資訊專欄INFORMATION COLUMN

摘要:本論文研究只有遺忘門的話會怎樣,并提出了,實驗表明該模型的性能優于標準。這里我們發現,一個只有遺忘門且帶有偏置項的版本不僅能節省計算成本,而且在多個基準數據集上的性能優于標準,能與一些當下較好的模型競爭。
本論文研究 LSTM 只有遺忘門的話會怎樣,并提出了 JANET,實驗表明該模型的性能優于標準 LSTM。
1.介紹
優秀的工程師確保其設計是實用的。目前我們已經知道解決序列分析問題較好的方式是長短期記憶(LSTM)循環神經網絡,接下來我們需要設計一個滿足資源受限的現實世界應用的實現。鑒于使用兩個門的門控循環單元(Cho 等,2014)的成功,第一種設計更硬件高效的 LSTM 的方法可能是消除冗余門(redundant gate)。因為我們要尋求比 GRU 更高效的模型,所以只有單門 LSTM 模型值得我們研究。為了說明為什么這個單門應該是遺忘門,讓我們從 LSTM 的起源講起。
在那個訓練循環神經網絡(RNN)十分困難的年代,Hochreiter 和 Schmidhuber(1997)認為在 RNN 中使用單一權重(邊)來控制是否接受記憶單元的輸入或輸出帶來了沖突性更新(梯度)。本質上來講,每一步中長短期誤差(long and short-range error)作用于相同的權重,且如果使用 sigmoid 激活函數的話,梯度消失的速度要比權重增加速度快。之后他們提出長短期記憶(LSTM)單元循環神經網絡,具備乘法輸入門和輸出門。這些門可以通過「保護」單元免受不相關信息(其他單元的輸入或輸出)影響,從而緩解沖突性更新問題。
LSTM 的第一個版本只有兩個門:Gers 等人(2000)首先發現如果沒有使記憶單元遺忘信息的機制,那么它們可能會無限增長,最終導致網絡崩潰。為解決這個問題,他們為這個 LSTM 架構加上了另一個乘法門,即遺忘門,完成了我們今天看到的 LSTM 版本。
