資訊專欄INFORMATION COLUMN

摘要:十三套框架助你玩轉機器學習技術在今天的文章中,我們將共同了解十三款機器學習框架,一部分去年剛剛發布另一部分則在不久前進行了全部升級。目前該項目正積極添加對的支持能力,不過此類項目一般更傾向于直接面向各承載機器學習任務的主流環境。
導讀
過去幾年以來,機器學習已經開始以前所未有的方式步入主流層面。這種趨勢并非單純由低成本云環境乃至極為強大的GPU硬件所推動; 除此之外,面向機器學習的可用框架也迎來了爆發式增長。此類框架全部為開源成果,但更重要的是它們在設計方面將更為復雜的部分從機器學習中抽象了出來,從而保證相關技術方案能夠為更多開發人員服務。

在今天的文章中,我們將共同了解十三款機器學習框架,一部分去年剛剛發布、另一部分則在不久前進行了全部升級。而這些框架中最值得關注的特性,在于它們正致力于通過簡單而新穎的方式應對與機器學習相關的種種挑戰。
Apache Spark MLlib
Apache Spark可能算得上當前Hadoop家族當中更為耀眼的成員,但這套內存內數據處理框架在誕生之初實際與Hadoop并無關系,且憑借著自身出色的特性在Hadoop生態系統之外闖出一片天地。Spark目前已經成為一款即時可用的機器學習工具,這主要歸功于其能夠以高速將算法庫應用至內存內數據當中。
Spark仍處于不斷發展當中,而Spark當中的可用算法亦在持續增加及改進。去年的1.5版本添加了眾多新算法,對現有算法做出改進,同時進一步通過持續流程恢復了MLlib中的Spark ML任務。
Apache Singa
這套“深層學習”框架能夠支持多種高強度機器學習功能,具體包括自然語言處理與圖像識別。Singa最近被納入Apache孵化器項目,這套開源框架致力于降低大規模數據的深層學習模型訓練難度。
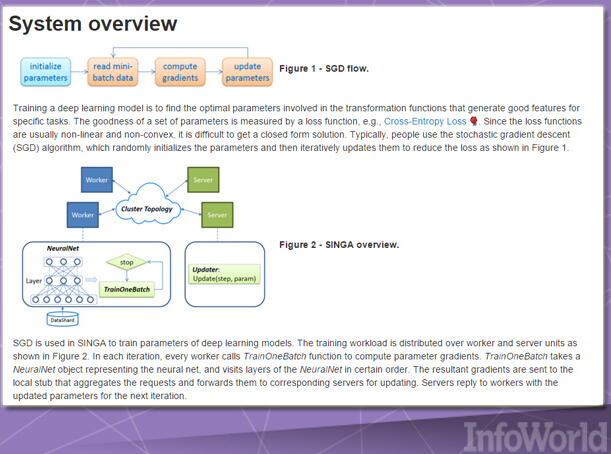
Singa提供一套簡單的編程模式,用于跨越一整套設備集群進行深層學習網絡訓練,同時支持多種常規訓練任務類型; 卷積神經網絡、受限玻爾茲曼機與復發性神經網絡。各模型能夠進行同步(一一)或者異步(并行)訓練,具體取決于實際問題的具體需求。Singa還利用Apache Zookeeper對集群設置進行了簡化。
Caffe
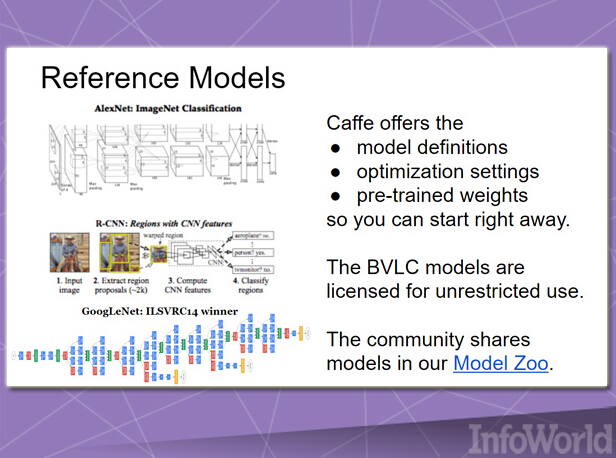
深層學習框架Caffe是一套“立足于表達、速度與模塊化”的解決方案。其最初誕生于2013年,主要用于機器視覺項目。Caffe自出現之后就一直將多種其它應用囊括入自身,包括語音與多媒體。
