資訊專欄INFORMATION COLUMN

摘要:第一個主流產品級深度學習庫,于年由啟動。在年月日宣布,的開發(fā)將終止。張量中最基本的單位是常量變量和占位符。占位符并沒有初始值,它只會分配必要的內存。是一個字典,在字典中需要給出每一個用到的占位符的取值。
為什么選擇 TensorFlow?
在本文中,我們將對比當前最流行的深度學習框架(包括 Caffe、Theano、PyTorch、TensorFlow 和 Keras),幫助你為應用選擇最合適的框架。
1. Caffe:第一個主流產品級深度學習庫,于 2014 年由 UC Berkeley 啟動。
優(yōu)點:
快速
支持 GPU
漂亮的 Matlab 和 Python 接口
缺點:
不靈活。在 Caffe 中,每個節(jié)點被當做一個層,因此如果你想要一種新的層類型,你需要定義完整的前向、后向和梯度更新過程。這些層是網絡的構建模塊,你需要在無窮無盡的列表中進行選擇。(相反,在 TensorFlow 中,每個節(jié)點被當做一個張量運算例如矩陣相加、相乘或卷積。你可以輕易地定義一個層作為這些運算的組合。因此 TensorFlow 的構建模塊更小巧,允許更靈活的模塊化。)
需要大量的非必要冗長代碼。如果你希望同時支持 CPU 和 GPU,你需要為每一個實現(xiàn)額外的函數。你還需要使用普通的文本編輯器來定義你的模型。真令人頭疼!幾乎每個人都希望程序化地定義模型,因為這有利于不同組件之間的模塊化。有趣的是,Caffe 的主要架構師現(xiàn)在在 TensorFlow 團隊工作。
專一性。僅定位在計算機視覺(但做得很不錯)。
不是以 Python 編寫!如果你希望引入新的變動,你需要在 C++和 CUDA 上編程(對于更小的變動,你可以使用它的 Python 和 Matlab 接口)。
糟糕的文檔。
安裝比較困難!有大量的依賴包。
只有少量種類的輸入格式,僅有一種輸出格式 HDF5(雖然你總是可以使用它的 Python/C++/Matlab 接口來運行,并從中得到輸出數據)。
不適用于構建循環(huán)網絡。
2. Theano:由蒙特利爾大學研究團隊構建。Theano 的頂層構建了數值開源深度庫,包括 Keras、Lasagne 和 Blocks。Yoshua Bengio 在 2017 年 9 月 28 日宣布,Theano 的開發(fā)將終止。因此實際上 Theano 已死!
優(yōu)點:
計算圖的抽象很漂亮(可媲美 TensorFlow)
為 CPU 和 GPU 都做了優(yōu)化
很好地適應數值優(yōu)化任務
高級封裝(Keras、Lasagne)
缺點:
原始的 Theano 只有比較低級的 API
import numpy
? ? ? ? ? ?for _ in range(T):
? ? ? ? ? ? ? ?h = torch.matmul(W, h) + b
大型模型可能需要很長的編譯時間
不支持多 GPU
錯誤信息可能沒有幫助(有時候令人懊惱)
3. Pytorch:2017 年 1 月,F(xiàn)acebook 將 Python 版本的 Torch 庫(用 Lua 編寫)開源。
優(yōu)點:
提供動態(tài)計算圖(意味著圖是在運行時生成的),允許你處理可變長度的輸入和輸出,例如,在使用 RNN 時非常有用。
另一個例子是,在 PyTorch 中,可以使用標準 Python 語法編寫 for 循環(huán)語句。
大量預訓練模型
大量易于組合的模塊化組件
易于編寫自己的圖層類型,易于在 GPU 上運行
「TensorBoard」缺少一些關鍵功能時,「Losswise」可以作為 Pytorch 的替代品
