資訊專欄INFORMATION COLUMN

摘要:導(dǎo)讀這是神經(jīng)網(wǎng)絡(luò)和深度學(xué)習(xí)簡史第一部分。實(shí)際上,神經(jīng)網(wǎng)絡(luò)準(zhǔn)確的說應(yīng)該是人工神經(jīng)網(wǎng)絡(luò),就是多層感知機(jī)今天感知機(jī)通常被稱為神經(jīng)元而已,只不過在這個(gè)階段,只有一層輸出層。多層輸出的神經(jīng)網(wǎng)絡(luò)也可以想象一個(gè)與感知機(jī)不同的人工神經(jīng)網(wǎng)絡(luò)。
導(dǎo)讀:這是《神經(jīng)網(wǎng)絡(luò)和深度學(xué)習(xí)簡史》第一部分。這一部分,我們會介紹1958年感知機(jī)神經(jīng)網(wǎng)絡(luò)的誕生,70年代人工智能寒冬以及1986年BP算法讓神經(jīng)網(wǎng)絡(luò)再度流行起來。
深度學(xué)習(xí)掀起海嘯
如今,深度學(xué)習(xí)浪潮拍打計(jì)算機(jī)語言的海岸已有好幾年,但是,2015年似乎才是這場海嘯全力沖擊自然語言處理(NLP)會議的一年。——Dr. Christopher D. Manning, Dec 2015
整個(gè)研究領(lǐng)域的成熟方法已經(jīng)迅速被新發(fā)現(xiàn)超越,這句話聽起來有些夸大其詞,就像是說它被「海嘯」襲擊了一樣。但是,這種災(zāi)難性的形容的確可以用來描述深度學(xué)習(xí)在過去幾年中的異軍突起——顯著改善人們對解決人工智能最難問題方法的駕馭能力,吸引工業(yè)巨人(比如谷歌等)的大量投資,研究論文的指數(shù)式增長(以及機(jī)器學(xué)習(xí)的研究生生源上升)。在聽了數(shù)節(jié)機(jī)器學(xué)習(xí)課堂,甚至在本科研究中使用它以后,我不禁好奇:這個(gè)新的「深度學(xué)習(xí)」會不會是一個(gè)幻想,抑或上世紀(jì)80年代已經(jīng)研發(fā)出來的「人工智能神經(jīng)網(wǎng)絡(luò)」擴(kuò)大版?讓我告訴你,說來話長——這不僅僅是一個(gè)有關(guān)神經(jīng)網(wǎng)絡(luò)的故事,也不僅僅是一個(gè)有關(guān)一系列研究突破的故事,這些突破讓深度學(xué)習(xí)變得比「大型神經(jīng)網(wǎng)絡(luò)」更加有趣,而是一個(gè)有關(guān)幾位不放棄的研究員如何熬過黑暗數(shù)十年,直至拯救神經(jīng)網(wǎng)絡(luò),實(shí)現(xiàn)深度學(xué)習(xí)夢想的故事。
機(jī)器學(xué)習(xí)算法的百年歷史
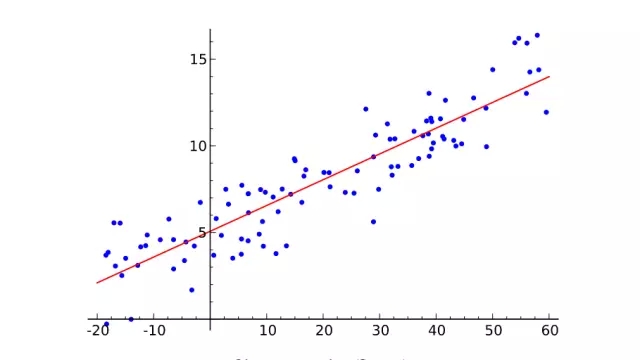
線性回歸
首先簡單介紹一下機(jī)器學(xué)習(xí)是什么。從二維圖像上取一些點(diǎn),盡可能繪出一條擬合這些點(diǎn)的直線。你剛才做的就是從幾對輸入值(x)和輸出值(y)的實(shí)例中概括出一個(gè)一般函數(shù),任何輸入值都會有一個(gè)對應(yīng)的輸出值。這叫做線性回歸,一個(gè)有著兩百年歷史從一些輸入輸出對組中推斷出一般函數(shù)的技巧。這就是它很棒的原因:很多函數(shù)難以給出明確的方程表達(dá),但是,卻很容易在現(xiàn)實(shí)世界搜集到輸入和輸出值實(shí)例——比如,將說出來的詞的音頻作為輸入,詞本身作為輸出的映射函數(shù)。
線性回歸對于解決語音識別這個(gè)問題來說有點(diǎn)太無用,但是,它所做的基本上就是監(jiān)督式機(jī)器學(xué)習(xí):給定訓(xùn)練樣本,「學(xué)習(xí)」一個(gè)函數(shù),每一個(gè)樣本數(shù)據(jù)就是需要學(xué)習(xí)的函數(shù)的輸入輸出數(shù)據(jù)(無監(jiān)督學(xué)習(xí),稍后在再敘)。尤其是,機(jī)器學(xué)習(xí)應(yīng)該推導(dǎo)出一個(gè)函數(shù),它能夠很好地泛化到不在訓(xùn)練集中的輸入值上,既然我們真的能將它運(yùn)用到尚未有輸出的輸入中。例如,谷歌的語音識別技術(shù)由擁有大量訓(xùn)練集的機(jī)器學(xué)習(xí)驅(qū)動,但是,它的訓(xùn)練集也不可能大到包含你手機(jī)所有語音輸入。
