資訊專欄INFORMATION COLUMN

摘要:因為在每一時刻對過去的記憶信息和當前的輸入處理策略都是一致的,這在其他領域如自然語言處理,語音識別等問題不大,但并不適用于個性化推薦,一個用戶的聽歌點擊序列,有正負向之分。
在內容爆炸性增長的今天,個性化推薦發揮著越來越重要的作用,如何在海量的數據中幫助用戶找到感興趣的物品,成為大數據領域極具挑戰性的一項工作;另一方面,深度學習已經被證明在圖像處理,計算機視覺,自然語言處理等領域都取得了不俗的效果,但在個性化推薦領域,工程應用仍然相對空白。
本文是深度學習在個性化推薦實踐應用的第二篇,在第一篇中,我詳述了如何利用歷史沉淀數據挖掘用戶的隱藏特征,本文在上一篇的基礎上進行延伸,詳細分析如何利用LSTM,即長短時記憶網絡來進行序列式的推薦。
1、從RBM,RNN到LSTM:
根據用戶的長期歷史數據來挖掘隱特征是協同過濾常用的方法,典型的算法有基于神經網絡的受限玻爾茲曼機 (RBM),基于矩陣分解的隱語義模型等。歷史的數據反映了用戶的長期興趣,但在很多推薦場景下,我們發現推薦更多的是短時間內的一連串點擊行為,例如在音樂的聽歌場景中,用戶的聽歌時間往往比較分散,有可能一個月,甚至更長的時間間隔才會使用一次,但每一次使用都會產生一連串的點擊序列,并且在諸如音樂等推薦領域中,受環境心情的影響因素很大,因此,在這種推薦場景下,基于用戶的短期會話行為(session-based) 能夠更好的捕獲用戶當前的情感變化。
另一方面,通過用戶的反饋,我們也不難發現,用戶的序列點擊行為并不是孤立的,當前的點擊行為往往是受到之前的結果影響,同理,當前的反饋也能夠影響到今后的決策,長期歷史數據的隱特征挖掘無法滿足這些需求。
RNN是解決序列性相關問題的常用網絡模型,通過展開操作,可以從理論上把網絡模型擴展為無限維,也就是無限的序列空間,如下圖所示:

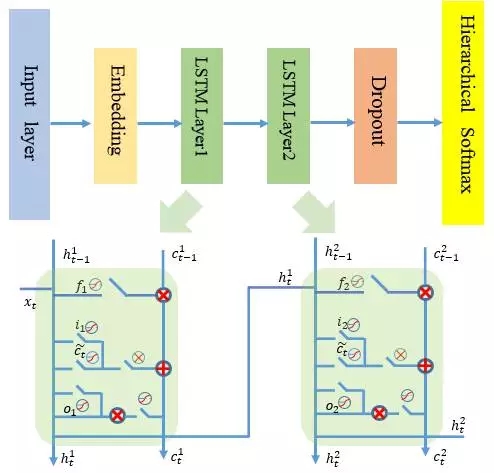
與CNN的參數共享原理一樣,RNN網絡在每一時刻也會共享相同的網絡權重參數,這時因為網絡在時間序列的不同時刻執行的是相同任務。在實際建模中,每一階段的網絡結構由輸入層,embedding層,1到多個LSTM層(可以選擇dropout)和層次softmax輸出層構成,如下圖所示,每一部分的設計思路將在后面詳細講述。