缺點:
正式文檔以外的參考資料/資源有限
無商業(yè)支持
4. TensorFlow: 由較低級別的符號計算庫(如 Theano)與較高級別的網絡規(guī)范庫(如 Blocks 和 Lasagne)組合而成。
優(yōu)點:
由谷歌開發(fā)、維護,因此可以保障支持、開發(fā)的持續(xù)性。
巨大、活躍的社區(qū)
網絡訓練的低級、高級接口
「TensorBoard」是一款強大的可視化套件,旨在跟蹤網絡拓撲和性能,使調試更加簡單。
用 Python 編寫(盡管某些對性能有重要影響的部分是用 C++實現(xiàn)的),這是一種頗具可讀性的開發(fā)語言
支持多 GPU。因此可以在不同的計算機上自由運行代碼,而不必停止或重新啟動程序
比基于 Theano 的選項更快的模型編譯
編譯時間比 Theano 短
TensorFlow 不僅支持深度學習,還有支持強化學習和其他算法的工具。
缺點:
計算圖是純 Python 的,因此速度較慢
圖構造是靜態(tài)的,意味著圖必須先被「編譯」再運行
5. Keras:Keras 是一個更高級、對用戶最友好的 API,具有可配置的后端,由 Google Brain 團隊成員 Francis Chollet 編寫和維護。
優(yōu)點:
提供高級 API 來構建深度學習模型,使其易于閱讀和使用
編寫規(guī)范的文檔
大型、活躍的社區(qū)
位于其他深度學習庫(如 Theano 和 TensorFlow,可配置)之上
使用面向對象的設計,因此所有內容都被視為對象(如網絡層、參數、優(yōu)化器等)。所有模型參數都可以作為對象屬性進行訪問。
例如:
model.layers[3].output 將提供模型的第三層
model.layers[3].weights 是符號權重張量的列表
缺點:
由于用途非常普遍,所以在性能方面比較欠缺
與 TensorFlow 后端配合使用時會出現(xiàn)性能問題(因為并未針對其進行優(yōu)化),但與 Theano 后端配合使用時效果良好
不像 TensorFlow 或 PyTorch 那樣靈活
TensorFlow 基礎
TensorFlow 是一種采用數據流圖(data flow graphs),用于數值計算的開源軟件庫。其中 Tensor 代表傳遞的數據為張量(多維數組),F(xiàn)low 代表使用計算圖進行運算。數據流圖用「節(jié)點」(nodes)和「邊」(edges)組成的有向圖來描述數學運算。「節(jié)點」一般用來表示施加的數學操作,但也可以表示數據輸入的起點和輸出的終點,或者是讀取/寫入持久變量(persistent variable)的終點。邊表示節(jié)點之間的輸入/輸出關系。這些數據邊可以傳送維度可動態(tài)調整的多維數據數組,即張量(tensor)。
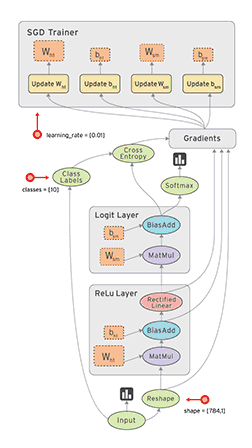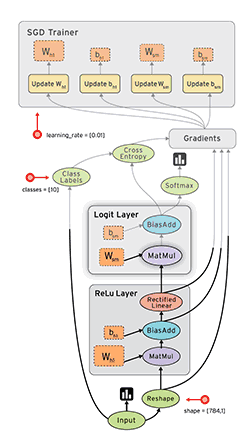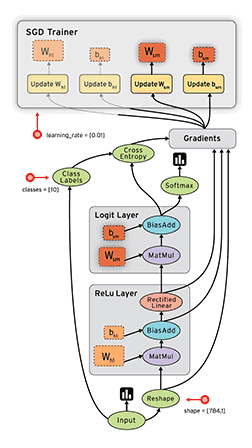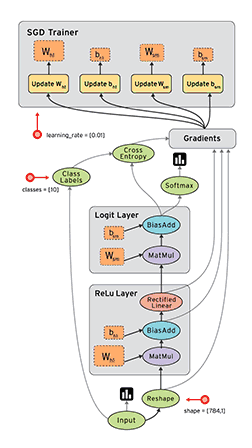
計算圖與會話
學習 TensorFlow 的第一步是了解它的主要特色——「計算圖」方法。基本上所有的 TensorFlow 代碼都包含兩個重要部分:
1. 創(chuàng)建「計算圖」,表示計算的數據流
2. 運行「會話」,執(zhí)行圖中的運算
事實上,TensorFlow 將計算的定義與其執(zhí)行分開。這兩個部分將在以下各節(jié)中詳細說明。在此之前,請記住第一步是導入 TensorFlow !