泛化能力機(jī)制如此重要,以至于總會有一套測試數(shù)據(jù)組(更多的輸入值與輸出值樣本)這套數(shù)據(jù)組并不包括在訓(xùn)練組當(dāng)中。通過觀察有多少個(gè)正確計(jì)算出輸入值所對應(yīng)的輸出值的樣本,這套多帶帶數(shù)據(jù)組可以用來估測機(jī)器學(xué)習(xí)技術(shù)有效性。概括化的克星是過度擬合——學(xué)習(xí)一個(gè)對于訓(xùn)練集有效但是卻在測試數(shù)據(jù)組中表現(xiàn)很差的函數(shù)。既然機(jī)器學(xué)習(xí)研究者們需要用來比較方法有效性的手段,隨著時(shí)間的推移,標(biāo)準(zhǔn)訓(xùn)練數(shù)據(jù)組以及測試組可被用來評估機(jī)器學(xué)習(xí)算法。
好了,定義談得足夠多了。重點(diǎn)是——我們繪制線條的聯(lián)系只是一個(gè)非常簡單的監(jiān)督機(jī)器學(xué)習(xí)例子:要點(diǎn)在于訓(xùn)練集(X為輸入,Y為輸出),線條是近似函數(shù),用這條線來為任何沒有包含在訓(xùn)練集數(shù)據(jù)里的X值(輸入值)找到相應(yīng)的Y值(輸出值)。別擔(dān)心,接下來的歷史就不會這么干巴巴了。讓我們繼續(xù)吧。
虛假承諾的荒唐
顯然這里話題是神經(jīng)網(wǎng)絡(luò),那我們前言里為何要扯線性回歸呢?呃, 事實(shí)上線性回歸和機(jī)器學(xué)習(xí)一開始的方法構(gòu)想,弗蘭克· 羅森布拉特(Frank Rosenblatt)的感知機(jī), 有些許相似性。
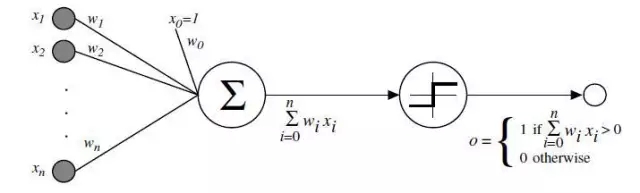
Perceptron
心理學(xué)家Rosenblatt構(gòu)想了感知機(jī),它作為簡化的數(shù)學(xué)模型解釋大腦神經(jīng)元如何工作:它取一組二進(jìn)制輸入值(附近的神經(jīng)元),將每個(gè)輸入值乘以一個(gè)連續(xù)值權(quán)重(每個(gè)附近神經(jīng)元的突觸強(qiáng)度),并設(shè)立一個(gè)閾值,如果這些加權(quán)輸入值的和超過這個(gè)閾值,就輸出1,否則輸出0(同理于神經(jīng)元是否放電)。對于感知機(jī),絕大多數(shù)輸入值不是一些數(shù)據(jù),就是別的感知機(jī)的輸出值。但有一個(gè)額外的細(xì)節(jié):這些感知機(jī)有一個(gè)特殊的,輸入值為1的,「偏置」輸入,因?yàn)槲覀兡苎a(bǔ)償加權(quán)和,它基本上確保了更多的函數(shù)在同樣的輸入值下是可計(jì)算的。這一關(guān)于神經(jīng)元的模型是建立在沃倫·麥卡洛克(Warren McCulloch)和沃爾特·皮茲(Walter Pitts)工作上的。他們曾表明,把二進(jìn)制輸入值加起來,并在和大于一個(gè)閾值時(shí)輸出1,否則輸出0的神經(jīng)元模型,可以模擬基本的或/與/非邏輯函數(shù)。這在人工智能的早期時(shí)代可不得了——當(dāng)時(shí)的主流思想是,計(jì)算機(jī)能夠做正式的邏輯推理將本質(zhì)上解決人工智能問題。
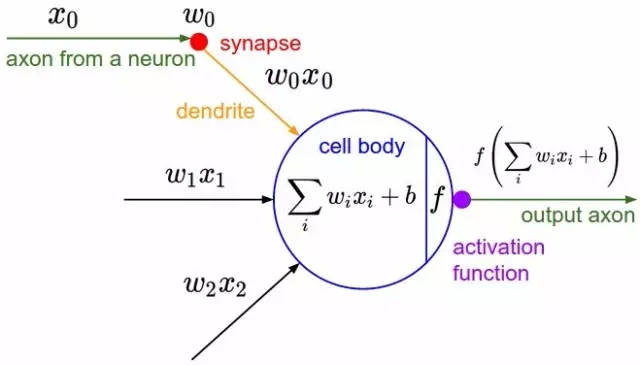
另一個(gè)圖表,顯示出生物學(xué)上的靈感。激活函數(shù)就是人們當(dāng)前說的非線性函數(shù),它作用于輸入值的加權(quán)和以產(chǎn)生人工神經(jīng)元的輸出值——在羅森布拉特的感知機(jī)情況下,這個(gè)函數(shù)就是輸出一個(gè)閾值操作
?
