資訊專欄INFORMATION COLUMN

摘要:神經(jīng)網(wǎng)絡(luò)在自然語言處理方面,未來有巨大的應(yīng)用潛力。講座學(xué)者之一與深度學(xué)習(xí)大神蒙特利爾大學(xué)學(xué)者在大會上發(fā)表了論文,進一步展現(xiàn)神經(jīng)機器翻譯的研究結(jié)果。那些指令的語義就是習(xí)得的進入嵌入中,來較大化翻譯質(zhì)量,或者模型的對數(shù)似然函數(shù)。
在 8月7日在德國柏林召開的2016 計算語言學(xué)(ACL)大會上,學(xué)者Thang Luong、Kyunghyun Cho 和 Christopher D. Manning進行了關(guān)于神經(jīng)機器翻譯(NMT)的講座。神經(jīng)機器翻譯是一種簡單的新架構(gòu),可以讓機器學(xué)會翻譯。該方法雖然相對較新,已經(jīng)顯示出了非常好的效果,在各種語言對上都實現(xiàn)了最頂尖的表現(xiàn)。神經(jīng)網(wǎng)絡(luò)在自然語言處理方面,未來有巨大的應(yīng)用潛力。
講座學(xué)者之一 Kyunghyn Cho 與深度學(xué)習(xí)“大神” Yoshua Bengio、蒙特利爾大學(xué)學(xué)者 Junyoung Chung 在 ACL 大會上發(fā)表了論文,進一步展現(xiàn)神經(jīng)機器翻譯的研究結(jié)果。在此,雷鋒網(wǎng)(搜索“雷鋒網(wǎng)”公眾號關(guān)注)為大家分享名為《針對神經(jīng)機器翻譯,無需顯性分割的字符等級解碼器》論文全文。
概況
現(xiàn)有的機器翻譯系統(tǒng),無論是基于詞組的還是神經(jīng)的,幾乎全部都依靠使用顯性分割的、詞語等級的建模。在這篇論文中,我們提出一個基本問題:神經(jīng)機器翻譯能否在生成字符序列時,不使用任何顯性分割?要回答這一問題,我們分析一個基于注意的編碼器解碼器,在四個語言對——En-Cs、En-De、En-Ru 和 En-Fi——中,帶有子字等級的編碼器,以及一個字符等級的解碼器,使用 WMT’ 15 的平行語料庫。我們的實驗證明,帶有字符等級解碼器的模型在所有四個語言對上,表現(xiàn)都優(yōu)于帶有子字等級解碼器的模型。并且,帶有字符等級解碼器的神經(jīng)模型組合在 En-Cs、En-De 和 En-Fi 上優(yōu)于較先進的非神經(jīng)機器翻譯系統(tǒng),在 En-Ru 上表現(xiàn)相當(dāng)。
1、簡介
現(xiàn)有的機器翻譯系統(tǒng)幾乎全部都依靠使用顯性分割的、詞語等級的建模。這主要是因為數(shù)據(jù)稀疏性的問題,這當(dāng)句子表征為一系列字符而非詞語時這個問題更為嚴重,尤其是針對 n-gram,由于序列的長度大大增加了。除了數(shù)據(jù)稀疏性之外,我們經(jīng)常先入為主地相信詞語——或其分割出的詞位——是語義最基本的單位,使我們很自然地認為翻譯就是將一系列的源語言詞語匹配為一系列的目標語言詞語。
在最近提出的神經(jīng)機器翻譯范示中,這種觀點也延續(xù)了下來,雖然神經(jīng)網(wǎng)絡(luò)不受到字符等級建模的拖累,但是會被詞語等級建模所特有的問題影響,例如目標語言的詞匯量非常大,會造成增加的計算復(fù)雜性。因此,這篇論文中,我們研究神經(jīng)機器翻譯是否能夠直接在一系列字符上進行,無需顯性的詞語分割。
為了回答這一問題,我們專注在將目標方表征為一個字符序列。我們用字符等級的解碼器在 WMT’ 15 的四個語言對上評估神經(jīng)機器翻譯模型,讓我們的評估具有很強的說服力。我們將源語言一方表征為一個子字序列,使用從 Sennrich 等人(2015) 中編碼的字節(jié)對將其抽取而出,并將目標方改變?yōu)橐粋€子字或者字符序列。在目標方,我們進一步設(shè)計了一個新的循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN),稱為雙度量循環(huán)神經(jīng)網(wǎng)絡(luò),能更好地處理序列中的多個時標,并額外在一個新的、堆積的循環(huán)神經(jīng)網(wǎng)絡(luò)中測試。
在所有四個語言對中——En-Cs、En-De、En- Ru 和 En-Fi——帶有字符等級解碼器的模型比帶有子字等級解碼器的模型更好。我們在每一個這些配置的組合中都觀察到了類似的趨勢,在 En-Cs、En-De 和 En-Fi 中超過了之前較好的神經(jīng)和非神經(jīng)翻譯系統(tǒng),而在 En-Ru 上實現(xiàn)了相同的結(jié)果。我們發(fā)現(xiàn)這些結(jié)果強有力地證明了,神經(jīng)機器翻譯真的可以學(xué)會在字符等級翻譯,并且其實可以從中獲益。
2、神經(jīng)機器翻譯
