資訊專欄INFORMATION COLUMN

摘要:深度神經網絡能夠煥發新春,大數據功不可沒,然而大數據的版權是否應當延伸到深度學習產生的知識,這是一個現實的問題。要獲得有用的學習效果,大型多層深度神經網絡又名深度學習系統需要大量的標簽數據。
深度神經網絡能夠煥發新春,大數據功不可沒,然而大數據的版權是否應當延伸到深度學習產生的知識,這是一個現實的問題。本文通過ImageNet可視化大數據、Caffe共享深度學習模型和家中訓練三個場景審查了深度學習的權值與大數據的關系,介紹了目前的問題和解決方案。文章最后預測深度學習將來可能需要相關的“AI法”。
要獲得有用的學習效果,大型多層深度神經網絡(又名深度學習系統)需要大量的標簽數據。這顯然需要大數據,但可用的可視化大數據很少。今天我們來看一個非常著名的可視化大數據來源地,深入了解一下訓練過的神經網絡,然后捫心自問一些關于數據/模型所有權的問題。接下來,我們需要牢記一個基本的問題:一個學習過的神經網絡的權值是輸入圖像的衍生品嗎?換句話說,當一個深度學習系統使用過你的數據之后,誰應該擁有什么?
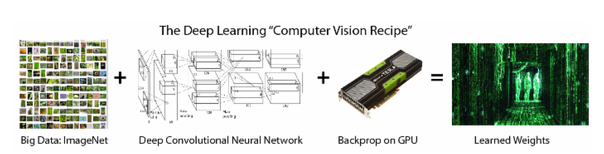
背景:深度學習“計算機視覺秘訣”
現今最成功的機器學習技術之一是深度學習。深度學習引起廣泛關注的原因是由于它在處理語音[1]、文本[2]和圖像[3]等任務中展現出來的顯著成果。深度學習和物體識別(object recognition)技術率先在學術界萌芽(多倫多大學、紐約大學、斯坦福大學、加州大學伯克利分校、麻省理工學院和CMU等),然后被工業界采用(谷歌、Facebook和Snapchat等),現在新興的創業團隊們(Clarifai.com、Metamind.io和Vision.ai等)正將可視化智能(visual intelligence)帶到公眾的面前。雖然人工智能的走向仍不清晰,但是深度學習將會扮演一個關鍵角色。
在可視化物體識別任務中,最常用的模型是卷積神經網絡(也稱為ConvNets或CNNs)。它們可以在不使用手工選取特征引擎的情況下來進行端對端的訓練,但是這需要大量的訓練圖片(有時候稱為大數據,或者可視化大數據)。這些大型的神經網絡從一個空白模型開始,使用一種高度優化的反向傳播算法進行端對端的訓練。反向傳播算法不過是在微積分101課程中學到的鏈式法則,并且現在的深度神經網絡訓練算法同二十世紀80年代的算法幾乎沒什么不一樣。但是今天高度優化的BP的實現是基于GPU的,它能夠處理的數據量遠多于互聯網、云、GPU時代之前的神經網絡。深度學習的訓練結果是一些權值的集合,這些學習過的權值代表的是模型架構中不同層上的權值——用浮點數表示的這些上百萬個的權值代表了從圖像中學到的內容。那么,關于這些權值,其中有趣的是什么呢?有趣的是權值和大數據之間的關系,現在,這種關系將受到審查。
“基于ImageNet訓練后的神經網絡權值是ImageNet的衍生品嗎?是數以百萬計的版權聲明的‘污水坑’嗎?通過訓練來逼近另外一個ImageNet網絡的神經網絡又算是什么?”(這個問題在HackerNews上被提出,出自kastnerkyle對文章“ A Revolutionary Technique That Changed Machine Vision”的評論。)
在計算機視覺的背景下,這個問題確實引起了我的興趣,因為我們開始看到機器人和裝備了人工智能技術的設備進入到了我們的家園中。我希望這個問題在未來的十年中受到更多更深的重視。現在先讓我們看看在2015年中正在解決的一些問題吧。
1.ImageNet:非商業化的可視化大數據
讓我們先看一下一個在深度學習系統中最常用的數據源——ImageNet[4],這個數據源設計的目的是用于識別大量的不同物體。對于研究大規模物體識別和檢測的學者來講,ImageNet是較大的可視化大數據。2009年,該數據集出現在由Fei-Fei Li研究團隊發表的一篇CVPR文章中,之后,該數據集取代了PASCAL數據集(這個數據集樣本的數量和多樣性不夠)和LabelMe數據集(這個數據集樣本缺乏標準化)。ImageNet數據集脫胎于Caltech101(2004年的一個數據集,側重于圖像分類,同樣由Fei-Fei Li團隊研發),所以我個人還是認為ImageNet是類似“Stanford10 ^ N”的。ImageNet在推動物體識別到一個新的領域——深度學習階段起到了核心的作用。