然而,麥卡洛克-皮茲模型缺乏一個(gè)對AI而言至關(guān)重要的學(xué)習(xí)機(jī)制。這就是感知機(jī)更出色的地方所在——羅森布拉特受到唐納德·赫布(Donald Hebb) 基礎(chǔ)性工作的啟發(fā),想出一個(gè)讓這種人工神經(jīng)元學(xué)習(xí)的辦法。赫布提出了一個(gè)出人意料并影響深遠(yuǎn)的想法,稱知識和學(xué)習(xí)發(fā)生在大腦主要是通過神經(jīng)元間突觸的形成與變化,簡要表述為赫布法則:
當(dāng)細(xì)胞A的軸突足以接近以激發(fā)細(xì)胞B,并反復(fù)持續(xù)地對細(xì)胞B放電,一些生長過程或代謝變化將發(fā)生在某一個(gè)或這兩個(gè)細(xì)胞內(nèi),以致A作為對B放電的細(xì)胞中的一個(gè),效率增加。
感知機(jī)并沒有完全遵循這個(gè)想法,但通過調(diào)輸入值的權(quán)重,可以有一個(gè)非常簡單直觀的學(xué)習(xí)方案:給定一個(gè)有輸入輸出實(shí)例的訓(xùn)練集,感知機(jī)應(yīng)該「學(xué)習(xí)」一個(gè)函數(shù):對每個(gè)例子,若感知機(jī)的輸出值比實(shí)例低太多,則增加它的權(quán)重,否則若設(shè)比實(shí)例高太多,則減少它的權(quán)重。更正式一點(diǎn)兒的該算法如下:
從感知機(jī)有隨機(jī)的權(quán)重和一個(gè)訓(xùn)練集開始。
對于訓(xùn)練集中一個(gè)實(shí)例的輸入值,計(jì)算感知機(jī)的輸出值。
如若感知機(jī)的輸出值和實(shí)例中默認(rèn)正確的輸出值不同:(1)若輸出值應(yīng)該為0但實(shí)際為1,減少輸入值是1的例子的權(quán)重。(2)若輸出值應(yīng)該為1但實(shí)際為0,增加輸入值是1的例子的權(quán)重。
對于訓(xùn)練集中下一個(gè)例子做同樣的事,重復(fù)步驟2-4直到感知機(jī)不再出錯。
這個(gè)過程很簡單,產(chǎn)生了一個(gè)簡單的結(jié)果:一個(gè)輸入線性函數(shù)(加權(quán)和),正如線性回歸被非線性激活函數(shù)「壓扁」了一樣(對帶權(quán)重求和設(shè)定閾值的行為)。當(dāng)函數(shù)的輸出值是一個(gè)有限集時(shí)(例如邏輯函數(shù),它只有兩個(gè)輸出值True/1 和 False/0),給帶權(quán)重的和設(shè)置閾值是沒問題的,所以問題實(shí)際上不在于要對任何輸入數(shù)據(jù)集生成一個(gè)數(shù)值上連續(xù)的輸出(即回歸類問題),而在于對輸入數(shù)據(jù)做好合適的標(biāo)簽(分類問題)。

康奈爾航天實(shí)驗(yàn)室的Mark I 感知機(jī),第一臺感知機(jī)的硬件?