import tensorflow as tf
這樣,Python 就可以訪問 TensorFlow 的所有類、方法和符號。使用此命令,TensorFlow 庫將在別名「tf」下導入,以便以后我們可以使用它而不必每次鍵入其全稱「TensorFlow」。
1. 計算圖
TensorFlow 的創(chuàng)意中的較大創(chuàng)意是數值計算被表達成計算圖。換種說法,任何 TensorFlow 程序的骨干都是一個計算圖。正如 TensorFlow 官網上提及的,「一個計算圖是被組織到圖節(jié)點上的一系列 TensorFlow 運算」。
首先,什么是節(jié)點和運算?較好的解釋方式是,舉個例子。假設我們?yōu)楹瘮怠竑(x,y)=x^2y+y+2」編寫代碼。TensorFlow 中的計算圖如下所示:
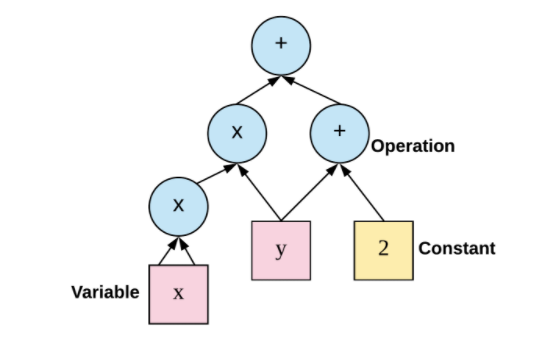
圖 2:TensorFlow 構建的計算圖。
如上圖所示,計算圖有一系列由邊互相連接的節(jié)點構成。每個節(jié)點稱為 op,即 operation(運算)的縮寫。因此每個節(jié)點代表一個運算,可能是張量運算或生成張量的操作。每個節(jié)點以零或更多張量為輸入,并生成一個張量作為輸出。
現(xiàn)在我們來構建一個簡單的計算圖。
import tensorflow as tf
a = 2
b = 3
c = tf.add(a, b, name="Add")
print(c)
______________________________________________________
Tensor("Add:0", shape=(), dtype=int32)
生成的計算圖和變量為:

圖 3:左:生成的圖在 Tensorboard 中可視化;右:生成的變量(在 debug 模式下運行時從 PyCharm 調試器獲取的屏幕截圖)
為了實際評估節(jié)點,必須在會話內運行計算圖。簡言之,編寫的代碼只生成僅僅用來確定張量的預期大小以及對它們執(zhí)行的運算的圖。但是,它不會為任何張量賦值。
因此,TensorFlow Graph 類似于 Python 中的函數定義。它「不會」為你執(zhí)行任何計算(就像函數定義不會有任何執(zhí)行結果一樣)。它「僅」定義計算操作。
2. 會話(Session)
在 TensorFlow 中,所有不同的變量和運算都是儲存在計算圖。所以在我們構建完模型所需要的圖之后,還需要打開一個會話(Session)來運行整個計算圖。在會話中,我們可以將所有計算分配到可用的 CPU 和 GPU 資源中。舉個簡單的例子,運行計算圖并獲取 c 的值:
sess = tf.Session()
print(sess.run(c))
sess.close()
__________________________________________
5
這些代碼創(chuàng)建了一個 Session() 對象(分配到 sess),然后(第二行)調用它的運行方法來運行足夠的計算圖以評估 c。計算完畢后需要關閉會話來幫助系統(tǒng)回收資源,不然就會出現(xiàn)資源泄漏的問題。
TensorFlow 張量
import tensorflow as tf
TensorFlow 中最基本的單位是常量(Constant)、變量(Variable)和占位符(Placeholder)。常量定義后值和維度不可變,變量定義后值可變而維度不可變。在神經網絡中,變量一般可作為儲存權重和其他信息的矩陣,而常量可作為儲存超參數或其他結構信息的變量。
1. 常量
創(chuàng)建一個節(jié)點取常數值,它接收以下的變量:
tf.constant(value, dtype=None, shape=None, name="Const", verify_shape=False)
我們來創(chuàng)建兩個常量并將它們加起來。常量張量可以通過定義一個值來簡單地定義:
# create graph
a = tf.constant(2)
b = tf.constant(3)
c = a + b
# launch the graph in a session
with tf.Session() as sess:
? ? print(sess.run(c))
____________________________________________________
5 ? ?
