資訊專欄INFORMATION COLUMN

摘要:算法速度系統性能以及易用性的瓶頸,制約著目前機器學習的普及應用,分布式深度機器學習開源項目中文名深盟的誕生,正是要降低分布式機器學習的門檻。因此我們聯合數個已有且被廣泛使用的分布式機器學習系統的開發者,希望通過一個統一的組織來推動開源項目。
算法速度、系統性能以及易用性的瓶頸,制約著目前機器學習的普及應用,DMLC分布式深度機器學習開源項目(中文名深盟)的誕生,正是要降低分布式機器學習的門檻。本文由深盟項目開發者聯合撰寫,將深入介紹深盟項目當前已有的xgboost、cxxnet、Minerva和Parameter Server等組件主要解決的問題、實現方式及其性能表現,并簡要說明項目的近期規劃。文章將被收錄到《程序員》電子刊(2015.06A)人工智能實踐專題,以下為全文內容:
機器學習能從數據中學習。通常數據越多,能學習到的模型就越好。在數據獲得越來越便利的今天,機器學習應用無論在廣度上還是在深度上都有了顯著進步。雖然近年來計算能力得到了大幅提高,但它仍然遠遠不及數據的增長和機器學習模型的復雜化。因此,機器學習算法速度和系統性能是目前工業界和學術界共同關心的熱點。
高性能和易用性的開源系統能對機器學習應用的其極大的推動作用。但我們發現目前兼具這兩個特點的開源系統并不多,而且分散在各處。因此我們聯合數個已有且被廣泛使用的C++分布式機器學習系統的開發者,希望通過一個統一的組織來推動開源項目。我們為這個項目取名DMLC: Deep Machine Learning in Common,也可以認為是Distributed Machine Learning in C++。中文名為深盟。代碼將統一發布在 https://github.com/dmlc。
這個項目將來自工業界和學術界的幾組開發人員拉到了一起,希望能提供更優質和更容易使用的分布式機器學習系統,同時也希望吸引更多的開發者參與進來。本文將介紹深盟項目目前已有的幾個部件,并簡要說明項目的近期規劃。
xgboost: 速度快效果好的Boosting模型
在數據建模中,當我們有數個連續值特征時,Boosting分類器是最常用的非線性分類器。它將成百上千個分類準確率較低的樹模型組合起來,成為一個準確率很高的模型。這個模型會不斷地迭代,每次迭代就生成一顆新的樹。然而,在數據集較大較復雜的時候,我們可能需要幾千次迭代運算,這將造成巨大的計算瓶頸。
xgboost正是為了解決這個瓶頸而提出。單機它采用多線程來加速樹的構建,并依賴深盟的另一個部件rabbit來進行分布式計算。為了方便使用,xgboost提供了 Python和R語言接口。例如在R中進行完整的訓練和測試:
require(xgboost)
data(agaricus.train, package="xgboost")
data(agaricus.test, package="xgboost")
train<- agaricus.train
test<- agaricus.test