神經(jīng)機器翻譯指的是一個最近提出的機器翻譯方法(Forcada 和 Neco, 1997;Kalchbrenner 和 Blunsom, 2013;Cho 等人, 2014;Sutskever 等人, 2014)。這種方法的目標是打造一個端到端的神經(jīng)網(wǎng)絡(luò),將輸入作為源句子 X = (x1, … , xTx),并輸出其翻譯 Y = (y1, … , yTy),其中 xt 和 yt’ 分別是源標志和目標標志。這個神經(jīng)網(wǎng)絡(luò)的打造方式是作為一個編碼網(wǎng)絡(luò)和解碼網(wǎng)絡(luò)。
編碼網(wǎng)絡(luò)將輸入句子 X 編碼為其連續(xù)的表征。在這篇論文中,我們緊密遵循 Bahdanau 等人(2015) 提出的神經(jīng)翻譯模型,使用一個雙向循環(huán)神經(jīng)網(wǎng)絡(luò),其中包含兩個循環(huán)神經(jīng)網(wǎng)絡(luò)。前饋網(wǎng)絡(luò)將輸入句子在前饋方向讀作:
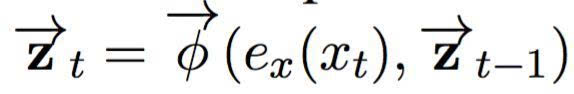
其中 ex (xt) 是對第 t 個輸入象征的連續(xù)嵌入,是一個循環(huán)激活函數(shù)。相同地,反向網(wǎng)絡(luò)將句子以反方向(從右到左)讀入:
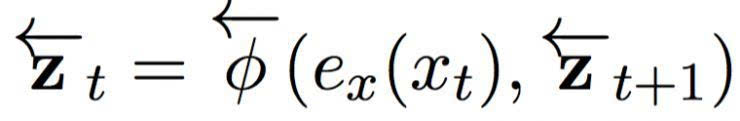
在輸入句子的每一個位置,我們將前饋和反向 RNN 中的隱藏狀態(tài)連接起來,形成一個情景組 C = { z1, …, zTx},其中
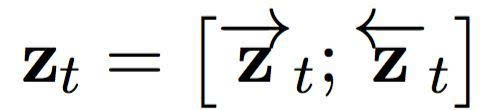
然后,解碼器基于這個情景組,計算出所有可能翻譯的條件分布。首先,重寫一個翻譯的條件分布:
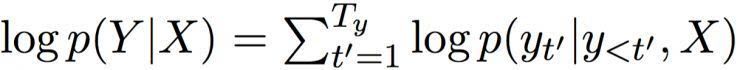
在總和的每一個條件中,解碼器 RNN 通過以下方程(1)更新其隱藏狀態(tài):
h’t = φ (ey (yt’ - 1), ht’-1, ct’), (1)
其中 ey 是一個目標象征的連續(xù)嵌入。ct’ 是一個情景矢量,由以下的軟堆砌機制計算而出:
ct’ = falign ( ey (yt’-1), ht’-1, C) )。 (2)
這個軟對齊機制 falign 在情景 C 中基于已經(jīng)翻譯的內(nèi)容,根據(jù)相關(guān)性權(quán)衡每一個矢量。每一個矢量 zt 的權(quán)重是由以下的方程(3)計算而出:
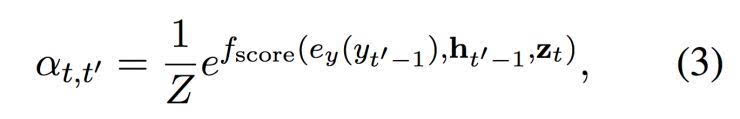
其中 fscore 是一個參數(shù)函數(shù),對于 ht’-1 和 yt’-1 返回一個非標準化的得分。
這篇論文中,我們使用一個帶有單一隱藏層的前饋網(wǎng)絡(luò)。 Z 是一個標準化的常數(shù):
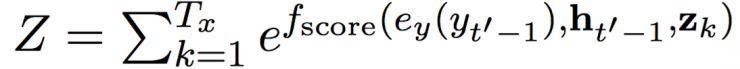
這個過程可以被理解為是在第 t’ 個目標符號和第 t 個源符號之間計算對齊概率。
在隱藏狀態(tài) ht’ 與之前的目標符號 yt’-1 和情景矢量 ct’ 一起,輸入一個前饋神經(jīng)網(wǎng)絡(luò),帶來以下的條件分布:
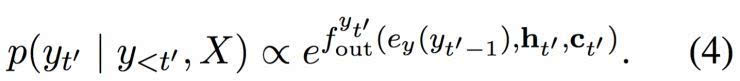
整個模型,由編碼器、加碼起和軟對齊機制構(gòu)成,然后經(jīng)過端到端的調(diào)試,使用隨機梯度下降將負面對數(shù)似然函數(shù)最小化。
3、向著字符等級翻譯
3.1 動機
讓我們回顧源句子和目標句子( X 和 Y ) 在神經(jīng)機器翻譯中是如何表征的。對于任何訓(xùn)練體中的源一方,我們可以掃描整體,來打造一個詞匯 Vx , 包含分配了整數(shù)標記的令牌。然后,源句子 X 作為一系列屬于該句子的類似令牌的標記,即 X = (x1, …, xTx) ,其中 xt ∈ { 1, 2, …, | Vx |}。與此類似地,目標句子轉(zhuǎn)化為一個整數(shù)標記的目標序列。
然后,每一個令牌或其指數(shù)轉(zhuǎn)化為 |Vx|所謂的 one-hot 矢量。除了一個以外,矢量中所有的元素都設(shè)置為 0。一個指數(shù)對應(yīng)令牌指數(shù)的元素設(shè)置為 1。這個 one-hot 矢量就是任何神經(jīng)機器翻譯模型所看見的。嵌入函數(shù) ex 或 ey,就是在這個 one-hot 矢量上應(yīng)用一個線性轉(zhuǎn)化(嵌入矩陣)的結(jié)果。
這種基于 one-hot 矢量的方法的重要特點是,神經(jīng)網(wǎng)絡(luò)忽視指令的底層語義。對于神經(jīng)網(wǎng)絡(luò)來說,詞匯中的每一個指令,等同于與其他每個指令間的距離。那些指令的語義就是習(xí)得的(進入嵌入中),來較大化翻譯質(zhì)量,或者模型的對數(shù)似然函數(shù)。
