資訊專欄INFORMATION COLUMN

摘要:開發(fā)指南開發(fā)指南開發(fā)指南本篇目錄運行運行定義定義定義工作流,為將多個按照一定的順序組織起來,按照既定的路徑運行的一個整體。配置將定時調(diào)度頻率改為分鐘。一個會創(chuàng)建并執(zhí)行。例如,,,,則時間為動作的實際創(chuàng)建時間。
Oozie定義工作流,為將多個Hadoop Job按照一定的順序組織起來,按照既定的路徑運行的一個整體。通過啟動工作流,就會執(zhí)行該工作流中的多個Hadoop Job,直到完成。這就是工作流的生命周期。
Oozie提出了Coordinator的概念,能夠?qū)⒚總€工作流的Job作為一個Action來運行。相當于工作流中的一個執(zhí)行節(jié)點。這樣就能夠?qū)⒍鄠€工作流Job組織起來,稱為Coordinator Job,并制定觸發(fā)時間和頻率,還可以配置數(shù)據(jù)集、并發(fā)數(shù)等。一個Coordinator Job包含了在Job外部設(shè)置執(zhí)行周期和頻率的語義。類似于在工作流外部專家了一個協(xié)調(diào)器來管理這些工作流的工作流Job的運行。
如果在集群安裝了Hue,也可以通過頁面操作配置工作流,具體操作步驟點此查看。以下介紹通過后臺配置工作流的方法:
先看一下官方發(fā)行包自帶的一個簡單例子 oozie/examples/src/main/apps/cron。它能夠?qū)崿F(xiàn)定時調(diào)度一個工作流Job運行,這個例子中給出的一個空的工作流Job,也是為了演示能夠使用Coordinator系統(tǒng)給調(diào)度起來。
這個例子有3個配置文件。修改后分別如下所示:
job.properties配置nameNode=hdfs://uhadoop-XXXXXX-master1:8020
jobTracker=uhadoop-XXXXXX-master1:23140
queueName=default
examplesRoot=examples
oozie.coord.application.path=${nameNode}/user/${user.name}/${examplesRoot}/apps/cron
start=2016-12-01T19:00Z
end=2016-12-31T01:00Z
workflowAppUri=${nameNode}/user/${user.name}/${examplesRoot}/apps/cron修改了Hadoop集群的配置,以及調(diào)度起止時間范圍。
wordflow.xml<workflow-app xmlns="uri:oozie:workflow:0.5" name="one-op-wf">
<start to="action1"/>
<action name="action1">
<fs/>
<ok to="end"/>
<error to="end"/>
action>
<end name="end"/>
workflow-app>這是一個空Job,沒做任何修改。
corrdinator.xml配置<coordinator-app name="cron-coord" frequency="${coord:minutes(2)}" start="${start}" end="${end}" timezone="UTC" xmlns="uri:oozie:coordinator:0.2">
<action>
<workflow>
<app-path>${workflowAppUri}app-path>
<configuration>
<property>
<name>jobTrackername>
<value>${jobTracker}value>
property>
<property>
<name>nameNodename>
<value>${nameNode}value>
property>
<property>
<name>queueNamename>
<value>${queueName}value>
property>
configuration>
workflow>
action>
coordinator-app>將定時調(diào)度頻率改為2分鐘。然后,將這3個文件上傳到HDFS上。
啟動一個Coordinator Job和啟動一個Oozie工作流Job類似,執(zhí)行如下命令即可:
bin/oozie job -oozie http://uhadoop-XXXXXX-master2:11000/oozie -config /home/hadoop/oozie/examples/src/main/apps/cron/job.properties -run運行上面命令,在控制臺上會返回這個Job的ID,我們也可以通過Oozie的Web控制臺來查看。
