資訊專欄INFORMATION COLUMN

摘要:多加了這兩層卷積層和匯集層是卷積神經網絡和普通舊神經網絡的主要區(qū)別。卷積神經網絡的操作過程那時,卷積的思想被稱作權值共享,也在年和關于反向傳播的延伸分析中得到了切實討論。
導讀:這是《神經網絡和深度學習簡史》第二部分,這一部分我們會了解BP算法發(fā)展之后一些取得迅猛發(fā)展的研究,稍后我們會看到深度學習的關鍵性基礎。
神經網絡獲得視覺
隨著訓練多層神經網絡的謎題被揭開,這個話題再一次變得空前熱門,羅森布拉特的崇高雄心似乎也將得以實現。直到1989年另一個關鍵發(fā)現被公布,現在仍廣為教科書及各大講座引用。
多層前饋神經網絡是普適模擬器( universal approximators)。」本質上,可以從數學證明多層結構使得神經網絡能夠在理論上執(zhí)行任何函數表達,當然包括XOR(異或)問題。
然而,這是數學,你可以在數學中暢想自己擁有無限內存和所需計算能力——反向傳播可以讓神經網絡被用于世界任何角落嗎?噢,當然。也是在1989年,Yann LeCunn在AT&T Bell實驗室驗證了一個反向傳播在現實世界中的杰出應用,即「反向傳播應用于手寫郵編識別(Backpropagation Applied to Handwritten Zip Code Recognition)」。
你或許會認為,讓計算機能夠正確理解手寫數字并沒有那么了不起,而且今天看來,這還會顯得你太過大驚小怪,但事實上,在這個應用公開發(fā)布之前,人類書寫混亂,筆畫也不連貫,對計算機整齊劃一的思維方式構成了巨大挑戰(zhàn)。這篇研究使用了美國郵政的大量數據資料,結果證明神經網絡完全能夠勝任識別任務。更重要的是,這份研究首次強調了超越普通(plain)反向傳播 、邁向現代深度學習這一關鍵轉變的實踐需求。
傳統(tǒng)的視覺模式識別工作已經證明,抽取局部特征并且將它們結合起來組成更高級的特征是有優(yōu)勢的。通過迫使隱藏單元結合局部信息來源,很容易將這樣的知識搭建成網絡。一個事物的本質特征可以出現在輸入圖片的不同位置。因此,擁有一套特征探測器,可以探測到位于輸入環(huán)節(jié)任何地方的某個具體特征實例,非常明智。既然一個特征的精準定位于分類無關,那么,我們可以在處理過程中適當舍棄一些位置信息。不過,近似的位置信息必須被保留,從而允許下面網絡層能夠探測到更加高級更加復雜的特征。(Fukushima1980,Mozer,1987)
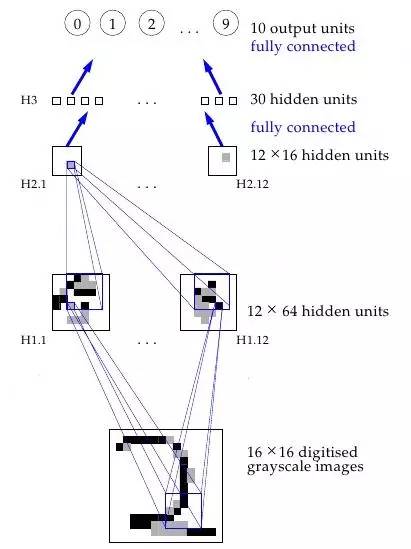
一個神經網絡工作原理的可視化過程
?
