spark功能SEARCH AGGREGATION


回答:Hadoop生態Apache?Hadoop?項目開發了用于可靠,可擴展的分布式計算的開源軟件。Apache Hadoop軟件庫是一個框架,該框架允許使用簡單的編程模型跨計算機集群對大型數據集進行分布式處理。 它旨在從單個服務器擴展到數千臺機器,每臺機器都提供本地計算和存儲。 庫本身不是設計用來依靠硬件來提供高可用性,而是設計為在應用程序層檢測和處理故障,因此可以在計算機集群的頂部提供高可用性服務,...
 娣辯孩
|
1511人閱讀
娣辯孩
|
1511人閱讀
回答:1998年9月4日,Google公司在美國硅谷成立。正如大家所知,它是一家做搜索引擎起家的公司。無獨有偶,一位名叫Doug?Cutting的美國工程師,也迷上了搜索引擎。他做了一個用于文本搜索的函數庫(姑且理解為軟件的功能組件),命名為Lucene。左為Doug Cutting,右為Lucene的LOGOLucene是用JAVA寫成的,目標是為各種中小型應用軟件加入全文檢索功能。因為好用而且開源(...
 ctriptech
|
861人閱讀
ctriptech
|
861人閱讀
回答:可以自行在某些節點上嘗試安裝 Spark 2.x,手動修改相應 Spark 配置文件,進行使用測試,不安裝 USDP 自帶的 Spark 3.0.1
回答:Spark Shark |即Hive onSparka.在實現上是把HQL翻譯成Spark上的RDD操作,然后通過Hive的metadata獲取數據庫里的表信息,Shark獲取HDFS上的數據和文件夾放到Spark上運算.b.它的最大特性就是快以及與Hive完全兼容c.Shark使用了Hive的API來實現queryparsing和logic plan generation,最后的Physical...
 liaoyg8023
|
992人閱讀
liaoyg8023
|
992人閱讀
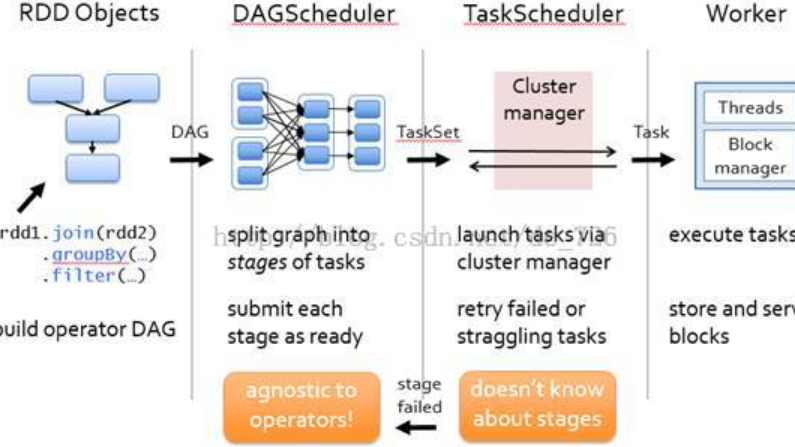
...; CDH Spark2 還包括許多特定于 CDH 發行版的增強功能和功能,例如改進的安全性和對企業級部署和管理的支持。這使其成為需要強大可靠的數據處理引擎來處理大規模數據處理任務的組織的理想選擇。 ...

...自動切分、數據計算和模型劃分的自動方案及異步控制等功能并支持多種高維度機器學習場景。(詳見《騰訊大數據將開源高性能計算平臺 Angel,機器之心專訪開發團隊》) 當時,騰訊曾表示將于 2017 年一季度開放其源代碼,...
...另外一個表中。 我們來看看 Waterdrop 是如何實現這么一個功能的。 Waterdrop Waterdrop 是一個非常易用,高性能,能夠應對海量數據的實時數據處理產品,它構建在 Spark 之上。Waterdrop 擁有著非常豐富的插件,支持從 TiDB、Kafka、HDFS...
在本文的例子中,你將使用 Kubernetes 和 Docker 創建一個功能型Apache Spark集群。 你將使用Spark standalone模式 安裝一個 Spark master服務和一組Spark workers。 對于已熟悉這部分內容的讀者,可以直接跳到 tl;dr 章節。 源代碼 Docker 鏡像...
ChatGPT和Sora等AI大模型應用,將AI大模型和算力需求的熱度不斷帶上新的臺階。哪里可以獲得...
大模型的訓練用4090是不合適的,但推理(inference/serving)用4090不能說合適,...
圖示為GPU性能排行榜,我們可以看到所有GPU的原始相關性能圖表。同時根據訓練、推理能力由高到低做了...




 Object
Object