一個Coordinator Job會創(chuàng)建并執(zhí)行Coordinator Action。通常一個Coordinator Action是一個工作流Job,這個工作流Job會生成一個dataset實例并處理這個數(shù)據(jù)集。當一個Coordinator Action被創(chuàng)建以后,它會一直等待滿足執(zhí)行條件的所有輸入事件的完成然后執(zhí)行,或者發(fā)生超時。
每個Coordinator Job都有一個驅(qū)動事件,來決定它所包含的Coordinator Action的初始化。對于同步Coordinator Job來說,觸發(fā)執(zhí)行頻率就是一個驅(qū)動事件。同樣,組成Coordinator Job的基本單元是Coordinator Action,它不像Oozie工作流Job只有OK和Error兩個執(zhí)行結(jié)果,一個Coordinator 動作的狀態(tài)集合,如下所示:
WAITING
READY
SUBMITTED
TIMEDOUT
RUNNING
KILLED
SUCCEEDED
FAILED
Coordinator Application當滿足一定條件時,會觸發(fā)Oozie工作流。其中,觸發(fā)條件可以是一個時間頻率、一個dataset實例是否可用,或者可能是外部的其他事件。 Coordinator Job是一個Coordinator應(yīng)用的運行實例,這個Coordinator Job是在Oozie提供的Coordinator引擎上運行的,并且這個實例從指定的時間開始,直到運行結(jié)束。一個Coordinator Job具有以下幾個狀態(tài):
PREP
RUNNING
RUNNINGWITHERROR
PREPSUSPENDED
SUSPENDED
SUSPENDEDWITHERROR
PREPPAUSED
PAUSED
PAUSEDWITHERROR
SUCCEEDED
DONEWITHERROR
KILLED
FAILED
Coordinator Job的狀態(tài)比一個基本的Oozie工作流Job的狀態(tài)要復(fù)雜的多。因為Coordinator Job的基本執(zhí)行單元可能是一個基本Oozie Job,而且外加了一些調(diào)度信息,必然要增加額外的狀態(tài)來描述。
一個同步的Coordinator Appliction定義的語法格式,如下所示:
<coordinator-app name="[NAME]" frequency="[FREQUENCY]" start="[DATETIME]" end="[DATETIME]" timezone="[TIMEZONE]" xmlns="uri:oozie:coordinator:0.1">
<controls>
<timeout>[TIME_PERIOD]timeout>
<concurrency>[CONCURRENCY]concurrency>
<execution>[EXECUTION_STRATEGY]execution>
controls>
<datasets>
<include>[SHARED_DATASETS]include>
...
<dataset name="[NAME]" frequency="[FREQUENCY]" initial-instance="[DATETIME]" timezone="[TIMEZONE]">
<uri-template>[URI_TEMPLATE]uri-template>
dataset>
...
datasets>
<input-events>
<data-in name="[NAME]" dataset="[DATASET]">
<instance>[INSTANCE]instance>
...
data-in>
...
<data-in name="[NAME]" dataset="[DATASET]">
<start-instance>[INSTANCE]start-instance>
<end-instance>[INSTANCE]end-instance>
data-in>
...
input-events>
<output-events>
<data-out name="[NAME]" dataset="[DATASET]">
<instance>[INSTANCE]instance>
data-out>
...
output-events>
<action>
<workflow>
<app-path>[WF-APPLICATION-PATH]app-path>
<configuration>
<property>
<name>[PROPERTY-NAME]name>
<value>[PROPERTY-VALUE]value>
property>
...