或者,更具體的:神經網絡的第一個隱層是卷積層——不同于傳統(tǒng)網絡層,每個神經元對應的一個圖片像素都相應有一個不同的權值(40*60=2400個權值),神經元只有很少一部分權值(5*5=25)以同樣的大小應用于圖像的一小個完整子空間。所以,比如替換了用四種不同的神經元來學習整個輸入圖片4個角的45度對角線探測,一個多帶帶的神經元能通過在圖片的子空間上學習探測45度對角線,并且照著這樣的方法對整張圖片進行學習。每層的第一道程序都以相類似的方式進行,但是,接收的是在前一隱藏層找到的「局部」特征位置而不是圖片像素值,而且,既然它們正在結合有關日益增大的圖片子集的信息,那么,它們也能「看到」其余更大的圖片部分。最后,倒數的兩個網絡層利用了前面卷積抽象出來的更加高級更加明顯的特征來判斷輸入的圖像究竟該歸類到哪里。這個在1989年的論文里提出的方法繼續(xù)成為舉國采用的支票讀取系統(tǒng)的基礎,正如LeCun在如下小視頻中演示的:
這很管用,為什么?原因很直觀,如果數學表述上不是那么清楚的話:沒有這些約束條件,網絡就必須學習同樣的簡單事情(比如,檢測45°角的直線和小圓圈等),要花大把時間學習圖像的每一部分。但是,有些約束條件,每一個簡單特征只需要一個神經元來學習——而且,由于整體權值大量減少,整個過程完成起來更快。而且,既然這些特征的像素確切位置無關緊要,那么,基本上可以跳過圖像相鄰子集——子集抽樣,一種共享池手段(a type of pooling)——當應用權值時,進一步減少了訓練時間。多加了這兩層——(卷積層和匯集層)——是卷積神經網絡(CNNs/ConvNets)和普通舊神經網絡的主要區(qū)別。

卷積神經網絡(CNN)的操作過程
那時,卷積的思想被稱作「權值共享」,也在1986年Rumelhart、Hinton和Williams關于反向傳播的延伸分析中得到了切實討論。顯然,Minsky和Papert在1969年《感知機》中的分析完全可以提出激發(fā)這一研究想法的問題。但是,和之前一樣,其他人已經獨立地對其進行了研究——比如,Kunihiko Fukushima在1980年提出的 Neurocognitron。而且,和之前一樣,這一思想從大腦研究汲取了靈感:
根據Hubel和Wiesel的層級模型,視覺皮層中的神經網絡具有一個層級結構:LGB(外側膝狀體)→樣品細胞→復雜細胞→低階超復雜細胞->高階超復雜細胞。低階超復雜細胞和高階超復雜細胞之間的神經網絡具有一個和簡單細胞與復雜細胞之間的網絡類似的結構。在這種層狀結構中,較高級別的細胞通常會有這樣的傾向,即對刺激模式的更復雜的特征進行選擇性響應,同時也具有一個更大的接收域,而且對刺激模式位置的移動更不敏感。因此,在我們的模型中就引入了類似于層級模型的結構。
LeCun也在貝爾實驗室繼續(xù)支持卷積神經網絡,其相應的研究成果也最終在上世紀90年代中期成功應用于支票讀取——他的談話和采訪通常都介紹了這一事實:「在上世紀90年代后期,這些系統(tǒng)當中的一個讀取了全美大約10%到20%的支票。」
神經網絡進入無監(jiān)督學習時期
將死記硬背,完全無趣的支票讀取工作自動化,就是機器學習大展拳腳的例子。也許有一個預測性小的應用? 壓縮。即指找到一種更小體量的數據表示模式,并從其可以恢復數據原有的表示形態(tài),通過機器學習找到的壓縮方法有可能會超越所有現有的壓縮模式。當然,意思是在一些數據中找到一個更小的數據表征,原始數據可以從中加以重構。學會壓縮這一方案遠勝于常規(guī)壓縮算法,在這種情況下,學習算法可以找到在常規(guī)壓縮算法下可能錯失的數據特征。而且,這也很容易做到——僅用訓練帶有一個小隱藏層的神經網絡就可以對輸入進行輸出。