bst<- xgboost(data = train$data, label = train$label, max.depth = 2, eta = 1, nround = 100, objective = "binary:logistic")
pred<- predict(bst, test$data)
由于其高效的C++實現,xgboost在性能上超過了最常用使用的R包gbm和Python包sklearn。例如在Kaggle的希格斯子競賽數據上,單線程xgboost比其他兩個包均要快出50%,在多線程上xgboost更是有接近線性的性能提升。由于其性能和使用便利性,xgboost已經在Kaggle競賽中被廣泛使用,并已經有隊伍成功借助其拿到了第一名,如圖1所示。
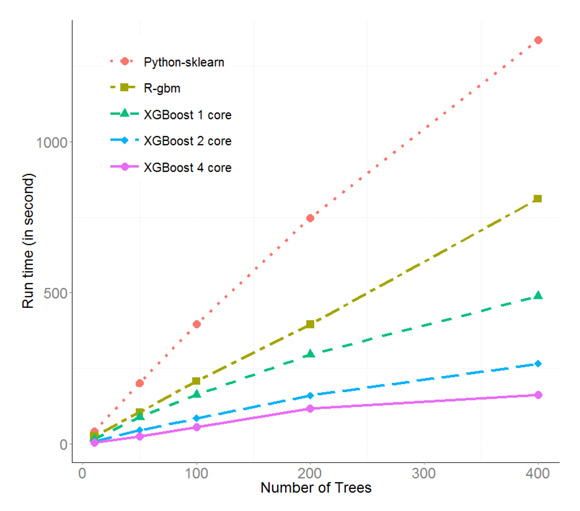
圖1 xgboost和另外兩個常用包的性能對比
CXXNET:極致的C++深度學習庫
cxxnet是一個并行的深度神經網絡計算庫,它繼承了xgboost的簡潔和極速的基因,并開始被越來越多人使用。例如Happy Lantern Festival團隊借助Cxxnet在近期的Kaggle數據科學競賽中獲得了第二名。在技術上,cxxnet有如下兩個亮點。
靈活的公式支持和極致的C++模板編程
追求速度極致的開發者通常使用C++來實現深度神經網絡。但往往需要給每個神經網絡的層和更新公式編寫獨立的CUDA kernel。很多以C++為核心的代碼之所以沒有向matlab/numpy那樣支持非常靈活的張量計算,是因為因為運算符重載和臨時空間的分配會帶來效率的降低。
然而,cxxnet利用深盟的mshadow提供了類似matlab/numpy的編程體驗,但同時保留了C++性能的高效性。其背后的核心思想是expression template,它通過模板編程技術將開發者寫的公式自動展開成優化過的代碼,避免重載操作符等帶來的額外數據拷貝和系統消耗。另外,mshadow通過模板使得非常方便的講代碼切換到CPU還是GPU運行。
通用的分布式解決方案
在分布式深度神經網絡中,我們既要處理一臺機器多GPU卡,和多臺機器多GPU卡的情況。然而后者的延遲和帶寬遠差于前者,因此需要對這種兩個情形做不同的技術考慮。cxxnet采用mshadow-ps這樣一個統一的參數共享接口,并利用接下來將要介紹Parameter Server實現了一個異步的通訊接口。其通過單機多卡和多機多卡采用不同的數據一致性模型來達到算法速度和系統性能的較佳平衡。
我們在單機4塊GTX 980顯卡的環境下測試了流行的圖片物體識別數據集ImageNet和神經網絡配置AlexNet。在單卡上,cxxnet能夠處理244張圖片每秒,而在4卡上可以提供3.7倍的加速。性能超過另一個流行深度學習計算庫Caffe (均使用CUDA 6.5,未使用cuDNN加速)。
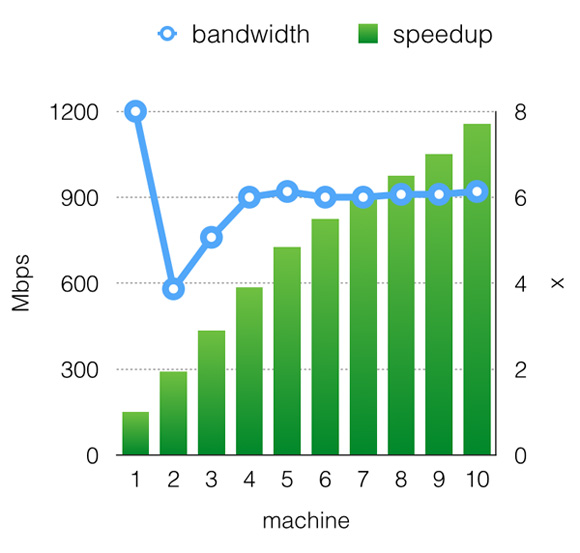
在多機情況下,我們使用Amazon EC2的GPU實例來測試性能。由于優秀的異步通信,cxxnet打滿了機器的物理帶寬,并提供了幾乎是線性的加速比,如圖2所示。
 ?
?