羅森布拉特用定制硬件的方法實(shí)現(xiàn)了感知機(jī)的想法(在花哨的編程語言被廣泛使用之前),展示出它可以用來學(xué)習(xí)對20×20像素輸入中的簡單形狀進(jìn)行正確分類。自此,機(jī)器學(xué)習(xí)問世了——建造了一臺可以從已知的輸入輸出對中得出近似函數(shù)的計(jì)算機(jī)。在這個(gè)例子中,它只學(xué)習(xí)了一個(gè)小玩具般的函數(shù),但是從中不難想象出有用的應(yīng)用,例如將人類亂糟糟的手寫字轉(zhuǎn)換為機(jī)器可讀的文本。
很重要的是,這種方法還可以用在多個(gè)輸出值的函數(shù)中,或具有多個(gè)類別的分類任務(wù)。這對一臺感知機(jī)來說是不可能完成的,因?yàn)樗挥幸粋€(gè)輸出,但是,多輸出函數(shù)能用位于同一層的多個(gè)感知機(jī)來學(xué)習(xí),每個(gè)感知機(jī)接收到同一個(gè)輸入,但分別負(fù)責(zé)函數(shù)的不同輸出。實(shí)際上,神經(jīng)網(wǎng)絡(luò)(準(zhǔn)確的說應(yīng)該是「人工神經(jīng)網(wǎng)絡(luò)(ANN,Artificial Neural Networks)」)就是多層感知機(jī)(今天感知機(jī)通常被稱為神經(jīng)元)而已,只不過在這個(gè)階段,只有一層——輸出層。所以,神經(jīng)網(wǎng)絡(luò)的典型應(yīng)用例子就是分辨手寫數(shù)字。輸入是圖像的像素,有10個(gè)輸出神經(jīng)元,每一個(gè)分別對應(yīng)著10個(gè)可能的數(shù)字。在這個(gè)案例中,10個(gè)神經(jīng)元中,只有1個(gè)輸出1,權(quán)值較高的和被看做是正確的輸出,而其他的則輸出0。
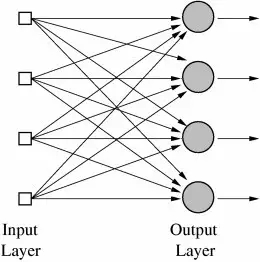
多層輸出的神經(jīng)網(wǎng)絡(luò)
?
也可以想象一個(gè)與感知機(jī)不同的人工神經(jīng)網(wǎng)絡(luò)。例如,閾值激活函數(shù)并不是必要的; 1960年,Bernard Widrow和Tedd Hoff很快開始探索一種方法——采用適應(yīng)性的「自適應(yīng)(ADALINE)」神經(jīng)元來輸出權(quán)值的輸入,這種神經(jīng)元使用化學(xué)「 存儲電阻器」,并展示了這種「自適應(yīng)線性神經(jīng)元」能夠在電路中成為「 存儲電阻器」的一部分(存儲電阻器是帶有存儲的電阻)。他們還展示了,不用閾值激活函數(shù),在數(shù)學(xué)上很美,因?yàn)樯窠?jīng)元的學(xué)習(xí)機(jī)制是基于將錯誤最小化的微積分,而微積分我們都很熟悉了。
如果我們多思考一下 「自適應(yīng)(ADALINE)」,就會有進(jìn)一步的洞見:為大量輸入找到一組權(quán)重真的只是一種線性回歸。再一次,就像用線性回歸一樣,這也不足以解決諸如語音識別或計(jì)算機(jī)視覺這樣的人工智能難題。McCullough,Pitts和羅森布拉特真正感到興奮的是聯(lián)結(jié)主義(Connectionism)這個(gè)寬泛的想法:如此簡單計(jì)算機(jī)單元構(gòu)成的網(wǎng)絡(luò),其功能會大很多而且可以解決人工智能難題。而且羅森布拉特說的和(坦白說很可笑的)《紐約時(shí)報(bào)》這段引文的意思差不多:
海軍披露了一臺尚處初期的電子計(jì)算機(jī),期待這臺電子計(jì)算機(jī)能行走,談話,看和寫,自己復(fù)制出自身存在意識…羅森布拉特博士,康奈爾航空實(shí)驗(yàn)室的一位心理學(xué)家說,感知機(jī)能作為機(jī)械太空探險(xiǎn)者被發(fā)射到行星上。