現(xiàn)在我們來看看創(chuàng)建的計算圖和生成的數據類型:

2. 變量
變量是狀態(tài)性的節(jié)點,輸出的是它們當前的值,意味著它們可以在一個計算圖的多次執(zhí)行中保留它們的值。它們有一系列的有用特征,例如:
它們可以在訓練期間或訓練后保存到硬盤上。這允許來自不同公司和團隊的人們保存、恢復和發(fā)送他們的模型參數給別人。
默認情況下,梯度更新(在所有神經網絡中應用)將應用到計算圖中的所有變量。實際上,變量是你希望調整以最小化損失函數的東西。
為了創(chuàng)建變量,你可以按如下方式使用 tf.Variable:
# Create a variable.
w = tf.Variable(
以下語句聲明一個 2 行 3 列的變量矩陣,該變量的值服從標準差為 1 的正態(tài)分布,并隨機生成。
w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
TensorFlow 還有 tf.truncated_normal() 函數,即截斷正態(tài)分布隨機數,它只保留 [mean-2*stddev,mean+2*stddev] 范圍內的隨機數。
調用 tf.Variable 來創(chuàng)建一個變量是一種老方法。TensorFlow 推薦使用封裝器 tf.get_variable,它能接收命名、形狀等參數:
tf.get_variable(name,
? ? ? ? ? ? ? ? shape=None,
? ? ? ? ? ? ? ? dtype=None,
? ? ? ? ? ? ? ? initializer=None,
? ? ? ? ? ? ? ? regularizer=None,
? ? ? ? ? ? ? ? trainable=True,
? ? ? ? ? ? ? ? collections=None,
? ? ? ? ? ? ? ? caching_device=None,
? ? ? ? ? ? ? ? partitioner=None,
? ? ? ? ? ? ? ? validate_shape=True,
? ? ? ? ? ? ? ? use_resource=None,
? ? ? ? ? ? ? ? custom_getter=None,
? ? ? ? ? ? ? ? constraint=None)
變量在使用前需要初始化。為此,我們必須調用「變量初始值設定項操作」,并在 session 上運行該操作。
a = tf.get_variable(name="var_1", initializer=tf.constant(2))
b = tf.get_variable(name="var_2", initializer=tf.constant(3))
c = tf.add(a, b, name="Add1")
# launch the graph in a session
with tf.Session() as sess:
? ? # now let"s evaluate their value
? ? print(sess.run(a))
? ? print(sess.run(b))
? ? print(sess.run(c))
3. 占位符
我們已經創(chuàng)建了各種形式的常量和變量,但 TensorFlow 同樣還支持占位符。占位符并沒有初始值,它只會分配必要的內存。在會話中,占位符可以使用 feed_dict 饋送數據。
feed_dict 是一個字典,在字典中需要給出每一個用到的占位符的取值。在訓練神經網絡時需要每次提供一個批量的訓練樣本,如果每次迭代選取的數據要通過常量表示,那么 TensorFlow 的計算圖會非常大。因為每增加一個常量,TensorFlow 都會在計算圖中增加一個節(jié)點。所以說擁有幾百萬次迭代的神經網絡會擁有極其龐大的計算圖,而占位符卻可以解決這一點,它只會擁有占位符這一個節(jié)點。
a = tf.constant([5, 5, 5], tf.float32, name="A")
b = tf.placeholder(tf.float32, shape=[3], name="B")
c = tf.add(a, b, name="Add")
with tf.Session() as sess:
? ? # create a dictionary:
? ? d = {b: [1, 2, 3]}
? ? # feed it to the placeholder
? ? print(sess.run(c, feed_dict=d))?
?___________________________________________________
?[6. 7. 8.]
