資訊專欄INFORMATION COLUMN

摘要:之后,注意力模型出現(xiàn)了。等企業(yè)越來越多地使用了基于注意力模型的網(wǎng)絡(luò)。所有這些企業(yè)已經(jīng)將及其變種替換為基于注意力的模型,而這僅僅是個(gè)開始。比起基于注意力的模型,需要更多的資源來訓(xùn)練和運(yùn)行。這樣的回溯前進(jìn)單元是神經(jīng)網(wǎng)絡(luò)注意力模型組。
循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN),長短期記憶(LSTM),這些紅得發(fā)紫的神經(jīng)網(wǎng)絡(luò)——是時(shí)候拋棄它們了!
LSTM和RNN被發(fā)明于上世紀(jì)80、90年代,于2014年死而復(fù)生。接下來的幾年里,它們成為了解決序列學(xué)習(xí)、序列轉(zhuǎn)換(seq2seq)的方式,這也使得語音到文本識(shí)別和Siri、Cortana、Google語音助理、Alexa的能力得到驚人的提升。
另外,不要忘了機(jī)器翻譯,包括將文檔翻譯成不同的語言,或者是神經(jīng)網(wǎng)絡(luò)機(jī)器翻譯還可以將圖像翻譯為文本,文字到圖像和字幕視頻等等。
在接下來的幾年里,ResNet出現(xiàn)了。ResNet是殘差網(wǎng)絡(luò),意為訓(xùn)練更深的模型。2016年,微軟亞洲研究院的一組研究員在ImageNet圖像識(shí)別挑戰(zhàn)賽中憑借驚人的152層深層殘差網(wǎng)絡(luò)(deep residual networks),以優(yōu)勢獲得圖像分類、圖像定位以及圖像檢測全部三個(gè)主要項(xiàng)目的冠軍。之后,Attention(注意力)模型出現(xiàn)了。
雖然僅僅過去兩年,但今天我們可以肯定地說:
“不要再用RNN和LSTM了,它們已經(jīng)不行了!”
讓我們用事實(shí)說話。Google、Facebook、Salesforce等企業(yè)越來越多地使用了基于注意力模型(Attention)的網(wǎng)絡(luò)。
所有這些企業(yè)已經(jīng)將RNN及其變種替換為基于注意力的模型,而這僅僅是個(gè)開始。比起基于注意力的模型,RNN需要更多的資源來訓(xùn)練和運(yùn)行。RNN命不久矣。
為什么
記住RNN和LSTM及其衍生主要是隨著時(shí)間推移進(jìn)行順序處理。請(qǐng)參閱下圖中的水平箭頭:

RNN中的順序處理
水平箭頭的意思是長期信息需在進(jìn)入當(dāng)前處理單元前順序遍歷所有單元。這意味著其能輕易被乘以很多次<0的小數(shù)而損壞。這是導(dǎo)致vanishing gradients(梯度消失)問題的原因。
為此,今天被視為救星的LSTM模型出現(xiàn)了,有點(diǎn)像ResNet模型,可以繞過單元從而記住更長的時(shí)間步驟。因此,LSTM可以消除一些梯度消失的問題。
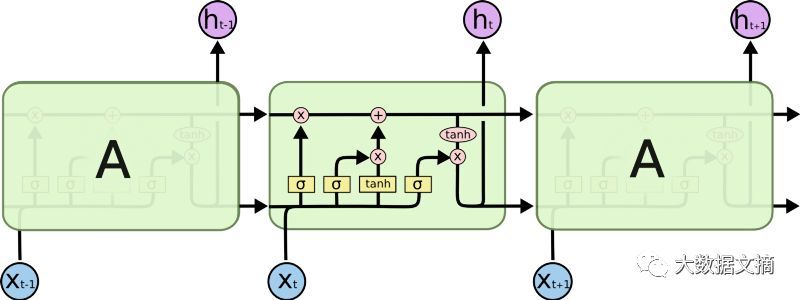
LSTM中的順序處理
從上圖可以看出,這并沒有解決全部問題。我們?nèi)匀挥幸粭l從過去單元到當(dāng)前單元的順序路徑。事實(shí)上,這條路現(xiàn)在更復(fù)雜了,因?yàn)樗懈郊游铮⑶液雎粤穗`屬于它上面的分支。
毫無疑問LSTM和GRU(Gated Recurrent Uni,是LSTM的衍生)及其衍生能夠記住大量更長期的信息!但是它們只能記住100個(gè)量級(jí)的序列,而不是1000個(gè)量級(jí),或者更長的序列。
還有一個(gè)RNN的問題是,訓(xùn)練它們對(duì)硬件的要求非常高。另外,在我們不需要訓(xùn)練這些網(wǎng)絡(luò)快速的情況下,它仍需要大量資源。同樣在云中運(yùn)行這些模型也需要很多資源。
考慮到語音到文本的需求正在迅速增長,云是不可擴(kuò)展的。我們需要在邊緣處進(jìn)行處理,比如Amazon Echo上處理數(shù)據(jù)。
該做什么?