這種談話無疑會惹惱人工領(lǐng)域的其他研究人員,其中有許多研究人員都在專注于這樣的研究方法,它們以帶有具體規(guī)則(這些規(guī)則遵循邏輯數(shù)學(xué)法則)的符號操作為基礎(chǔ)。MIT人工智能實(shí)驗(yàn)室創(chuàng)始人Marvin Minsky和Seymour Paper就是對這一炒作持懷疑態(tài)度研究人員中的兩位,1969年,他們在一本開創(chuàng)性著作中表達(dá)了這種質(zhì)疑,書中嚴(yán)謹(jǐn)分析了感知機(jī)的局限性,書名很貼切,叫《感知機(jī)》。
他們分析中,最被廣為討論的內(nèi)容就是對感知機(jī)限制的說明,例如,他們不能學(xué)習(xí)簡單的布爾函數(shù)XOR,因?yàn)樗荒苓M(jìn)行線性分離。雖然此處歷史模糊,但是,人們普遍認(rèn)為這本書對人工智能步入第一個(gè)冬天起到了推波助瀾的作用——大肆炒作之后,人工智能進(jìn)入泡沫幻滅期,相關(guān)資助和出版都遭凍結(jié)。
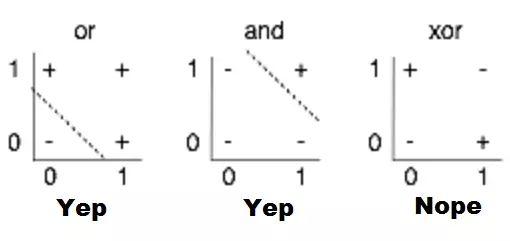
感知機(jī)局限性的視覺化。找到一個(gè)線性函數(shù),輸入X,Y時(shí)可以正確地輸出+或-,就是在2D圖表上畫一條從+中分離出-的線;很顯然,就第三幅圖顯示的情況來看,這是不可能的
人工智能冬天的復(fù)蘇
因此,情況對神經(jīng)網(wǎng)絡(luò)不利。但是,為什么?他們的想法畢竟是想將一連串簡單的數(shù)學(xué)神經(jīng)元結(jié)合在一起,完成一些復(fù)雜任務(wù),而不是使用單個(gè)神經(jīng)元。換句話說,并不是只有一個(gè)輸出層,將一個(gè)輸入任意傳輸?shù)蕉鄠€(gè)神經(jīng)元(所謂的隱藏層,因?yàn)樗麄兊妮敵鰰鳛榱硪浑[藏層或神經(jīng)元輸出層的輸入)。只有輸出層的輸出是「可見」的——亦即神經(jīng)網(wǎng)絡(luò)的答案——但是,所有依靠隱藏層完成的間接計(jì)算可以處理復(fù)雜得多的問題,這是單層結(jié)構(gòu)望塵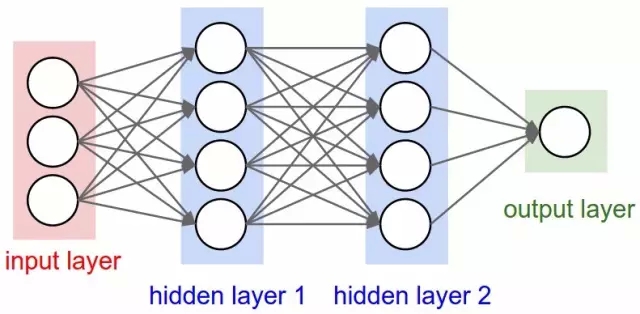
有兩個(gè)隱藏層的神經(jīng)網(wǎng)絡(luò)?
言簡意賅地說,多個(gè)隱藏層是件好事,原因在于隱藏層可以找到數(shù)據(jù)內(nèi)在特點(diǎn),后續(xù)層可以在這些特點(diǎn)(而不是嘈雜龐大的原始數(shù)據(jù))基礎(chǔ)上進(jìn)行操作。以圖片中的面部識別這一非常常見的神經(jīng)網(wǎng)絡(luò)任務(wù)為例,第一個(gè)隱藏層可以獲得圖片的原始像素值,以及線、圓和橢圓等信息。接下來的層可以獲得這些線、圓和橢圓等的位置信息,并且通過這些來定位人臉的位置——處理起來簡單多了!而且人們基本上也都明白這一點(diǎn)。事實(shí)上,直到最近,機(jī)器學(xué)習(xí)技術(shù)都沒有普遍直接用于原始數(shù)據(jù)輸入,比如圖像和音頻。相反,機(jī)器學(xué)習(xí)被用于經(jīng)過特征提取后的數(shù)據(jù)——也就是說,為了讓學(xué)習(xí)更簡單,機(jī)器學(xué)習(xí)被用在預(yù)處理的數(shù)據(jù)上,一些更加有用的特征,比如角度,形狀早已被從中提取出來。
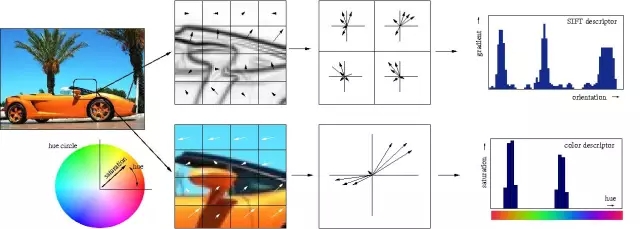
傳統(tǒng)的特征的手工提取過程的視覺化
?