configuration>
workflow>
action>
coordinator-app>基于上述定義語法格式,我們分別說明對應(yīng)元素的含義,如下所示:
control元素 元素名稱含義說明timeout超時時間,單位為分鐘。當一個CoordinatorJob啟動的時候,會初始化多個Coordinator動作,timeout用來限制這個初始化過程。默認值為-1,表示永遠不超時,如果為0則總是超時。concurrency并發(fā)數(shù),指多個CoordinatorJob并發(fā)執(zhí)行,默認值為1。execution配置多個CoordinatorJob并發(fā)執(zhí)行的策略:默認是FIFO。另外還有兩種:LIFO(最新的先執(zhí)行)、LAST_ONLY(只執(zhí)行最新的CoordinatorJob,其它的全部丟棄)。throttle一個CoordinatorJob初始化時,允許Coordinator動作處于WAITING狀態(tài)的最大數(shù)量。 dataset元素Coordinator Job中有一個Dataset的概念,它可以為實際計算提供計算的數(shù)據(jù),主要是指HDFS上的數(shù)據(jù)目錄或文件,能夠配置數(shù)據(jù)集生成的頻率(Frequency)、URI模板、時間等信息,下面看一下dataset的語法格式:
<dataset name="[NAME]" frequency="[FREQUENCY]" initial-instance="[DATETIME]" timezone="[TIMEZONE]">
<uri-template>[URI TEMPLATE]uri-template>
<done-flag>[FILE NAME]done-flag>
dataset>舉例如下:
<dataset name="stats_hive_table" frequency="${coord:days(1)}" initial-instance="2016-12-25T00:00Z" timezone="America/Los_Angeles">
<uri-template>
hdfs://m1:9000/hive/warehouse/user_events/${YEAR}${MONTH}/${DAY}/data
uri-template>
<done-flag>donefile.flagdone-flag>
dataset>上面會每天都會生成一個用戶事件表,可以供Hive查詢分析,這里指定了這個數(shù)據(jù)集的位置,后續(xù)計算會使用這部分數(shù)據(jù)。其中,uri-template指定了一個匹配的模板,滿足這個模板的路徑都會被作為計算的基礎(chǔ)數(shù)據(jù)。 另外,還有一種定義dataset集合的方式,將多個dataset合并成一個組來定義,語法格式如下所示:
<datasets>
<include>[SHARED_DATASETS]include>
...
<dataset name="[NAME]" frequency="[FREQUENCY]" initial-instance="[DATETIME]" timezone="[TIMEZONE]">
<uri-template>[URI TEMPLATE]uri-template>
dataset>
...
datasets>一個Coordinator Application的輸入事件指定了要執(zhí)行一個Coordinator動作必須滿足的輸入條件,在Oozie當前版本,只支持使用dataset實例。
一個Coordinator Action可能會生成一個或多個dataset實例,在Oozie當前版本,輸出事件只支持輸出dataset實例。
常量表示形式含義說明${coord:minutes(intn)}返回日期時間:從一開始,周期執(zhí)行n分鐘${coord:hours(intn)}返回日期時間:從一開始,周期執(zhí)行n*60分鐘${coord:days(intn)}返回日期時間:從一開始,周期執(zhí)行n*24*60分鐘${coord:months(intn)}返回日期時間:從一開始,周期執(zhí)行n*M*24*60分鐘(M表示一個月的天數(shù))${coord:endOfDays(intn)}返回日期時間:從當天的最晚時間(即下一天)開始,周期執(zhí)行n*24*60分鐘${coord:endOfMonths(1)}返回日期時間:從當月的最晚時間開始(即下個月初),周期執(zhí)行n*24