個人中心PERSONAL CENTER

Veo是什么Veo是由Google DeepMind開發的一款視頻生成模型,用戶可以通過文本、圖像或視頻提示來指導其生成所需的視頻內容,能夠生成時長超過一分鐘1080P分辨率的高質量視頻。Veo擁有對自然語言的深入理解能夠準確捕捉和執行各種電影制作術語和效果,如延時攝...

5月20日,微軟在其特別活動上,向世界介紹了一種新類別的WindowsPC,一款專為AI設計的Copilot+ PC。Copilot+ PC引入了全新的系統架構,將 CPU、GPU和高性能神經處理單元(NPU)結合在一起,并與 Azure 云中的大語言模型(LLM)和小語言模型(SLM)協同工作,帶來前...

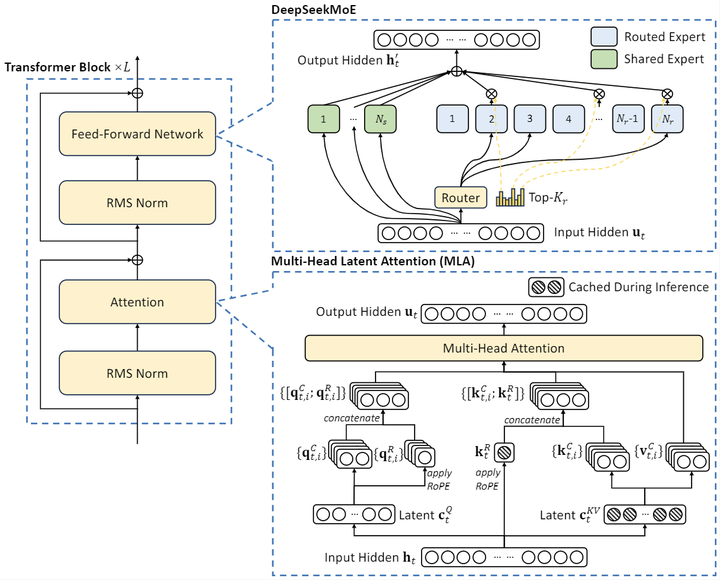
項目簡介DeepSeek-V2,一個專家混合(MoE)語言模型,其特點是經濟高效的訓練和推理。它包含 2360 億個總參數,其中每個token激活了21億個參數。與 DeepSeek67B相比,DeepSeek-V2 實現了更強的性能,同時節省了 42.5%的訓練成本,將 KV 緩存減少了 93.3%,并將...
Llama3 中文聊天項目綜合資源庫,該文檔集合了與Lama3 模型相關的各種中文資料,包括微調版本、有趣的權重、訓練、推理、評測和部署的教程視頻與文檔。1. 多版本支持與創新:該倉庫提供了多個版本的Lama3 模型,包括基于不同技術和偏好的微調版本,如直接中文...