由于優先考量速度需求,因此Caffe全部利用C++編寫而成,同時支持CUDA加速機制。不過它也能夠根據需要在CPU與GPU處理流程間往來切換。其發行版中包含一系列免費與開源參考模型,主要面向各類常規典型任務; 目前Caffe用戶社區亦在積極開發其它模型。
微軟Azure ML Studio
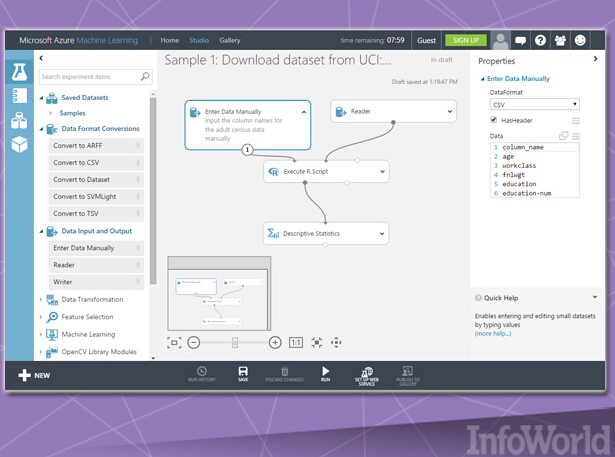 根據機器學習任務的實際數據規模與計算性能需求,云往往能夠成為機器學習應用的一大理想運行環境。微軟公司已經立足于Azure發布了其按需計費機器學習服務,即Azure ML Studio,其能夠提供按月、按小時以及免費等分層版本。(微軟公司的HowOldRobot項目亦利用這套系統創建而成。)
根據機器學習任務的實際數據規模與計算性能需求,云往往能夠成為機器學習應用的一大理想運行環境。微軟公司已經立足于Azure發布了其按需計費機器學習服務,即Azure ML Studio,其能夠提供按月、按小時以及免費等分層版本。(微軟公司的HowOldRobot項目亦利用這套系統創建而成。)
Azure ML Studio允許用戶創建并訓練模型,而后將其轉化為能夠由其它服務消費的API。每個用戶賬戶能夠為模型數據提供較高10 GB存儲容量,不過大家也可以將自己的Azure存儲資源連接至服務當中以承載規模更大的模型。目前可用算法已經相當可觀,其分別由微軟自身以及其它第三方所提供。大家甚至不需要賬戶即可體驗這項服務; 用戶可以匿名登錄并最多使用八小時Azure ML Studio。
Amazon Machine Learning

Amazon的這套面向云服務的通用型方案遵循既定模式。其提供核心用戶更為關注的運行基礎,幫助他們立足于此尋求自身最需要的機器學習方案并加以交付。
Amazon Machine Learning同時也是云巨頭首次嘗試推出機器學習即服務方案。它能夠接入被保存在Amazon S3、Redshift或者RDS當中的數據,并能夠運行二進制分類、多類分類或者數據遞歸以創建模型。然而,該服務高度依賴于Amazon本身。除了要求數據必須被存儲于Amazon之內之外,其結果模型也無法進行導入與導出,另外訓練模型的數據庫集亦不可超過100 GB。當然,這只是Amazon Machine Learning的起步成效,其也足以證明機器學習完全具備可行性——而非技術巨頭的奢侈玩物。
微軟分布式機器學習工具包
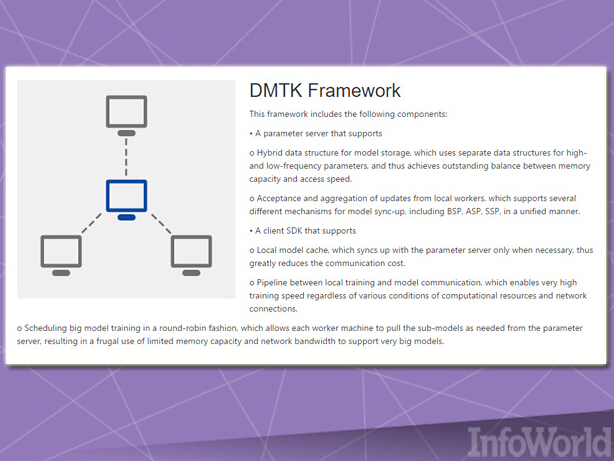
