資訊專欄INFORMATION COLUMN

摘要:本文是關于我如何應用基本性能分析技術,借助火焰圖做了一處小改進,使得我們計算機集群的狀況獲得了倍的改善,并在第二年幫助節省了幾百萬刀。最終,通過對平均大小在的事件進行批量插入,我們的吞吐量獲得了的提高。
本文是關于我如何應用基本性能分析技術,借助火焰圖做了一處小改進,使得我們 Postgres 計算機集群的 CPU 狀況獲得了 10 倍的改善,并在第二年幫助 Heap 節省了幾百萬刀。
針對用戶分析的索引數據
Heap 是一個用戶分析工具,它自動捕捉每個用戶與網站或應用進行的交互行為。成功安裝于網站后,Heap 會自動追蹤每個頁面的瀏覽量、點擊量、表單提交等信息。這樣每個網站擁有者可以針對不同子集的原始數據,使用 Heap 來執行不同種類的聚合。
為了能夠對無意義的原始數據有所洞見,Heap 能讓用戶根據原始數據自定義事件。“登陸”就是一個例子,可以定義為“在 /login 頁面進行表單提交”。
為了加快分析速度,我們用了一個非常規的索引策略,它基于 Postgres 的部分索引特性。部分索引就像一個普通的 Postgres 索引,不同點在于它只包含了滿足特定謂詞 (predicate) 的行,你可以把它想象成帶有 WHERE 條件的常規索引。針對每個用戶創建的事件定義,我們根據用戶的原始事件數據,創造了一個部分索引,并將其綁定在滿足定義的行上。每當我們的 events 表格中插入一條新行,Postgres 會自動將它與表內現存的每條部分索引的謂詞進行測試,并將其加入匹配的索引中。
針對每個事件定義,對應的部分索引能讓它快速獲得所有的匹配事件,因為索引恰恰包含了滿足定義的事件。你應該閱讀我們這篇關于如何索引數據的博客,它更加深入地介紹了部分索引的相關內容。
問題初顯:異常的高 CPU 占用率
當我們第一次運用這條索引策略時,對比之前的策略,我們的 CPU 占用率有了大幅上升。我們認為這是正常的現象,因為我們較大的客戶有著成千上萬條索引,而為了支持基于 CSS 選擇器的過濾器,大部分的部分索引都包含了一個正則表達式過濾器。我們認為由于正則表達式的求值極其耗時耗力,而每個插入的事件都要經過上千條正則表達式的測試,這就成了高 CPU 占用率的合理解釋。盡管沒有明顯的證據表明這就是原因,但每個使用 Heap 的人都慢慢將它當作了 CPU 占用率過高的合理解釋。它被看作是新索引策略帶來的根本妥協。
十月左右,隨著數據量的持續增長,問題開始出現:高峰時間無法消化所有信息。有時候新事件需要花費數小時才能顯示在 Heap 儀表板上,而這對一個實時分析工具而言完全不可理喻。拋開通過花錢解決問題的常規路線,我想動手嘗試優化 Heap 的信息吞吐量問題。
用火焰圖對 CPU 占用情況可視化
此前我鮮有調試此類性能問題的經驗。在搜索了一陣后,我看到了大牛 Brendan Gregg 寫的一篇關于火焰圖的文章。火焰圖是 Brendan Gregg 發明的一種可視化方法,用于快速查看哪些部分正在占用 CPU。創建火焰圖的第一步是使用 Linux perf 工具從進程堆棧中取樣:
perf record -p $(pid of process) -F 99 -g -- sleep 60
它會對指定的進程堆棧以每秒 99 次的速度,進行持續一分鐘的取樣,并將數據寫入 perf.data 數據文件中。這樣,你就可以從 Brendan Gregg 的火焰圖數據庫中運行以下命令,對文件進行分析并生成火焰圖:
perf script | ./stackcollapse-perf.pl > out.perf-folded ./flamegraph.pl out.perf-folded > flame-graph.svg
