hadoop性能提升SEARCH AGGREGATION


問(wèn)題描述:該問(wèn)題暫無(wú)描述
 dmlllll
|
951人閱讀
dmlllll
|
951人閱讀
問(wèn)題描述:關(guān)于url轉(zhuǎn)發(fā)怎么提升排名這個(gè)問(wèn)題,大家能幫我解決一下嗎?
 馬忠志
|
1055人閱讀
馬忠志
|
1055人閱讀
問(wèn)題描述:關(guān)于如何使用云主機(jī)運(yùn)行hadoop這個(gè)問(wèn)題,大家能幫我解決一下嗎?
 鄒立鵬
|
928人閱讀
鄒立鵬
|
928人閱讀
回答:當(dāng)前最多的程序員可能就是Java程序員了,作為工作了近20年的Java程序員,一路走來(lái)經(jīng)歷過(guò)很多彎路,也見(jiàn)過(guò)、培訓(xùn)過(guò)很多技術(shù)人員一步步成長(zhǎng),作為公司的技術(shù)負(fù)責(zé)人一直試圖把自己血淚史、最佳實(shí)踐進(jìn)行傳導(dǎo)、傳播,中間犯過(guò)理想主義的錯(cuò)誤,以為:告訴他(們),他們就可以知道、就會(huì)不犯錯(cuò)誤,事實(shí)上不是這樣的,計(jì)算機(jī)是一門實(shí)踐性科學(xué),很多東西需要實(shí)踐、反復(fù)訓(xùn)練才可以深刻理解、才可以轉(zhuǎn)化為能力,以至變成下意識(shí)的行...
 luodongseu
|
989人閱讀
luodongseu
|
989人閱讀

...展,一個(gè)大數(shù)據(jù)系統(tǒng),可以多達(dá)幾萬(wàn)臺(tái)機(jī)器甚至更多。 Hadoop最初主要包含分布式文件系統(tǒng)HDFS和計(jì)算框架MapReduce兩部分,是從Nutch中獨(dú)立出來(lái)的項(xiàng)目。在2.0版本中,又把資源管理和任務(wù)調(diào)度功能從MapReduce中剝離形成YARN,使其他框...
...文件并發(fā)寫入IOPS提升10倍。在大數(shù)據(jù)場(chǎng)景下,US3支持完整Hadoop接入方案,相同規(guī)模的對(duì)象存儲(chǔ)集群,可比原有HDFS集群提升5倍數(shù)據(jù)寫入速度;Spark數(shù)據(jù)處理時(shí)間縮短75%,幫助用戶大幅提升數(shù)據(jù)處理效率。特點(diǎn)四:性價(jià)比存儲(chǔ)成本...
...將來(lái)也可能會(huì)有大用處。所以,大量公司都寄希望于使用Hadoop解決如下難題:采集并存儲(chǔ)與公司業(yè)務(wù)職能相關(guān)的所有數(shù)據(jù)。支撐先進(jìn)的分析功能,包括商業(yè)智能,采用現(xiàn)代方式對(duì)數(shù)據(jù)進(jìn)行先進(jìn)的可視化和預(yù)測(cè)性分析。將數(shù)據(jù)快速...
...,一個(gè)大數(shù)據(jù)系統(tǒng),可以多達(dá)幾萬(wàn)臺(tái)機(jī)器甚至更多。二、hadoop概述Hadoop是一個(gè)開(kāi)發(fā)和運(yùn)行處理大規(guī)模數(shù)據(jù)的軟件平臺(tái),是Apache的一個(gè)用Java語(yǔ)言實(shí)現(xiàn)開(kāi)源軟件框架,實(shí)現(xiàn)在大量計(jì)算機(jī)組成的集群中對(duì)海量數(shù)據(jù)進(jìn)行分布式計(jì)算。Hadoo...
...術(shù)與最佳實(shí)踐》 《利用Python進(jìn)行數(shù)據(jù)分析》 大數(shù)據(jù)類 《Hadoop權(quán)威指南(第3版)》 《大數(shù)據(jù)之路 阿里巴巴大數(shù)據(jù)實(shí)踐》 《Flume構(gòu)建高可用、可擴(kuò)展的海量日志采集系統(tǒng)》 《Greenplum企業(yè)應(yīng)用實(shí)戰(zhàn)》 《Hadoop技術(shù)內(nèi)幕:深入解析MapR...
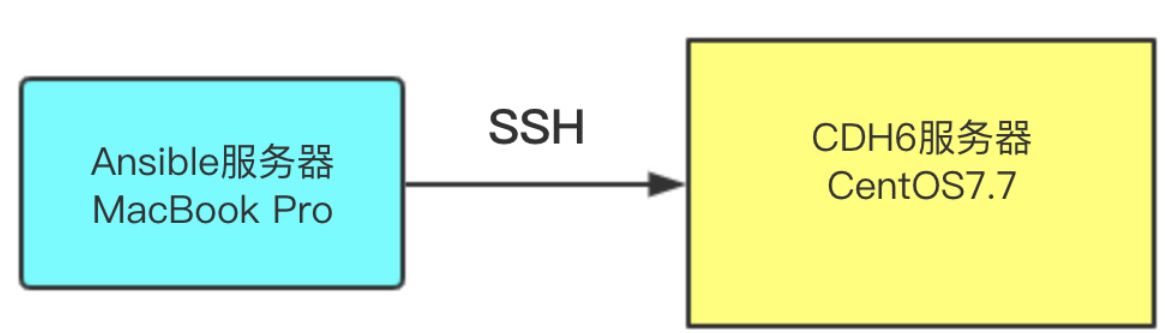
...進(jìn)和新功能,及開(kāi)源項(xiàng)目具體如下: Hadoop:CDH 8.3.0提供了Apache Hadoop 3.3.0版本,其中包含了Hadoop 3.3.0-alpha4版本。Hadoop 3.3.0包含了許多改進(jìn),包括對(duì)HDFS和YARN的性能提升,以及對(duì)MapReduce的改進(jìn)。 ...
ChatGPT和Sora等AI大模型應(yīng)用,將AI大模型和算力需求的熱度不斷帶上新的臺(tái)階。哪里可以獲得...
大模型的訓(xùn)練用4090是不合適的,但推理(inference/serving)用4090不能說(shuō)合適,...
圖示為GPU性能排行榜,我們可以看到所有GPU的原始相關(guān)性能圖表。同時(shí)根據(jù)訓(xùn)練、推理能力由高到低做了...




 wind5o
wind5o 馬龍駒
馬龍駒