它生成的計算圖與變量如下所示:

現(xiàn)在,我們已經能創(chuàng)建一個簡單的神經網絡。如下利用隨機生成的數據創(chuàng)建了一個三層全連接網絡:
import tensorflow as tf
from numpy.random import RandomState
batch_size=10
w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2=tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
# None 可以根據batch 大小確定維度,在shape的一個維度上使用None
x=tf.placeholder(tf.float32,shape=(None,2))
y=tf.placeholder(tf.float32,shape=(None,1))
#激活函數使用ReLU
a=tf.nn.relu(tf.matmul(x,w1))
yhat=tf.nn.relu(tf.matmul(a,w2))
#定義交叉熵為損失函數,訓練過程使用Adam算法最小化交叉熵
cross_entropy=-tf.reduce_mean(y*tf.log(tf.clip_by_value(yhat,1e-10,1.0)))
train_step=tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
rdm=RandomState(1)
data_size=516
#生成兩個特征,共data_size個樣本
X=rdm.rand(data_size,2)
#定義規(guī)則給出樣本標簽,所有x1+x2<1的樣本認為是正樣本,其他為負樣本。Y,1為正樣本
Y = [[int(x1+x2 < 1)] for (x1, x2) in X]
with tf.Session() as sess:
? ? sess.run(tf.global_variables_initializer())
? ? print(sess.run(w1))
? ? print(sess.run(w2))
? ? steps=11000
? ? for i in range(steps):
? ? ? ? #選定每一個批量讀取的首尾位置,確保在1個epoch內采樣訓練
? ? ? ? start = i * batch_size % data_size
? ? ? ? end = min(start + batch_size,data_size)
? ? ? ? sess.run(train_step,feed_dict={x:X[start:end],y:Y[start:end]})
? ? ? ? if i % 1000 == 0:
? ? ? ? ? ? training_loss= sess.run(cross_entropy,feed_dict={x:X,y:Y})
? ? ? ? ? ? print("在迭代 %d 次后,訓練損失為 %g"%(i,training_loss))
上面的代碼定義了一個簡單的三層全連接網絡(輸入層、隱藏層和輸出層分別為 2、3 和 2 個神經元),隱藏層和輸出層的激活函數使用的是 ReLU 函數。該模型訓練的樣本總數為 512,每次迭代讀取的批量為 10。這個簡單的全連接網絡以交叉熵為損失函數,并使用 Adam 優(yōu)化算法進行權重更新。
其中需要注意的幾個函數如 tf.nn.relu() 代表調用 ReLU 激活函數,tf.matmul() 為矩陣乘法等。tf.clip_by_value(yhat,1e-10,1.0) 這一語句代表的是截斷 yhat 的值,因為這一語句是嵌套在 tf.log() 函數內的,所以我們需要確保 yhat 的取值不會導致對數無窮大。
TensorBoard 基礎
TensorBoard 是一個可視化軟件,在所有的 TensorFlow 標準安裝中都包含了 TensorBoard。按谷歌的話說:「使用 TensorFlow 執(zhí)行的計算,例如訓練一個大規(guī)模深度神經網絡,可能復雜且令人困惑。為了更加容易理解、調試和優(yōu)化 TensorFlow 程序,我們內置了一套可視化工具,即 TensorBoard。」