圖2 cxxnet在Amazon EC2上的加速比
cxxnet的另外一些特性:
輕量而齊全的框架:推薦環境下僅需要CUDA、OpenCV、MKL或BLAS即可編譯。
cuDNN支持:Nvidia原生卷積支持,可加速計算30%。
及時更新的技術:及時跟進學術界的動態,例如現在已經支持MSRA的ParametricRelu和Google的Batch Normalization。
Caffe模型轉換:支持將訓練好的Caffe模型直接轉化為cxxnet模型。
Minerva: 高效靈活的并行深度學習引擎
不同于cxxnet追求極致速度和易用性,Minerva則提供了一個高效靈活的平臺讓開發者快速實現一個高度定制化的深度神經網絡。
Minerva在系統設計上使用分層的設計原則,將“算的快”這一對于系統底層的需求和“好用”這一對于系統接口的需求隔離開來,如圖3所示。在接口上,我們提供類似numpy的用戶接口,力圖做到友好并且能充分利用Python和numpy社區已有的算法庫。在底層上,我們采用數據流(Dataflow)計算引擎。其天然的并行性能夠高效地同時地利用多GPU進行計算。Minerva通過惰性求值(Lazy Evaluation),將類numpy接口和數據流引擎結合起來,使得Minerva能夠既“好用”又“算得快”。
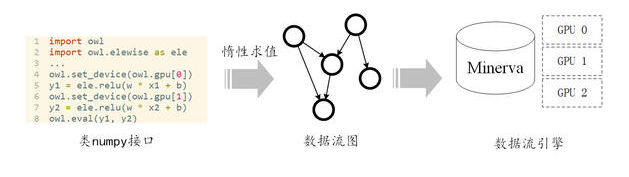
圖 3 Minerva的分層設計
惰性求值
Minerva通過自己實現的ndarray類型來支持常用的矩陣和多維向量操作。在命名和參數格式上都盡量和numpy保持一致。Minerva同時支持讀取Caffe的配置文件并進行完整的訓練。Minerva提供了兩個函數與numpy進行對接。from_numpy函數和to_numpy函數能夠在numpy的ndarray與Minerva的類型之間互相轉換。因此,將Minerva和numpy混合使用將變得非常方便。
數據流引擎和多GPU計算
從Mapreduce到Spark到Naiad,數據流引擎一直是分布式系統領域研究的熱點。數據流引擎的特點是記錄任務和任務之間的依賴關系,然后根據依賴關系對任務進行調度。沒有依賴的任務則可以并行執行,因此數據流引擎具有天然的并行性。在Minerva中,我們利用數據流的思想將深度學習算法分布到多GPU上進行計算。每一個ndarray運算在Minerva中就是一個任務,Minerva自身的調度器會根據依賴關系進行執行。用戶可以指定每個任務在哪塊卡上計算。因此如果兩個任務之間沒有依賴并且被分配到不同GPU上,那這兩個任務將能夠并行執行。同時,由于數據流調度是完全異步的,多卡間的數據通信也可以和其他任務并行執行。由于這樣的設計,Minerva在多卡上能夠做到接近線性加速比。此外,利用深盟的Parameter Server,Minerva可以輕松將數據流拓展到多機上,從而實現多卡多機的分布式訓練。
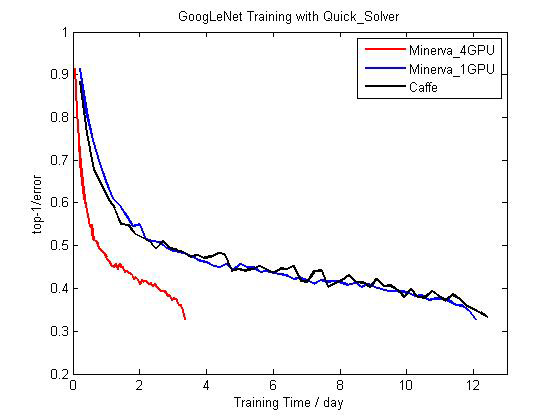
圖4 ?Minerva和Caffe在單卡和多卡上訓練GoogLeNet的比較
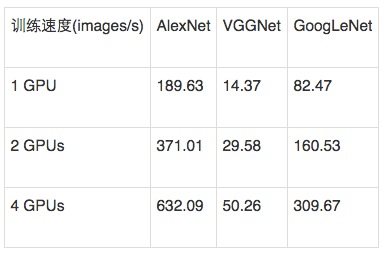 ?
