資訊專欄INFORMATION COLUMN

摘要:很好解決,采用排序算法進行排序即可。處理方式是記錄頂點在最小生成樹中的終點,頂點的終點是在最小生成樹中與它連通的最大頂點。如何判斷回路將所有頂點按照從小到大的順序排列好之后,某個頂點的終點就是與它連通的最大頂點。
①對圖的所有邊按照權值大小進行排序。
②將邊添加到最小生成樹中時,怎么樣判斷是否形成了回路。
①很好解決,采用排序算法進行排序即可。
②處理方式是:記錄頂點在"最小生成樹"中的終點,頂點的終點是"在最小生成樹中與它連通的最大頂點"。然后每次需要將一條邊添加到最小生存樹時判斷該邊的兩個頂點的終點是否重合,重合的話則會構成回路。
將所有頂點按照從小到大的順序排列好之后,某個頂點的終點就是"與它連通的最大頂點"。我們加入的邊的兩個頂點不能都指向同一個終點,否則構成回路。
具體是這個方法
/** * 返回傳入的點的終點的下標 * @param ends ends[i] = j i是傳入的點的下標,j是i的相鄰點的下標 * @param i * @return */public static int getEnd(int[] ends,int i){ //如果這個點有可以到達的點,那么就把可以到達的點賦值到i,然后如果i還有可以到達的點,那么就重復此操作。一直到最后,最后的點就是最初傳入的點的終點 //其實ends數組記的是每一個點的相鄰點,而不是終點,但是可以通過ends數組,利用while循環,求出一個點的終點 while (ends[i] != 0){ i = ends[i]; } return i;}public class Main { static char[] data = {"A","B","C","D","E","F","G"}; public static void main(String[] args) { //char[] data = {"A","B","C","D","E","F","G"}; int[][] weight = { {0,12,10000,10000,10000,16,14}, {12,0,10,10000,10000, 7,10000}, {10000,10,0,3,5,6,10000}, {10000,10000,3,0,4,10000,10000}, {10000,10000,5,4,0,2,8}, {16,7,6,10000,2,0,9}, {14,10000,10000,10000,8,9,0}}; MGraph mGraph = new MGraph(data.length); mGraph.createGraph(data,weight); mGraph.showGraph(); createMinTreeKruskal(mGraph); //System.out.println(Arrays.toString(MEdge.getEdges(mGraph))); //System.out.println(Arrays.toString(MEdge.getSortedEdges(MEdge.getEdges(mGraph)))); } /** * 克魯斯卡爾算法構建最小生成樹 */ public static void createMinTreeKruskal(MGraph mGraph){ if (mGraph.vertexNum == 0){ return; } //首先得到傳入的圖的所有邊按權值從小到大的順序排序 MEdge[] sortedEdges = MEdge.getSortedEdges(MEdge.getEdges(mGraph));//所有邊 ArrayList<MEdge> mEdges = new ArrayList<>(); //創建所有頂點的終點集 int[] ends = new int[mGraph.vertexNum]; for (int i = 0;i < sortedEdges.length;i++){ int p1 = MEdge.getPointIndex(sortedEdges[i].startPoint,data); int p2 = MEdge.getPointIndex(sortedEdges[i].endPoint,data); //判斷此邊的兩個點的終點是否相同 int end1 = MEdge.getEnd(ends,p1); int end2 = MEdge.getEnd(ends,p2); if (end1 != end2){ ends[end1] = end2; mEdges.add(sortedEdges[i]); } } System.out.println(mEdges); }}//創建邊class MEdge{ char startPoint; char endPoint; int weight; public MEdge(char startPoint, char endPoint, int weight) { this.startPoint = startPoint; this.endPoint = endPoint; this.weight = weight; } @Override public String toString() { return "MEdge{" + "startPoint=" + startPoint + ", endPoint=" + endPoint + ", weight=" + weight + "}"; } //傳入一個圖,根據其鄰接矩陣,得到其邊的數目 public static int getEdgesNum(MGraph mGraph){ if (mGraph.vertexNum == 0){ return -1; } int edgeNum = 0; for (int i = 0;i < mGraph.vertexNum;i++){ for(int j = i + 1;j < mGraph.vertexNum;j++){ if (mGraph.weight[i][j] != 10000){ //說明這是一條邊,i和j分別是其端點 edgeNum++; } } } return edgeNum; } //傳入一個圖,根據其鄰接矩陣,得到其邊 public static MEdge[] getEdges(MGraph mGraph){ if (mGraph.vertexNum == 0){ return null; } MEdge[] mEdges = new MEdge[getEdgesNum(mGraph)]; int index = 0; for (int i = 0;i < mGraph.vertexNum;i++){ for(int j = i + 1;j < mGraph.vertexNum;j++){ if (mGraph.weight[i][j] != 10000){ //說明這是一條邊,i和j分別是其端點 mEdges[index] = new MEdge(mGraph.data[i],mGraph.data[j],mGraph.weight[i][j]); index++;//這里一定別忘了+1 } } } return mEdges; } //傳入一個邊集合,根據其權值大小進行排序 public static MEdge[] getSortedEdges(MEdge[] mEdges){ for (int i = 0;i < mEdges.length - 1;i++){ for (int j = 0;j < mEdges.length - i - 1;j++){ if (mEdges[j + 1].weight < mEdges[j].weight){ //不能用下面的 因為下面這種僅僅改變了邊的權,我們應該整個邊都去改變// int temp = mEdges[j + 1].weight;// mEdges[j + 1].weight = mEdges[j].weight;// mEdges[j].weight = temp; MEdge mEdge = mEdges[j + 1]; mEdges[j + 1] = mEdges[j]; mEdges[j] = mEdge; } } } return mEdges; } /** * 返回傳入的點的終點的下標 * @param ends ends[i] = j i是傳入的點的下標,j是i的終點的下標 * @param i * @return */ public static int getEnd(int[] ends,int i){ //如果這個點有可以到達的點,那么就把可以到達的點賦值到i,然后如果i還有可以到達的點,那么就重復此操作。 //其實ends數組記的是每一個點的相鄰點,而不是終點,但是可以通過ends數組,利用while循環,求出一個點的終點 while (ends[i] != 0){ i = ends[i]; } return i; } //輸入一個頂點(char類型),返回其索引值(int類型) public static int getPointIndex(char point,char[] datas){ for (int i = 0;i < datas.length;i++){ if (datas[i] == point){ return i; } } return -1;//沒找到 }}//這是圖class MGraph{ //節點數目 int vertexNum; //節點 char[] data; //邊的權值 int[][] weight; MGraph(int vertexNum){ this.vertexNum = vertexNum; data = new char[vertexNum]; weight = new int[vertexNum][vertexNum]; } //圖的創建 public void createGraph(char[] mData,int[][] mWeight){ if (vertexNum == 0){ return;//節點數目為0 無法創建 } for (int i = 0;i < data.length;i++){ data[i] = mData[i]; } for (int i = 0;i < mWeight.length;i++){ for (int j = 0;j < mWeight.length;j++){ weight[i][j] = mWeight[i][j]; } } } //打印圖 public void showGraph(){ if (vertexNum == 0){ return; } for (int[] oneLine: weight){ for (int oneNum: oneLine){ System.out.printf("%20d",oneNum); } System.out.println(); } }}結果
0 12 10000 10000 10000 16 14 12 0 10 10000 10000 7 10000 10000 10 0 3 5 6 10000 10000 10000 3 0 4 10000 10000 10000 10000 5 4 0 2 8 16 7 6 10000 2 0 9 14 10000 10000 10000 8 9 0[MEdge{startPoint=E, endPoint=F, weight=2}, MEdge{startPoint=C, endPoint=D, weight=3}, MEdge{startPoint=D, endPoint=E, weight=4}, MEdge{startPoint=B, endPoint=F, weight=7}, MEdge{startPoint=E, endPoint=G, weight=8}, MEdge{startPoint=A, endPoint=B, weight=12}]文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/121401.html
摘要:應用分治法是一種很重要的算法。字面上的解釋是分而治之,就是把一個復雜的問題分成兩個或更多的相同或相似的子問題,再把子問題分成更小的子問題直到最后子問題可以簡單的直接求解,原問題的解即子問題的解的合并。 ...
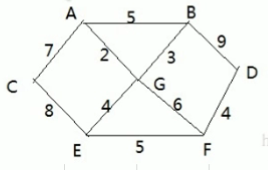
摘要:問題勝利鄉有個村莊現在需要修路把個村莊連通各個村莊的距離用邊線表示權比如距離公里問如何修路保證各個村莊都能連通并且總的修建公路總里程最短代碼重點理解中的三層循環 問...
摘要:遞歸實現不考慮相同數二分查找,不考慮有相同數的情況遞歸找到了考慮有相同數二分查找考慮有相同元素的情況遞歸要查找的值 1.遞歸實現 ①不考慮相同數 /** * 二分查...
摘要:學習資料迪杰斯特拉計算的是單源最短路徑,而弗洛伊德計算的是多源最短路徑代碼不能設置為,否則兩個相加會溢出導致出現負權創建頂點和邊 學習資料 迪杰斯特拉計算的是單源最...
摘要:例題假設存在如下表的需要付費的廣播臺,以及廣播臺信號可以覆蓋的地區。 例題 假設存在如下表的需要付費的廣播臺,以及廣播臺信號可以覆蓋的地區。如何選擇最少的廣播臺,讓...

閱讀 2365·2023-04-25 20:07
閱讀 3303·2021-11-25 09:43
閱讀 3662·2021-11-16 11:44
閱讀 2529·2021-11-08 13:14
閱讀 3177·2021-10-19 11:46
閱讀 895·2021-09-28 09:36
閱讀 2975·2021-09-22 10:56
閱讀 2374·2021-09-10 10:51