我最初創建的火焰圖之一是 Postgres 的后端進程。因為我們使用了連接池,一個簡單的后端進程要服務多項請求。由于我們運行的最多的請求是 INSERTs,Postgres 后端進程的火焰圖能夠讓我們清楚地看到,事件插入數據庫時的 CPU 占用情況。在 pid 中對來自 pg_stat_activity 的 Postgres 進程運行以上命令后,我獲得了下面這張火焰圖:
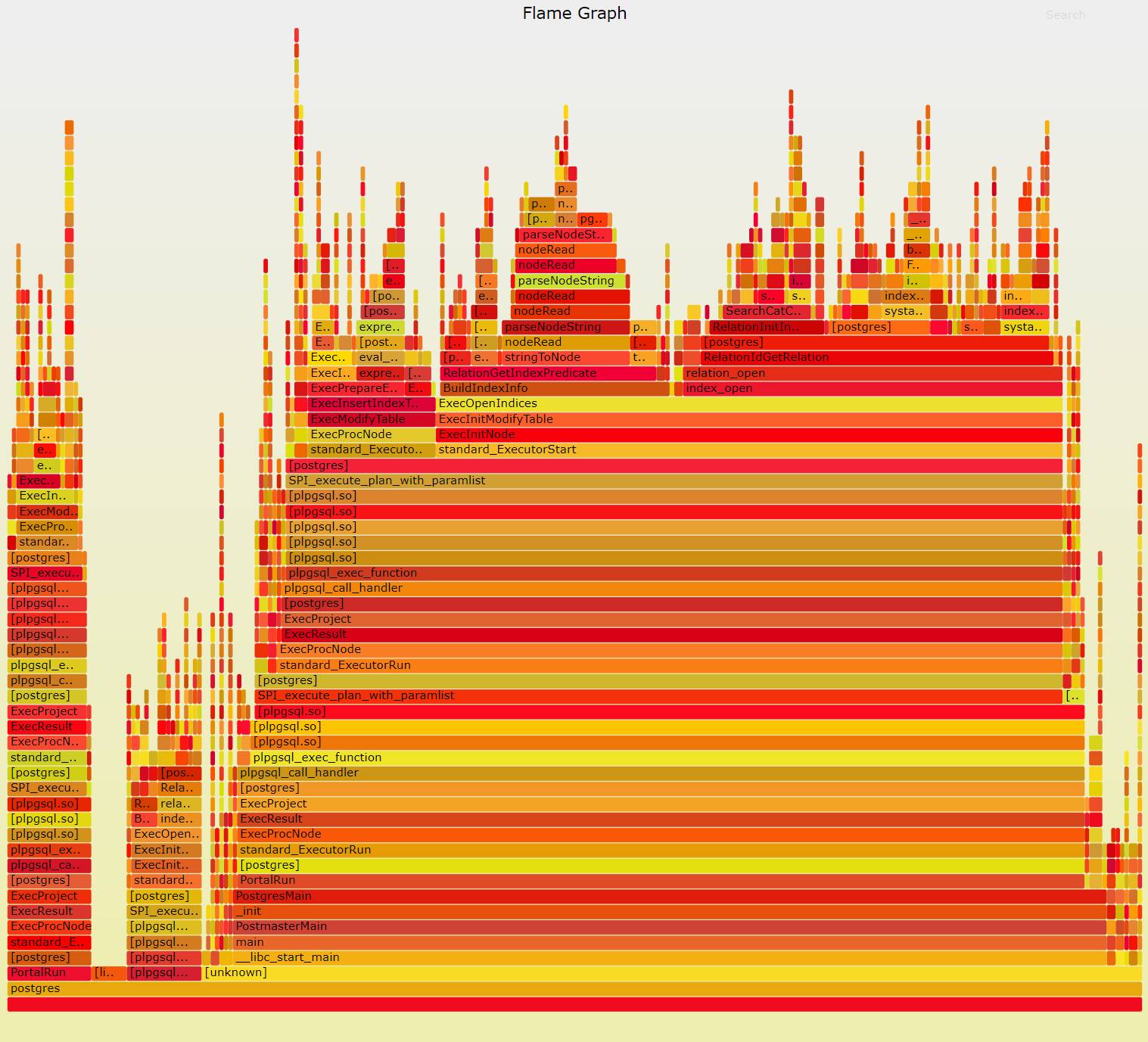
對于新手而言,火焰圖可能非常難以理解。Brendan Gregg 給出以下解釋幫助我們理解一張火焰圖:
X 軸顯示堆棧剖面群體,以字母順序排序(而不是時間的流逝),Y 軸顯示堆棧深度。每個方塊框代表了一個堆棧幀。幀越寬,代表了它在堆棧中出現的頻率越高。頂端顯示了 CPU 正在運行的進程,下面是歷史進程。顏色通常而言并不重要,它們是隨機分配的,用來區分不同的框架。
從火焰圖中可以清楚地看到,大約 55% 的 CPU 時間花在了 ExecOpenIndices 上(圖中行右側區域的大黃色條)。視線上移一點,可以看到大部分的時間被兩個不同的功能所消耗,它們是 BuildIndexInfo 和 index_open。BuildIndexInfo 調用了 RelationGetIndexPredicate,而后者花費了 ~20% 的總 CPU 時間。這樣來看,大部分時間都花在了 RelationGetIndexPredicate 上。
仔細查看 RelationGetIndexPredicate 的源代碼,它的作用是解析和優化部分索引謂詞。這就解釋了為什么 RelationGetIndexPredicate 耗費了如此大量的時間,因為相比對已解析表達式進行求值,解析二進制表達式要更加困難。
現在我們再看看剩下花在 ExecOpenIndices 上的時間。其中大部分剩余時間花在了 index_open 上。看上去 index_open 先調用了 relation_open,后者又調用了 RelationIdGetRelation。從 RelationIdGetRelation 的源代碼文件中,可以看到它的作用是查找不同關系的元數據(本次問題中它主要用于查找部分索引)。根據 RelationGetIndexPredicate 和 RelationIdGetRelation 消耗的時間,看起來 Postgres 花費了更多的時間用于獲取和解析部分索引謂詞,而不是對其求值。
實施修復
看了不同函數的源代碼,可以發現存在著大量的緩存。在 RelationGetIndexPredicate中,Postfres 先檢測是否已抽取謂詞并立即返回它。
RelationIdGetRelation 先使用 RelationIdCacheLookup 來檢查關系源數據是否已經過計算并緩存。通常情況下,索引元數據只需要經歷一次獲取和解析,剩下的時間都是從緩存中讀取。
不幸的是,因為我們每次將一個事件寫入數以萬計的不同表格,緩存出了問題。Postgres 有一個服務請求的進程池,并且每個進程都有多帶帶的緩存。這些進程對每次插入都分配了輪詢 (round-robin)。由于共享的模式中現存上萬張基礎表格,每次插入事件時,很有可能將兩次事件插入同一進程的同一張表中,也就是說索引元數據幾乎無法在執行插入時進行緩存。因此,Postgres 幾乎每次都需要在插入事件時,獲取并解析目的表格的索引元數據。
根據這一點,我們可以做一個簡單的改進:與其將每個事件多帶帶插入表格,我們可以對需要插入相同表格的事件進行一次批量插入。通過運行一個簡單的命令來批量插入事件,Postgres 就只需要在每次批處理時獲取和解析索引元數據。我們之前本想進行批量插入以減少執行計數,但不是出于節省 CPU 資源的目的,因為我們假設所有的 CPU 都要用于對索引謂詞求值。