?
表1 Minerva在不同網絡模型和不同GPU數目上的訓練速度
數據流引擎和多GPU計算
Minerva采用惰性求值的方式將類numpy接口和數據流引擎結合起來。每次用戶調用Minerva的ndarray運算,系統并不立即執行這一運算,而是將這一運算作為任務,異步地交給底層數據流調度器進行調度。之后,用戶的線程將繼續進行執行,并不會阻塞。這一做法帶來了許多好處:
在數據規模較大的機器學習任務中,文件I/O總是比較繁重的。而惰性求值使得用戶線程進行I/O的同時,系統底層能同時進行計算。
由于用戶線程非常輕量,因此能將更多的任務交給系統底層。其中相互沒有依賴的任務則能并行運算。
用戶能夠在接口上非常輕松地指定每個GPU上的計算任務。Minerva提供了set_device接口,其作用是在下一次set_device調用前的運算都將會在指定的GPU上進行執行。由于所有的運算都是惰性求值的,因此兩次set_device后的運算可以幾乎同時進行調度,從而達到多卡的并行。
Parameter Server: 一小時訓練600T數據
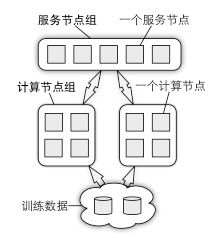
深盟的組件參數服務器(Parameter Server)對前述的應用提供分布式的系統支持。在大規模機器學習應用里,訓練數據和模型參數均可大到單臺機器無法處理。參數服務器的概念正是為解決此類問題而提出的。如圖5所示,參數以分布式形式存儲在一組服務節點中,訓練數據則被劃分到不同的計算節點上。這兩組節點之間數據通信可歸納為發送(push)和獲取(pull)兩種。例如,一個計算節點既可以把自己計算得到的結果發送到所有服務節點上,也可以從服務節點上獲取新模型參數。在實際部署時,通常有多組計算節點執行不同的任務,甚至是更新同樣一組模型參數。
 ?
?
圖5 參數服務器架構
在技術上,參數服務器主要解決如下兩個分布式系統的技術難點。
降低網絡通信開銷
在分布式系統中,機器通過網絡通信來共同完成任務。但不論是按照延時還是按照帶寬,網絡通信速度都是本地內存讀寫的數十或數百分之一。解決網絡通信瓶頸是設計分布式系統的關鍵。
異步執行
在一般的機器學習算法中,計算節點的每一輪迭代可以劃分成CPU繁忙和網絡繁忙這兩個階段。前者通常是在計算梯度部分,后者則是在傳輸梯度數據和模型參數部分。串行執行這兩個階段將導致CPU和網絡總有一個處于空閑狀態。我們可以通過異步執行來提升資源利用率。例如,當前一輪迭代的CPU繁忙階段完成時,可直接開始進行下一輪的CPU繁忙階段,而不是等到前一輪的網絡繁忙階段完成。這里我們隱藏了網絡通信開銷,從而將CPU的使用率較大化。但由于沒有等待前一輪更新的模型被取回,會導致這個計算節點的模型參數與服務節點處的參數不一致,由此可能會影響算法效率。
靈活的數據一致性模型
數據不一致性需要考慮提高算法效率和發揮系統性能之間的平衡。較好的平衡點取決于很多因素,例如CPU計算能力、網絡帶寬和算法的特性。我們發現很難有某個一致性模型能適合所有的機器學習問題。為此,參數服務器提供了一個靈活的方式用于表達一致性模型。
首先執行程序被劃分為多個任務。一個任務類似于一個遠程過程調用(Remote Procedure Call, RPC),可以是一個發送或一個獲取,或者任意一個用戶定義的函數,例如一輪迭代。任務之間可以并行執行,也可以加入依賴關系的控制邏輯,來串行執行,以確保數據的一致性。所有這些任務和依賴關系組成一個有向無環圖,從而定義一個數據一致性模型,如圖6所示。
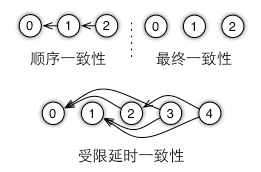
圖6 使用有向無環圖來定義數據一致性模型
如圖7所示,我們可以在相鄰任務之間加入依賴關系的控制邏輯,得到順序一致性模型,或者不引入任何依賴關系的邏輯控制,得到最終一致性模型。在這兩個極端模型之間是受限延時模型。這里一個任務可以和最近的數個任務并行執行,但必須等待超過較大延時的未完成任務的完成。我們通過使用較大允許的延時來控制機器在此之前的數據不一致性。
 ?
