資訊專欄INFORMATION COLUMN

摘要:其實我們在做線性回歸也好,分類邏輯斯蒂回歸也好,本質上來講,就是把數據進行映射,要么映射到一個多個離散的標簽上,或者是連續的空間里面,一般簡單的數據而言,我們很好擬合,只要線性變化一下,然后學習出較好的就可以了,但是對于一些比較復雜的數據怎
其實我們在做線性回歸也好,分類(邏輯斯蒂回歸)也好,本質上來講,就是把數據進行映射,要么映射到一個多個離散的標簽上,或者是連續的空間里面,一般簡單的數據而言,我們很好擬合,只要線性變化一下,然后學習出較好的W就可以了,但是對于一些比較復雜的數據怎么辦呢?比如說,對于一個二分類問題,特別是高緯度復雜化之后,數據不一定是線性可分的,這個時候,我們的basis function隆重登場,我們可以把數據進行一定的映射,轉變,非線性的線性的,轉變之后,就可以進行分類,最明顯的例子在andrew NG在講SVM里面的例子就很好的說明了,但是這個時候問題來了,對于一個很復雜,高維度的數據,我們如何才能找到較好的basis function呢?
這個時候,神經網絡隆重登場,我們把我們的basis function打開來,我們把誤差轉遞到basis function的里面,通過這樣的方式,來得到較好的basis function,同理,我們可以無限打開basis function,一直打開,對應的也就是一層神經網絡(具體出自于prml關于神經網絡的章節最開始簡介的部分),但是問題來了,對于圖片怎么辦?我們知道,對于圖片而言,圖片是一個二維度的數據,我們怎樣才能通過學習圖片正確的模式來對于一張圖片有正確的對于圖片分類呢?這個時候,有人就提出了一個觀點,我們可以這樣,對于所有的像素,全部都連接上一個權值,我們也分很多層,然后最后進行分類,這樣也可以,但是對于一張圖片來說,像素點太多,參數太多了。然后就有人提出來,我們只看一部分怎么樣,就是對于一張圖片來說,我們只看一個小窗口就可以了,對于其他的地方,我們也提供類似的小窗口,我們知道,當我們對圖片進行卷積的時候,我們可以對圖片進行很多操作,比如說圖片整體模糊,或者是邊緣的提取,卷積操作對于圖片來說可以很好的提取到特征,而且通過BP誤差的傳播,我們可以根據不同任務,得到對于這個任務較好的一個參數,學習出相對于這個任務的較好的卷積核,之所以權值共享的邏輯是:如果說一個卷積核在圖片的一小塊兒區域可以得到很好的特征,那么在其他的地方,也可以得到很好的特征。
這就有了alex net的提出,通過對圖片進行五層(不知道有沒有記憶錯誤)的卷積,然后后面三層的全連接,我們可以得到一個很好的結果,特別的相對于更大的數據集而言,較好參數越多越好,也就是網絡較好更加深,更加的寬。
但是神經網絡到底是什么?對于一批數據我們有很多的問題,為什么設置五層較好,batchsize多少比較好,每一層多少個卷積核(這個到現在我依舊沒有一個更好的解釋,每一個應該多少卷積核),寬度多少?要不要LRN?每一層都代表了什么?
這些的解釋,就要好好看看今年CVPR的文章Visualizing and Understanding Convolutional Networks ?這篇文章寫的很棒,而且2015 CVPR出了很多對于卷積神經網絡理解的文章,這篇文章提出了一個反卷積的方法(De-convolution)的方法,這樣我們就可以好好看看每一層卷積神經網絡到底做了什么事情:
首先第一層的返卷積(上面是反卷積的圖片,下面對于第一層來說,激活值較大的圖片):

我們看到,第一個卷積層只是表達了簡單的圖片的邊緣而已,我們來看第二層:

第二層稍稍復雜了一點點,可以包含的不僅僅是一個邊緣,可以是幾個邊緣的組合
第三層:

第四層:
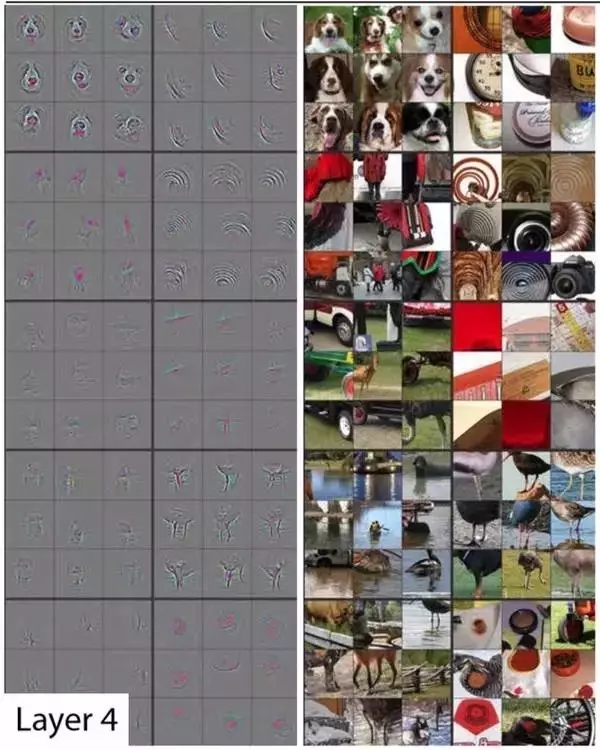
第五層:

我們看到,每一層都是對于一張圖片從最基礎的邊緣,不斷到最復雜的圖片自己本身。
同時在進行反卷積的時候M.D. Zeiler and R. Fergus也發現,對于第一層的alexnet,會得到頻度很高的像素(也就是顏色很深),所以他們也提出了應該要減小窗口,這樣可以得到頻度比較適中的像素:

當圖片卷積完之后,會把一個圖片對于這一類本身最獨特的部分凸顯出來,然后來進行判斷,這一類到底是什么?有下面的實驗截圖:

最左邊的圖像是原圖像,作者蓋住不同的區域,來分析對于一張圖片,經過五次卷積之后,到底是如何判斷的,我們看到卷積到最后(左三),比較凸顯出來的是狗的頭部,左二和右二的意思是,當我們遮住不同的區域,判斷是狗的幾率,紅色區域代表概率很高,藍色區域代表概率很低,我們發現,當我們遮擋住狗的頭的地方的時候,我們得到這個物體時狗的概率較低,這個側面證明了,所謂卷積神經網絡,就是會自動的對于一張圖片學習出較好的卷積核以及這些卷積核的組合方式,也就是對于一張圖片的任務來說,求出較好的圖片對于本任務的特征的表達,然后來進行判斷
還有一篇文章也助于理解,
Understanding Deep Image Representations by Inverting Them
這篇對于卷積每一層都不斷的還原到最原始的圖片:

越是到后面,圖片越模糊,但是它自己獨特的部分,卻凸顯了出來。(也就是這個猩猩還是狒狒的頭的部分)
聲明:文章收集于網絡,如有侵權,請聯系小編及時處理,謝謝!
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4819.html
摘要:其實我們在做線性回歸也好,分類邏輯斯蒂回歸也好,本質上來講,就是把數據進行映射,要么映射到一個多個離散的標簽上,或者是連續的空間里面,一般簡單的數據而言,我們很好擬合,只要線性變化一下,然后學習出較好的就可以了,但是對于一些比較復雜的數據怎 其實我們在做線性回歸也好,分類(邏輯斯蒂回歸)也好,本質上來講,就是把數據進行映射,要么映射到一個多個離散的標簽上,或者是連續的空間里面,一般簡單的數據...
摘要:卷積神經網絡除了為機器人和自動駕駛汽車的視覺助力之外,還可以成功識別人臉,物體和交通標志。卷積卷積神經網絡的名字來源于卷積運算。在卷積神經網絡中,卷積的主要目的是從輸入圖像中提取特征。 什么是卷積神經網絡,它為何重要?卷積神經網絡(也稱作 ConvNets 或 CNN)是神經網絡的一種,它在圖像識別和分類等領域已被證明非常有效。 卷積神經網絡除了為機器人和自動駕駛汽車的視覺助力之外,還可以成...

閱讀 2860·2019-08-30 15:44
閱讀 1887·2019-08-29 13:59
閱讀 2845·2019-08-29 12:29
閱讀 1090·2019-08-26 13:57
閱讀 3202·2019-08-26 13:45
閱讀 3330·2019-08-26 10:28
閱讀 824·2019-08-26 10:18
閱讀 1695·2019-08-23 16:52



