hbase調優SEARCH AGGREGATION


回答:這個太范化了吧。大數據架構選擇的方案就有很多,海量數據的即席查詢本省就是業內目前的痛點,暫時沒有太好的解決方案,kylin等框架也只是一個折中方案,如果你不是要求海量數據分析的秒級響應的話sparkSql、presto等都是不錯的方案,分鐘級別可以返回。
 Paul_King
|
681人閱讀
Paul_King
|
681人閱讀
回答:安裝 HBase(Hadoop Database)是在 Linux 操作系統上進行大規模數據存儲和處理的一種分布式數據庫解決方案。以下是在 Linux 上安裝 HBase 的一般步驟: 步驟 1:安裝 Java 在 Linux 上安裝 HBase 需要 Java 運行時環境(JRE)或 Java 開發工具包(JDK)。您可以通過以下命令安裝 OpenJDK: 對于 Ubuntu/Debian...
 hyuan
|
923人閱讀
hyuan
|
923人閱讀
回答:我們已經上線了好幾個.net core的項目,基本上都是docker+.net core 2/3。說實話,.net core的GC非常的優秀,基本上不需要像做Java時候,還要做很多的優化。因此沒有多少人研究很正常。換句話,如果一個GC還要做很多優化,這肯定不是好的一個GC。當然平時編程的時候,常用的非托管的對象處理等等還是要必須掌握的。
 ZweiZhao
|
1004人閱讀
ZweiZhao
|
1004人閱讀
回答:一、區別:1、Hbase: 基于Hadoop數據庫,是一種NoSQL數據庫;HBase表是物理表,適合存放非結構化的數據。2、hive:本身不存儲數據,通過SQL來計算和處理HDFS上的結構化數據,依賴HDFS和MapReduce;hive中的表是純邏輯表。Hbase主要解決實時數據查詢問題,Hive主要解決數據處理和計算問題,二者通常協作配合使用。二、適用場景:1、Hbase:海量明細數據的隨機...
 wizChen
|
2506人閱讀
wizChen
|
2506人閱讀
問題描述:[hadoop@usdp01 ~]$ hbase shellSLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/opt/usdp-srv/srv/udp/2.0.0.0/hdfs/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]...
回答:1. 如果你對數據的讀寫要求極高,并且你的數據規模不大,也不需要長期存儲,選redis;2. 如果你的數據規模較大,對數據的讀性能要求很高,數據表的結構需要經常變,有時還需要做一些聚合查詢,選MongoDB;3. 如果你需要構造一個搜索引擎或者你想搞一個看著高大上的數據可視化平臺,并且你的數據有一定的分析價值或者你的老板是土豪,選ElasticSearch;4. 如果你需要存儲海量數據,連你自己都...
 xiao7cn
|
962人閱讀
xiao7cn
|
962人閱讀
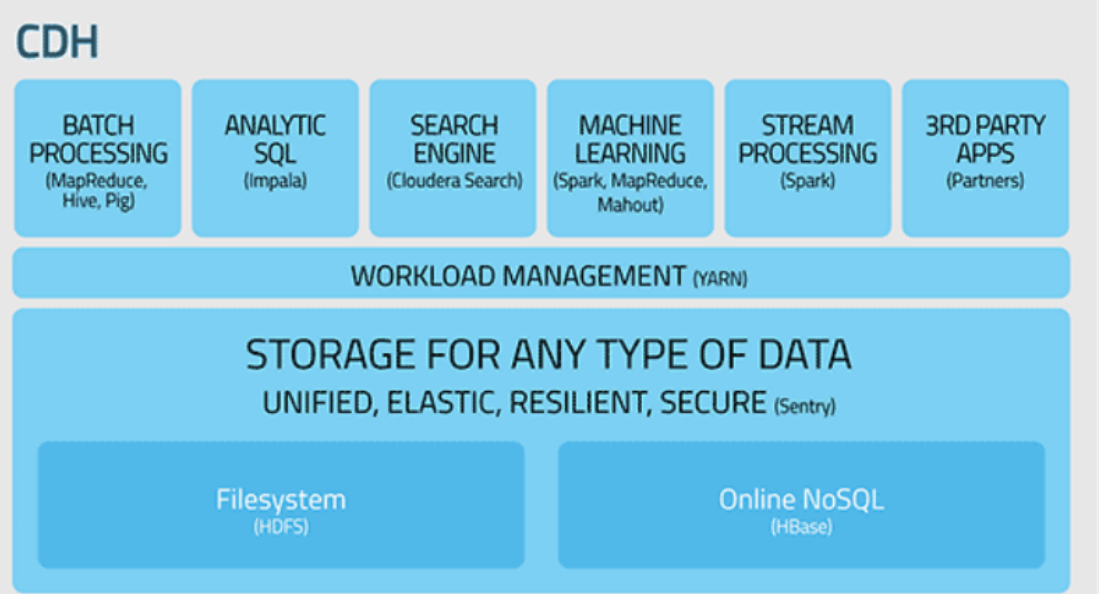

...景分別是?你項目中用的是哪個? 9、你還知道哪些 JVM 調優參數? 10、假如線上服務發生 OOM,有哪些措施可以找到問題? 11、假如線上服務 CPU 很高該怎么做?有哪些措施可以找到問題? 12、假如線上應用頻繁發生 Full GC,有哪...
...表會影響穩定性;SQL支持算子下推、schema映射、各種參數調優,高并發scan大表會影響穩定性;直接訪問HFile,直接訪問存儲不經過計算,大批量量訪問性能最好,需要snapshot對齊數據。時序-OpenTSDB & HiTSDBTSD沒有狀態,可以動態加...
...內容預覽 大數據:spark、HBase、Hadoop 46頁《JVM 深度調優,演講PPT》 互聯網2340面試答案、JVM深度調優PPT、大數據文檔 關注我私信回復666即可領取。
...持**UCloud大數據團隊積淀了多年公有云大數據運維和業務調優經驗,通過持續更新的文檔知識庫,為用戶提供專家級技術支持,解決使用USDP的后顧之憂。反哺開源社區USDP免費版中所使用的開源、全面兼容優化后的服務包,將反...
...支持UCloud大數據團隊積淀了多年公有云大數據運維和業務調優經驗,通過持續更新的文檔知識庫,為用戶提供專家級技術支持,解決使用USDP的后顧之憂。反哺開源社區USDP免費版中所使用的開源、全面兼容優化后的服務包,將反...
ChatGPT和Sora等AI大模型應用,將AI大模型和算力需求的熱度不斷帶上新的臺階。哪里可以獲得...
大模型的訓練用4090是不合適的,但推理(inference/serving)用4090不能說合適,...
圖示為GPU性能排行榜,我們可以看到所有GPU的原始相關性能圖表。同時根據訓練、推理能力由高到低做了...