?
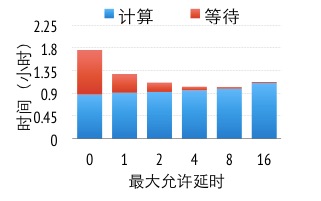
圖7 不同數據一致性下運行時間
圖8展示了在廣告點擊預測中(細節描述見后文),不同的一致性模型下得到同樣精度參數模型所花費的時間。當使用順序一致性模型時(0延時),一半的運行時間花費在等待上。當我們逐漸放松數據一致性要求,可以看到計算時間隨著較大允許的延時緩慢上升,這是由于數據一致性減慢了算法的收斂速度,但由于能有效地隱藏網絡通信開銷,從而明顯降低了等待時間。在這個實驗里,較佳平衡點是較大延時為8。
選擇性通信
任務之間的依賴關系可以控制任務間的數據一致性。而在一個任務內,我們可以通過自定義過濾器來細粒度地控制數據一致性。這是因為一個節點通常在一個任務內有數百或者更多對的關鍵字和值(key, value)需要通信傳輸,過濾器對這些關鍵字和值進行選擇性的通信。例如我們可以將較上次同步改變值小于某個特定閾值的關鍵字和值過濾掉。再如,我們設計了一個基于算法最優條件的KKT過濾器,它可過濾掉對參數影響弱的梯度。我們在實際中使用了這個過濾器,可以過濾掉至少95%的梯度值,從而節約了大量帶寬。
緩沖與壓縮
我們為參數服務器設計了基于區段的發送和獲取通信接口,既能靈活地滿足機器學習算法的通信需求,又盡可能地進行批量通信。在訓練過程中,通常是值發生變化,而關鍵字不變。因此可以讓發送和接收雙方緩沖關鍵字,避免重復發送。此外,考慮到算法或者自定義過濾器的特性,這些通信所傳輸的數值里可能存在大量“0”,因此可以利用數據壓縮有效減少通信量。
容災
大規模機器學習任務通常需要大量機器且耗時長,運行過程中容易發生機器故障或被其他優先級高的任務搶占資源。為此,我們收集了一個數據中心中3個月內所有的機器學習任務。根據“機器數×用時”的值,我們將任務分成大中小三類,并發現小任務(100機器時)的平均失敗率是6.5%;中任務(1000機器時)的失敗率超過了13%;而對于大任務(1萬機器時),每4個中至少有1個會執行失敗。因此機器學習系統必須具備容災功能。
參數服務器中服務節點和計算節點采用不同的容災策略。對于計算節點,可以采用重啟任務,丟棄失敗節點,或者其他與算法相關的策略。而服務節點維護的是全局參數,若數據丟失和下線會嚴重影響應用的運行,因此對其數據一致性和恢復時效性要求更高。
參數服務器中服務節點的容災采用的是一致性哈希和鏈備份。服務節點在存儲模型參數時,通過一致性哈希協議維護一段或者數段參數。這個協議用于確保當有服務節點發生變化時,只有維護相鄰參數段的服務節點會受到影響。每個服務節點維護的參數同時會在數個其他服務節點上備份。當一個服務節點收到來自計算節點的數據時,它會先將此數據備份到其備份節點上,然后再通知計算節點操作完成。中間的任何失敗都會導致這次發送失敗,但不會造成數據的不一致。
鏈備份適用于任何機器學習算法,但會使網絡通信量成倍增長,從而可能形成性能瓶頸。對于某些算法,我們可以采用先聚合再備份的策略來減少通信。例如,在梯度下降算法里,每個服務節點先聚合來自所有計算節點的梯度,之后再更新模型參數,因此可以只備份聚合后的梯度而非來自每個計算節點的梯度。聚合可以有效減少備份所需通信量,但聚合會使得通信的延遲增加。不過這可以通過前面描述的異步執行來有效地隱藏。
在實現聚合鏈備份時,我們可以使用向量鐘(vector clock)來記錄收到了哪些節點的數據。向量鐘允許我們準確定位未完成的節點,從而對節點變更帶來的影響進行最小化。由于參數服務器的通信接口是基于區段發送的,所有區段內的關鍵字可以共享同一個向量鐘來壓縮其存儲開銷。
?
