資訊專欄INFORMATION COLUMN

摘要:我們可以通過在特征圖上滑動窗口來檢測目標。以前的滑動窗口方法的致命錯誤在于使用窗口作為最終的邊界框,這就需要非常多的形狀來覆蓋大部分目標。更有效的方法是將窗口當做初始猜想,這樣我們就得到了從當前滑動窗口同時預測類別和邊界框的檢測器。
單次檢測器
Faster R-CNN 中,在分類器之后有一個專用的候選區域網絡。

Faster R-CNN 工作流
基于區域的檢測器是很準確的,但需要付出代價。Faster R-CNN 在 PASCAL VOC 2007 測試集上每秒處理 7 幀的圖像(7 FPS)。和 R-FCN 類似,研究者通過減少每個 ROI 的工作量來精簡流程。
作為替代,我們是否需要一個分離的候選區域步驟?我們可以直接在一個步驟內得到邊界框和類別嗎?
讓我們再看一下滑動窗口檢測器。我們可以通過在特征圖上滑動窗口來檢測目標。對于不同的目標類型,我們使用不同的窗口類型。以前的滑動窗口方法的致命錯誤在于使用窗口作為最終的邊界框,這就需要非常多的形狀來覆蓋大部分目標。更有效的方法是將窗口當做初始猜想,這樣我們就得到了從當前滑動窗口同時預測類別和邊界框的檢測器。
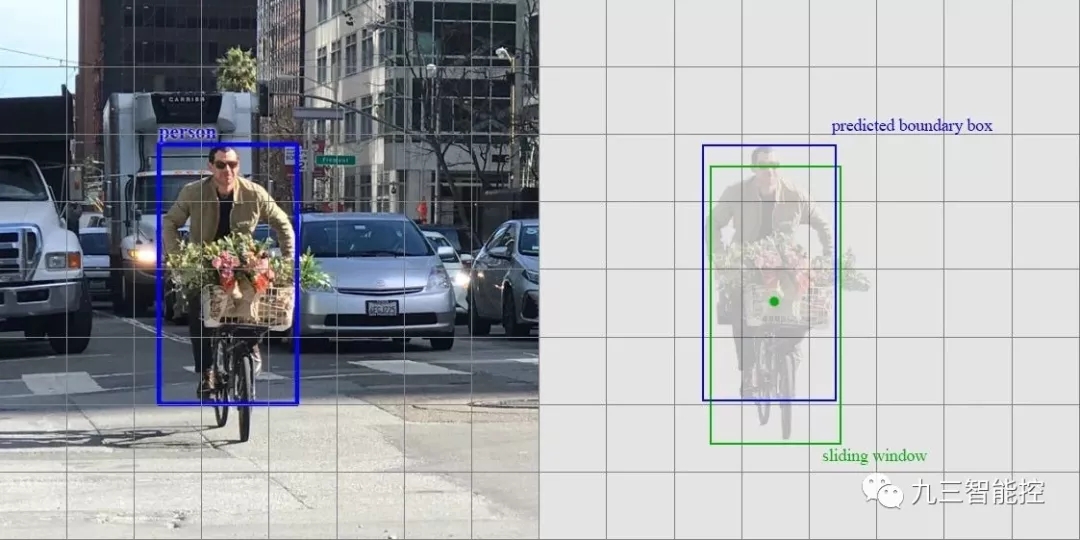
基于滑動窗口進行預測
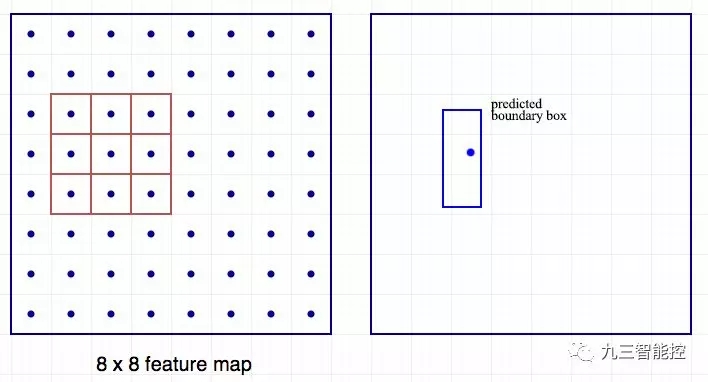
這個概念和 Faster R-CNN 中的錨點很相似。然而,單次檢測器會同時預測邊界框和類別。例如,我們有一個 8 × 8 特征圖,并在每個位置做出 k 個預測,即總共有 8 × 8 × k 個預測結果。