這項特性讓我們在選擇指令的單位時獲得了很大的自由度。神經(jīng)網(wǎng)絡(luò)已經(jīng)被證實與詞語指令配合良好 (Bengio 等人, 2001; Schwenk, 2007; Mikolov 等人, 2010),還與更細微的單元也配合良好,例如子字(Sennrich 等人, 2015; Botha 和 Blunson, 2014; Luong 等人, 2013) 和壓縮或編碼造成的符號(Chitnis 和 DeNero, 2015)。雖然已經(jīng)有一系列先前的研究報告稱使用了帶有字符的神經(jīng)網(wǎng)絡(luò)(例如 Mikolov 等人 (2012) 和 Santos 和 Zadrozny (2014)的研究),主流的方法一直是將文字預(yù)先處理為一系列符號,每個與一個字符系列相關(guān)聯(lián),之后神經(jīng)網(wǎng)絡(luò)就用那些符號、而非字符來表征。
最近在神經(jīng)機器翻譯中,兩組研究團隊已經(jīng)提出過直接使用字符。Kim 等人(2015)提出不像以前一樣以單一整數(shù)指令來代表每一個詞,而是作為一個字符序列,并使用一個卷積網(wǎng)絡(luò),隨后用一個高速神經(jīng)網(wǎng)絡(luò)(Srivastava 等人, 2015)來抽取詞語的連續(xù)表征。這種方法有效替換了嵌入函數(shù) ex,被 Costa-Jussa 和 Fonollosa(2016)在神經(jīng)機器翻譯中采用。類似地,Ling 等人 (2015b) 使用了一個雙向循環(huán)神經(jīng)網(wǎng)絡(luò)來代替嵌入函數(shù) ex 和 ey,來分別從相應(yīng)的連續(xù)詞語表征中編碼一個字符序列,并且編碼進這個連續(xù)表征中去。Lee 等人(2015) 提出了一個類似、但是略有不同的方法,他們用字符在詞語中的相對位置來顯性地標記每一個字符,例如,英文單詞中的 “B”eginning 和 “I”ntermediate。
雖然這些最近的方法是研究字符層面,但還是不如人意,因為它們都依賴于了解如何將字符分割為詞語。雖然總體上這在英語等語言中還是相對簡單的,這并不總是可行的。這種詞語分割過程可以非常簡單,就像帶有標點符號常規(guī)化的指令化,不過,也可能非常復(fù)雜,就像詞素分割,需要預(yù)先訓(xùn)練一個多帶帶的模型(Creutz 和 Lagus, 2005; Huang 和 Zhao,2007;)。而且,這些分割步驟經(jīng)常是經(jīng)過微調(diào)的,或者與最終的翻譯質(zhì)量目標分開設(shè)計,潛在來說可能造成非最優(yōu)的質(zhì)量。
基于這項觀察和分析,這篇論文中,我們向自己和讀者提出一個早該提出的問題:有沒有可能,不使用任何顯性的分割,就進行字符等級的翻譯?
3.2 為什么要使用詞語等級的翻譯?
(1)詞語作為語義的基本單位
詞語可以被理解為兩種意思。抽象意義來說,一個詞語是語義(詞素)的基本單位,在另一種意義來說,可以理解為“在句子中使用的具體詞語” (Booij,2012)。在第一種意義中,一個詞語通過詞語形態(tài)學(xué)的過程——包括變音、組合和衍生——轉(zhuǎn)化進入第二種意義。這三種過程的確改變詞素的含義,但是經(jīng)常與原意保持相近。因為這種語言學(xué)中的觀點認為詞語是語義的基本單位(作為詞素或者衍生形式),自然語言處理中的很多先前研究都將詞語作為基本單位,將句子編碼為詞語的序列。另外,匹配詞語的字符序列和語義的潛在困難,也可能推動了這種詞語等級建模的潮流。
(2)數(shù)據(jù)稀疏性
還有另一個技術(shù)原因,使得很多之前對于翻譯匹配的研究都將詞語作為基本單位。這主要是因為現(xiàn)有翻譯系統(tǒng)中的主要組成部分——例如語言模型和詞組表——都是基于字數(shù)的概率模擬。換句話說,標志子序列的概率(或者)一對標志,估計的方法是數(shù)出它在訓(xùn)練體出現(xiàn)了幾次。這種方法嚴重地受到數(shù)據(jù)稀疏性問題的影響,這是因為一個很大的狀態(tài)空間,子序列會出現(xiàn)指數(shù)級別的增長,而在訓(xùn)練體的體積方面只會線性增長。這對字符等級的建模帶來了很大挑戰(zhàn),由于當(dāng)使用字符(而非詞語)時,任何子序列都會變長平均 4-5 倍。的確,Vilar 等人(2007)的報告提出,當(dāng)基于詞組的機器翻譯系統(tǒng)直接使用字符序列時,表現(xiàn)變得更差。更加近期的,Neubig 等人(2013) 提出了一種方法,用基于詞組的翻譯系統(tǒng)來提升字符等級的翻譯,不過成效有限。
(3)消失的梯度
具體到神經(jīng)機器翻譯,之所以詞語等級的建模得到廣泛采用,有一個主要原因是對循環(huán)神經(jīng)網(wǎng)絡(luò)的長期依存性的建模難度(Bengio 等人, 1994; Hochreiter, 1998)。當(dāng)句子作為字符表征時,由于雙方句子長度增長,我們很容易相信未來會有更多的長期依存性,循環(huán)神經(jīng)網(wǎng)絡(luò)一定會在成功翻譯中使用。
3.3 為什么要使用字符等級的翻譯?