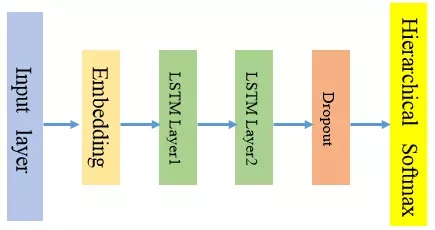
2、三“門”狀態邏輯設計
從理論的角度來分析,傳統的RNN采用BPTT (Backpropagation Through Time)來進行梯度求導,對V的求導較為簡單直接,但對W和U的求導會導致梯度消失(Vanishing Gradients)問題,梯度消失的直接后果是無法獲取過去的長時間依賴信息。
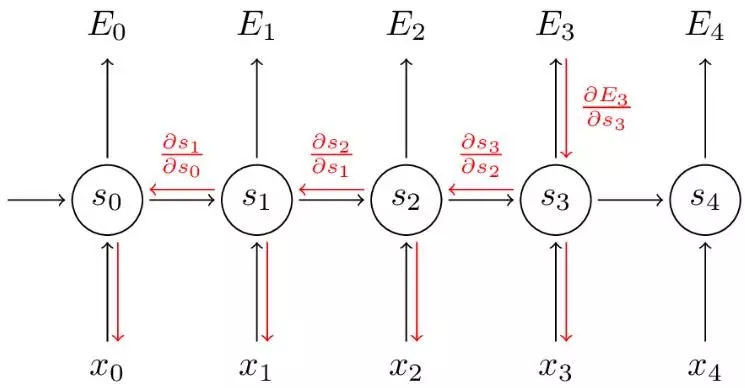
從個性化推薦的角度來看,傳統的RNN還有另外一個缺點。因為RNN在每一時刻對過去的記憶信息和當前的輸入處理策略都是一致的,這在其他領域(如自然語言處理,語音識別等)問題不大,但并不適用于個性化推薦,一個用戶的聽歌點擊序列,有正負向之分。正向的數據,包括諸如聽歌時長較長的歌曲,收藏,下載等;負向的聽歌,包括了跳過,刪除等,因此,在每一時刻的訓練,需要對當前的輸入數據有所區分,如果當前時刻是正向的歌曲,應該能夠對后面的推薦策略影響較大,相反,如果當前時刻是負向的歌曲,應該對后面的策略影響小,或者后面的推薦策略應該避免類似的歌曲出現。
LSTM (長短時記憶網絡)是對傳統RNN的改進,通過引入cell state來保留過去的記憶信息,避免BPTT導致的梯度消失問題,同時,針對前面提到的個性化推薦的獨有特點,我們對長短時記憶網絡也進行了修改,下面來詳細分析如何在個性化推薦中設計合理的門邏輯:
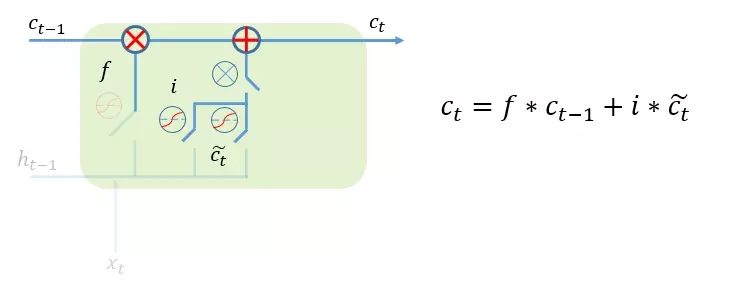
Forget gate (忘記門):這一步是首先決定要從前面的“記憶”中丟棄哪些信息或丟棄多少信息,比如,之前可能對某一位歌手或者某一個流派的歌曲特別感興趣,這種正向操作的記憶需要得到保留,并且能夠影響今后的決策。“門”開關通過sigmoid函數來實現,當函數值越接近于1時,表示當前時刻保留的記憶信息就越多,并把這些記憶帶到下一階段;當函數值接近于0時,表示當前時刻丟棄的記憶就越多。

Input gate(輸入門): 這一步由兩部分構成,第一部分是決定當前時刻的歌曲有多少信息會被加入到新的記憶中,如果是正向的歌曲,傳遞的信息就會越多,相反,對于負向歌曲,傳遞的信息就會越少。