我們用于解決機器學習難題的設備數量越多,實際效果就越好——但將大量設備匯聚起來并開發出能夠順利跨越各設備運行的機器學習應用絕非易事。微軟的DMTK(即分布式機器學習工具包)框架則能夠輕松跨越一整套系統集群解決多種機器學習任務類型的分發難題。
DMTK的計費機制歸屬于框架而非完整的開箱即用解決方案,因此其中實際涉及的算法數量相對較小。不過DMTK在設計上允許用戶進行后續擴展,同時發揮現有集群之內的有限資源。舉例來說,集群中的每個節點都擁有一套本地緩存,其能夠由中央服務器節點為當前任務提供參數,從而降低實際流量規模。
谷歌TensorFlow
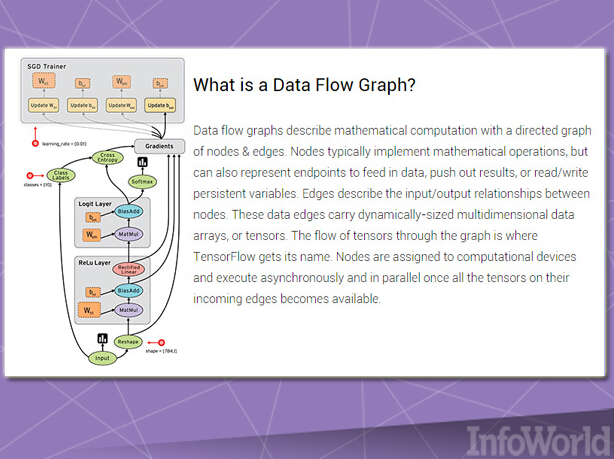
與微軟的DMTK類似,谷歌TensorFlow是一套專門面向多節點規模設計而成的機器學習框架。與谷歌的Kubernetes類似,TensorFlow最初也是為谷歌內部需求所量身打造,但谷歌公司最終決定將其以開源產品進行發布。
TensorFlow能夠實現所謂數據流圖譜,其中批量數據(即‘tensor’,意為張量)可通過一系列由圖譜描述的算法進行處理。系統之內往來移動的數據被稱為“流”,可由CPU或者GPU負責處理。谷歌公司的長期規劃在于通過第三方貢獻者推動TensorFlow項目的后續發展。
微軟計算網絡工具包
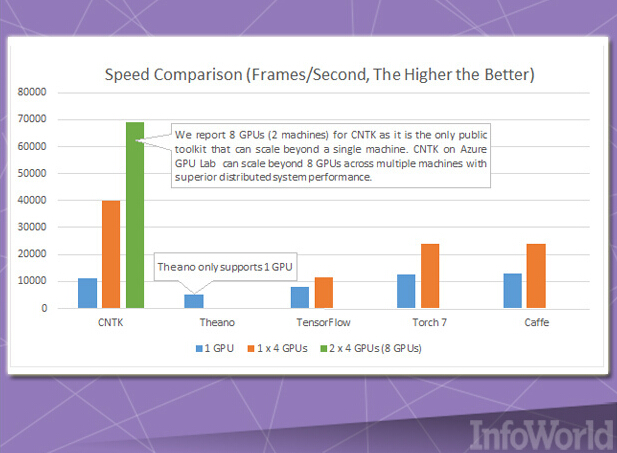
趁著DMTK的推出良機,微軟公司還發布了另一套機器學習工具包,即計算網絡工具包——或者簡稱CNTK。
CNTK與谷歌TensorFlow非常類似,因為它允許用戶通過有向圖的方式建立神經網絡。另外,微軟還將其視為可與Caffe、Theano以及Torch等項目相媲美的技術成果。它的主要亮點在于出色的速度表現,特別是以并行方式利用多CPU與多GPU的能力。微軟公司宣稱,其利用CNTK與Azure之上的GPU集群共同將Cortana語音識別服務訓練的速度提升到了新的數量級。
最初作為微軟語音識別項目組成部分開發而成的CNTK,最終于2015年4月以開源項目形式走向公眾視野——但其隨后以更為寬松的MIT類別許可在GitHub進行了重新發布。
Veles (三星)
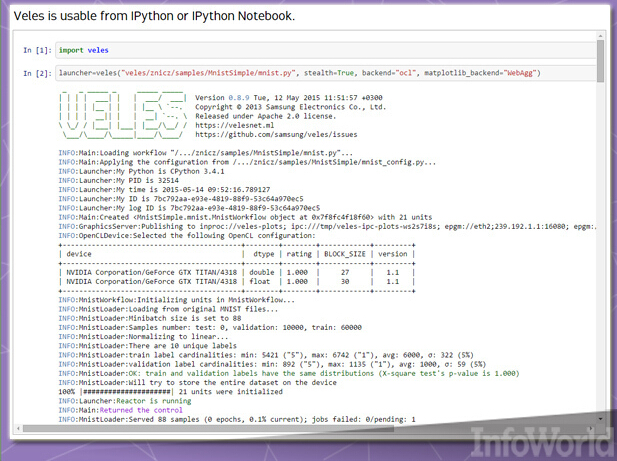
Veles是一套面向深層學習應用程序的分布式平臺,而且與TensorFlow與DMTK一樣,它也由C++編寫而成——不過它利用Python在不同節點之間執行自動化與協作任務。相關數據集可在被供給至該集群之前經過分析與自動標準化調整,另外其還具備REST API以允許將各已訓練模型立即添加至生產環境當中(假設大家的硬件已經準備就緒)。