如果要避免順序處理,那么我們可以找到“前進(jìn)”或更好“回溯”單元,因?yàn)榇蟛糠謺r(shí)間我們處理實(shí)時(shí)因果數(shù)據(jù),我們“回顧過去”并想知道其對(duì)未來決定的影響(“影響未來”)。在翻譯句子或分析錄制的視頻時(shí)并非如此,例如,我們擁有完整的數(shù)據(jù),并有足夠的處理時(shí)間。這樣的回溯/前進(jìn)單元是神經(jīng)網(wǎng)絡(luò)注意力(Neural Attention)模型組。
為此,通過結(jié)合多個(gè)神經(jīng)網(wǎng)絡(luò)注意力模型,“分層神經(jīng)網(wǎng)絡(luò)注意力編碼器”出現(xiàn)了,如下圖所示:
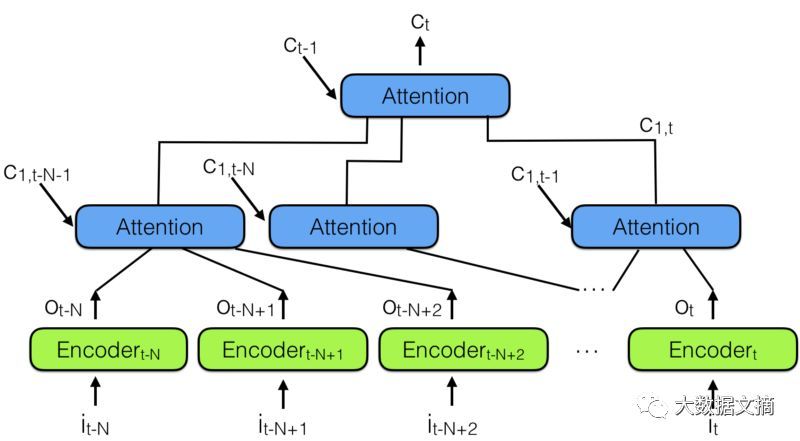
分層神經(jīng)網(wǎng)絡(luò)注意力編碼器
“回顧過去”的更好方式是使用注意力模型將過去編碼向量匯總到語境矢量 CT中。
請(qǐng)注意上面有一個(gè)注意力模型層次結(jié)構(gòu),它和神經(jīng)網(wǎng)絡(luò)層次結(jié)構(gòu)非常相似。這也類似于下面的備注3中的時(shí)間卷積網(wǎng)絡(luò)(TCN)。
在分層神經(jīng)網(wǎng)絡(luò)注意力編碼器中,多個(gè)注意力分層可以查看最近過去的一小部分,比如說100個(gè)向量,而上面的層可以查看這100個(gè)注意力模塊,有效地整合100 x 100個(gè)向量的信息。這將分層神經(jīng)網(wǎng)絡(luò)注意力編碼器的能力擴(kuò)展到10,000個(gè)過去的向量。
這才是“回顧過去”并能夠“影響未來”的正確方式!
但更重要的是查看表示向量傳播到網(wǎng)絡(luò)輸出所需的路徑長度:在分層網(wǎng)絡(luò)中,它與log(N)成正比,其中N是層次結(jié)構(gòu)層數(shù)。這與RNN需要做的T步驟形成對(duì)比,其中T是要記住的序列的較大長度,并且T >> N。
跳過3-4步追溯信息比跳過100步要簡單多了!
這種體系結(jié)構(gòu)跟神經(jīng)網(wǎng)絡(luò)圖靈機(jī)很相似,但可以讓神經(jīng)網(wǎng)絡(luò)通過注意力決定從內(nèi)存中讀出什么。這意味著一個(gè)實(shí)際的神經(jīng)網(wǎng)絡(luò)將決定哪些過去的向量對(duì)未來決策有重要性。
但是存儲(chǔ)到內(nèi)存怎么樣呢?上述體系結(jié)構(gòu)將所有先前的表示存儲(chǔ)在內(nèi)存中,這與神經(jīng)網(wǎng)絡(luò)圖靈機(jī)(NTM)不同。這可能是相當(dāng)?shù)托У模嚎紤]將每幀的表示存儲(chǔ)在視頻中——大多數(shù)情況下,表示向量不會(huì)改變幀到幀,所以我們確實(shí)存儲(chǔ)了太多相同的內(nèi)容!