截止到2015年5月1日,ImageNet數據庫擁有超過1500萬的圖像。
問題:有很多非常大的數據集,其圖像是從網上采集的,但是這些圖像通常都帶有自己的版權。版權阻止了圖像的收集和出售,所以從商業角度來看,當產生這樣的數據集的時候,必須要小心一些。為了使現實世界中識別問題保持較先進技術,我們必須使用標準的大數據集(代表了能夠在現實網絡中找到的內容),培養一種共享成果的社區意識,并且維持數據源的版權。
解決方案:ImageNet決定公開提供數據集中圖像的源鏈接,這樣人們就可以不必從一個大學托管的服務器上來下載這些圖像了。ImageNet僅提供圖像的縮略圖和一個版權侵犯刪除聲明。只有當使用者簽署協議,保證不將數據商業化使用之后,數據集組織者才提供完整的數據集。ImageNet具有下述的聲明條款(獲取日期:2015年5月5日):
ImageNet不擁有圖像的版權。ImageNet會以一種圖像搜索引擎的方式,僅提供縮略圖和圖像的URL。也就是說,ImageNet針對每個同義詞集編譯了一個較精確的網絡圖片列表。對于希望將圖片用于非商業化研究和/或教育目的的研究人員和教育工作者來說,在同意我們的一定條件和條款的情況下,我們可以提供通過我們的網站來進行訪問的方式。
2.Caffe:無使用限制的深度學習模式
現在,比較明確的是,我們知道哪里可以下載到可視化大數據以及它們適用的條款,我們再將目光轉向另一個方面:深度學習訓練過程的輸出結果。我們看一下Caffe,一個非常流行的深度學習庫,它可以用來處理類似于ImageNet的數據。Caffe提供了一個共享模式的生態系統(動物園模型),并且已經成為計算機視覺研究者必不可少的工具。Caffe是伯克利視覺和學習中心研發的,并貢獻給了開源社區——它是開源的。

“使用Caffe自己動手搭建深度學習計算機視覺”中的一頁幻燈片
問題:作為一個在大學啟動的項目,Caffe旨在成為創建、訓練和分享深度學習模型的事實標準。分享的模型最初是用于非商業用途,但問題是一波新的初創企業都使用了這些技術。所以必須有一個許可協議,允許高校、大型企業和初創公司來探索同一套預訓練模型。
解決方案:Caffe的當前模型許可是無使用限制的。對于大量的黑客、科學家和工程師們來說這是非常偉大的一件事。需要分享的模型需遵守一項非商業使用條款。下面是全部的Caffe的模型條款(獲取日期:2015年5月5日):
Caffe模型是BVLC的附屬軟件,它沒有使用的限制。
這些模型利用了ImageNet項目的數據進行訓練,這些訓練數據包括了一些從網上獲取的照片,而這些照片可能受到版權保護。
作為研究者,我們目前的理解是:對于這些公開發布的訓練過的模型權值,其使用不應受到什么限制,因為這里面沒有包含任何原始圖像的全部或者部分。對于現在興起的一種說法,‘權值系由原始圖像訓練所得,其版權應歸屬原始圖像版權所有者’,加州大學伯克利分校沒有做過任何聲明說什么樣的使用是被允許的,而是基于大學使命來對待我們的模型,以盡可能不受限制的方式來傳播知識和工具。
3.Vision.ai:在家里生成和訓練的數據集
深度學習能夠學習輸入數據的概要。但是如果另一個不同的模型記住了訓練數據的詳細細節會怎樣呢?更重要的是如果模型記住的內容中有你不想對外分享的內容會怎樣呢?為了研究這種情況,我們來看Vision.ai,他們設計的實時計算機視覺服務器用于模擬產生一個數據集并且學習一個對象的外觀。Vision.ai軟件能夠從視頻和直播的網絡攝像頭流中實時訓練。
不同于從互聯網上的圖像中收集可視化大數據(如ImageNet),vision.ai的訓練過程基于一個人在網絡攝像頭面前揮舞一個感興趣的對象。用戶自力更生的學習過程一開始有一個初始邊界框,算法會在不用干預的情況下持續學習。在算法學習過程中,它會存儲它以前見到的部分歷史信息,從而有效地創建自己的數據集。因為Vision.ai使用了卷積神經網絡來檢測物體(圖像中目標僅占據很少的一部分),所以收集到的數據集中還保持了大量的背景數據。當訓練過程結束后,你同時得到了Caffe類型的信息(學習過的權值)和ImageNet類型的信息(收集的圖像)。那么如果現在進行分享模型,會發生什么呢?