64 個位置
在每個位置,我們有 k 個錨點(錨點是固定的初始邊界框猜想),一個錨點對應一個特定位置。我們使用相同的 錨點形狀仔細地選擇錨點和每個位置。
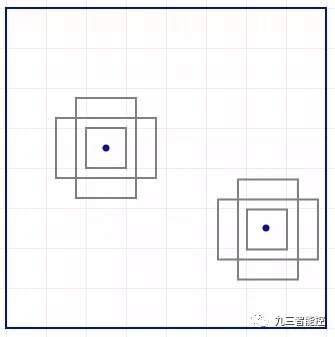
使用 4 個錨點在每個位置做出 4 個預測。
以下是 4 個錨點(綠色)和 4 個對應預測(藍色),每個預測對應一個特定錨點。
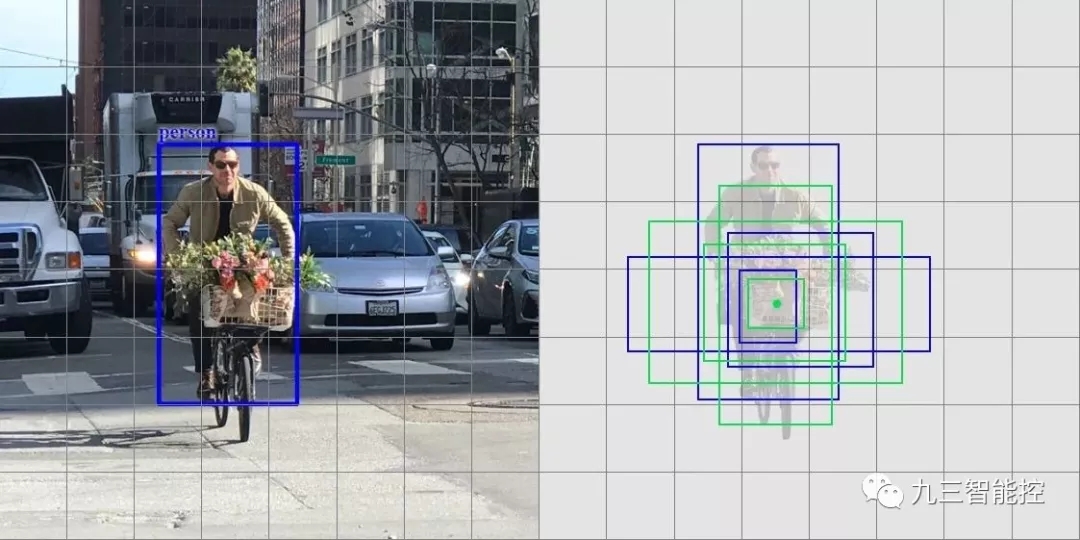
4 個預測,每個預測對應一個錨點。
在 Faster R-CNN 中,我們使用卷積核來做 5 個參數的預測:4 個參數對應某個錨點的預測邊框,1 個參數對應 objectness 置信度得分。因此 3× 3× D × 5 卷積核將特征圖從 8 × 8 × D 轉換為 8 × 8 × 5。
使用 3x3 卷積核計算預測。
在單次檢測器中,卷積核還預測 C 個類別概率以執行分類(每個概率對應一個類別)。因此我們應用一個 3× 3× D × 25 卷積核將特征圖從 8 × 8 × D 轉換為 8 × 8 × 25(C=20)。
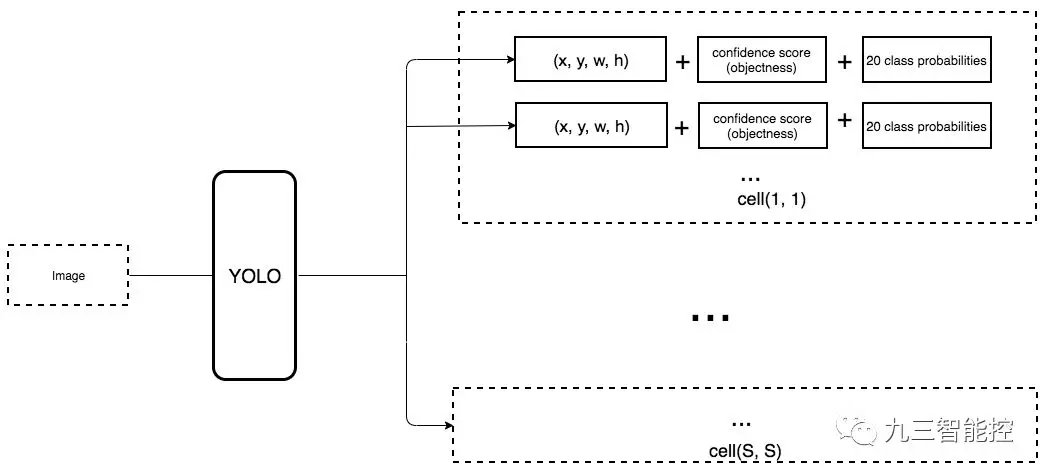
每個位置做出 k 個預測,每個預測有 25 個參數。
單次檢測器通常需要在準確率和實時處理速度之間進行權衡。它們在檢測太近距離或太小的目標時容易出現問題。在下圖中,左下角有 9 個圣誕老人,但某個單次檢測器只檢測出了 5 個。