為什么不使用詞語等級的翻譯?
詞語等級的處理中最緊迫的問題是,我們沒有一個針對任何語言的、完美的詞語分割算法。一個完美的詞語分割算法需要能將任何已知的句子分割為一系列的詞素和詞位。然而,這個問題本身是一個嚴重的問題,經(jīng)常需要幾十年的研究(關(guān)于芬蘭語和其他詞素豐富的語言,參見例如 Creutz 和 Lagus (2005)的研究,關(guān)于中文,參見 Huang 和 Zhao (2007)的研究)。因此,許多人選擇使用基于規(guī)則的指令化方法,或者非最優(yōu)的、不過仍可行的、基于學(xué)習(xí)的分割算法。
這種非最優(yōu)分割的結(jié)果是,詞匯中經(jīng)常充滿許多詞義相近的詞語,分享同一個詞位但是形態(tài)不同。例如,如果我們將一個簡單的指令話腳本應(yīng)用于英文,“run”、“runs”、 “ran” 和 “running”(英文“跑步”的一般式、第三人稱單數(shù)形式、過去式和現(xiàn)在進行式)都是詞匯中多帶帶的條目,盡管它們顯然是共享一個相同的詞位 “run”。這使得任何機器翻譯——尤其是神經(jīng)機器翻譯——都沒法正確高效地為這些詞形變化的詞語建模。
具體到神經(jīng)機器翻譯的情況下來說,每一個詞形變體——“run”、“runs”、“ran” 和 “running”——將會分配一個 d 維詞語矢量,產(chǎn)生四個獨立矢量,雖然如果我們能將那些變體分割為一個詞位和其他詞素,顯然我們就能更加高效地將其建模。舉個例子,針對詞位 “run” 我們可以有一個 d 維矢量,針對 “s” 和 “ing” 可以有一些更小的矢量。這些變體的每一個之后都會變成詞位矢量(由這些變體共享)和語素矢量(由帶有相同后綴或其它結(jié)構(gòu)的詞語共享)(Botha 和 Blunsom,2014)。這利用了分布表征,在總體上帶來更好的抽象化,但好像需要一種最優(yōu)分割,可惜這總是無法獲得。
除了建模中的低效,使用(未分割的)詞語還有兩個額外的負面結(jié)果。首先,翻譯系統(tǒng)不能很好地在新詞上進行抽象化,經(jīng)常匹配到一個預(yù)留給未知詞語的指令上。這實際在翻譯中忽略了任何詞語的需要融合進來的語義或者結(jié)構(gòu)。第二,即便是一個詞位很普遍,經(jīng)常在訓(xùn)練體里觀察到,其詞形變體可能不一定。這意味著模型更少地見到這種特定的、罕見的詞形變體,而且將不能好好翻譯。然而,如果這種罕見的變體與其它更常見的詞語共享很大的一部分拼寫,我們就希望機器翻譯系統(tǒng)在翻譯罕見變體時能利用那些常見詞語。
為什么使用字符等級的翻譯
從某種程度上,所有這些問題都可以通過直接建模字符來解決。雖然數(shù)據(jù)稀疏性的問題在字符等級的翻譯中出現(xiàn),通過使用一個基于循環(huán)神經(jīng)網(wǎng)絡(luò)的參數(shù)方法(而非一個基于字數(shù)的非參數(shù)方法)就可以優(yōu)雅地解決。而且,最近幾年,我們已經(jīng)了解如何打造和訓(xùn)練循環(huán)神經(jīng)網(wǎng)絡(luò),來通過使用更復(fù)雜的激活函數(shù),例如長短期記憶(LSTM)單元(Hochreiter 和 Schmidhuber,1997)和門限循環(huán)單元(Cho 等人, 2014),來良好抓取長期依存性。
Kim 等人(2015)和 Ling 等人(2015a)最近證明了,通過一個神經(jīng)網(wǎng)絡(luò)來將字符序列轉(zhuǎn)化為詞語矢量,我們可以避免很多詞形變量作為詞匯中的多帶帶實體出現(xiàn)。這之所以成為可能,是通過在所有獨特指令之間分享“字符到詞語”神經(jīng)網(wǎng)絡(luò)。一個類似的方法由 Ling 等人(2015b)應(yīng)用在機器翻譯中。
然而,這些最近的方法仍依賴獲得一個好的(如果不是最優(yōu)的)分割算法。Ling 等人(2015b) 的確說:“很多關(guān)于詞形學(xué)、同源詞和罕見詞翻譯等等等先前信息應(yīng)該被融合進來。”
然而,如果我們直接在未分割的字符序列上使用一個神經(jīng)網(wǎng)絡(luò)——無論是循環(huán)的、卷積的或者它們的組合——就沒有必要考慮這些先前信息了。使用未分割字符序列的可能性已經(jīng)在深度學(xué)習(xí)領(lǐng)域中研究了很多年。例如,Mikolov 等人(2012)和 Sutskever 等人2011)在字符序列上訓(xùn)練了一個循環(huán)神經(jīng)網(wǎng)絡(luò)語言模型(RNN-LM)。后者證明了,只通過從這個模型中一次取樣一個字符就可以生成合理的文本序列。最近,Zhang 等人(2015) 及 Xiao 和 Cho (2016)成功地對字符等級文檔分別應(yīng)用了一個卷積網(wǎng)絡(luò)和一個卷積-循環(huán)網(wǎng)絡(luò),并且未使用任何顯性分割。Gillick 等人 (2015) 進一步證明了可以在 unicode 字節(jié)(而非在字符或詞語上)訓(xùn)練一個循環(huán)神經(jīng)網(wǎng)絡(luò),來進行部分語音自動標注以及命名實體識別。