第二部分是當前階段產生的真實數據信息,它是通過tanh函數把前面的記憶與當前的輸入相結合而得到。
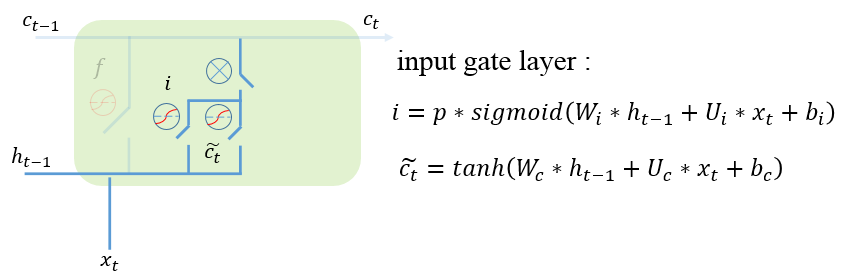
經過前面兩個門的設計,我們可以對cell state進行更新,把舊的記憶狀態通過與forget gate相結合,丟棄不需要的信息,把當前的輸入信息與input gate相結合,加入新的輸入數據信息,如下圖所示:
output gate (輸出門):這一步是把前面的記憶更新輸出,通過輸出門開關來控制記憶流向下一步的大小,確定哪些信息適合向后傳播。
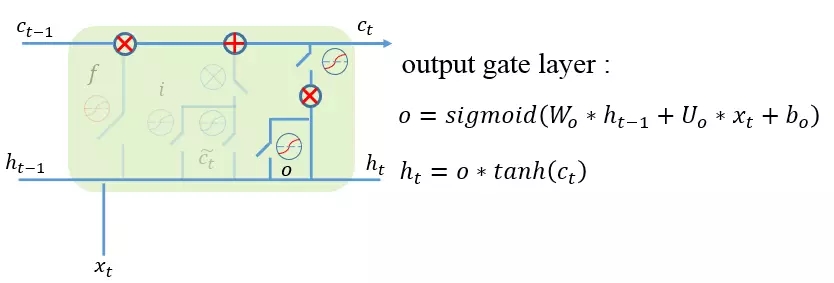
到此為止,序列中每一階段的門邏輯設計也完成了,最終的LSTM層設計如下圖所示:
小技巧:在代碼實現的時候,我們應該能夠發現上面提到的三個門運算和cell state的計算除了激活函數稍有不同外,它們具有下面的相同線性操作公式:

經過這樣的改造后,原來需要多帶帶執行四步的操作,現在只需要一次矩陣運算就能完成,這一技巧使得訓練速度提升非常明顯。
3、時序規整與并行化設計
普通的遞歸網絡(或者是其變種,LSTM,GRU等)每一次訓練會因為訓練數據間的序列長度不相等,需要多帶帶訓練,對于上億條的流水訓練數據來說,這種做法顯然是不可行的,為此我們需要對輸入數據做時序的補齊,具體來說就是把batch_size的訓練樣本集中起來,取點擊最長的序列長度作為矩陣的行數,其余樣本數據用0來補齊。
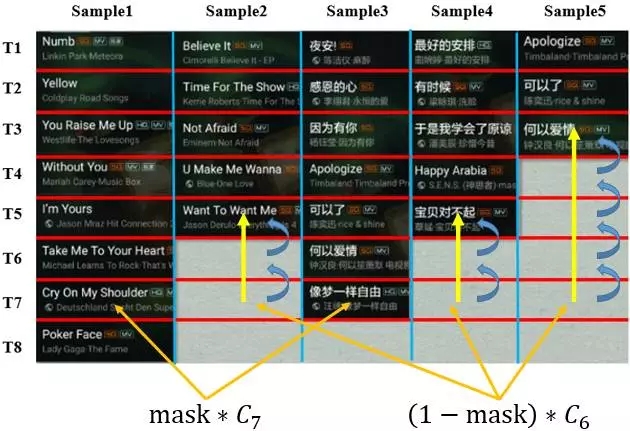
下面通過一個具體例子來形象的描述這個過程,下圖是從騰訊QQ音樂抽取的部分聽歌訓練樣本,為了便于理解,這里只選擇batch_size的大小為5,最長的點擊序列是8。

由訓練數據,我們得到對應的掩碼(mask)為:

掩碼的設計為我們解決了不同用戶聽歌序列不相同的問題,讓多個用戶的聽歌數據同時進行矩陣運算,但卻產生了另外一個問題,在每一次LSTM層訓練的時候,狀態遷移輸出和隱藏層結點輸出計算是全局考慮的,對于當前用0來padding的訓練樣本,理論上是不應該進行更新,如何解決這一個問題呢?