SSD
SSD 是使用 VGG19 網絡作為特征提取器(和 Faster R-CNN 中使用的 CNN 一樣)的單次檢測器。我們在該網絡之后添加自定義卷積層(藍色),并使用卷積核(綠色)執行預測。
 同時對類別和位置執行單次預測。
同時對類別和位置執行單次預測。然而,卷積層降低了空間維度和分辨率。因此上述模型僅可以檢測較大的目標。為了解決該問題,我們從多個特征圖上執行獨立的目標檢測。

使用多尺度特征圖用于檢測。
以下是特征圖圖示。

圖源:https://arxiv.org/pdf/1512.02325.pdf
SSD 使用卷積網絡中較深的層來檢測目標。如果我們按接近真實的比例重繪上圖,我們會發現圖像的空間分辨率已經被顯著降低,且可能已無法定位在低分辨率中難以檢測的小目標。如果出現了這樣的問題,我們需要增加輸入圖像的分辨率。
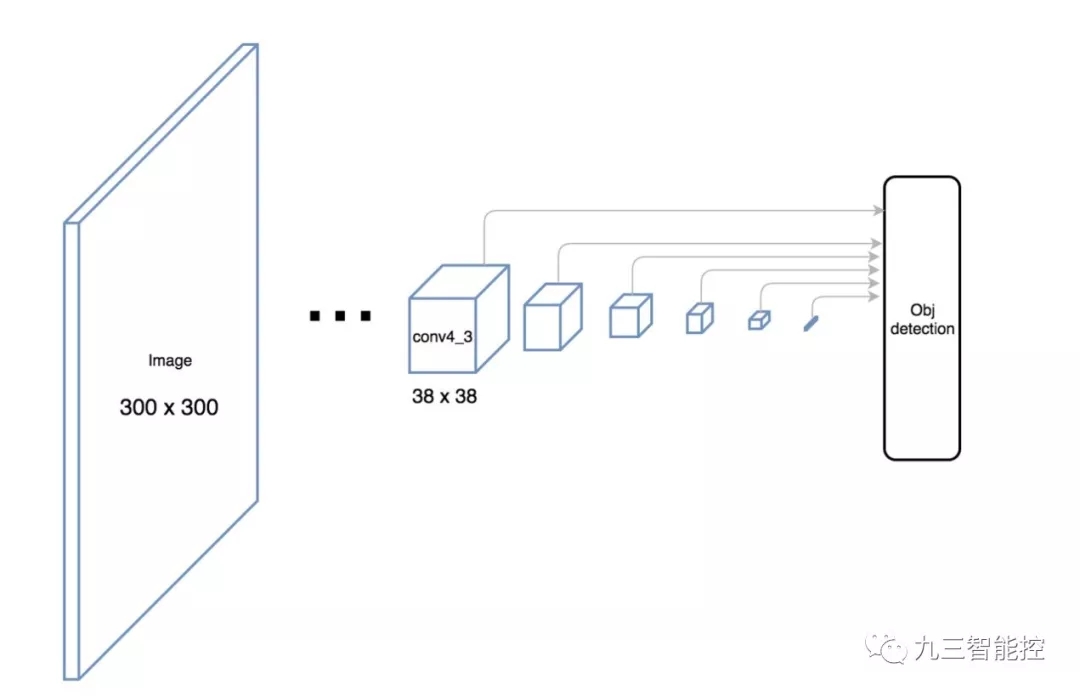
YOLO
YOLO 是另一種單次目標檢測器。YOLO 在卷積層之后使用了 DarkNet 來做特征檢測。