這些早先研究讓我們看到了在機器翻譯任務(wù)中應(yīng)用神經(jīng)網(wǎng)絡(luò)的可能性,這經(jīng)常被認為比文件分類和語言建模更加困難。
3.4 挑戰(zhàn)與問題
針對源語言方和目標語言方,有兩組相互重疊的挑戰(zhàn)。在源語言方,我們還未知如何打造一個神經(jīng)網(wǎng)絡(luò)來學(xué)習(xí)拼寫和句子語義之間的高度非線性匹配。
在目標語言方有兩項挑戰(zhàn)。第一項挑戰(zhàn)是和源語言方相同,因為解碼器神經(jīng)網(wǎng)絡(luò)需要總結(jié)翻譯的內(nèi)容。此外,目標語言方的字符等級建模更加具有挑戰(zhàn)性,因為解碼器網(wǎng)絡(luò)必須得能生成長的、連貫的字符序列。這是一個大挑戰(zhàn),因為狀態(tài)空間的大小會由于符號的數(shù)量而指數(shù)增長,而在字符的情況下,經(jīng)常有300-1000個符號那么長。
所有這些挑戰(zhàn)首先都應(yīng)該描述為問題;目前的循環(huán)神經(jīng)網(wǎng)絡(luò)——在神經(jīng)機器翻譯中已經(jīng)廣泛使用——能否解決這些問題。這篇論文中,我們的目標是實證性地回答這些問題,并集中考慮目標方的挑戰(zhàn)(由于目標方兩項挑戰(zhàn)都會顯示)。
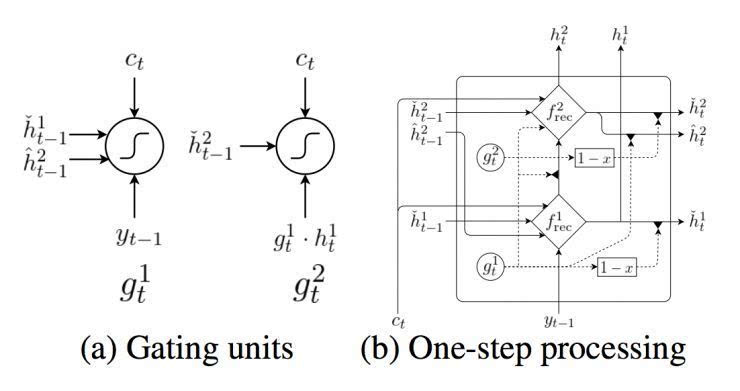
圖1: 雙度量循環(huán)神經(jīng)網(wǎng)絡(luò)。
4、字符等級翻譯
這篇論文中,我們試圖通過在目標方(解碼器)測試兩種不同類型的循環(huán)神經(jīng)網(wǎng)絡(luò),回答早前提出的問題。
首先,我們用門限循環(huán)單元(GRU)測試一個現(xiàn)有的循環(huán)神經(jīng)網(wǎng)絡(luò)。我們將這個解碼器稱為基準解碼器。
第二步,我們在 Chung 等人(2015)的門限反饋網(wǎng)絡(luò)的啟發(fā)之下,打造一個新的雙層循環(huán)神經(jīng)網(wǎng)絡(luò),稱為“雙度量”循環(huán)神經(jīng)網(wǎng)絡(luò)。我們設(shè)計這個網(wǎng)絡(luò)來輔助抓取兩種時間量程,初衷是由于字符和詞語可能在兩個分開的時間量程上運行。
我們選擇測試這兩種選項是為了以下這兩種目的。使用基準解碼器的實驗會明確地回答這一問題:現(xiàn)有神經(jīng)網(wǎng)絡(luò)是否能夠處理字符等級的解碼。這一問題在機器翻譯的領(lǐng)域內(nèi)還沒有良好解答過。另一個選項——雙度量解碼器——也經(jīng)過測試,為了了解如果第一個問題的答案是肯定的,那么有沒有可能設(shè)計一個更好的解碼器。
4.1 雙度量循環(huán)神經(jīng)網(wǎng)絡(luò)
在這個提出的雙度量循環(huán)神經(jīng)網(wǎng)絡(luò)中有兩組隱藏單元,h1 和 h2。它們包含同樣數(shù)量的單元,即: dim (h1) = dim (h2)。第一組 h1 使用一個快速變化的時間度量(因而是一個更快的層),h2 使用更慢的時間度量(因而是一個更慢的層)。針對每一個隱藏單元,都有一個相關(guān)的門限單元,我們分別稱為 g1 和 g2。接下來的描述中,我們?yōu)橹暗哪繕朔柡颓榫笆噶糠謩e使用 yt’-1 和 ct’ (見方程(2))。
讓我們先從更快的層開始。更快的層輸出兩組激活,一個標準輸出
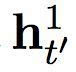
及其門限版本

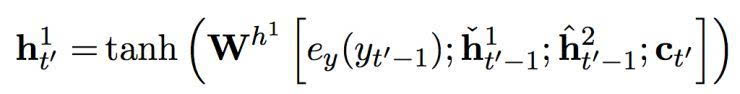
其中
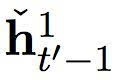
和
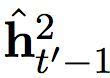
分別是快速層和慢速層的門限激活。這些門限激活由以下方程計算而出:
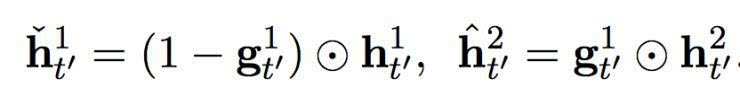
換句話說,快速層的激活是基于之前時間步中,快速層和慢速層的適應(yīng)性結(jié)合。當(dāng)快速層任務(wù)需要重啟,即