因此,注意到這一點(diǎn)很重要:Minsky和Paper關(guān)于感知機(jī)的分析不僅僅表明不可能用單個(gè)感知機(jī)來計(jì)算XOR,而且特別指出需要多層感知機(jī)——亦即現(xiàn)在所謂的多層神經(jīng)網(wǎng)絡(luò)——才可以完成這一任務(wù),而且羅森布拉特的學(xué)習(xí)算法對多層并不管用。那是一個(gè)真正的問題:之前針對感知機(jī)概括出的簡單學(xué)習(xí)規(guī)則并不是適用于多層結(jié)構(gòu)。想知道原因?讓我們再來回顧一下單層結(jié)構(gòu)感知機(jī)如何學(xué)習(xí)計(jì)算一些函數(shù):
和函數(shù)輸出數(shù)量相等的感知機(jī)會以小的初始權(quán)值開始(僅為輸入函數(shù)的倍數(shù))
選取訓(xùn)練集中的一個(gè)例子作為輸入,計(jì)算感知機(jī)的輸出
對于每一個(gè)感知機(jī),如果其計(jì)算結(jié)果和該例子的結(jié)果不匹配,調(diào)整初始權(quán)值
繼續(xù)采用訓(xùn)練集中的下一個(gè)例子,重復(fù)過程2到4次,直到感知機(jī)不再犯錯。
這一規(guī)則并不適用多層結(jié)構(gòu)的原因應(yīng)該很直觀清楚了:選取訓(xùn)練集中的例子進(jìn)行訓(xùn)練時(shí),我們只能對最終的輸出層的輸出結(jié)果進(jìn)行校正,但是,對于多層結(jié)構(gòu)來說,我們該如何調(diào)整最終輸出層之前的層結(jié)構(gòu)權(quán)值呢?答案(盡管需要花時(shí)間來推導(dǎo))又一次需要依賴古老的微積分:鏈?zhǔn)椒▌t。這里有一個(gè)重要現(xiàn)實(shí):神經(jīng)網(wǎng)絡(luò)的神經(jīng)元和感知機(jī)并不完全相同,但是,可用一個(gè)激活函數(shù)來計(jì)算輸出,該函數(shù)仍然是非線性的,但是可微分,和Adaline神經(jīng)元一樣;該導(dǎo)數(shù)不僅可以用于調(diào)整權(quán)值,減少誤差,鏈?zhǔn)椒▌t也可用于計(jì)算前一層所有神經(jīng)元導(dǎo)數(shù),因此,調(diào)整它們權(quán)重的方式也是可知的。說得更簡單些:我們可以利用微積分將一些導(dǎo)致輸出層任何訓(xùn)練集誤差的原因分配給前一隱藏層的每個(gè)神經(jīng)元,如果還有另外一層隱藏層,我們可以將這些原因再做分配,以此類推——我們在反向傳播這些誤差。而且,如果修改了神經(jīng)網(wǎng)絡(luò)(包括那些隱藏層)任一權(quán)重值,我們還可以找出誤差會有多大變化,通過優(yōu)化技巧(時(shí)間長,典型的隨機(jī)梯度下降)找出最小化誤差的較佳權(quán)值。
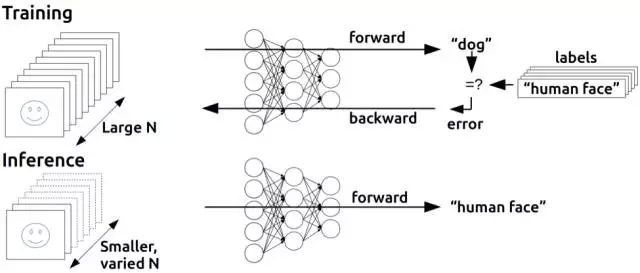
反向傳播的基本思想?
反向傳播由上世紀(jì)60年代早期多位研究人員提出,70年代,由Seppo Linnainmaa引入電腦運(yùn)行,但是,Paul Werbos在1974年的博士畢業(yè)論文中深刻分析了將之用于神經(jīng)網(wǎng)絡(luò)方面的可能性,成為美國第一位提出可以將其用于神經(jīng)網(wǎng)絡(luò)的研究人員。有趣的是,他從模擬人類思維的研究工作中并沒有獲得多少啟發(fā),在這個(gè)案例中,弗洛伊德心理學(xué)理論啟發(fā)了他,正如他自己敘述:
1968年,我提出我們可以多少模仿弗洛伊德的概念——信度指派的反向流動( a backwards flow of credit assignment,),指代從神經(jīng)元到神經(jīng)元的反向流動…我解釋過結(jié)合使用了直覺、實(shí)例和普通鏈?zhǔn)椒▌t的反向計(jì)算,雖然它正是將弗洛伊德以前在心理動力學(xué)理論中提出的概念運(yùn)用到數(shù)學(xué)領(lǐng)域中!