自編碼神經網絡
這是一個自編碼神經網絡,也是一種學習壓縮的方法——有效地將數據轉換為壓縮格式,并且自動返回到本身。我們可以看到,輸出層會計算其輸出結果。由于隱藏層的輸出比輸入層少,因此,隱藏層的輸出是輸入數據的一個壓縮表達,可以在輸出層進行重建。
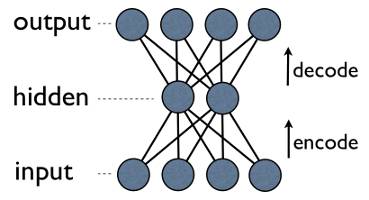
更明確地了解自編碼壓縮
注意一件奇妙的事情:我們訓練所需的東西就是一些輸入數據。這與監(jiān)督式機器學習的要求形成鮮明的對比,監(jiān)督式機器學習需要的訓練集是輸入-輸出對(標記數據),來近似地生成能從這些輸入得到對應輸出的函數。確實,自編碼器并不是一種監(jiān)督式學習;它們實際上是一種非監(jiān)督式學習,只需要一組輸入數據(未標記的數據),目的是找到這些數據中某些隱藏的結構。換句話說,非監(jiān)督式學習對函數的近似程度不如它從輸入數據中生成另一個有用的表征那么多。這樣一來,這個表征比原始數據能重構的表征更小,但它也能被用來尋找相似的數據組(聚類)或者潛在變量的其他推論(某些從數據看來已知存在但數值未知的方面)。
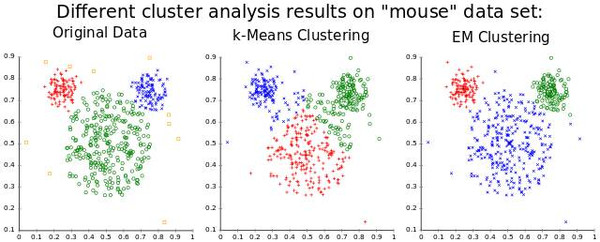
聚類,一種很常用的非監(jiān)督式學習應用
在反向傳播算法發(fā)現之前和之后,神經網絡都還有其他的非監(jiān)督式應用,最著名的是自組織映射神經網絡(SOM,Self Organizing Maps)和自適應共振理論(ART,Adapative Resonance Theory)。SOM能生成低維度的數據表征,便于可視化,而ART能夠在不被告知正確分類的情況下,學習對任意輸入數據進行分類。如果你想一想就會發(fā)現,從未標記數據中能學到很多東西是符合直覺的。假設你有一個數據集,其中有一堆手寫數字的數據集,并沒有標記每張圖片對應著哪個數字。那么,如果一張圖片上有數據集中的某個數字,那它看起來與其他大多數擁有同樣數字的圖片很相似,所以,盡管計算機可能并不知道這些圖片對應著哪個數字,但它應該能夠發(fā)現它們都對應著同一個數字。這樣,模式識別就是大多數機器學習要解決的任務,也有可能是人腦強大能力的基礎。但是,讓我們不要偏離我們的深度學習之旅,回到自編碼器上。
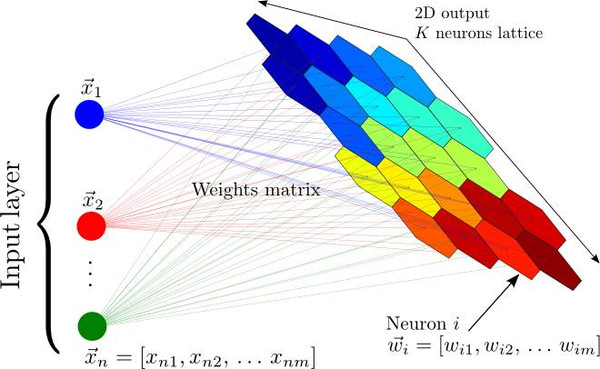
自組織映射神經網絡:將輸入的一個大向量映射到一個神經輸出的網格中,在其中,每個輸出都是一個聚類。相鄰的神經元表示同樣的聚類。
正如權重共享一樣,關于自編碼器最早的討論是在前面提到過的1986年的反向傳播分析中所進行。有了權重共享,它在接下來幾年中的更多研究中重新浮出了水面,包括Hinton自己。這篇論文,有一個有趣的標題:《自編碼器,最小描述長度和亥姆霍茲自由能》(Autoencoders, Minimum Description Length, and Helmholts Free Energy),提出「最自然的非監(jiān)督式學習方法就是使用一個定義概率分布而不是可觀測向量的模型」,并使用一個神經網絡來學習這種模型。所以,還有一件你能用神經網絡來做的奇妙事:對概率分布進行近似。
神經網絡迎來信念網絡
事實上,在成為1986年討論反向傳播學習算法這篇有重大影響力論文的合作者之前,Hinton在研究一種神經網絡方法,可以學習1985年「 A Learning Algorithm for Boltzmann Machines」中的概率分布。