TensorFlow 程序既能解決非常簡單也能解決非常復雜的問題,它們都有兩種基本組件——運算和張量。如前所述,你創(chuàng)建了一個由一系列運算構成的模型,饋送數據到模型上,張量將在運算之間流動,直到得到了輸出張量,即你的結果。
完全配置好后,TensorBoard 窗口將呈現(xiàn)與下圖類似的畫面:

TensorBoard 的創(chuàng)建是為了幫助你了解模型中張量的流動,以便調試和優(yōu)化模型。它通常用于兩項任務:
1. 圖形可視化
2. 編寫摘要(或可視化學習)
在本教程中,我們將介紹 TensorBoard 的上述兩項主要用法。盡早學習使用 TensorBoard,可以讓使用 TensorFlow 的工作更有趣也更有成效。
1. 計算圖可視化
強大的 TensorFlow 計算圖會變得極其復雜。可視化圖形有助于理解并對其進行調試。這是一個在 TensorFlow 網站工作的可視化示例。
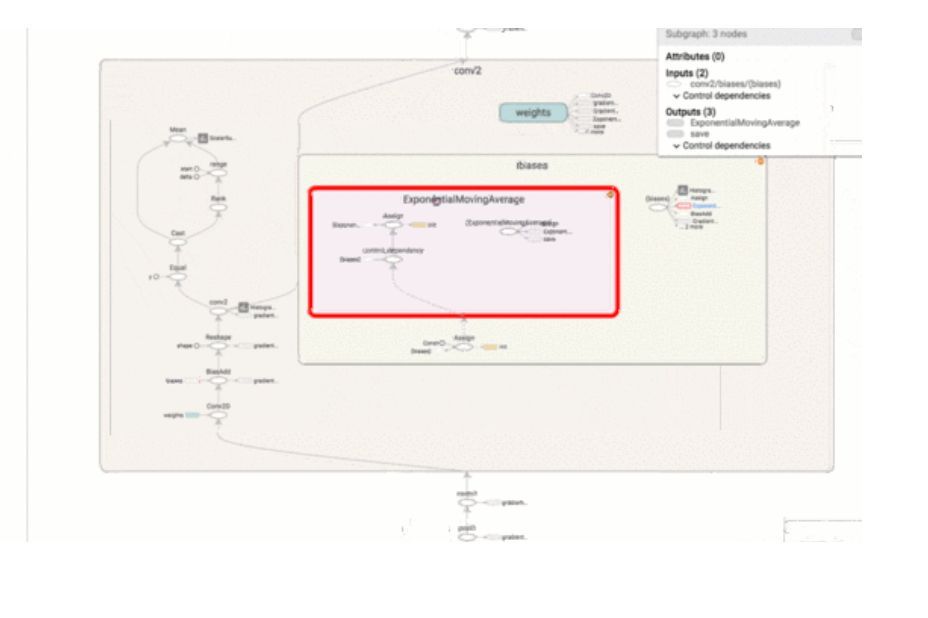
為了激活 TensorFlow 程序 TensorBoard,需要向其中添加幾行代碼。這將把 TensorFlow 運算導出到一個名為「event file」(或 event log file)的文件中。TensorBoard 能夠讀取此文件并深入了解模型圖及其性能。
現(xiàn)在我們來編寫一個簡單的 TensorFlow 程序,并用 TensorBoard 可視化其計算圖。先創(chuàng)建兩個常量并將其添加到一起。常數張量可以簡單地通過定義它們的值來定義:
import tensorflow as tf
# create graph
a = tf.constant(2)
b = tf.constant(3)
c = tf.add(a, b)
# launch the graph in a session
with tf.Session() as sess:
? ? print(sess.run(c))
_____________________________________________
5?
為了用 TensorBoard 可視化程序,我們需要編寫程序的日志文件。為了編寫事件文件,我們首先需要為那些日志編寫一個 writer,使用以下代碼:
writer = tf.summary.FileWriter([logdir], [graph])
其中 [logdir] 是你想要保存那些日志文件的文件夾。你可以選擇 [logdir] 作為某些有意義的東西,例如『./graphs』。第二個參數 [graph] 是我們正在編寫的程序的計算圖。有兩種獲取計算圖的方法:
1. 使用 tf.get_default_graph() 調用計算圖,返回程序的默認計算圖
2. 將計算圖設置為 sess.graph,返回會話的計算圖(注意這里需要我們已經創(chuàng)建了會話)
我們將在以下的例子中展示兩種方法。然而,第二種方法更加常用。不管用哪種方法,確保僅當你定義了計算圖之后才創(chuàng)建一個 writer。否則,TensorBoard 中可視化的計算圖將是不完整的。讓我們添加 writer 到第一個例子中并可視化計算圖。
import tensorflow as tf
# create graph
a = tf.constant(2)
b = tf.constant(3)
c = tf.add(a, b)
# creating the writer out of the session
# writer = tf.summary.FileWriter("./graphs", tf.get_default_graph())
# launch the graph in a session
with tf.Session() as sess:
? ? # or creating the writer inside the session
? ? writer = tf.summary.FileWriter("./graphs", sess.graph)
? ? print(sess.run(c))
? ? # don"t forget to close the writer at the end