利用動態規劃的思想可以優雅的解決這個問題,當我們計算出當前階段的cell state和隱藏層結點輸出后,把當前的狀態輸出與前一個狀態輸出作線性的組合,具體來說,假如當前正在更新第T次點擊狀態。
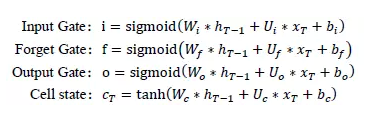
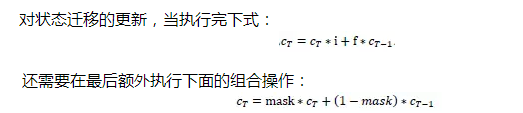
右式由兩部分構成,加號左邊,如果mask的值為1,更新當前狀態,加號右邊,如果mask為0,那么狀態退回到最后一個非0態。如下圖所示:當運行到T7時,對于sample1和sample3都是直接更新新數據,對于sample2,sample4和sample5則執行回溯。
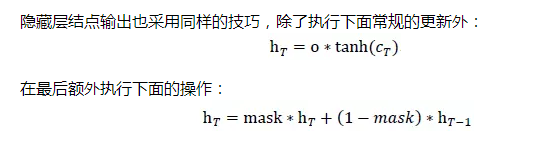
4、Dropout-深度學習正則化的利器
正則化是機器學習中常用來解決過擬合的技巧,在深度學習領域,神經網絡的參數更多,更深,結構也更復雜,而往往訓練樣本相對較少,過擬合的問題會更加嚴重。較為常見的正則化方法包括:對單模型,比如當驗證集的效果變化不明顯的時候我們可以提前終止迭代,或者采用L1正則化和L2正則化等;對多模型,我們可以利用boosting來集成提升,但在深度學習中,這種方法是不現實的,因為單個模型的訓練已經非常復雜耗時,并且即使訓練出多個網路模型,也難以在實際環境中做到快速集成。
Dropout結合了單模型和多模型的優點,是深度學習領域解決過擬合的強有力武器,前面提到,如果不考慮時間復雜度的前提下,可以通過訓練多個不同的網絡模型來集成提升效果,網路結構之間差別越大,提升效果也會越明顯,可以假設一個神經網絡中有n個不同神經元,那么相當于有2n個不同的網絡結構,如下圖所示:

Dropout的思想是每一迭代的過程中,我們會隨機讓網絡某些節點 (神經元) 不參與訓練,同時把與這些暫時丟棄的神經元(如下圖的黑色結點)相關的所有邊全部去掉,相應的權重不會在這一次的迭代中更新,每一次迭代訓練我們都重復這個操作。需要注意的是這些被丟棄的的神經元只是暫時不做更新,下一次還是會重新參與隨機化的dropout。

Hinton給出了dropout隨機化選擇的概率,對于隱藏層,一般取P=0.5,在大部分網絡模型中,能達到或接近最優的效果,而對于輸入層,被選中的概率要比被丟棄的概率要大,一般被選中的概率大約在P=0.8左右。在具體實現的時候,我并沒有對輸入層做dropout,在隱藏層取概率為0.5來進行正則化。
從理論角度來說,這個做法的巧妙之處在于,每一次的訓練,網絡都會丟棄部分的神經元,也就是相當于我們每一次迭代都在訓練不同的網絡結構,這樣同一個模型多次dropout迭代訓練便達到了多模型融合的效果。