?
盡管解決了如何訓(xùn)練多層神經(jīng)網(wǎng)絡(luò)的問題,在寫作自己的博士學(xué)位論文時(shí)也意識到了這一點(diǎn),但是,Werbos沒有發(fā)表將BP算法用于神經(jīng)網(wǎng)絡(luò)這方面的研究,直到1982年人工智能冬天引發(fā)了寒蟬效應(yīng)。實(shí)際上,Werbos認(rèn)為,這種研究進(jìn)路對解決感知機(jī)問題是有意義的,但是,這個(gè)圈子大體已經(jīng)失去解決那些問題的信念。
Minsky的書最著名的觀點(diǎn)有幾個(gè):(1)我們需要用MLPs[多層感知機(jī),多層神經(jīng)網(wǎng)絡(luò)的另一種說法)來代表簡單的非線性函數(shù),比如XOR 映射;而且(2)世界上沒人發(fā)現(xiàn)可以將MLPs訓(xùn)練得夠好,以至于可以學(xué)會這么簡單的函數(shù)的方法。Minsky的書讓世上絕大多數(shù)人相信,神經(jīng)網(wǎng)絡(luò)是最糟糕的異端,死路一條。Widrow已經(jīng)強(qiáng)調(diào),這種壓垮早期『感知機(jī)』人工智能學(xué)派的悲觀主義不應(yīng)怪在Minsky的頭上。他只是總結(jié)了幾百位謹(jǐn)慎研究人員的經(jīng)驗(yàn)而已,他們嘗試找出訓(xùn)練MLPs的辦法,卻徒勞無功。也曾有過希望,比如Rosenblatt所謂的backpropagation(這和我們現(xiàn)在說的 backpropagation并不完全相同!),而且Amari也簡短表示,我們應(yīng)該考慮將最小二乘(也是簡單線性回歸的基礎(chǔ))作為訓(xùn)練神經(jīng)網(wǎng)絡(luò)的一種方式(但沒有討論如何求導(dǎo),還警告說他對這個(gè)方法不抱太大期望)。但是,當(dāng)時(shí)的悲觀主義開始變得致命。上世紀(jì)七十年代早期,我確實(shí)在MIT采訪過Minsky。我建議我們合著一篇文章,證明MLPs實(shí)際上能夠克服早期出現(xiàn)的問題…但是,Minsky并無興趣(14)。事實(shí)上,當(dāng)時(shí)的MIT,哈佛以及任何我能找到的研究機(jī)構(gòu),沒人對此有興趣。
?
我肯定不能打保票,但是,直到十年后,也就是1986年,這一研究進(jìn)路才開始在David Rumelhart, Geoffrey Hinton和Ronald Williams合著的《Learning representations by back-propagating errors》中流行開來,原因似乎就是缺少學(xué)術(shù)興趣。
盡管研究方法的發(fā)現(xiàn)不計(jì)其數(shù)(論文甚至清楚提道,David Parker 和 Yann LeCun是事先發(fā)現(xiàn)這一研究進(jìn)路的兩人),1986年的這篇文章卻因其較精確清晰的觀點(diǎn)陳述而顯得很突出。實(shí)際上,學(xué)機(jī)器學(xué)習(xí)的人很容易發(fā)現(xiàn)自己論文中的描述與教科書和課堂上解釋概念方式本質(zhì)上相同。
不幸的是,科學(xué)圈里幾乎無人知道Werbo的研究。1982年,Parker重新發(fā)現(xiàn)了這個(gè)研究辦法[39]并于1985年在M.I.T[40]上發(fā)表了一篇相關(guān)報(bào)道。就在Parker報(bào)道后不久,Rumelhart, Hinton和Williams [41], [42]也重新發(fā)現(xiàn)了這個(gè)方法, 他們最終成功地讓這個(gè)方法家喻戶曉,也主要?dú)w功于陳述觀點(diǎn)的框架非常清晰。
但是,這三位作者沒有止步于介紹新學(xué)習(xí)算法,而是走得更遠(yuǎn)。同年,他們發(fā)表了更有深度的文章《Learning internal representations by error propagation》。
文章特別談到了Minsky在《感知機(jī)》中討論過的問題。盡管這是過去學(xué)者的構(gòu)想,但是,正是這個(gè)1986年提出的構(gòu)想讓人們廣泛理解了應(yīng)該如何訓(xùn)練多層神經(jīng)網(wǎng)絡(luò)解決復(fù)雜學(xué)習(xí)問題。而且神經(jīng)網(wǎng)絡(luò)也因此回來了!第二部分,我們將會看到幾年后,《Learning internal representations by error propagation》探討過的BP算法和其他一些技巧如何被用來解決一個(gè)非常重要的問題:讓計(jì)算機(jī)識別人類書寫。(待續(xù))
?