玻爾茲曼機器就是類似神經網絡的網絡,并有著和感知器(Perceptrons)非常相似的單元,但該機器并不是根據輸入和權重來計算輸出,在給定相連單元值和權重的情況下,網絡中的每個單元都能計算出自身概率,取得值為1或0。因此,這些單元都是隨機的——它們依循的是概率分布而非一種已知的決定性方式。玻爾茲曼部分和概率分布有關,它需要考慮系統(tǒng)中粒子的狀態(tài),這些狀態(tài)本身基于粒子的能量和系統(tǒng)本身的熱力學溫度。這一分布不僅決定了玻爾茲曼機器的數學方法,也決定了其推理方法——網絡中的單元本身擁有能量和狀況,學習是由最小化系統(tǒng)能量和熱力學直接刺激完成的。雖然不太直觀,但這種基于能量的推理演繹實際上恰是一種基于能量的模型實例,并能夠適用于基于能量的學習理論框架,而很多學習算法都能用這樣的框架進行表述。
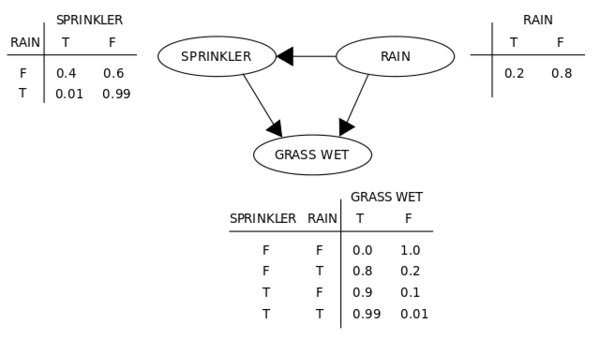
一個簡單的信念,或者說貝葉斯網絡——玻爾茲曼機器基本上就是如此,但有著非直接/對稱聯系和可訓練式權重,能夠學習特定模式下的概率。
回到玻爾茲曼機器。當這樣的單元一起置于網絡中,就形成了一張圖表,而數據圖形模型也是如此。本質上,它們能夠做到一些非常類似普通神經網絡的事:某些隱藏單元在給定某些代表可見變量的可見單元的已知值(輸入——圖像像素,文本字符等)后,計算某些隱藏變量的概率(輸出——數據分類或數據特征)。以給數字圖像分類為例,隱藏變量就是實際的數字值,可見變量是圖像的像素;給定數字圖像「1」作為輸入,可見單元的值就可知,隱藏單元給圖像代表「1」的概率進行建模,而這應該會有較高的輸出概率。
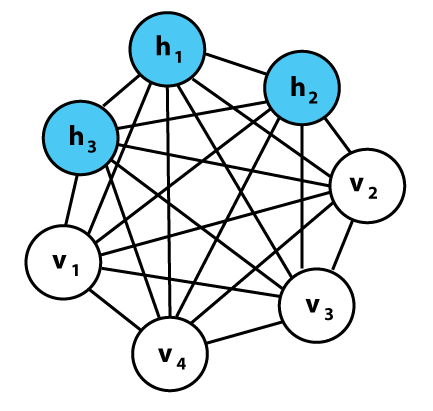
玻爾茲曼機器實例。每一行都有相關的權重,就像神經網絡一樣。注意,這里沒有分層——所有事都可能跟所有事相關聯。我們會在后文討論這樣一種變異的神經網絡
因此,對于分類任務,現在有一種計算每種類別概率的好方法了。這非常類似正常分類神經網絡實際計算輸出的過程,但這些網絡有另一個小花招:它們能夠得出看似合理的輸入數據。這是從相關的概率等式中得來的——網絡不只是會學習計算已知可見變量值時的隱藏變量值概率,還能夠由已知隱藏變量值反推可見變量值概率。所以,如果我們想得出一幅「1」數字圖像,這些跟像素變量相關的單元就知道需要輸出概率1,而圖像就能夠根據概率得出——這些網絡會再創(chuàng)建圖像模型。雖然可能能夠實現目標非常類似普通神經網絡的監(jiān)督式學習,但學習一個好的生成模型的非監(jiān)督式學習任務——概率性地學習某些數據的隱藏結構——是這些網絡普遍所需要的。這些大部分都不是小說,學習算法確實存在,而使其成為可能的特殊公式,正如其論文本身所描述的:
或許,玻爾茲曼機器公式最有趣的方面在于它能夠引導出一種(與領域無關的)一般性學習算法,這種算法會以整個網絡發(fā)展出的一種內部模型(這個模型能夠捕獲其周圍環(huán)境的基礎結構)的方式修改單元之間的聯系強度。在尋找這樣一個算法的路上,有一段長時間失敗的歷史(Newell,1982),而很多人(特別是人工智能領域的人)現在相信不存在這樣的算法。