*60分鐘${coord:current(intn)}返回日期時間:從一個Coordinator動作(Action)創(chuàng)建時開始計算,第n個dataset實例執(zhí)行時間${coord:dataIn(Stringname)}在輸入事件(input-events)中,解析dataset實例包含的所有的URI${coord:dataOut(Stringname)}在輸出事件(output-events)中,解析dataset實例包含的所有的URI${coord:offset(intn,StringtimeUnit)}表示時間偏移,如果一個Coordinator動作創(chuàng)建時間為T,n為正數(shù)表示向時刻T之后偏移,n為負數(shù)向向時刻T之前偏移,timeUnit表示時間單位(選項有MINUTE、HOUR、DAY、MONTH、YEAR)${coord:hoursInDay(intn)}指定的第n天的小時數(shù),n>0表示向后數(shù)第n天的小時數(shù),n=0表示當天小時數(shù),n<0表示向前數(shù)第n天的小時數(shù)${coord:daysInMonth(intn)}指定的第n個月的天數(shù),n>0表示向后數(shù)第n個月的天數(shù),n=0表示當月的天數(shù),n<0表示向前數(shù)第n個月的天數(shù)${coord:tzOffset()}dataset對應(yīng)的時區(qū)與CoordinatorJob的時區(qū)所差的分鐘數(shù)${coord:latest(intn)}最近以來,當前可以用的第n個dataset實例${coord:future(intn,intlimit)}當前時間之后的dataset實例,n>=0,當n=0時表示立即可用的dataset實例,limit表示dataset實例的個數(shù)${coord:nominalTime()}nominal時間等于CoordinatorJob啟動時間,加上多個CoordinatorJob的頻率所得到的日期時間。例如:start=”2009-01-01T24:00Z”,end=”2009-12-31T24:00Z”,frequency=”${coord:days(1)}”,frequency=”${coord:days(1)},則nominal時間為:2009-01-02T00:00Z、2009-01-03T00:00Z、2009-01-04T00:00Z、…、2010-01-01T00:00Z${coord:actualTime()}Coordinator動作的實際創(chuàng)建時間。例如:start=”2011-05-01T24:00Z”,end=”2011-12-31T24:00Z”,frequency=”${coord:days(1)}”,則實際時間為:2011-05-01,2011-05-02,2011-05-03,…,2011-12-31${coord:user()}啟動當前CoordinatorJob的用戶名稱${coord:dateOffset(StringbaseDate,intinstance,StringtimeUnit)}計算新的日期時間的公式:newDate=baseDate+instance*timeUnit,如:baseDate=’2009-01-01T00:00Z’,instance=’2′,timeUnit=’MONTH’,則計算得到的新的日期時間為’2009-03-01T00:00Z’。${coord:formatTime(StringtimeStamp,Stringformat)}格式化時間字符串,format指定模式。文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/126871.html
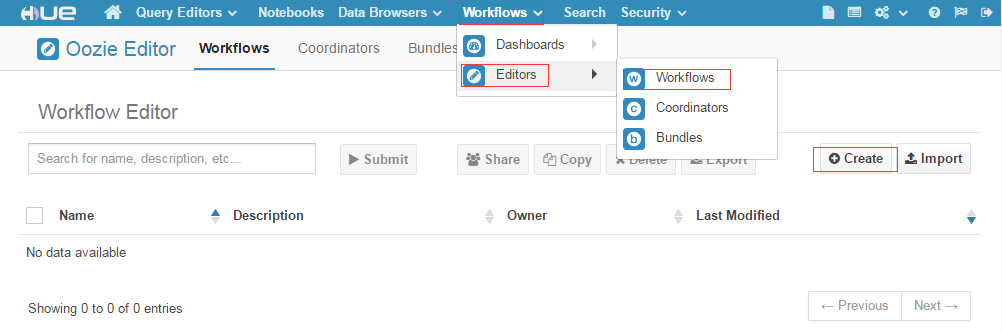
摘要:創(chuàng)建任務(wù)創(chuàng)建任務(wù)選擇這個標簽拖動到中。頁面權(quán)限控制頁面權(quán)限控制頁面權(quán)限控制點擊管理用戶組選擇要修改的組名稱,設(shè)置相應(yīng)權(quán)限并保存 Hue開發(fā)指南本篇目錄1. 配置工作流2. Hue頁面權(quán)限控制Hue是面向 Hadoop 的開源用戶界面,可以讓您更輕松地運行和開發(fā) Hive 查詢、管理 HDFS 中的文件、運行和開發(fā) Pig 腳本以及管理表。服務(wù)默認已經(jīng)啟動,用戶只需要配置外網(wǎng)IP,在防火墻中配...