用戶使用vision.ai的實時檢測器訓練接口來訓練茶杯檢測器
問題:在家里的訓練意味著潛在的私人信息和敏感信息以背景的形式被采集到圖像中。如果你在自己家里訓練模型,然后對公眾開放它,那你在分享的時候就需要三思而后行了。同樣的,你如果從有版權保護的視頻/圖像中訓練了一個物體檢測器,那么當你分享/出售這個模型的時候,也需要考慮其中存在的問題。
解決方案:當你把一個Vision.ai模型保存到磁盤上的時候,你能獲取到編譯模型和完整模型。編譯模型是不包含圖像的完整模型(因此小的多)。這就允許你在自己的電腦上保留完整的可編輯模型,而只需要分享編譯模型即可(特別是只發布訓練過的權值),這就避免了別人來偷窺你的生活空間。Vision.ai的計算機視覺服務器稱為VMX,它既能夠運行完整模型,也能夠運行編譯模型;然而,只有非編譯模型能夠編輯和擴展。另外,Vision.ai提供的是視覺服務器的獨立安裝模式,因此訓練圖像和計算結果可以保留在本地計算機上。簡而言之,Vision.ai的解決方案允許你選擇在本機運行還是在云上運行,并且允許你選擇是發布完整模型(具有背景圖像)還是編譯模型(僅有需要檢測的對象)。當需要分享訓練模型和/或產生數據集的時候,你就能夠自由的選擇自己的許可協議。
4.授權基于內存的機器學習模型的開放問題
深度學習方法并不是物體識別的可用技術。如果我們的模型是使用原始RGB像素的最近鄰分類器(Nearest Neighbor Classifier )會怎樣?最近鄰分類器是基于內存的分類,它記憶所有的訓練數據——模型就是訓練數據。如果對同一數據集使用不同的許可,將會產生矛盾,因為某天它可能作為訓練數據,而其他的時候又可能是做為學習算法的輸出數據了。我不知道是否有一種方法可以調和那種來自ImageNet的非商業使用限制許可和來自Caffe深度學習模型的完全不受限制許可。是否有可能有一個黑客友好的數據模型/許可協議來統一所有的情況?
結論
如果將來神經網絡升級成為你的操作系統的一部分,不要感到驚訝。當我們從數據經濟(共享圖片)向知識經濟(共享神經網絡)過渡的時候,法律/所有權問題就成為了一個需要考慮的問題了。我希望今天描述的三種場景(可視化大數據、共享深度學習模型、家中訓練)可以在你想要分享知識的時候,幫助你思考這里面的法律問題。當AI開始生成自己的藝術(可能通過重新合成老照片),法律問題會出現。當你的競爭對手出售你的模型和/或數據的時候,法律問題再次出現。如果MIT協議、GPL協議和Apache協議針對預訓練深度學習模型開始展開爭論的時候,也不要感到吃驚。誰知道呢,或許AI法將是接下來的大事件呢。
參考文獻:
[1] Deep Speech: Accurate Speech Recognition with GPU-Accelerated Deep Learning
[2]Text Understanding from Scratch
[3]ImageNet Classification with Deep Convolutional Neural Networks
[4]A Large-Scale Hierarchical Image Database
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4316.html
摘要:三大牛和在深度學習領域的地位無人不知。逐漸地,這些應用使用一種叫深度學習的技術。監督學習機器學習中,不論是否是深層,最常見的形式是監督學習。 三大牛Yann LeCun、Yoshua Bengio和Geoffrey Hinton在深度學習領域的地位無人不知。為紀念人工智能提出60周年,的《Nature》雜志專門開辟了一個人工智能 + 機器人專題 ,發表多篇相關論文,其中包括了Yann LeC...
摘要:在每一層學習到的結果表示作為下一層的輸入用監督訓練來調整所有層加上一個或者更多的用于產生預測的附加層當前,國外在這方面的研究就是三分天下的局面,的與微軟合作,的和合作,以及的計算機科學家和。深度學習的入門材料。 轉載自:http://doctorimage.cn/2013/01/04/%e5%85%b3%e4%ba%8e%e6%b7%b1%e5%ba%a6%e5%ad%a6%e4%b9%a0...

閱讀 2831·2021-09-28 09:45
閱讀 1506·2021-09-26 10:13
閱讀 897·2021-09-04 16:45
閱讀 3661·2021-08-18 10:21
閱讀 1083·2019-08-29 15:07
閱讀 2632·2019-08-29 14:10
閱讀 3146·2019-08-29 13:02
閱讀 2458·2019-08-29 12:31




