發展更為迅速,目前已廣泛在語音輸入、語音搜索、語音助手等產品中得到應用并日臻成熟。但是,語音應用的...
摘要:文本谷歌神經機器翻譯去年,谷歌宣布上線的新模型,并詳細介紹了所使用的網絡架構循環神經網絡。目前唇讀的準確度已經超過了人類。在該技術的發展過程中,谷歌還給出了新的,它包含了大量的復雜案例。谷歌收集該數據集的目的是教神經網絡畫畫。 1. 文本1.1 谷歌神經機器翻譯去年,谷歌宣布上線 Google Translate 的新模型,并詳細介紹了所使用的網絡架構——循環神經網絡(RNN)。關鍵結果:與...
摘要:自從年深秋,他開始在上撰寫并公開分享他感興趣的機器學習論文。本文選取了上篇閱讀注釋的機器學習論文筆記。希望知名專家注釋的深度學習論文能使一些很復雜的概念更易于理解。主要講述的是奧德賽因為激怒了海神波賽多而招致災禍。 Hugo Larochelle博士是一名謝布克大學機器學習的教授,社交媒體研究科學家、知名的神經網絡研究人員以及深度學習狂熱愛好者。自從2015年深秋,他開始在arXiv上撰寫并...
摘要:在與李世石比賽期間,谷歌天才工程師在漢城校區做了一次關于智能計算機系統的大規模深度學習的演講。而這些任務完成后,谷歌已經開始進行下一項挑戰了。谷歌深度神經網絡小歷史谷歌大腦計劃于年啟動,聚焦于真正推動神經網絡科學能達到的較先進的技術。 在AlphaGo與李世石比賽期間,谷歌天才工程師Jeff Dean在Google Campus漢城校區做了一次關于智能計算機系統的大規模深度學習(Large-...

閱讀 1659·2021-11-23 10:07
閱讀 2652·2019-08-30 11:10
閱讀 2834·2019-08-29 17:08
閱讀 1777·2019-08-29 15:42
閱讀 3162·2019-08-29 12:57
閱讀 2395·2019-08-28 18:06
閱讀 3544·2019-08-27 10:56
閱讀 382·2019-08-26 11:33