摘要:也可以將托管集群設(shè)置為快捷方式,通過左側(cè)快捷方式菜單欄點擊進入。框架集群中僅部署。用于做存儲集群,有專屬的節(jié)點機型。節(jié)點管理節(jié)點,負責協(xié)調(diào)整個集群服務(wù)。目前僅節(jié)點支持綁定。通過云主機內(nèi)網(wǎng)進行登錄。登錄密碼為集群創(chuàng)建時設(shè)置的密碼。 快速上手本篇目錄創(chuàng)建集群提交任務(wù)本文檔將帶領(lǐng)您如何創(chuàng)建UHadoop集群,并使用UHadoop集群完成數(shù)據(jù)處理任務(wù)。創(chuàng)建集群本章簡單介紹了用戶使用UHadoop服務(wù)...
.png?v=1644489545)
摘要:架構(gòu)架構(gòu)元數(shù)據(jù)管理元數(shù)據(jù)管理元數(shù)據(jù)管理創(chuàng)建集群時可在控制臺開啟元數(shù)據(jù)獨立管理。若項目中已開啟過元數(shù)據(jù)獨立管理,則新集群開啟該功能時,不再創(chuàng)建新的,而是將新集群的元數(shù)據(jù)存儲于已有的中。 元數(shù)據(jù)管理本篇目錄介紹產(chǎn)品架構(gòu)元數(shù)據(jù)管理介紹UHadoop 支持將 Hive-Metastore 的數(shù)據(jù)庫獨立于 Hadoop 集群部署,也支持多個集群訪問同一個 Hive 元數(shù)據(jù)庫,可在控制臺對其做管理。產(chǎn)品...
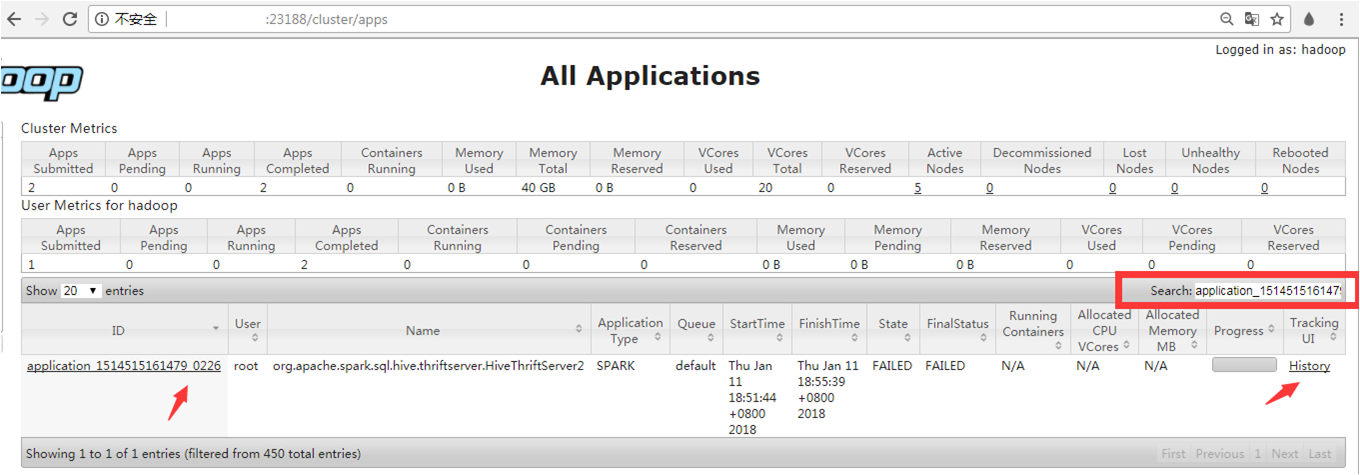
摘要:查看上的歷史日志查看上的歷史日志任務(wù)的日志在任務(wù)運行結(jié)束之后會上傳到上,當日志文件過大無法通過來查看時,可以通過將日志文件從上下載下來查看。掛載在允許的主機上執(zhí)行 常用操作本篇目錄應(yīng)用的Web接口查看日志配置NFS掛載hdfs到本地應(yīng)用的Web接口Hadoop 提供了基于 Web 的用戶界面,可通過它查看您的 Hadoop 集群。Web 服務(wù)會在主節(jié)點上運行(Active NameNode或...