Hinton在其論文中還對dropout給出了一種很有意思的生物學的解析,也就是為什么有性繁殖會比無性繁殖更能適應環境的變化,無性繁殖從母體中直接產生下一代,能保持母體的優良特性,不容易發生變異,但也因此造成了適應新環境能力差的缺點,而為了避免環境改變時物種可能面臨的滅亡(相當于過擬合),有性繁殖除了會分別吸收父體和母體的基因之外,還會為了適應新環境而進行一定的基因變異。
5、Hierarchical softmax輸出
最后的一個難點問題是推薦結果的輸出。對于常規的輸出層,一般是采用softmax函數建模,當輸出數據很少,比如只有幾千個候選數據,那么softmax的計算是很方便簡單的,但對于上百萬甚至上千萬的推薦數據,這種方法就會成為訓練效率的一個瓶頸。有什么好的方法可以解決這個問題呢?Hierarchical softmax是深度學習中解決高維度輸出的一個技巧,在NLP領域,經典的word2vec就采用Hierarchical softmax來對輸出層進行建模,我們也借助同樣的思想,把Hierarchical softmax應用于推薦數據的輸出選擇。
首先來簡要的回顧Hierarchical softmax的原理,如果輸出層是常規的softmax輸出,假設有V個候選輸出數據,那么,每一時刻的輸出都需要計算P(vi|ht),時間復雜度為O(V), Hierarchical softmax的思想是構建一顆哈夫曼樹,我在應用中使用歌曲的熱度作為初始權值來構建哈夫曼樹,哈夫曼樹構建完成后,可以得到每一首歌曲對應的哈夫曼編碼。從而把softmax輸出層轉化為Hierarchical softmax,即多層次輸出,如下圖所示:
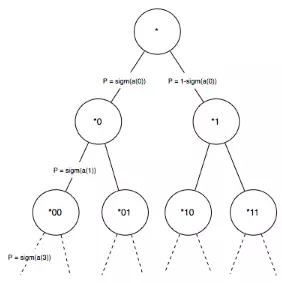
對于任意的輸出數據,哈夫曼樹都必然存在一條從根節點到葉子結點(歌曲)的路徑,并且該路徑是的,從根結點到葉子結點會產生L-1個分支,每一個分支都可以看成是一個二元分類,每一個分類會產生一個概率,將這些概率相乘就是我們最后的預測值。
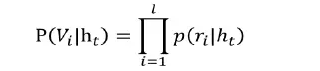
通過層次softmax求取概率,時間復雜度從原來的O(V)下降為O(log(V))。
關于推薦輸出,除了顯式求解每一首歌的輸出概率之外,我還嘗試了采用流派來進行層次softmax建模,事實上,在線上環境中,很多時候不需要較精確到具體的歌曲,在輸出層,我們可以按流派層次來建模,第一層是一級流派標簽,選擇了一級標簽之后,進入二級標簽的選擇,三級標簽的選擇等等,一般來說標簽的數量相對歌曲總量來說要少很多,但這種方法也要求標簽和曲庫的體系建設做到比較完善。
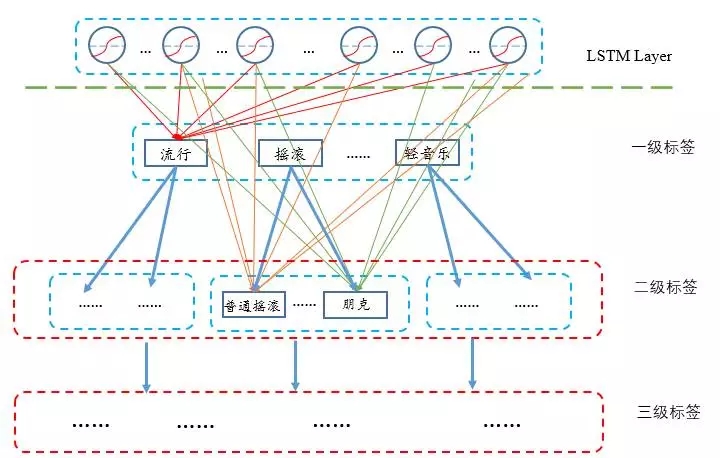
6、測試效果
模型訓練目標是最小化下式的損失函數,目標函數由兩部分構成,分別對應于正向數據集和負向數據集。