然而,它并沒有使用多尺度特征圖來做獨立的檢測。相反,它將特征圖部分平滑化,并將其和另一個較低分辨率的特征圖拼接。例如,YOLO 將一個 28 × 28 × 512 的層重塑為 14 × 14 × 2048,然后將它和 14 × 14 ×1024 的特征圖拼接。之后,YOLO 在新的 14 × 14 × 3072 層上應用卷積核進行預測。
YOLO(v2)做出了很多實現上的改進,將 mAP 值從第一次發布時的 63.4 提高到了 78.6。YOLO9000 可以檢測 9000 種不同類別的目標。

圖源:https://arxiv.org/pdf/1612.08242.pdf
以下是 YOLO 論文中不同檢測器的 mAP 和 FPS 對比。YOLOv2 可以處理不同分辨率的輸入圖像。低分辨率的圖像可以得到更高的 FPS,但 mAP 值更低。
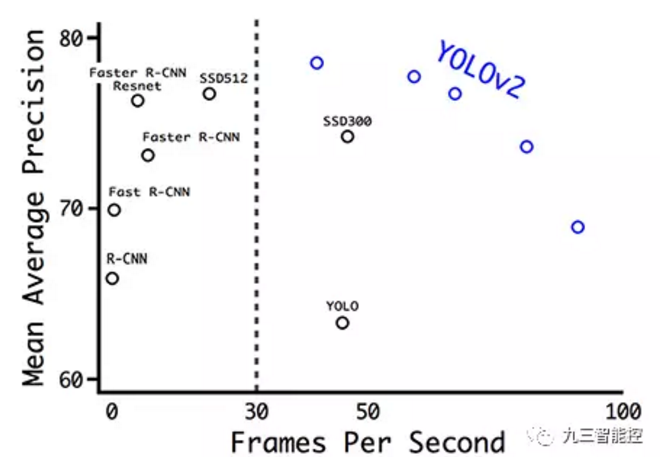
圖源:https://arxiv.org/pdf/1612.08242.pdf
YOLOv3
YOLOv3 使用了更加復雜的骨干網絡來提取特征。DarkNet-53 主要由 3 × 3 和 1× 1 的卷積核以及類似 ResNet 中的跳過連接構成。相比 ResNet-152,DarkNet 有更低的 BFLOP(十億次浮點數運算),但能以 2 倍的速度得到相同的分類準確率。
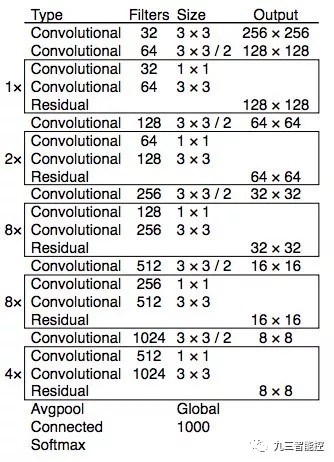
圖源:https://pjreddie.com/media/files/papers/YOLOv3.pdf
YOLOv3 還添加了特征金字塔,以更好地檢測小目標。以下是不同檢測器的準確率和速度的權衡。
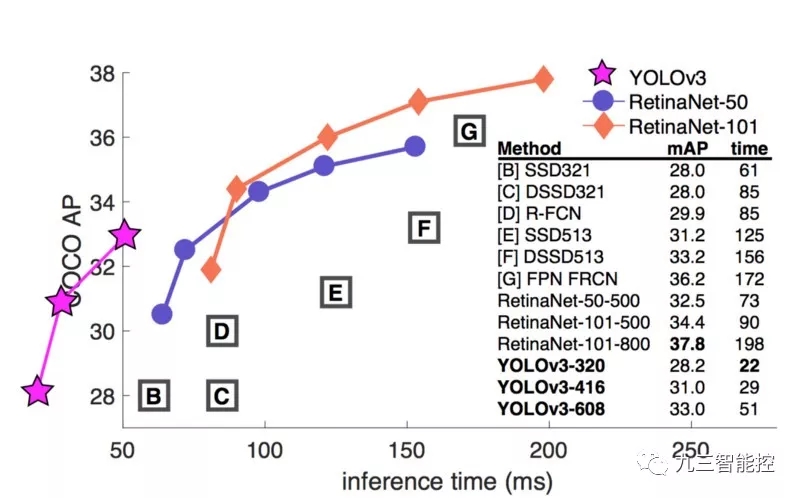
圖源:https://pjreddie.com/media/files/papers/YOLOv3.pdf
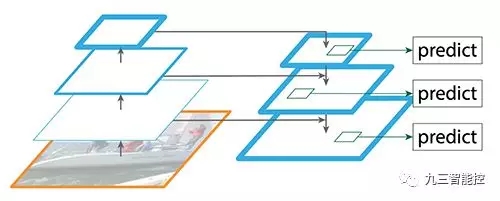
特征金字塔網絡(FPN)
檢測不同尺度的目標很有挑戰性,尤其是小目標的檢測。特征金字塔網絡(FPN)是一種旨在提高準確率和速度的特征提取器。它取代了檢測器(如 Faster R-CNN)中的特征提取器,并生成更高質量的特征圖金字塔。
數據流