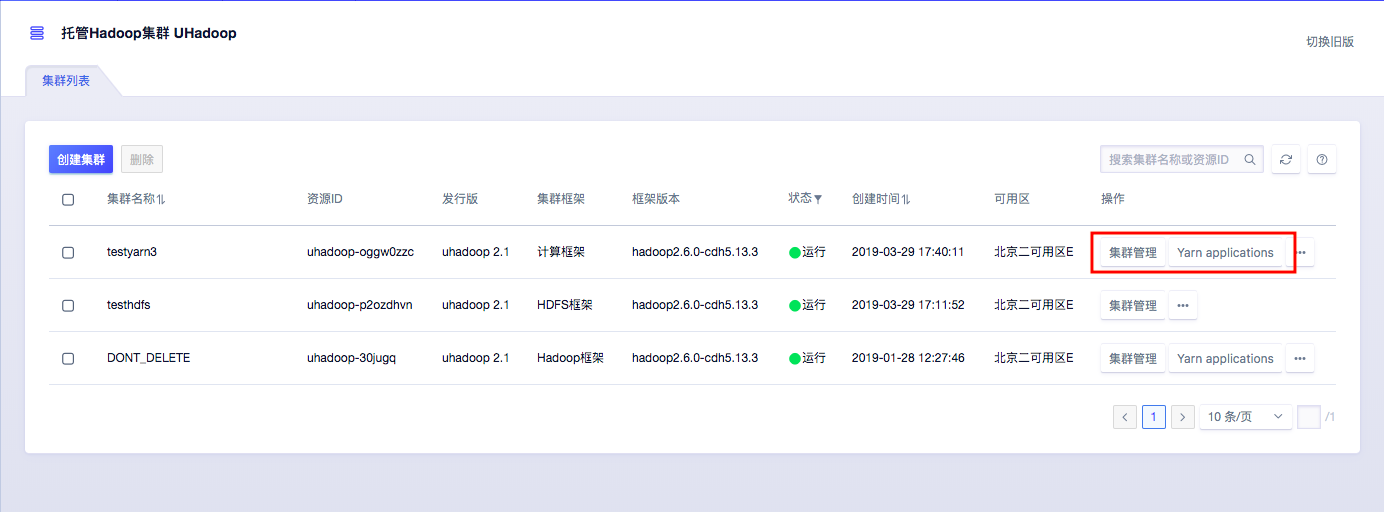
摘要:監(jiān)控數(shù)據(jù)查看監(jiān)控數(shù)據(jù)查看用戶可于產(chǎn)品界面右側(cè)彈框中查看集群監(jiān)控數(shù)據(jù),也可進入監(jiān)控視圖中進行詳細查看集群及各節(jié)點監(jiān)控數(shù)據(jù)信息。 基本操作本篇目錄集群管理服務(wù)管理告警與監(jiān)控數(shù)據(jù)均衡Yarn Application跟蹤集群管理1、進入集群管理頁面通過UHadoop集群列表頁面進入集群管理頁面:2、獲取當前節(jié)點配置信息本例中,Master 節(jié)點數(shù)量 2,機型為 C1-large;Core 節(jié)點數(shù)量為...

閱讀 351·2024-11-07 18:25
閱讀 130598·2024-02-01 10:43
閱讀 914·2024-01-31 14:58
閱讀 879·2024-01-31 14:54
閱讀 82884·2024-01-29 17:11
閱讀 3176·2024-01-25 14:55
閱讀 2028·2023-06-02 13:36
閱讀 3108·2023-05-23 10:26
