spark數(shù)據(jù)選擇SEARCH AGGREGATION


回答:Hadoop生態(tài)Apache?Hadoop?項(xiàng)目開發(fā)了用于可靠,可擴(kuò)展的分布式計(jì)算的開源軟件。Apache Hadoop軟件庫是一個(gè)框架,該框架允許使用簡單的編程模型跨計(jì)算機(jī)集群對大型數(shù)據(jù)集進(jìn)行分布式處理。 它旨在從單個(gè)服務(wù)器擴(kuò)展到數(shù)千臺(tái)機(jī)器,每臺(tái)機(jī)器都提供本地計(jì)算和存儲(chǔ)。 庫本身不是設(shè)計(jì)用來依靠硬件來提供高可用性,而是設(shè)計(jì)為在應(yīng)用程序?qū)訖z測和處理故障,因此可以在計(jì)算機(jī)集群的頂部提供高可用性服務(wù),...
 娣辯孩
|
1490人閱讀
娣辯孩
|
1490人閱讀
回答:1998年9月4日,Google公司在美國硅谷成立。正如大家所知,它是一家做搜索引擎起家的公司。無獨(dú)有偶,一位名叫Doug?Cutting的美國工程師,也迷上了搜索引擎。他做了一個(gè)用于文本搜索的函數(shù)庫(姑且理解為軟件的功能組件),命名為Lucene。左為Doug Cutting,右為Lucene的LOGOLucene是用JAVA寫成的,目標(biāo)是為各種中小型應(yīng)用軟件加入全文檢索功能。因?yàn)楹糜枚议_源(...
 ctriptech
|
849人閱讀
ctriptech
|
849人閱讀
回答:MySQL是單機(jī)性能很好,基本都是內(nèi)存操作,而且沒有任何中間步驟。所以數(shù)據(jù)量在幾千萬級(jí)別一般都是直接MySQL了。hadoop是大型分布式系統(tǒng),最經(jīng)典的就是MapReduce的思想,特別適合處理TB以上的數(shù)據(jù)。每次處理其實(shí)內(nèi)部都是分了很多步驟的,可以調(diào)度大量機(jī)器,還會(huì)對中間結(jié)果再進(jìn)行匯總計(jì)算等。所以數(shù)據(jù)量小的時(shí)候就特別繁瑣。但是數(shù)據(jù)量一旦起來了,優(yōu)勢也就來了。
 李世贊
|
514人閱讀
李世贊
|
514人閱讀
問題描述:關(guān)于買主機(jī)數(shù)據(jù)機(jī)房怎么選擇這個(gè)問題,大家能幫我解決一下嗎?
 劉德剛
|
474人閱讀
劉德剛
|
474人閱讀

...Apache Spark現(xiàn)在非常熱門。它是Apache軟件基礎(chǔ)中最活躍的大數(shù)據(jù)項(xiàng)目,最近也被IBM神化——其中IBM還投入了3, 500個(gè)工程師來推動(dòng)它。盡管一些人還對Spark是什么有所疑惑,或者聲稱它將會(huì)淘汰Hadoop(也許它并不會(huì),或者至少不...
前言 有贊數(shù)據(jù)平臺(tái)從2017年上半年開始,逐步使用 SparkSQL 替代 Hive 執(zhí)行離線任務(wù),目前 SparkSQL 每天的運(yùn)行作業(yè)數(shù)量5000個(gè),占離線作業(yè)數(shù)目的55%,消耗的 cpu 資源占集群總資源的50%左右。本文介紹由 SparkSQL 替換 Hive 過程中碰到...
前言 有贊數(shù)據(jù)平臺(tái)從2017年上半年開始,逐步使用 SparkSQL 替代 Hive 執(zhí)行離線任務(wù),目前 SparkSQL 每天的運(yùn)行作業(yè)數(shù)量5000個(gè),占離線作業(yè)數(shù)目的55%,消耗的 cpu 資源占集群總資源的50%左右。本文介紹由 SparkSQL 替換 Hive 過程中碰到...
...開源工具和技術(shù),例如 Apache Spark,它是一種用于大規(guī)模數(shù)據(jù)處理的快速靈活的數(shù)據(jù)處理引擎。 CDH Spark2 是 Apache Spark 的一個(gè)版本,包含在 Cloudera Distribution for Apache Hadoop (CDH) 中。它是一個(gè)強(qiáng)大而靈活的數(shù)據(jù)處...
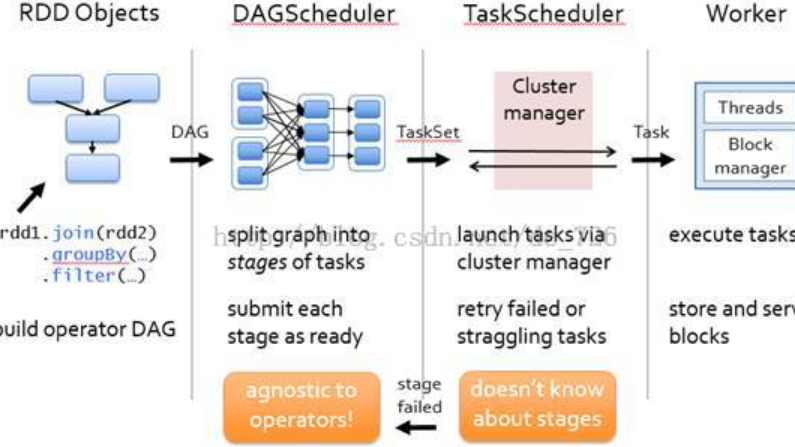
...定義一個(gè) spark 應(yīng)用程序所需要的三大步驟的邏輯:加載數(shù)據(jù)集,處理數(shù)據(jù),結(jié)果展示。 3. Cluster Manager 集群的資源管理器,在集群上獲取資源的外部服務(wù)。拿 Yarn 舉例,客戶端程序會(huì)向 Yarn 申請計(jì)算我這個(gè)任務(wù)需要多少的 memory...
ChatGPT和Sora等AI大模型應(yīng)用,將AI大模型和算力需求的熱度不斷帶上新的臺(tái)階。哪里可以獲得...
大模型的訓(xùn)練用4090是不合適的,但推理(inference/serving)用4090不能說合適,...
圖示為GPU性能排行榜,我們可以看到所有GPU的原始相關(guān)性能圖表。同時(shí)根據(jù)訓(xùn)練、推理能力由高到低做了...




 劉永祥
劉永祥 未東興
未東興