Veles并非單純利用Python作為其粘合代碼。IPython(如今已被更名為Jupyter)數據可視化與分析工具能夠對來自Veles集群的結果進行可視化處理與發布。三星公司希望能夠將該項目以開源形式發布,從而推進其進一步發展——例如面向Windows與Mac OS X。
BrainStorm
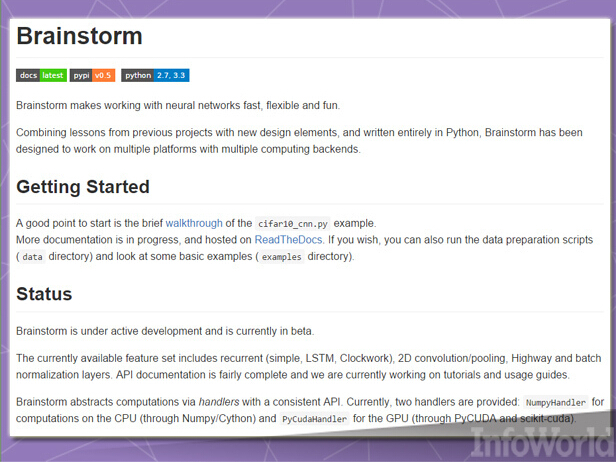
作為瑞士盧加諾博士生Klaus Greff于2015年開發的技術成果,Brainstorm項目的目標在于“幫助深層神經網絡實現高速、靈活與趣味性。”目前其已經包含有一系列常見神經網絡模型,例如LSTM。
Brainstorm采用Python代碼以提供兩套“hander”,或者稱之為數據管理API——其一來自Numpy庫以實現CPU計算,其二通過CUDA使用GPU資源。大部分工作由Python腳本完成,所以各位沒辦法指望其提供豐富的GUI前端——大家需要自己動手接入相關界面。不過從長期規劃角度看,其能夠使用“源自多種早期開源項目的學習經驗”,同時利用“能夠與多種平臺及計算后端相兼容的新的設計元素。”
mlpack 2
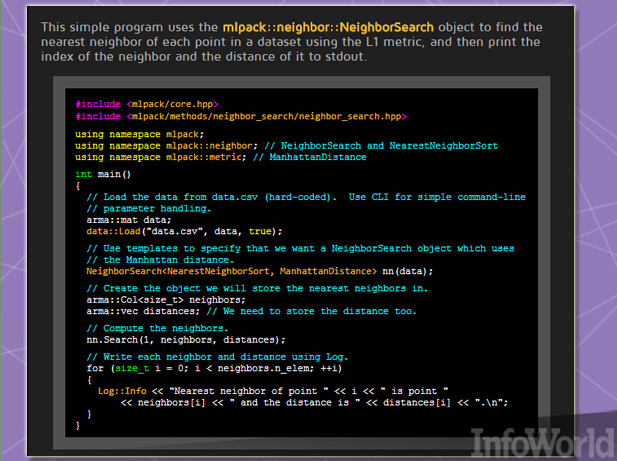
mlpack這套基于C++的機器學習庫最初誕生于2011年,其設計傾向為“可擴展性、速度性與易用性,”該庫構建者們指出。用戶可以通過命令行可執行緩存運行mlpack以實現快速運行、“黑盒”操作或者通過C++ API完成其它更為復雜的任務。
其2.0版本則擁有一系列重構與新特性,其中包括多種新算法,并對現有算法加以修改以提升運行速度或者縮小其體積。舉例來說,它能夠將Boost庫的隨機數生成器指向C++ 11的原生隨機功能。
mlpack的固有劣勢在于其缺乏除C++之外的任何其它語言綁定能力,這意味著從R語言到Python語言的各類其他用戶都無法使用mlpack——除非其他開發者推出了自己的對應語言軟件包。目前該項目正積極添加對MatLab的支持能力,不過此類項目一般更傾向于直接面向各承載機器學習任務的主流環境。
Marvin

作為另一套剛剛誕生的方案,Marvin神經網絡框架為Princeton Vision集團的開發成果。它可謂“為hack而生”,因為項目開發者們在其說明文檔當中直接做出這樣的描述,且僅僅依賴于C++編寫的數個文件及CUDA GPU框架即可運行。盡管其代碼本身的體積非常小巧,但其中仍然存在相當一部分能夠復用的部分,并可以將pull請求作為項目自身代碼進行貢獻。