FPN(圖源:https://arxiv.org/pdf/1612.03144.pdf)
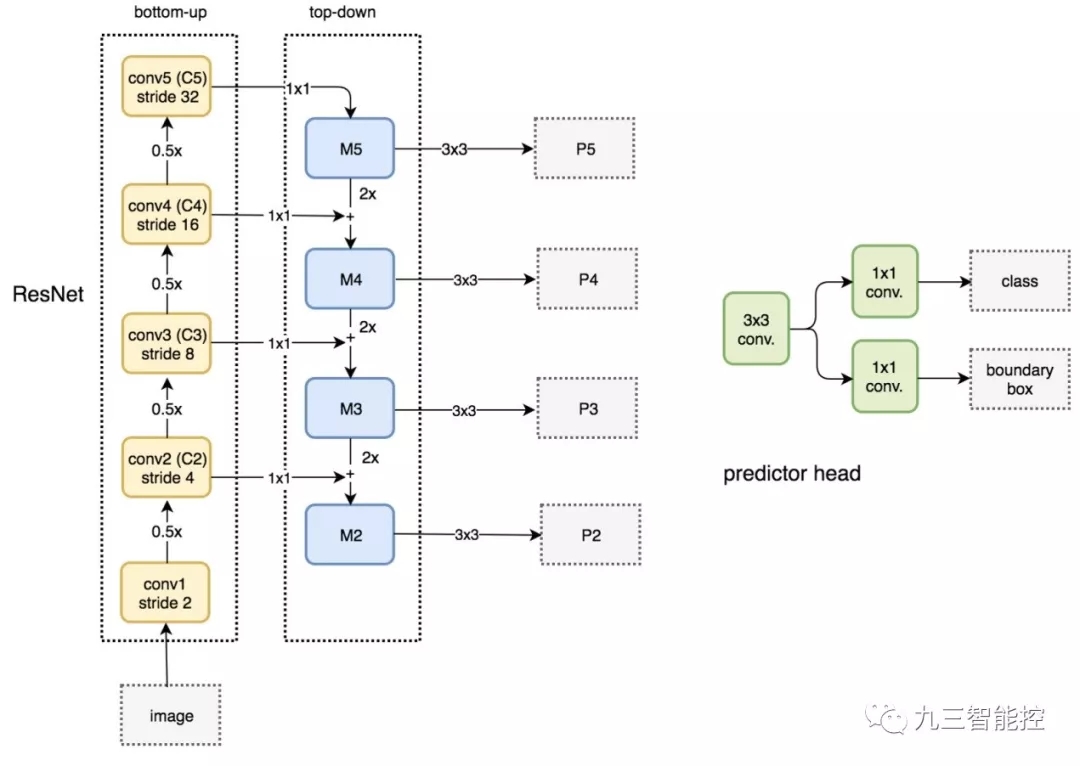
FPN 由自下而上和自上而下路徑組成。其中自下而上的路徑是用于特征提取的常用卷積網絡。空間分辨率自下而上地下降。當檢測到更高層的結構,每層的語義值增加。