 ?
?
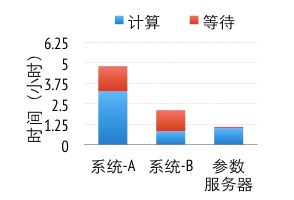
圖8 三個系統在訓練得到同樣精度的模型時所各花費的時間
參數服務器不僅為深盟其他組件提供分布式支持,也可以直接在上面開發應用。例如,我們實現了一個分塊的Proximal Gradient算法來解決稀疏的Logistic Regression,這是最常用的一個線性模型,被大量的使用在點擊預測等分類問題中。
為了測試算法性能,我們采集了636TB真實廣告點擊數據,其中含有1700億樣本和650億特征,并使用1000臺機器共1.6萬核來進行訓練。我們使用兩個服務產品的私有系統(均基于參數服務器架構)作為基線。圖8展示的是這3個系統為了達到同樣精度的模型所花費的時間。系統A使用了類梯度下降的算法(L-BFGS),但由于使用連續一致性模型,有30%的時間花費在等待上。系統B則使用了分塊坐標下降算法,由于比系統A使用的算法更加有效,因此用時比系統A少。但系統B也使用連續一致性模型,并且所需全局同步次數要比系統A更多,所以系統B的等待時間增加到了50%以上。我們在參數服務器實現了與系統B同樣的算法,但將一致性模型放松至受限延時一致性模型并應用了KKT過濾。與系統B相比,參數服務器需要略多的計算時間,但其等待時間大幅降低。由于網絡開銷是這個算法的主要瓶頸,放松的一致性模型使得參數服務器的總體用時只是系統B的一半。
未來規劃
深盟目前已有的組件覆蓋三類最常用的機器學習算法,包括被廣泛用于排序的GBDT,用于點擊預測的稀疏線性模型,以及目前的研究熱點深度學習。未來深盟將致力于將實現和測試更多常用的機器學習算法,目前有數個算法正在開發中。另一方面,我們將更好的融合目前的組件,提供更加一致性的用戶體驗。例如我們將對cxxnet和Minerva結合使得其既滿足對性能的苛刻要求,又能提供靈活的開發環境。
深盟另一個正在開發中的組件叫做蟲洞,它將大幅降低安裝和部署分布式機器學習應用的門檻。具體來說,蟲洞將對所有組件提供一致的數據流支持,無論數據是以任何格式存在網絡共享磁盤,無論HDFS還是Amazon S3。此外,它還提供統一腳本來編譯和運行所有組件。使得用戶既可以在方便的本地集群運行深盟的任何一個分布式組件,又可以將任務提交到任何一個包括Amazon EC2、Microsfot Azure和Google Compute Engine在內的云計算平臺,并提供自動的容災管理。
這個項目較大的愿望就是能將分布式機器學習的門檻降低,使得更多個人和機構能夠享受大數據帶來的便利。同時也希望能多的開發者能加入,聯合大家的力量一起把這個事情做好。(責編/周建丁)
參考文獻
[1] M. Li, D. G. Andersen, J. Park, A. J. Smola, A. Amhed, V. Josi- fovski, J. Long, E. Shekita, and B. Y. Su, Scaling distributed machine learning with the parameter server, in USENIX Symposium on Operating System Design and Implementation, 2014.