參考文獻(xiàn)
Christopher D. Manning. (2015). Computational Linguistics and Deep Learning Computational Linguistics, 41(4), 701–707.?
F. Rosenblatt. The perceptron, a perceiving and recognizing automaton Project Para. Cornell Aeronautical Laboratory, 1957. ?
W. S. McCulloch and W. Pitts. A logical calculus of the ideas immanent in nervous activity. The bulletin of mathematical biophysics, 5(4):115–133, 1943. ?
The organization of behavior: A neuropsychological theory. D. O. Hebb. John Wiley And Sons, Inc., New York, 1949 ?
B. Widrow et al. Adaptive ”Adaline” neuron using chemical ”memistors”. Number Technical Report 1553-2. Stanford Electron. Labs., Stanford, CA, October 1960. ?
“New Navy Device Learns By Doing”, New York Times, July 8, 1958. ?
Perceptrons. An Introduction to Computational Geometry. MARVIN MINSKY and SEYMOUR PAPERT. M.I.T. Press, Cambridge, Mass., 1969. ?
Linnainmaa, S. (1970). The representation of the cumulative rounding error of an algorithm as a Taylor expansion of the local rounding errors. Master’s thesis, Univ. Helsinki. ?
P. Werbos. Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences. PhD thesis, Harvard University, Cambridge, MA, 1974. ?
Werbos, P.J. (2006). Backwards differentiation in AD and neural nets: Past links and new opportunities. In Automatic Differentiation: Applications, Theory, and Implementations, pages 15-34. Springer. ?
Rumelhart, D. E., Hinton, G. E., and Williams, R. J. (1986). Learning representations by back-propagating errors. Nature, 323, 533–536. ?
Widrow, B., & Lehr, M. (1990). 30 years of adaptive neural networks: perceptron, madaline, and backpropagation. Proceedings of the IEEE, 78(9), 1415-1442. ?
D. E. Rumelhart, G. E. Hinton, and R. J. Williams. 1986. Learning internal representations by error propagation. In Parallel distributed processing: explorations in the microstructure of cognition, vol. 1, David E. Rumelhart, James L. McClelland, and CORPORATE PDP Research Group (Eds.). MIT Press, Cambridge, MA, USA 318-362 ?
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4349.html
摘要:如何看待人工智能的本質(zhì)人工智能的飛速發(fā)展又經(jīng)歷了哪些歷程本文就從技術(shù)角度為大家介紹人工智能領(lǐng)域經(jīng)常提到的幾大概念與發(fā)展簡史。一人工智能相關(guān)概念人工智能就是讓機(jī)器像人一樣的智能會思考是機(jī)器學(xué)習(xí)深度學(xué)習(xí)在實(shí)踐中的應(yīng)用。 作為近幾年的一大熱詞,人工智能一直是科技圈不可忽視的一大風(fēng)口。隨著智能硬件的迭代,智能家居產(chǎn)品逐步走進(jìn)千家萬戶,語音識別、圖像識別等AI相關(guān)技術(shù)也經(jīng)歷了階梯式發(fā)展。如何看待...
摘要:如何看待人工智能的本質(zhì)人工智能的飛速發(fā)展又經(jīng)歷了哪些歷程本文就從技術(shù)角度為大家介紹人工智能領(lǐng)域經(jīng)常提到的幾大概念與發(fā)展簡史。一人工智能相關(guān)概念人工智能就是讓機(jī)器像人一樣的智能會思考是機(jī)器學(xué)習(xí)深度學(xué)習(xí)在實(shí)踐中的應(yīng)用。 作為近幾年的一大熱詞,人工智能一直是科技圈不可忽視的一大風(fēng)口。隨著智能硬件的迭代,智能家居產(chǎn)品逐步走進(jìn)千家萬戶,語音識別、圖像識別等AI相關(guān)技術(shù)也經(jīng)歷了階梯式發(fā)展。如何看待...

閱讀 765·2019-08-29 16:32
閱讀 836·2019-08-29 12:31
閱讀 3208·2019-08-26 18:26
閱讀 3152·2019-08-26 12:20
閱讀 1727·2019-08-26 12:00
閱讀 3006·2019-08-26 10:58
閱讀 2811·2019-08-23 17:08
閱讀 2308·2019-08-23 16:32