? ? writer.close()
接下來轉到 Terminal,確保當前工作目錄與運行 Python 代碼的位置相同。例如,此處我們可以使用以下代碼切換到目錄
$ cd ~/Desktop/tensorboard
接下來運行:
$ tensorboard --logdir="./graphs" —port 6006
這將為你生成一個鏈接。ctrl+左鍵單擊該鏈接(或將其復制到瀏覽器中,或只需打開瀏覽器并轉到 http://localhost:6006/)。接下來將顯示 TensorBoard 頁面,如下所示:
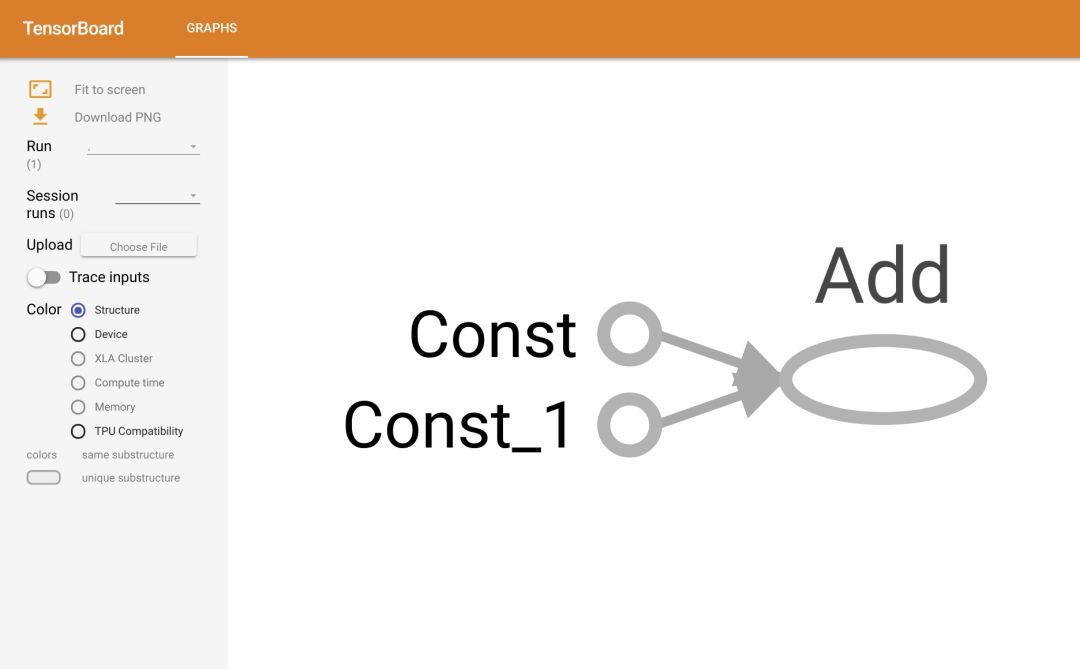
參數存儲與加載
在基礎部分中,最后還介紹了模型參數的保存與恢復。一般 TensorFlow 模型持久化可使用 tf.train.Saver() 完成,它會將 TensorFlow 模型保存為 .ckpt 格式的文件。一般該文件目錄下會有三個文件,第一個 model.ckpt.meta 保存了 TensorFlow 計算圖的結構,第二個 model.ckpt 文件保存了 TensorFlow 中每一個變量的取值,而最后一個 cheekpoint 文件保存了同目錄下所有的模型文件列表。
為了保存和恢復模型變量,我們需要在構建計算圖后調用 tf.train.Saver(),例如:
# create the graph
X = tf.placeholder(..)
Y = tf.placeholder(..)
w = tf.get_variale(..)
b = tf.get_variale(..)
...
loss = tf.losses.mean_squared_error(..)
optimizer = tf.train.AdamOptimizer(..).minimize(loss)
...
saver = tf.tfain.Saver()
在訓練模式中,我們需要打開會話初始化變量和運行計算圖,并在訓練結束時調用 saver.save() 保存變量:
# TRAIN
with tf.Session() as sess:
? ? sess.run(tf.globale_variables_initializer())
? ? # train our model
? ? for step in range(steps):
? ? ? ? sess.run(optimizer)
? ? ? ? ...
? ? saved_path = saver.save(sess, "./my-model", global_step=step)
在測試模式中,我們需要使用 saver.restore() 恢復參數:
# TEST
with tf.Session() as sess:
? ? saver.restore(sess, "./my-model")
? ? ...
當然,模型持久化還有非常多的內容,例如由 MetaGraphDef Protocol Buffer 定義的計算圖節(jié)點元數據。
歡迎加入本站公開興趣群商業(yè)智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4781.html
摘要:值得一提的是每篇文章都是我用心整理的,編者一貫堅持使用通俗形象的語言給我的讀者朋友們講解機器學習深度學習的各個知識點。今天,紅色石頭特此將以前所有的原創(chuàng)文章整理出來,組成一個比較合理完整的機器學習深度學習的學習路線圖,希望能夠幫助到大家。 一年多來,公眾號【AI有道】已經發(fā)布了 140+ 的原創(chuàng)文章了。內容涉及林軒田機器學習課程筆記、吳恩達 deeplearning.ai 課程筆記、機...

閱讀 2418·2021-11-16 11:44
閱讀 1876·2021-10-12 10:12
閱讀 2160·2021-09-22 15:22
閱讀 3007·2021-08-11 11:17
閱讀 1505·2019-08-29 16:53
閱讀 2653·2019-08-29 14:09
閱讀 3474·2019-08-29 14:03
閱讀 3300·2019-08-29 11:09