?
鑒于遺忘門發現的重要性,那么設想 LSTM 僅使用一個遺忘門,輸入和輸出門是否必要呢?本研究將探索多帶帶使用遺忘門的優勢。在五個任務中,僅使用遺忘門的模型提供了比使用全部三個 LSTM 門的模型更好的解決方案。
3 JUST ANOTHER NETWORK
我們提出了一個簡單的 LSTM 變體,其只有一個遺忘門。它是 Just Another NETwork,因此我們將其命名為 JANET。我們從標準 LSTM(Lipton 等,2015)開始,其中符號具備標準含義,定義如下
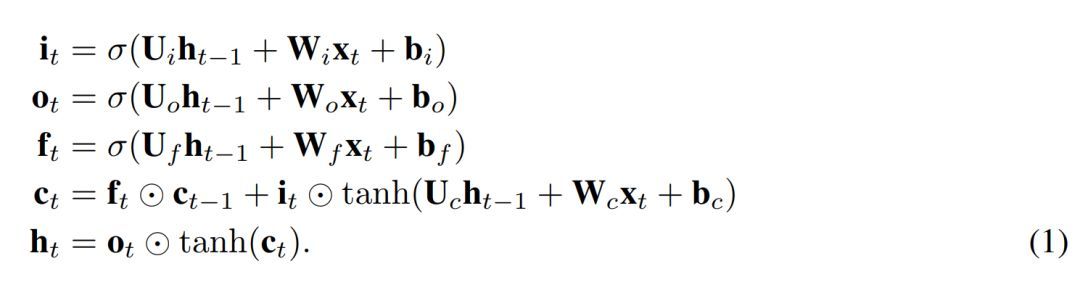
為了將上述內容轉換成 JANET 架構,我們刪除了輸入和輸出門。將信息的累積和刪除關聯起來似乎是明智的,因此我們將輸入和遺忘調制結合起來,就像 Greff et al. (2015) 論文中所做的那樣,而這與 leaky unit 實現 (Jaeger, 2002, §8.1) 類似。此外,h_t 的 tanh 激活函數使梯度在反向傳播期間出現收縮,這可能加劇梯度消失問題。權重 U? 可容納 [-1,1] 區間外的值,因此我們可移除這個不必要且可能帶來問題的 tanh 非線性函數。得出的 JANET 結果如下:
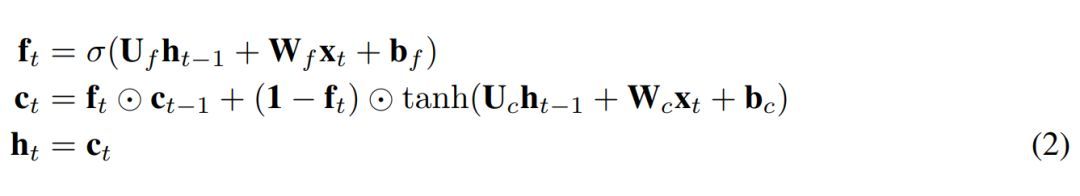
4 實驗與結果
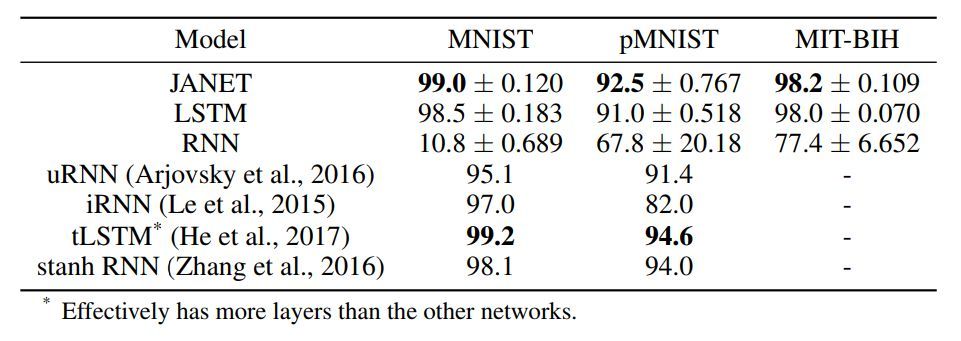
表 1:不同循環神經網絡架構的準確率 [%]。圖中展示了 10 次獨立運行得到的平均值和標準差。我們實驗中的較佳準確率結果以及引用論文中的較佳結果以粗體顯示。