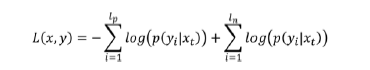
在測試中,我們收集了QQ音樂最近的電臺聽歌記錄,共約8千萬條聽歌序列,并對數據做了必要的預處理操作,主要包括下面兩點:
去掉了點擊序列小于5首,大于50首的聽歌數據,去掉序列過少是為了防止誤點擊,去掉過長的聽歌序列是為了防止用戶忘記關掉播放器。
對于全部是5秒內跳過的聽歌序列也同樣去掉,這樣可以有效防止不正當的負操作過多對模型訓練產生的影響。
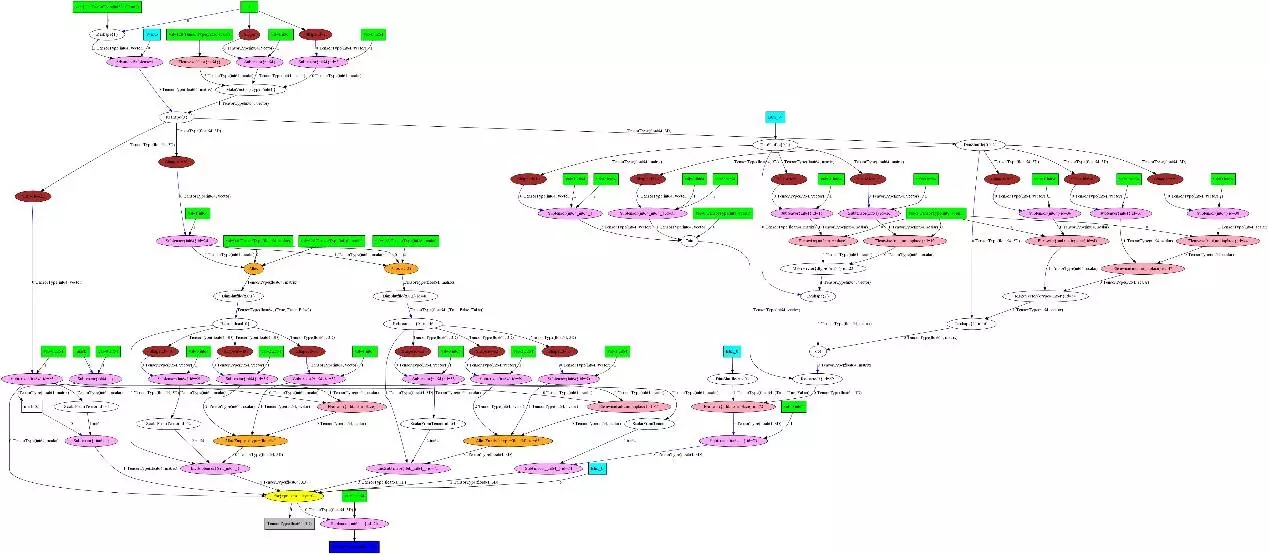
代碼采用Theano深度學習框架來實現,Theano也是當前對RNN支持較好的深度學習框架之一,它的scan機制使得RNN (包括LSTM, GRU) 的實現代碼非常優雅。下圖是核心遞歸代碼生成的圖結構:
我們分別采用單層LSTM和兩層LSTM來訓練,通過測試對比,兩層的LSTM效果要比單層的提高5%,同時我們也采用dropout來防止過擬合,dropout的效果還是比較明顯,在lr和momentum相同的情況下,取p=0.5, 效果進一步提升了3%。
除了前面提到的一些技巧外,還有很多細節能幫助我們提高網絡的訓練速度,下面是我用到的其中一些技巧:
【1】Theano的cuda backend當前只支持float32,需要將floatX設置為float32,并且將全部的shared變量設置為float32。
【2】權重參數盡量放在non_sequences中,作為參數傳遞給遞歸函數,這樣防止每一次迭代的時候都需要把參數反復重新導入計算圖中。
【3】為了避免數據在顯存和內存之間頻繁的交互,我大量采用了sandbox.gpu_from_host來存儲結果數據,但也對可移植性造成一定的影響。
【4】最后,theano的調試是不方便的,靈活使用eval和compute_test_value來調試theano。
對于新數據的預測,如下圖所示,給出初始的歌曲X0, 模型就能連續生成輸出序列,但有一點需要注意的是,與數據訓練不同,新數據的生成過程中,當前階段的輸出數據也是下一階段的輸入數據。

7、小結
本文是深度學習在智能推薦的第二篇實踐文章,詳細解析了如何使用LSTM對用戶的點擊進行序列建模,具體包括了如何設計lstm的門邏輯,以更好適應個性化推薦場景,dropout正則化,序列的規整,以及層次softmax解決高維度的推薦結果輸出。
隨著個性化推薦的不斷發展,推薦也早已不局限于淺層的用戶和物品挖掘,但對用戶行為的挖掘是一個相對困難的問題,我們也將會繼續探索深度學習在個性化推薦領域的研究與落地應用。
參考文獻:
【1】Erik Bernhardsson. Recurrent Neural Networks for Collaborative Filtering at Spotify.?