FPN 中的特征提取(編輯自原論文)
SSD 通過多個特征圖完成檢測。但是,最底層不會被選擇執行目標檢測。它們的分辨率高但是語義值不夠,導致速度顯著下降而不能被使用。SSD 只使用較上層執行目標檢測,因此對于小的物體的檢測性能較差。

圖像修改自論文 https://arxiv.org/pdf/1612.03144.pdf
FPN 提供了一條自上而下的路徑,從語義豐富的層構建高分辨率的層。

自上而下重建空間分辨率(編輯自原論文)
雖然該重建層的語義較強,但在經過所有的上采樣和下采樣之后,目標的位置不較精確。在重建層和相應的特征圖之間添加橫向連接可以使位置偵測更加準確。
增加跳過連接(引自原論文)
下圖詳細說明了自下而上和自上而下的路徑。其中 P2、P3、P4 和 P5 是用于目標檢測的特征圖金字塔。

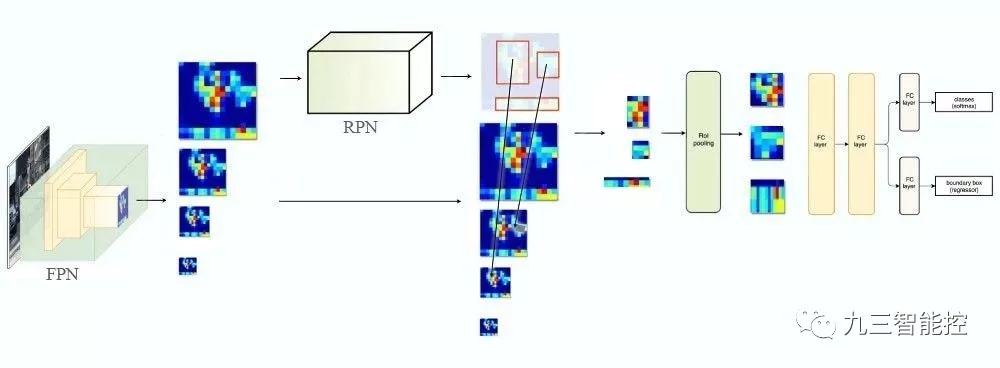
FPN 結合 RPN
FPN 不單純是目標檢測器,還是一個目標檢測器和協同工作的特征檢測器。分別傳遞到各個特征圖(P2 到 P5)來完成目標檢測。
FPN 結合 Fast R-CNN 或 Faster R-CNN
在 FPN 中,我們生成了一個特征圖的金字塔。用 RPN(詳見上文)來生成 ROI。基于 ROI 的大小,我們選擇最合適尺寸的特征圖層來提取特征塊。
困難案例
對于如 SSD 和 YOLO 的大多數檢測算法來說,我們做了比實際的目標數量要多得多的預測。所以錯誤的預測比正確的預測要更多。這產生了一個對訓練不利的類別不平衡。訓練更多的是在學習背景,而不是檢測目標。但是,我們需要負采樣來學習什么是較差的預測。所以,我們計算置信度損失來把訓練樣本分類。選取較好的那些來確保負樣本和正樣本的比例最多不超過 3:1。這使訓練更加快速和穩定。
推斷過程中的非極大值抑制
檢測器對于同一個目標會做出重復的檢測。我們利用非極大值抑制來移除置信度低的重復檢測。將預測按照置信度從高到低排列。如果任何預測和當前預測的類別相同并且兩者 IoU 大于 0.5,我們就把它從這個序列中剔除。
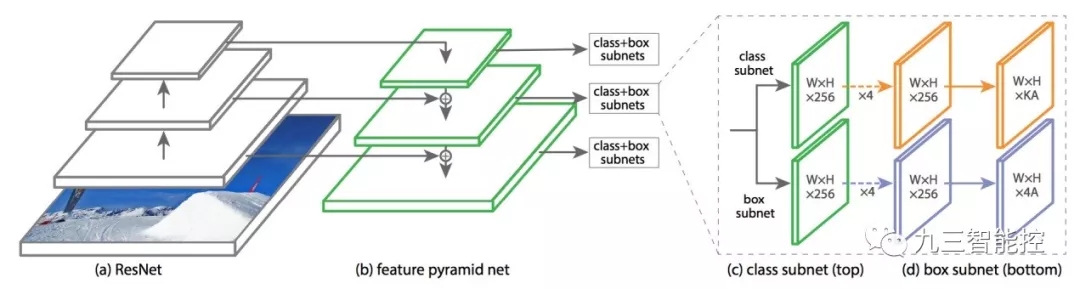
Focal Loss(RetinaNet)
類別不平衡會損害性能。SSD 在訓練期間重新采樣目標類和背景類的比率,這樣它就不會被圖像背景淹沒。Focal loss(FL)采用另一種方法來減少訓練良好的類的損失。因此,只要該模型能夠很好地檢測背景,就可以減少其損失并重新增強對目標類的訓練。我們從交叉熵損失 CE 開始,并添加一個權重來降低高可信度類的 CE。