令人驚訝的是,結果表明 JANET 比標準 LSTM 的準確率更高。此外,JANET 是在所有分析數據集上表現較佳的模型之一。因此,通過簡化 LSTM,我們不僅節省了計算成本,還提高了測試集上的準確率!
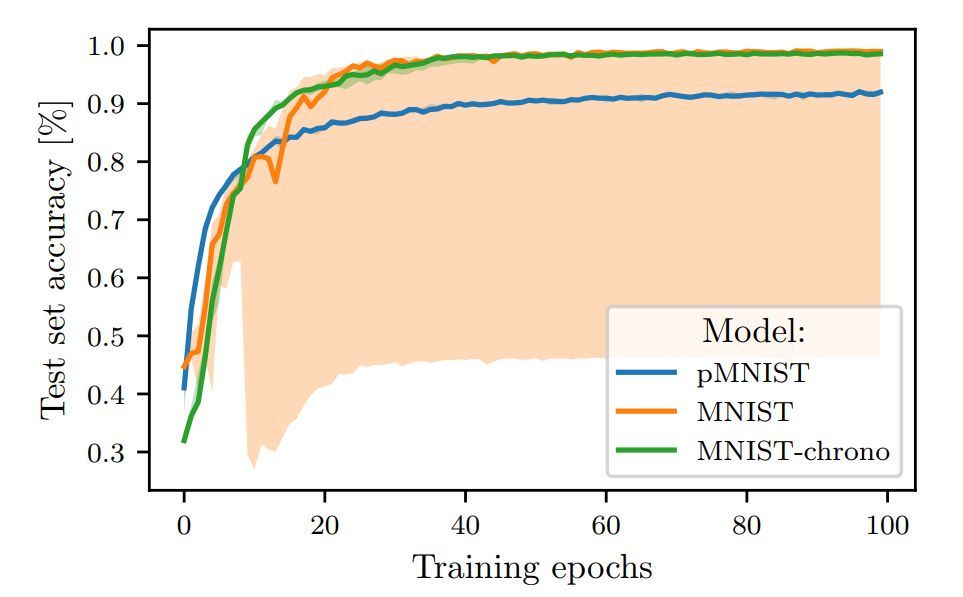
圖 1:在 MNIST 和 pMNIST 上訓練的 LSTM 的測試準確率。
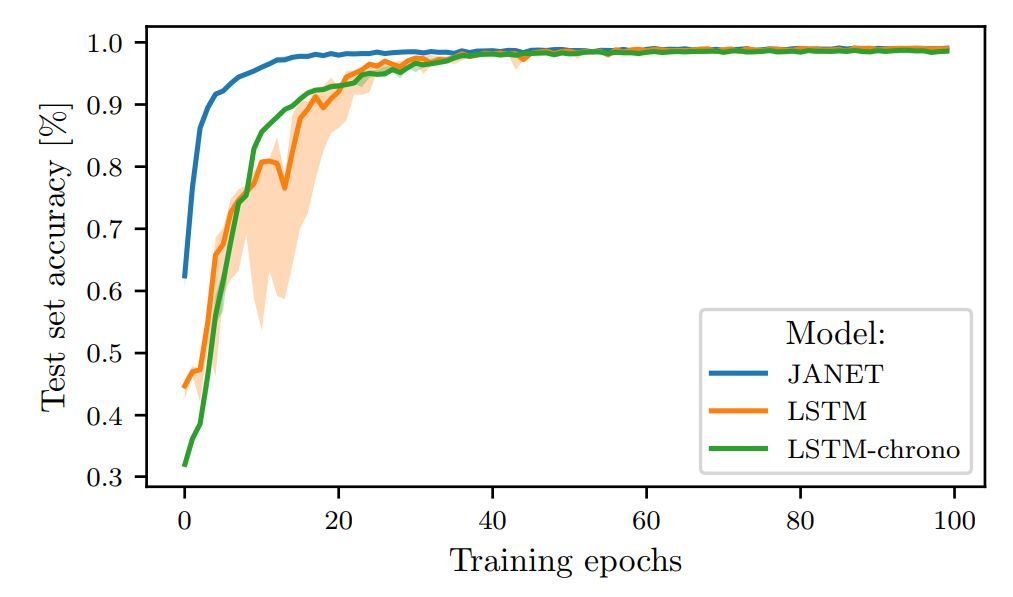
圖 2:JANET 和 LSTM 在 MNIST 上訓練時的測試集準確率對比。
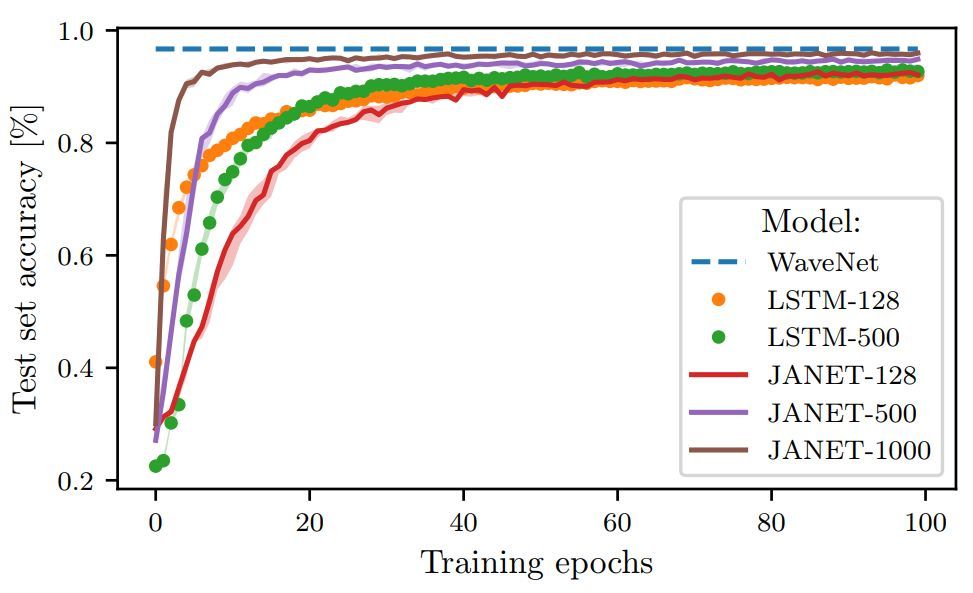
圖 3:不同層大小的 JANET 和 LSTM 在 pMNIST 數據集上的準確率(%)。
論文:THE UNREASONABLE EFFECTIVENESS OF THE FORGET GATE
論文鏈接:https://arxiv.org/abs/1804.04849
摘要:鑒于門控循環單元(GRU)的成功,一個很自然的問題是長短期記憶(LSTM)網絡中的所有門是否是必要的。之前的研究表明,遺忘門是 LSTM 中最重要的門之一。這里我們發現,一個只有遺忘門且帶有 chrono-initialized 偏置項的 LSTM 版本不僅能節省計算成本,而且在多個基準數據集上的性能優于標準 LSTM,能與一些當下較好的模型競爭。我們提出的網絡 JANET,在 MNIST 和 pMNIST 數據集上分別達到了 99% 和 92.5% 的準確率,優于標準 LSTM 98.5% 和 91% 的準確率。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4765.html