我們就不展開算法的全部細節(jié)了,就列出一些亮點:這是較大似然算法的變體,這簡單意味著它追求與已知正確值匹配的網絡可見單元值(visible unit values)概率的較大化。同時計算每個單元的實際最有可能值 ,計算要求太高,因此,訓練吉布斯采樣(training Gibbs Sampling)——以隨機的單元值網絡作為開始,在給定單元連接值的情況下,不斷迭代重新給單元賦值——被用來給出一些實際已知值。當使用訓練集學習時,設置可見單位值( visible units)從而能夠得到當前訓練樣本的值,這樣就通過抽樣得到了隱藏單位值。一旦抽取到了一些真實值,我們就可以采取類似反向傳播的辦法——針對每個權重值求偏導數,然后估算出如何調整權重來增加整個網絡做出正確預測的概率。
和神經網絡一樣,算法既可以在監(jiān)督(知道隱藏單元值)也可以在無監(jiān)督方式下完成。盡管這一算法被證明有效(尤其是在面對自編碼神經網絡解決的「編碼」問題時),但很快就看出不是特別有效。Redford M. Neal1992年的論文《Connectionist learning of belief networks》論證了需要一種更快的方法,他說:「這些能力使得玻耳茲曼機在許多應用中都非常有吸引力——要不是學習過程通常被認為是慢的要命。」因此,Neal引入了類似信念網絡的想法,本質上就像玻耳茲曼機控制、發(fā)送連接(所以又有了層次,就像我們之前看過的神經網絡一樣,而不像上面的玻耳茲曼機控制機概念)。跳出了討厭的概率數學,這一變化使得網絡能以一種更快的學習算法得到訓練。灑水器和雨水那一層上面可以視為有一個信念網絡——這一術語非常嚴謹,因為這種基于概率的模型,除了和機器學習領域有著聯系,和數學中的概率領域也有著密切的關聯。
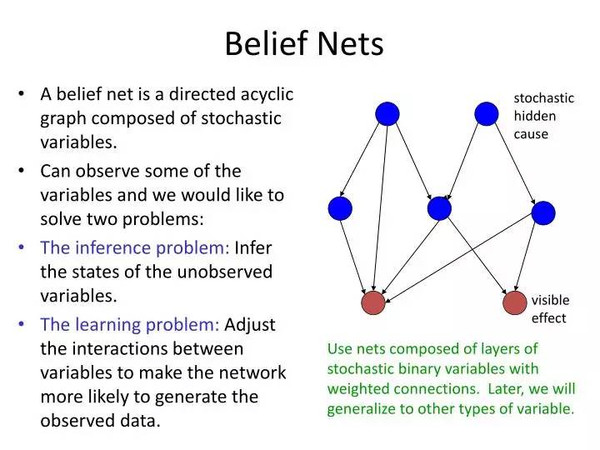
盡管這種方法比玻爾茲曼機進步,但還是太慢了,正確計算變量間的概率關系的數學需求計算量太大了,而且還沒啥簡化技巧。Hinton、Neal和其他兩位合作者很快在1995年的論文《 The wake-sleep algorithm for unsupervised neural networks》中提出了一些新技巧。這次他們又搞出一個和上個信念網絡有些不一樣的網絡,現在被叫做「亥姆霍茲機」。再次拋開細節(jié)不談,核心的想法就是對隱含變量的估算和對已知變量的逆轉生成計算采取兩套不同的權重,前者叫做recognition weights,后者叫做generative weights,保留了Neal"s信念網絡的有方向的特性。這樣一來,當用于玻爾茲曼機的那些監(jiān)督和無監(jiān)督學習問題時,訓練就快得多。
最終,信念網絡的訓練多少會快些!盡管沒那么大的影響力,對信念網絡的無監(jiān)督學習而言,這一算法改進是非常重要的進步,堪比十年前反向傳播的突破。不過,目前為止,新的機器學習方法也開始涌現,人們也與開始質疑神經網絡,因為大部分的想法似乎基于直覺,而且因為計算機仍舊很難滿足它們的計算需求。正如我們將在第三部分中看到的,人工智能寒冬將在幾年內到來。(待續(xù))
Kurt Hornik, Maxwell Stinchcombe, Halbert White, Multilayer feedforward networks are universal approximators, Neural Networks, Volume 2, Issue 5, 1989, Pages 359-366, ISSN 0893-6080, http://dx.doi.org/10.1016/0893-6080(89)90020-8.?