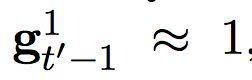
下一個激活將更多地由慢速層的激活而決定。
快速層的門限單元由以下方程計算而出:
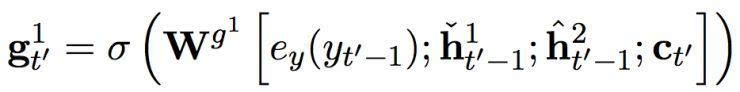
其中 σ 是一個 sigmoid 函數(shù)。
慢速層還輸出兩組激活,一個常規(guī)輸出

及其門限版本
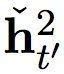
這些激活是由以下方程計算而出:

其中
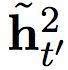
是一個候選激活。慢速層的門限單元是由以下方程計算而出:
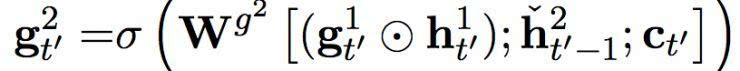
這項適應(yīng)性融合是基于從快速層而來的門限單元,其結(jié)果是,慢速層只有當(dāng)快速層重啟時才更新其激活。這設(shè)置了一種軟限制,通過防止慢速層在快速層處理一個當(dāng)前部分時進行更新,使得快速層運行速率更快。
然后,候選激活由以下方程計算而出:
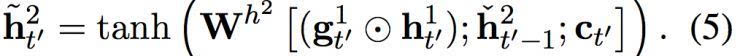

圖2:(左)關(guān)于源句子長度在 En-Cs 上的 BLEU 分。(右)子字等級解碼器和字符等級基準或雙度量解碼器之間的詞語負面對數(shù)概率差異。
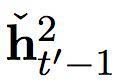
意味著之前時間步的重啟,與在快速層中發(fā)生的相似,
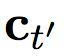
是情景中而來的輸入。
根據(jù)方程(5)中的
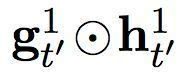 ,
,
只有當(dāng)快速層已經(jīng)完成處理目前部分、將要開始重啟的時候,快速層才會影響到慢速層。換句話說,慢速層不會從快速層收到任何輸入,直到快速層已經(jīng)完成處理目前部分,因而比快速層的運行速率更慢。
在每一個時間步,所提出的雙度量循環(huán)神經(jīng)網(wǎng)絡(luò)的最終輸出,是快速層和慢速層輸出矢量的結(jié)合,即:[h1; h2]。這個結(jié)合矢量用來計算所有符號在詞匯中的分布概率,正如方程(4)。詳見圖1。
5、實驗設(shè)定
為了評估,我們將一個源句子表征為一系列子字符號序列,用字節(jié)對編碼(BPE,Sennrich 等(2015))抽取而來,并將目標句子編碼為一系列基于 BPE 的符號序列或者一個字符序列。
主體和預(yù)處理
我們使用 WMT’ 15 的四個語言對——En-Cs、En-De、En-Ru 和 En-Fi——中所有可用的平行主體。它們分別由 12.1 M、4.5 M、2.3 M 和 2 M 句子對構(gòu)成。我們我們將每一個主體指令化,使用一個包含在 Moses 中的指令化腳本。當(dāng)源語言方長達 50 個子字,并且目標方長達 100 個子字標識或者 500 個字符時,我們只使用句子對。我們不使用任何單一語言主體。

表格1: 單一模型及組合的子字等級、字符等級技術(shù)和字符等級雙量級解碼器的 BLEU 分。每一個語言對的單一模型的較佳分數(shù)以黑體標記,而組合中的較佳分數(shù)以下劃線標記。當(dāng)可獲得時,我們返回平均值、較高值和較低值,分別作為下標文字和上標文字。
針對除 En-Fi 之外的所有對,我們使用 newstest-2013 作為發(fā)展測試,并使用 newstests-2014 (Test 1) 和 newstests-2015 (Test 2) 作為測試組。針對 En-Fi, 我們使用 newsdev-2015 和 newstest-2015 分別作為發(fā)展組和測試組。
模型和訓(xùn)練
我們測試三個模型設(shè)定:(1)BPE → BPE,(2)BPE → Char (基準)和(3)BPE → Char (雙度量)。后兩項的不同點是我們使用的循環(huán)神經(jīng)網(wǎng)絡(luò)類型不同。我們在所有設(shè)定中都使用了 GRU 作為編碼器。我們在前兩個設(shè)定(1)和(2)中使用 GRU 作為解碼器,而在最后一個設(shè)定(3)中使用了提出的雙度量循環(huán)網(wǎng)絡(luò)。針對每一個方向(前饋和反向),編碼器具有 512 個隱藏單元,解碼器有 1024 個隱藏單元。
我們使用帶有 Adam 的隨機梯度下降來訓(xùn)練每一個模型(Kingma 和 Ba,2014)。每一個更新都是使用由 128 個句子對組成的迷你批次來計算。梯度的常規(guī)是使用閾值 1 來剪切(Pascanu 等,2013)。