我們可以做的是添加另一個(gè)單元來防止相關(guān)數(shù)據(jù)被存儲(chǔ)。例如,不存儲(chǔ)與以前存儲(chǔ)的向量太相似的向量。但這確實(shí)只是一種破解的方法,較好的方法是讓應(yīng)用程序指導(dǎo)哪些向量應(yīng)該保存或不保存。這是當(dāng)前研究的重點(diǎn)。
看到如此多的公司仍然使用RNN/LSTM進(jìn)行語音到文本的轉(zhuǎn)換,我真的十分驚訝。許多人不知道這些網(wǎng)絡(luò)是如此低效和不可擴(kuò)展。
訓(xùn)練RNN和LSTM的噩夢
RNN和LSTM的訓(xùn)練是困難的,因?yàn)樗鼈冃枰鎯?chǔ)帶寬綁定計(jì)算,這是硬件設(shè)計(jì)者最糟糕的噩夢,最終限制了神經(jīng)網(wǎng)絡(luò)解決方案的適用性。簡而言之,LSTM需要每個(gè)單元4個(gè)線性層(MLP層)在每個(gè)序列時(shí)間步驟中運(yùn)行。
線性層需要大量的存儲(chǔ)帶寬來計(jì)算,事實(shí)上,它們不能使用許多計(jì)算單元,通常是因?yàn)橄到y(tǒng)沒有足夠的存儲(chǔ)帶寬來滿足計(jì)算單元。而且很容易添加更多的計(jì)算單元,但是很難增加更多的存儲(chǔ)帶寬(注意芯片上有足夠的線,從處理器到存儲(chǔ)的長電線等)。
因此,RNN/LSTM及其變種不是硬件加速的良好匹配,我們?cè)谶@里之前和這里都討論過這個(gè)問題。一個(gè)解決方案將在存儲(chǔ)設(shè)備中計(jì)算出來,就像我們?cè)贔WDNXT上工作的一樣。
總而言之,拋棄RNN吧。注意力模型真的就是你需要的一切!
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識(shí)
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請(qǐng)注明本文地址:http://specialneedsforspecialkids.com/yun/4763.html
摘要:通過兩年的發(fā)展,今天我們可以肯定地說放棄你的和有證據(jù)表明,谷歌,,等企業(yè)正在越來越多地使用基于注意力模型的網(wǎng)絡(luò)。 摘要: 隨著技術(shù)的發(fā)展,作者覺得是時(shí)候放棄LSTM和RNN了!到底為什么呢?來看看吧~ showImg(https://segmentfault.com/img/bV8ZS0?w=800&h=533); 遞歸神經(jīng)網(wǎng)絡(luò)(RNN),長期短期記憶(LSTM)及其所有變體: 現(xiàn)在是...
摘要:舉例,神經(jīng)元,感知機(jī),神經(jīng)網(wǎng)絡(luò)行為主義智能機(jī)器人認(rèn)為人工智能源于控制論。人工智能的研究領(lǐng)域包括專家系統(tǒng)推薦系統(tǒng)等等。是一種實(shí)現(xiàn)人工智能的方法根據(jù)某些算法,通過大量數(shù)據(jù)進(jìn)行訓(xùn)練和學(xué)習(xí),然后對(duì)真實(shí)世界中的事件做出決策和預(yù)測。 1. 緒論 四大流派 符號(hào)主義(知識(shí)圖譜)原理主要為物理符號(hào)系統(tǒng)(即符號(hào)操作系統(tǒng))假設(shè)和有限合理性原理 用數(shù)理邏輯描述智能行為, 在計(jì)算機(jī)上實(shí)現(xiàn)了邏輯演繹系統(tǒng)。 ...

閱讀 1129·2021-11-08 13:13
閱讀 1712·2019-08-30 15:55
閱讀 2767·2019-08-29 11:26
閱讀 2434·2019-08-26 13:56
閱讀 2556·2019-08-26 12:15
閱讀 2133·2019-08-26 11:41
閱讀 1400·2019-08-26 11:00
閱讀 1535·2019-08-23 18:30