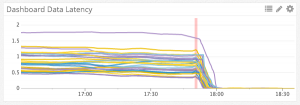
批量插入的初始基準顯示 CPU 占用率得到了 10x 的縮減。得知了這一結果,我們開始在生產中測試批量插入。最終,通過對平均大小在 ~50 的事件進行批量插入,我們的吞吐量獲得了 10x 的提高。這是對不同 Kafka 部分的吞吐量傳輸延遲時間,進行批處理前后的對比:左邊的單位是延遲時間 (latency time)。我們能夠在幾分鐘內清理完一個小時的積壓 (backlog)。
在實行批處理后,我又生成了一張插入事件的火焰圖:

這一次圖上顯示大部分的時間都歸于 ExecQual(中間的紅條),而根據源碼,而它是作用是對部分索引謂詞進行求值,也就是說這一次 Postgres 將大量的 CPU 用在了正途上。
我在半年前發現了這個問題。自此,我們不需要給集群增加額外的 CPU,而且看起來以后的幾個月也不用這樣做。我只是運用了基本的性能分析就有如此成效,沒花什么力氣就獲得了 10 倍的收益。
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/3965.html
摘要:美國金融行業監管局有的重要應用目前正運行于亞馬遜云端服務上面,其中包括市場監測應用,每年因此節省萬美元的費用。穆林斯負責與金融企業達成新的云服務協議。 配圖:安全性不再是云服務客戶最擔心的事情北京時間3月19日消息,路透社今天撰文指出,對于美國金融公司而言,使用共享云服務的益處是顯而易見的。市場研究公司IDC預計,得益于云服務,到2019年全球較大幾家銀行將節省150億美元的龐大資金,技術基...
摘要:上榜較多的國家還有德英法,歷年數量一直穩在附近。本年度上榜企業利潤情況極少數負利潤,大部分純利潤集中在一百億美元以下。總結從世界五百強年的榜單分析了那么多,有些地方確實值得驕傲。 ?前言: 前幾天看到新聞才知道今年的500強已經出爐了,后面又看到小米首次進榜,第468名,雷軍蜀黍開心的像個只有幾十億元的小孩子。還特意發了好幾條微博: showImg(https://segmentfau...

6月20日周四,OpenAI競爭對手Anthropic發布了公司迄今為止性能最強大的AI模型Claude 3.5 Sonnet。在覆蓋閱讀、編程、數學和視覺等領域的多項性能測試中,Claude 3.5 Sonnet的性能略勝一籌,吊打GPT-4o等一眾競爭對手的AI模型,且優于自家旗艦模型Claude 3 Opus。如今,Claude 3.5 Sonnet已經面向全球開啟免費試用了。在費用上,So...
摘要:后端開發的疑惑后端開發最常面對的一個問題性能高并發等等。而到了時代,在方面有了前后端分離概念移動后端更是無力渲染天然前后端分離。 先來上一張前端頁面的效果圖(Vue + Vux + Vuex + Vue-Router)。showImg(https://segmentfault.com/img/remote/1460000010207850); 第一次做gif 沒什么經驗,太大了。加載...

閱讀 1478·2021-10-14 09:43
閱讀 1442·2021-10-09 09:58
閱讀 1937·2021-09-28 09:42
閱讀 3727·2021-09-26 09:55
閱讀 1752·2021-08-27 16:23
閱讀 2755·2021-08-23 09:46
閱讀 906·2019-08-30 15:55
閱讀 1405·2019-08-30 15:54