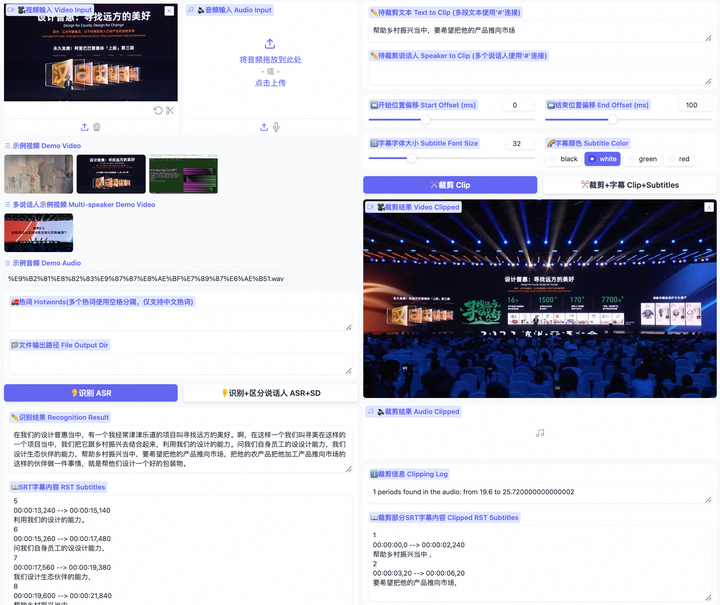
項目簡介Funclip 是阿里巴巴通義實驗室開源的一款視頻剪輯工具,專門用于精準、便捷的視頻切片。它能夠自動識別視頻中的中文語音并允許用戶根據語音內容來裁剪視頻。該工具使用了阿里巴巴語音識別模型FunASR Paraformer-Large確保了剪輯的精準性。你可以根據...
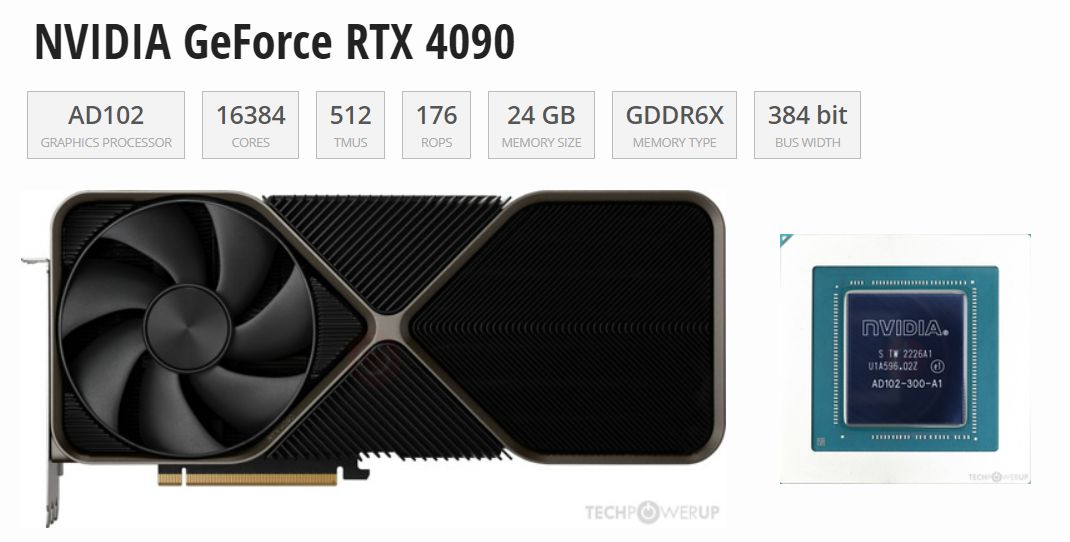
ChatGPT和Sora等AI大模型應用,將AI大模型和算力需求的熱度不斷帶上新的臺階。哪里可以獲得廉價算力,進行AI視頻生成等模型開發和應用呢?Compshare是隸屬于UCloud云計算的GPU算力平臺,專注提供高性價比的NVIDIA RTX 40 系列資源,滿足 AI應用、模型推理/微...