Neon
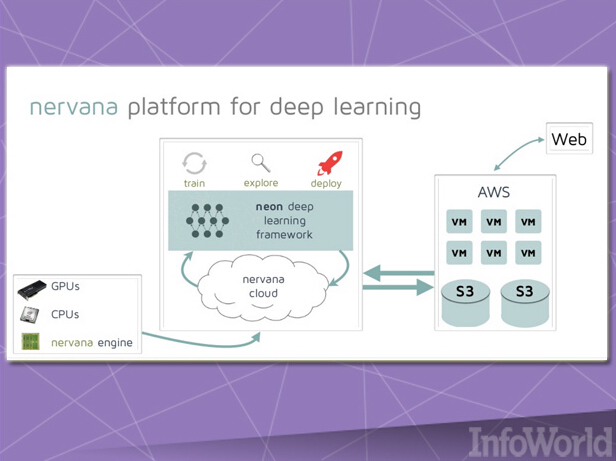
Nervana公司專門構建自己的深層學習硬件與軟件平臺,其推出了一套名為Neon的深層學習框架,并將其作為開源項目。該項目利用可插拔模塊以支持高強度負載在CPU、GPU或者Nervana自有定制化硬件上運行。
Neon主要由Python語言編寫而成,C++為其編寫了多條代碼片段并帶來可觀的運行速度。這樣的特性讓Neon立即成為各Python開發之數據科學場景或者其它綁定Python之框架的理想解決方案。

軟件開發技術群
興趣范圍包括:Java,C/C++,Python,PHP,Ruby,shell等各種語言開發經驗交流,各種框架使用,外包項目機會,學習、培訓、跳槽等交流
QQ群:26931708
Hadoop源代碼研究群
興趣范圍包括:Hadoop源代碼解讀,改進,優化,分布式系統場景定制,與Hadoop有關的各種開源項目,總之就是玩轉Hadoop
QQ群:288410967?
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4346.html
摘要:前端日報精選解密一專題之如何判斷兩個對象相等在項目上,為什么我們分別選擇了音頻框架教程發布中文深入理解筆記解構使數據訪問更便捷周二放送緩存知乎專欄個非常實用的小技巧風雨過后見彩虹個你可能不知道的屬性眾成翻譯如何在模板驅動表單中自 2017-08-09 前端日報 精選 解密 Angular WebWorker Renderer (一)JavaScript專題之如何判斷兩個對象相等在項目上...
摘要:關于請點擊這里隨著谷歌新機器學習平臺的首次展示,等于在這片沙地上首次插入了這面旗幟,后續會有比如,的等等有著高級機器學習和云基礎設施的公司比如紛至沓來。 在NEXT2016會議上,Google的Eric Schmidt提到Google所占最大的優勢之一就是站在云計算下一個十年的前沿。它不是基礎設施或者軟件,也不像純數據一樣簡單。 Crowdsourced 智能,是個進化,可以創建更加智...

閱讀 2671·2021-11-18 10:02
閱讀 3401·2021-09-28 09:35
閱讀 2585·2021-09-22 15:12
閱讀 740·2021-09-22 15:08
閱讀 3070·2021-09-07 09:58
閱讀 3464·2021-08-23 09:42
閱讀 724·2019-08-30 12:53
閱讀 2071·2019-08-29 13:51