解碼和評估
我們使用集束搜索來近似尋找特定源句子的最可能的翻譯。集束寬對子字等級和字符等級解碼器分別是 5 和 15。選擇它們是基于發(fā)展組的翻譯質(zhì)量。翻譯使用 BLEU 進行評估。
多層解碼器和軟對齊機制
當(dāng)解碼器是一個多層循環(huán)神經(jīng)網(wǎng)絡(luò)(包括一個堆積網(wǎng)絡(luò),以及提出的雙度量網(wǎng)絡(luò)),針對 L 層,解碼器一次輸出多個隱藏矢量 {h1, …,hL}。這使得軟對齊機制(方程(3)中的 fscore)中可以有一個額外的自由度。我們使用其它選項來進行評估,包括(1)只使用 hL (慢速層)和(2)使用所有(結(jié)合)。
組合
我們還評估了神經(jīng)機器翻譯模型的組合,在所有四組語言對上,將其與較先進的基于詞組翻譯系統(tǒng)進行比較。我們?nèi)∶恳徊捷敵龈怕蚀笃骄担瑥亩鴱哪骋粋€組合中解碼。

圖3:使用 BPE → Char (雙度量)模型,En-De 中測試例子的對齊矩陣。
6、定量分析
用于對齊的慢速層
在 En-De 上,我們測試應(yīng)該使用哪一層解碼器來計算軟對齊。在子字等級解碼器的情況下,我們沒有觀察到選擇解碼器的兩層與使用所有層的結(jié)合(表格1(a-b))有什么不同。另一方面,有了字符等級的解碼器,我們注意到,當(dāng)針對軟對齊機制(表格1(c-g))只使用慢速層(h2)的時候,表現(xiàn)會有提升。這意味著,在目標中將更大的部分與源一方的子字單元對齊,會給軟對齊機制帶來益處,我們對所有其它語言對都只使用慢速層。
單一模型
在表格1中,我們呈現(xiàn)了一個關(guān)于所有語言對的翻譯質(zhì)量的綜合報告,包括了(1)子字等級解碼器、(2)字符等級基準解碼器和(3)字符等級雙度量解碼器。我們可以看見,針對 En-Cs 和 En-Fi,兩種字符等級解碼器都比較明顯地優(yōu)于子字等級解碼器。在 En-De 上,字符等級基準解碼器比子字等級解碼器和字符等級雙度量解碼器都更好,證實了字符等級建模的有效性。在 En-Ru 上,在單一模型中,字符等級解碼器優(yōu)于子字等級解碼器,但是,我們觀察到所有三種選項之間就總體來說都比較均等。
這些結(jié)果顯然驗證了這一點:不使用顯性的分割而進行字符等級的翻譯,的確是有可能的。實際上,我們觀察到字符等級的翻譯質(zhì)量經(jīng)常超過詞語等級的翻譯。當(dāng)然,我們又一次提到我們的實驗有限制,解碼器只使用未分割字符序列,未來還需要研究用一個未分割的字符序列來代替源句子。
組合
每一個組合都是使用8個獨立模型打造的。我們得出的第一個觀察結(jié)論是,在所有的語言對中,神經(jīng)機器翻譯與較先進的非神經(jīng)翻譯系統(tǒng)表現(xiàn)相當(dāng),或者經(jīng)常更好。而且,字符等級的解碼器在所有情況中都優(yōu)于子字等級的解碼器。
7 定性分析
(1)字符等級的解碼器能否生成長的、連貫的句子?
字符翻譯比詞語翻譯要長得多,可能使得循環(huán)神經(jīng)網(wǎng)絡(luò)以字符生成連貫句子變得更難。這種想法證明是錯誤的。就像在圖2(左)中,子字等級和字符等級的解碼器之間沒有什么明顯不同,雖然生成翻譯的長度總體來說在字符里會長5-10倍。
(2)字符等級的解碼器對罕見詞語有幫助嗎?
基于字符建模的其中的一個好處是,可以將任何字符序列建模,因此能更好地對罕見的詞形變體進行建模。我們實證性地證實了這一點,通過觀察子字等級和字符等級解碼器的平均負對數(shù)概率,隨著詞語頻率下降,兩者之間的差距也越來越大。這展示在圖2(右),解釋了我們實驗中字符等級解碼成功背后的一個原因(我們定義 diff (x, y) = x - y)。
(3)字符等級解碼器能否在原詞語和目標字符之間軟對齊?
在圖3(左)中,我們展示了一個源句子軟對齊的例子,“Two sets of light so close to one another” (兩組互相非常接近的燈光)。很明顯,字符等級的翻譯模型良好抓取了源子字和目標字符之間的對齊。我們觀察到,字符等級解碼器在生成一個德語復(fù)合詞 “Lichtersets”(燈的組合)時,正確對齊到了“l(fā)ights”(燈)和“sets of”(組合)(放大版本詳見圖3(右))。這種行為在英語單詞“one another”和德語單詞“einaner” (編者注:都是“互相”的意思)也類似地出現(xiàn)了,這不意味著在原詞語和目標字符之間存在對齊。相反,這意味著字符等級解碼器的內(nèi)在狀態(tài)——基準或者雙度量 ——良好抓取了字符有意義的部分,讓模型可以將其匹配到源句子中更大的部分(子字)中去。
(4)字符等級解碼器的解碼速度有多快?