例如,令 γ = 0.5, 經良好分類的樣本的 Focal loss 趨近于 0。

編輯自原論文
這是基于 FPN、ResNet 以及利用 Focal loss 構建的 RetianNet。
原文鏈接
https://medium.com/@jonathan_hui/what-do-we-learn-from-region-based-object-detectors-faster-r-cnn-r-fcn-fpn-7e354377a7c9
https://medium.com/@jonathan_hui/what-do-we-learn-from-single-shot-object-detectors-ssd-yolo-fpn-focal-loss-3888677c5f4d
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4762.html
摘要:摘要本文介紹使用和完成視頻流目標檢測,代碼解釋詳細,附源碼,上手快。將應用于視頻流對象檢測首先打開文件并插入以下代碼同樣,首先從導入相關數據包和命令行參數開始。 摘要:?本文介紹使用opencv和yolo完成視頻流目標檢測,代碼解釋詳細,附源碼,上手快。 在上一節內容中,介紹了如何將YOLO應用于圖像目標檢測中,那么在學會檢測單張圖像后,我們也可以利用YOLO算法實現視頻流中的目標檢...
摘要:我盡可能對深度學習目標檢測器的組成做一個概述,包括使用預訓練的目標檢測器執行任務的源代碼。當我們理解了什么是目標檢測時,隨后會概述一個深度學習目標檢測器的核心模塊。方法傳統的目標檢測技術路線第一個方法不是純端到端的深度學習目標檢測器。 目標檢測技術作為計算機視覺的重要方向,被廣泛應用于自動駕駛汽車、智能攝像頭、人臉識別及大量有價值的應用上。這些系統除了可以對圖像中的每個目標進行識別、分類以外...
摘要:三大牛和在深度學習領域的地位無人不知。逐漸地,這些應用使用一種叫深度學習的技術。監督學習機器學習中,不論是否是深層,最常見的形式是監督學習。 三大牛Yann LeCun、Yoshua Bengio和Geoffrey Hinton在深度學習領域的地位無人不知。為紀念人工智能提出60周年,的《Nature》雜志專門開辟了一個人工智能 + 機器人專題 ,發表多篇相關論文,其中包括了Yann LeC...

閱讀 3029·2021-11-18 10:07
閱讀 3777·2021-11-17 17:00
閱讀 2107·2021-11-15 18:01
閱讀 933·2021-10-11 10:58
閱讀 3383·2021-09-10 10:50
閱讀 3450·2021-08-13 15:05
閱讀 1232·2019-08-30 15:53
閱讀 2652·2019-08-29 13:01