【2】Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, Domonkos Tikk. Session-based Recommendations with Recurrent Neural Networks.
【3】David Zhan Liu, Gurbir Singh. A Recurrent Neural Network Based Recommendation System.
【4】WILDML. RECURRENT NEURAL NETWORKS TUTORIAL.
【5】Andrej Karpathy. The Unreasonable Effectiveness of Recurrent Neural Networks.
【6】Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, Ruslan Salakhutdinov. Dropout: A Simple Way to Prevent Neural Networks from Overfitting.
【7】https://www.quora.com/Has-there-been-any-work-on-using-deep-learning-for-recommendation-engines.
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4416.html
摘要:自從年深秋,他開始在上撰寫并公開分享他感興趣的機器學習論文。本文選取了上篇閱讀注釋的機器學習論文筆記。希望知名專家注釋的深度學習論文能使一些很復雜的概念更易于理解。主要講述的是奧德賽因為激怒了海神波賽多而招致災禍。 Hugo Larochelle博士是一名謝布克大學機器學習的教授,社交媒體研究科學家、知名的神經網絡研究人員以及深度學習狂熱愛好者。自從2015年深秋,他開始在arXiv上撰寫并...
摘要:機器學習系統被用來識別圖像中的物體將語音轉為文本,根據用戶興趣自動匹配新聞消息或產品,挑選相關搜索結果。而深度學習的出現,讓這些問題的解決邁出了至關重要的步伐。這就是深度學習的重要優勢。 借助深度學習,多處理層組成的計算模型可通過多層抽象來學習數據表征( representations)。這些方法顯著推動了語音識別、視覺識別、目標檢測以及許多其他領域(比如,藥物發現以及基因組學)的技術發展。...
摘要:簡稱是為和編寫的較早的商業級開源分布式深度學習庫。這一靈活性使用戶可以根據所需,在分布式生產級能夠在分布式或的基礎上與和協同工作的框架內,整合受限玻爾茲曼機其他自動編碼器卷積網絡或遞歸網絡。 Deeplearning4j(簡稱DL4J)是為Java和Scala編寫的較早的商業級開源分布式深度學習庫。DL4J與Hadoop和Spark集成,為商業環境(而非研究工具目的)所設計。Skymind是...
摘要:本文將詳細解析深度神經網絡識別圖形圖像的基本原理。卷積神經網絡與圖像理解卷積神經網絡通常被用來張量形式的輸入,例如一張彩色圖象對應三個二維矩陣,分別表示在三個顏色通道的像素強度。 本文將詳細解析深度神經網絡識別圖形圖像的基本原理。針對卷積神經網絡,本文將詳細探討網絡 中每一層在圖像識別中的原理和作用,例如卷積層(convolutional layer),采樣層(pooling layer),...

閱讀 3735·2021-11-24 10:46
閱讀 1705·2021-11-15 11:38
閱讀 3759·2021-11-15 11:37
閱讀 3479·2021-10-27 14:19
閱讀 1938·2021-09-03 10:36
閱讀 1990·2021-08-16 11:02
閱讀 2997·2019-08-30 15:55
閱讀 2247·2019-08-30 15:44