我們在 newstest - 2013 主體(En-De) 上,用一個單一的 Titan X GPU 評估了子字等級基準的解碼速度、字符等級基準和字符等級雙度量解碼器。子字等級基準解碼器每秒生產(chǎn) 31.9 個詞,字符等級基準解碼器和字符等級雙度量解碼器每秒分別生成 27.5 個單詞和 25.6 個單詞。注意,這是在一個在線設(shè)定中評估的,其中我們進行連續(xù)翻譯,同一時間只翻譯一句話。在批量設(shè)定中進行翻譯,可能與這些結(jié)果不同。
8. 結(jié)論
在這篇論文中,我們研究一個基本問題,也就是一個最近提出的神經(jīng)機器翻譯系統(tǒng)是否能直接在字符等級處理翻譯,不需要任何詞語分割。我們集中在目標方,其中一個解碼器需要一次生成一個字符,同時在目標字符和源子字之間進行軟對齊。我們大量的實驗利用了四個語言對——En-Cs、En-De、En-Ru 和 En-Fi——強有力證明了字符等級的神經(jīng)機器翻譯是可能的,并且實際上會從中獲益。
我們的結(jié)果有一個局限:我們在源方使用子字符號。然而,這讓我們可以獲得更加細微的分析,但是在未來必須調(diào)查另一種設(shè)定,其中源一方也表征為字符序列。
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4384.html
摘要:然而反向傳播自誕生起,也受到了無數(shù)質(zhì)疑。主要是因為,反向傳播機制實在是不像大腦。他集結(jié)了來自和多倫多大學(xué)的強大力量,對這些替代品進行了一次評估。號選手,目標差傳播,。其中來自多倫多大學(xué)和,一作和來自,來自多倫多大學(xué)。 32年前,人工智能、機器學(xué)習(xí)界的泰斗Hinton提出反向傳播理念,如今反向傳播已經(jīng)成為推動深度學(xué)習(xí)爆發(fā)的核心技術(shù)。然而反向傳播自誕生起,也受到了無數(shù)質(zhì)疑。這些質(zhì)疑來自各路科學(xué)家...
摘要:在與李世石比賽期間,谷歌天才工程師在漢城校區(qū)做了一次關(guān)于智能計算機系統(tǒng)的大規(guī)模深度學(xué)習(xí)的演講。而這些任務(wù)完成后,谷歌已經(jīng)開始進行下一項挑戰(zhàn)了。谷歌深度神經(jīng)網(wǎng)絡(luò)小歷史谷歌大腦計劃于年啟動,聚焦于真正推動神經(jīng)網(wǎng)絡(luò)科學(xué)能達到的較先進的技術(shù)。 在AlphaGo與李世石比賽期間,谷歌天才工程師Jeff Dean在Google Campus漢城校區(qū)做了一次關(guān)于智能計算機系統(tǒng)的大規(guī)模深度學(xué)習(xí)(Large-...
摘要:八月初,我有幸有機會參加了蒙特利爾深度學(xué)習(xí)暑期學(xué)校的課程,由最知名的神經(jīng)網(wǎng)絡(luò)研究人員組成的為期天的講座。另外,當(dāng)損失函數(shù)接近全局最小時,概率會增加。降低訓(xùn)練過程中的學(xué)習(xí)率。對抗樣本的訓(xùn)練據(jù)最近信息顯示,神經(jīng)網(wǎng)絡(luò)很容易被對抗樣本戲弄。 8月初的蒙特利爾深度學(xué)習(xí)暑期班,由Yoshua Bengio、 Leon Bottou等大神組成的講師團奉獻了10天精彩的講座,劍橋大學(xué)自然語言處理與信息檢索研...
摘要:另外,當(dāng)損失函數(shù)接近全局最小時,概率會增加。降低訓(xùn)練過程中的學(xué)習(xí)率。對抗樣本的訓(xùn)練據(jù)最近信息顯示,神經(jīng)網(wǎng)絡(luò)很容易被對抗樣本戲弄。使用高度正則化會有所幫助,但會影響判斷不含噪聲圖像的準確性。 由 Yoshua Bengio、 Leon Bottou 等大神組成的講師團奉獻了 10 天精彩的講座,劍橋大學(xué)自然語言處理與信息檢索研究組副研究員 Marek Rei 參加了本次課程,在本文中,他精煉地...
摘要:本文是雜志為紀念人工智能周年而專門推出的深度學(xué)習(xí)綜述,也是和三位大神首次合寫同一篇文章。逐漸地,這些應(yīng)用使用一種叫深度學(xué)習(xí)的技術(shù)。監(jiān)督學(xué)習(xí)機器學(xué)習(xí)中,不論是否是深層,最常見的形式是監(jiān)督學(xué)習(xí)。 本文是《Nature》雜志為紀念人工智能60周年而專門推出的深度學(xué)習(xí)綜述,也是Hinton、LeCun和Bengio三位大神首次合寫同一篇文章。該綜述在深度學(xué)習(xí)領(lǐng)域的重要性不言而喻,可以說是所有人入門深...

閱讀 1376·2021-10-14 09:43
閱讀 4209·2021-09-27 13:57
閱讀 4552·2021-09-22 15:54
閱讀 2548·2021-09-22 10:54
閱讀 2350·2021-09-22 10:02
閱讀 2108·2021-08-27 13:11
閱讀 867·2019-08-29 18:44
閱讀 1639·2019-08-29 15:20