摘要:作為解決方案的和和是解決短時記憶問題的解決方案,它們具有稱為門的內部機制,可以調節信息流。隨后,它可以沿著長鏈序列傳遞相關信息以進行預測,幾乎所有基于遞歸神經網絡的技術成果都是通過這兩個網絡實現的。和采用門結構來克服短時記憶的影響。 短時記憶RNN 會受到短時記憶的影響。如果一條序列足夠長,那它們將很難將信息從較早的時間步傳送到后面的時間步。 因此,如果你正在嘗試處理一段文本進行預測,RNN...
摘要:前饋網絡的反向傳播從最后的誤差開始,經每個隱藏層的輸出權重和輸入反向移動,將一定比例的誤差分配給每個權重,方法是計算權重與誤差的偏導數,即兩者變化速度的比例。隨后,梯度下降的學習算法會用這些偏導數對權重進行上下調整以減少誤差。 目錄前饋網絡遞歸網絡沿時間反向傳播梯度消失與梯度膨脹長短期記憶單元(LSTM)涵蓋多種時間尺度本文旨在幫助神經網絡學習者了解遞歸網絡的運作方式,以及一種主要的遞歸網絡...
摘要:得到的結果如下上圖是門卷積神經網絡模型與和模型在數據集基準上進行測試的結果。雖然在這一研究中卷積神經網絡在性能上表現出了對遞歸神經網絡,尤其是的全面超越,但是,現在談取代還為時尚早。 語言模型對于語音識別系統來說,是一個關鍵的組成部分,在機器翻譯中也是如此。近年來,神經網絡模型被認為在性能上要優于經典的 n-gram 語言模型。經典的語言模型會面臨數據稀疏的難題,使得模型很難表征大型的文本,...

閱讀 2461·2021-11-22 15:35
閱讀 3756·2021-11-04 16:14
閱讀 2685·2021-10-20 13:47
閱讀 2487·2021-10-13 09:49
閱讀 2064·2019-08-30 14:09
閱讀 2359·2019-08-26 13:49
閱讀 879·2019-08-26 10:45
閱讀 2762·2019-08-23 17:54