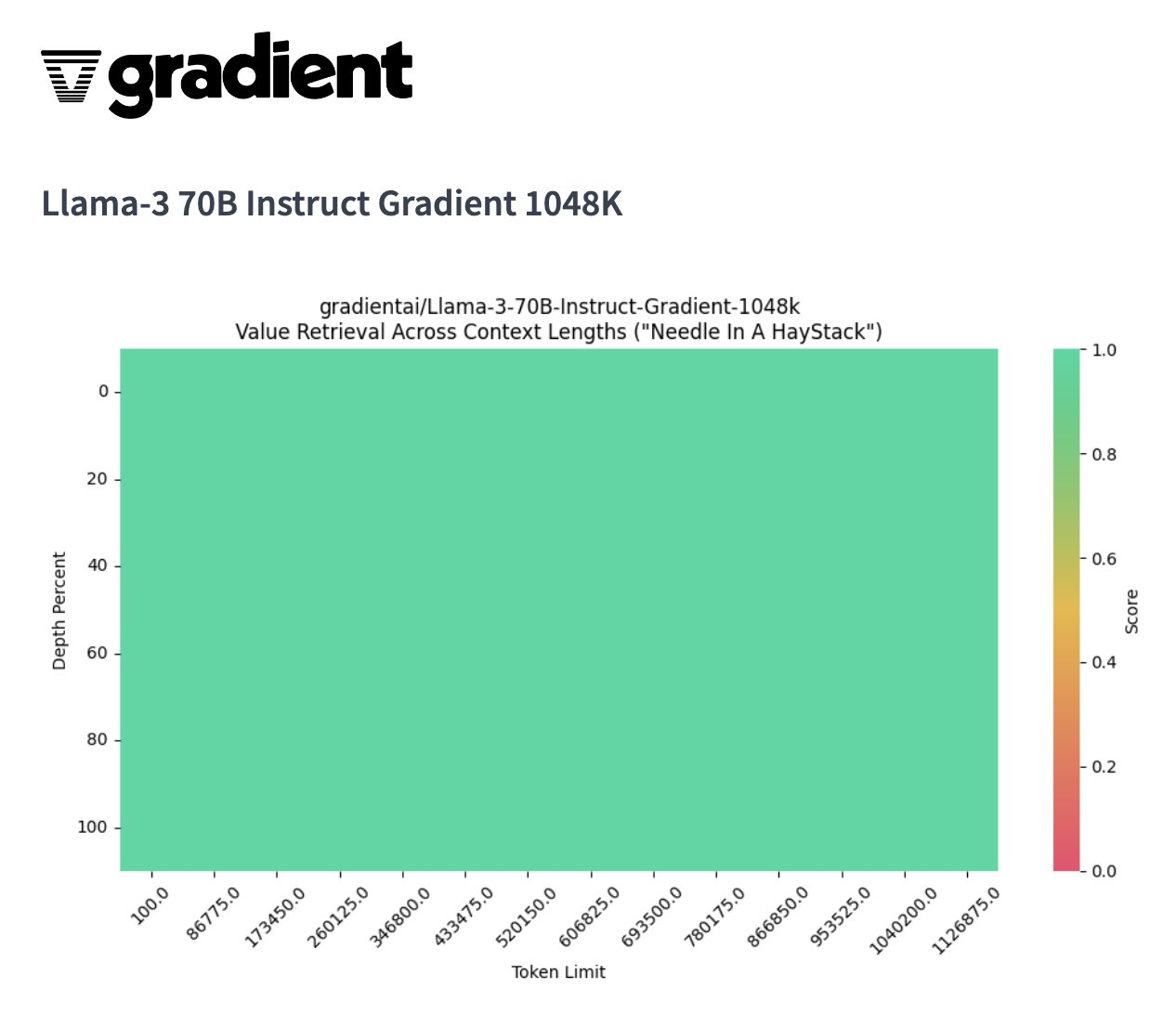
Gradient Al最近將Llama-3 8B和7B模型通過漸進式訓練方法不斷將Llama-3模型的上下文長度從8k-路擴展到262k、524k今天Gradient Al成功宣布成功地將Llama-3 系列模型的上下文長度擴展到超過1 M...并且1M上下文窗口 70B 模型在 NIAH(大海撈針)上取得了完美分數。...
NVIDIA和MIT的研究人員推出了一種新的視覺語言模型(VLM)預訓練框架,名為VILA。這個框架旨在通過有效的嵌入對齊和動態神經網絡架構,改進語言模型的視覺和文本的學習能力。VILA通過在大規模數據集如Coy0-700m上進行預訓練,采用基于LLaVA模型的不同預訓練策略...