LeCun, Y; Boser, B; Denker, J; Henderson, D; Howard, R; Hubbard, W; Jackel, L, “Backpropagation Applied to Handwritten Zip Code Recognition,” in Neural Computation , vol.1, no.4, pp.541-551, Dec. 1989 89?
D. E. Rumelhart, G. E. Hinton, and R. J. Williams. 1986. Learning internal representations by error propagation. In Parallel distributed processing: explorations in the microstructure of cognition, vol. 1, David E. Rumelhart, James L. McClelland, and CORPORATE PDP Research Group (Eds.). MIT Press, Cambridge, MA, USA 318-362?
Fukushima, K. (1980), ‘Neocognitron: A Self-Organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position’, Biological Cybernetics 36 , 193–202 .?
Gregory Piatetsky, ‘KDnuggets Exclusive: Interview with Yann LeCun, Deep Learning Expert, Director of Facebook AI Lab’ Feb 20, 2014. http://www.kdnuggets.com/2014/02/exclusive-yann-lecun-deep-learning-facebook-ai-lab.html?
Teuvo Kohonen. 1988. Self-organized formation of topologically correct feature maps. In Neurocomputing: foundations of research, James A. Anderson and Edward Rosenfeld (Eds.). MIT Press, Cambridge, MA, USA 509-521.?
Gail A. Carpenter and Stephen Grossberg. 1988. The ART of Adaptive Pattern Recognition by a Self-Organizing Neural Network. Computer 21, 3 (March 1988), 77-88.?
H. Bourlard and Y. Kamp. 1988. Auto-association by multilayer perceptrons and singular value decomposition. Biol. Cybern. 59, 4-5 (September 1988), 291-294.?
P. Baldi and K. Hornik. 1989. Neural networks and principal component analysis: learning from examples without local minima. Neural Netw. 2, 1 (January 1989), 53-58.?