[2] M. Li, D. G. Andersen, and A. J. Smola.Communication Efficient DistributedMachine Learning with the Parameter Server.In Neural Information Processing Systems, 2014.
[3] M. Li, 大數據:系統遇上機器學習中國計算機學會通訊 2014 年 12 月
[4]Tianqichen, cxxnet和大規模深度學習http://www.weibo.com/p/1001603821399843149639
[5] Tianqi Chen, Tong He, Higgs Boson Discovery with Boosted Trees, Tech Report.
[6] 何通, xgboost: 速度快效果好的boosting模型, 統計之都http://cos.name/2015/03/xgboost/
[7] Minjie Wang, Tianjun Xiao, Jianpeng Li, Jiaxing Zhang, Chuntao Hong, Zheng Zhang, Minerva: A Scalable and Highly Efficient Training Platform for Deep Learning, Workshop, NIPS 14
作者背景
李沐 百度IDL深度學習實驗室,卡內基梅隆大學
陳天奇 華盛頓大學
王敏捷 紐約大學
余凱 百度IDL深度學習實驗室
張崢 上海紐約大學
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4315.html
摘要:國內互聯網巨頭百度也在近期表明,將發起建立一個名為深盟的分布式機器學習開源平臺,由旗下深度學習研究院牽頭,聯合來自卡耐基梅隴大學華盛頓大學紐約大學香港科技大學的多位系統開發者,共同推出旨在大幅降低機器深度學習門檻的蟲洞項目。 當前人工智能之所以能夠引起大家的興奮和廣泛關注,在很大程度上是源于深度學習的研究進展。這項機器學習技術為計算機視覺、語音識別和自然語言處理帶來了巨大的、激動人心的進步,...
摘要:而道器相融,在我看來,那煉丹就需要一個好的丹爐了,也就是一個優秀的機器學習平臺。因此,一個機器學習平臺要取得成功,最好具備如下五個特點精辟的核心抽象一個機器學習平臺,必須有其靈魂,也就是它的核心抽象。 *本文首發于 AI前線 ,歡迎轉載,并請注明出處。 摘要 2017年6月,騰訊正式開源面向機器學習的第三代高性能計算平臺 Angel,在GitHub上備受關注;2017年10月19日,騰...
摘要:亞馬遜和華盛頓大學今天合作發布了開源的端到端深度學習編譯器。項目作者之一陳天奇在微博上這樣介紹這個編譯器我們今天發布了基于工具鏈的深度學習編譯器。陳天奇團隊對的性能進行了基準測試,并與進行了比較。 亞馬遜和華盛頓大學今天合作發布了開源的端到端深度學習編譯器NNVM compiler。先提醒一句,NNVM compiler ≠ NNVM。NNVM是華盛頓大學博士陳天奇等人2016年發布的模塊化...
摘要:簡稱,是基于聚焦行業應用且提供商業支持的分布式深度學習框架,其宗旨是在合理的時間內解決各類涉及大量數據的問題。是負責開發的用編寫,通過引擎加速的深度學習框架,是目前受關注最多的深度學習框架。 作者簡介魏秀參,曠視科技 Face++ 南京研究院負責人。南京大學 LAMDA 研究所博士,主要研究領域為計算機視覺和機器學習。在相關領域較高級國際期刊如 IEEE TIP、IEEE TNNLS、Mac...

閱讀 832·2023-04-26 00:13
閱讀 2823·2021-11-23 10:08
閱讀 2450·2021-09-01 10:41
閱讀 2118·2021-08-27 16:25
閱讀 4198·2021-07-30 15:14
閱讀 2365·2019-08-30 15:54
閱讀 864·2019-08-29 16:22
閱讀 2741·2019-08-26 12:13