NVIDIA和MIT的研究人員推出了一種新的視覺語言模型(VLM)預訓練框架,名為VILA。這個框架旨在通過有效的嵌入對齊和動態神經網絡架構,改進語言模型的視覺和文本的學習能力。VILA通過在大規模數據集如Coy0-700m上進行預訓練,采用基于LLaVA模型的不同預訓練策略...
ollama介紹在本地啟動并運行大型語言模型。運行Llama 3、Phi 3、Mistral、Gemma和其他型號。Llama 3Meta Llama 3 是 Meta Inc. 開發的一系列最先進的模型,提供8B和70B參數大小(預訓練或指令調整)。Llama 3 指令調整模型針對對話/聊天用例進行了微調和優化...
Perplexica是一個開源的人工智能搜索工具,也可以說是一款人工智能搜索引擎,它深入互聯網以找到答案。受Perplexity AI啟發,它是一個開源選擇,不僅可以搜索網絡,還能理解您的問題。它使用先進的機器學習算法,如相似性搜索和嵌入式技術,以精細化結果,并...
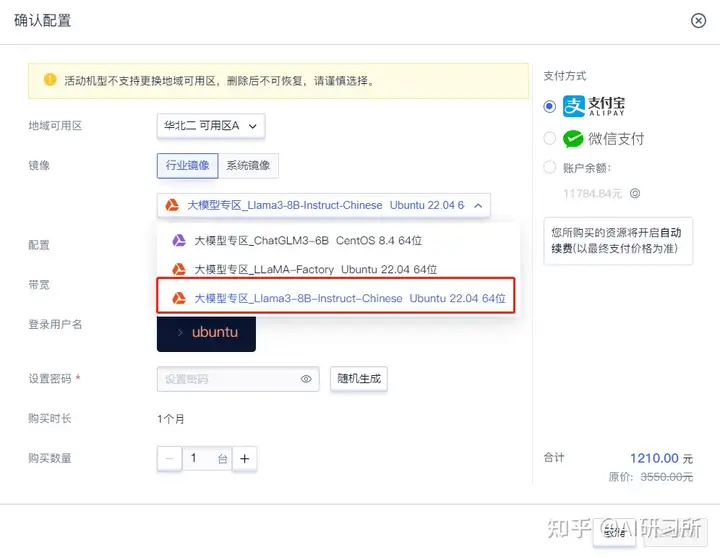
Llama3-8B-Chinese-Chat 是基于 Meta-Llama-3-8B-Instruct 模型通過 ORPO進行微調的中文聊天模型。與原始的 Meta-Llama-3-8B-Instruct 模型相比,此模型顯著減少了中文問題英文回答"和混合中英文回答的問題。此外,相較于原模型,新模型在回答中大量減少了...

2024年4月18日,Meta AI正式宣布推出開源大模型Llama3,這標志著開源大型語言模型(LLM)領域的又一重大突破。Llama3以其卓越的性能和廣泛的應用前景,或將推動人工智能技術快速邁進新紀元。為方便AI應用企業及個人AI開發者快速體驗Llama3的超高性能,近期優...
隨著人工智能的持續火熱,好的加速卡成為了各行業的重點關注對象,因為在AI機器學習中,通常涉及大量矩陣運算、向量運算和其他數值計算。這些計算可以通過并行處理大幅提高效率,而高端顯卡的存在,使得在處理要求擁有大量算力的任務時,變得不那么難了。這篇...
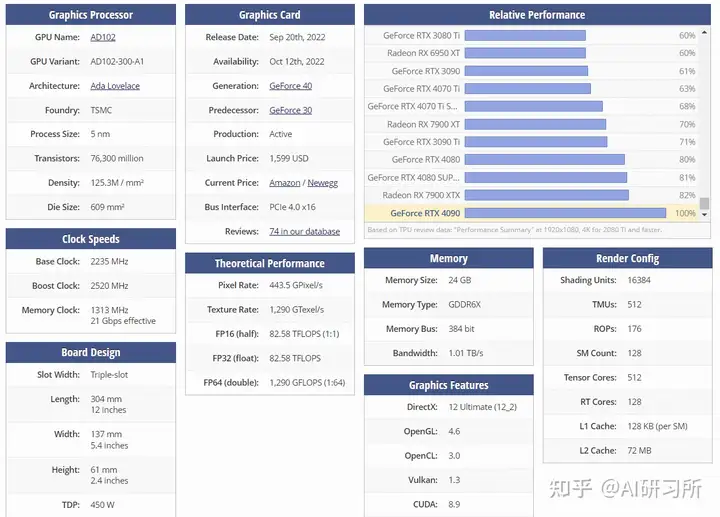
圖示為GPU性能排行榜,我們可以看到所有GPU的原始相關性能圖表。同時根據訓練、推理能力由高到低做了排名。我們可以看到,H100 GPU的8位性能與16位性能的優化與其他GPU存在巨大差距。針對大模型訓練來說,H100和A100有絕對的優勢首先,從架構角度來看,A100采...