Hinton, G. E. & Zemel, R. S. (1993), Autoencoders, Minimum Description Length and Helmholtz Free Energy., in Jack D. Cowan; Gerald Tesauro & Joshua Alspector, ed., ‘NIPS’ , Morgan Kaufmann, , pp. 3-10 .?
Ackley, D. H., Hinton, G. E., & Sejnowski, T. J. (1985). A learning algorithm for boltzmann machines*. Cognitive science, 9(1), 147-169.?
LeCun, Y., Chopra, S., Hadsell, R., Ranzato, M., & Huang, F. (2006). A tutorial on energy-based learning. Predicting structured data, 1, 0.?
Neal, R. M. (1992). Connectionist learning of belief networks. Artificial intelligence, 56(1), 71-113.?
Hinton, G. E., Dayan, P., Frey, B. J., & Neal, R. M. (1995). The” wake-sleep” algorithm for unsupervised neural networks. Science, 268(5214), 1158-1161.?
Dayan, P., Hinton, G. E., Neal, R. M., & Zemel, R. S. (1995). The helmholtz machine. Neural computation, 7(5), 889-904.?
歡迎加入本站公開興趣群商業(yè)智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規(guī)行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4348.html
摘要:導讀這是神經網絡和深度學習簡史第一部分。實際上,神經網絡準確的說應該是人工神經網絡,就是多層感知機今天感知機通常被稱為神經元而已,只不過在這個階段,只有一層輸出層。多層輸出的神經網絡也可以想象一個與感知機不同的人工神經網絡。 導讀:這是《神經網絡和深度學習簡史》第一部分。這一部分,我們會介紹1958年感知機神經網絡的誕生,70年代人工智能寒冬以及1986年BP算法讓神經網絡再度流行起來。深度...
摘要:主流機器學習社區(qū)對神經網絡興趣寡然。對于深度學習的社區(qū)形成有著巨大的影響。然而,至少有兩個不同的方法對此都很有效應用于卷積神經網絡的簡單梯度下降適用于信號和圖像,以及近期的逐層非監(jiān)督式學習之后的梯度下降。 我們終于來到簡史的最后一部分。這一部分,我們會來到故事的尾聲并一睹神經網絡如何在上世紀九十年代末擺脫頹勢并找回自己,也會看到自此以后它獲得的驚人先進成果。「試問機器學習領域的任何一人,是什...
摘要:如何看待人工智能的本質人工智能的飛速發(fā)展又經歷了哪些歷程本文就從技術角度為大家介紹人工智能領域經常提到的幾大概念與發(fā)展簡史。一人工智能相關概念人工智能就是讓機器像人一樣的智能會思考是機器學習深度學習在實踐中的應用。 作為近幾年的一大熱詞,人工智能一直是科技圈不可忽視的一大風口。隨著智能硬件的迭代,智能家居產品逐步走進千家萬戶,語音識別、圖像識別等AI相關技術也經歷了階梯式發(fā)展。如何看待...
摘要:如何看待人工智能的本質人工智能的飛速發(fā)展又經歷了哪些歷程本文就從技術角度為大家介紹人工智能領域經常提到的幾大概念與發(fā)展簡史。一人工智能相關概念人工智能就是讓機器像人一樣的智能會思考是機器學習深度學習在實踐中的應用。 作為近幾年的一大熱詞,人工智能一直是科技圈不可忽視的一大風口。隨著智能硬件的迭代,智能家居產品逐步走進千家萬戶,語音識別、圖像識別等AI相關技術也經歷了階梯式發(fā)展。如何看待...

閱讀 2053·2021-11-11 16:55
閱讀 1394·2021-09-28 09:36
閱讀 1038·2019-08-29 15:21
閱讀 1570·2019-08-29 14:10
閱讀 2757·2019-08-29 14:08
閱讀 1627·2019-08-29 12:31
閱讀 3243·2019-08-29 12:31
閱讀 976·2019-08-26 16:47





